ES有些事你应该知道
1.是什么?
Elasticsearch 是一个实时的分布式存储、搜索、分析的引擎,并具有强大的模糊/相关性查询。
2.数据结构?
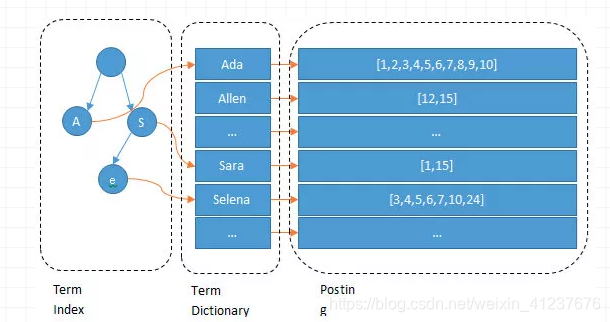
Term Dictionary:我们输入一段文字,Elasticsearch会根据分词器对我们的那段文字进行分词(也就是图上所看到的Ada/Allen/Sara…),这些分词汇总起来我们叫做Term Dictionary。在Term Dictionary中的词由于是非常非常多的,所以我们会为其进行排序,等要查找的时候就可以通过二分来查,不需要遍历整个Term Dictionary
Term Index:由于Term Dictionary的词实在太多了,不可能把Term Dictionary所有的词都放在内存中,于是Elasticsearch还抽了一层叫做Term Index,这层只存储 部分 词的前缀,Term Index会存在内存中(检索会特别快)。Term Index在内存中是以FST(Finite State Transducers)的形式保存的,其特点是非常节省内存。
Posting:文档ID保存在PostingList,PostingList会使用Frame Of Reference(FOR)编码技术对里边的数据进行压缩,节约磁盘空间。
Finite State Transducers:(待补充)
Frame Of Reference:(待补充)
3.ES中常见术语?
Index:Elasticsearch的Index相当于数据库的Table
Type:这个在新的Elasticsearch版本已经废除(在以前的Elasticsearch版本,一个Index下支持多个Type–有点类似于消息队列一个topic下多个group的概念)
Document:Document相当于数据库的一行记录
Field:相当于数据库的Column的概念
Mapping:相当于数据库的Schema的概念
DSL:相当于数据库的SQL(给我们读取Elasticsearch数据的API)
4.ES整体架构
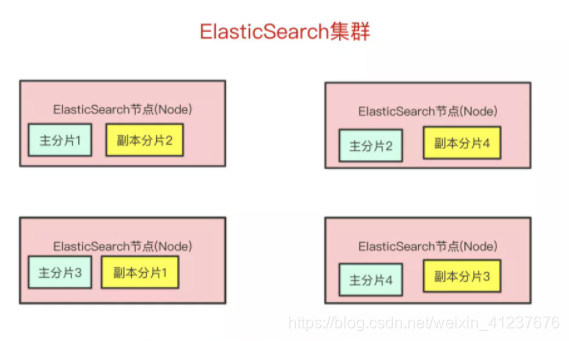
ES架构(分布式,高可用)
ES写入
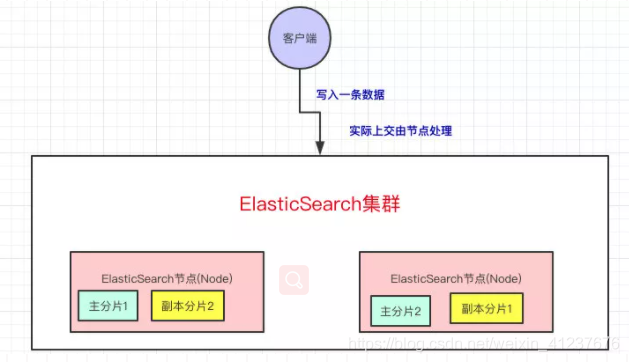
集群上的每个节点都是coordinating node(协调节点),协调节点表明这个节点可以做路由。比如节点1接收到了请求,但发现这个请求的数据应该是由节点2处理(因为主分片在节点2上),所以会把请求转发到节点2上。
coodinate(协调)节点通过hash算法可以计算出是在哪个主分片上,然后路由到对应的节点 shard = hash(document_id) % (num_of_primary_shards)
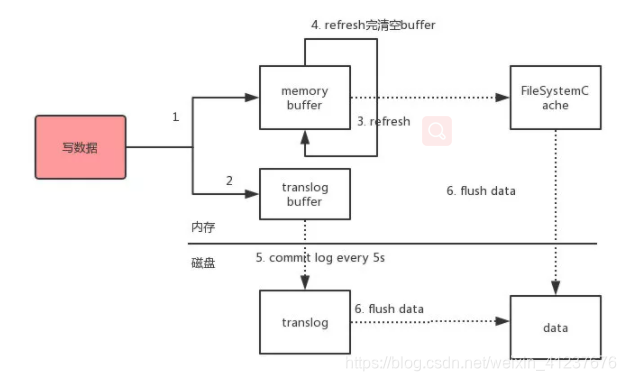
主分片写入流程
-
将数据写到内存缓存区
-
然后将数据写到translog缓存区
-
每隔1s数据从buffer中refresh到FileSystemCache中,生成segment文件,一旦生成 segment 文件,就能通过索引查询到了
-
refresh完,memory buffer就清空了。
-
每隔5s中,translog 从buffer flush到磁盘中
-
定期/定量从FileSystemCache中,结合translog内容
flush index到磁盘中。
- Elasticsearch会把数据先写入内存缓冲区,然后每隔1s刷新到文件系统缓存区(当数据被刷新到文件系统缓冲区以后,数据才可以被检索到)。所以:Elasticsearch写入的数据需要1s才能查询到
- 为了防止节点宕机,内存中的数据丢失,Elasticsearch会另写一份数据到日志文件上,但最开始的还是写到内存缓冲区,每隔5s才会将缓冲区的刷到磁盘中。所以:Elasticsearch某个节点如果挂了,可能会造成有5s的数据丢失。
- 等到磁盘上的translog文件大到一定程度或者超过了30分钟,会触发commit操作,将内存中的segement文件异步刷到磁盘中,完成持久化操作。
等主分片写完了以后,会将数据并行发送到副本集节点上,等到所有的节点写入成功就返回ack给协调节点,协调节点返回ack给客户端,完成一次的写入。
ES更新/删除
Elasticsearch的更新和删除操作流程:给对应的doc记录打上.del标识,如果是删除操作就打上delete状态,如果是更新操作就把原来的doc标志为delete,然后重新新写入一条数据
前面提到了,每隔1s会生成一个segement 文件,那segement文件会越来越多越来越多。Elasticsearch会有一个merge任务,会将多个segement文件合并成一个segement文件。
在合并的过程中,会把带有delete状态的doc给物理删除掉。
ES查询
查询我们最简单的方式可以分为两种:
- 根据ID查询doc
- 根据query(搜索词)去查询匹配的doc
根据ID去查询具体的doc的流程是:
- 检索内存的Translog文件
- 检索硬盘的Translog文件
- 检索硬盘的Segement文件
根据query去匹配doc的流程是:
- 同时去查询内存和硬盘的Segement文件

从上面所讲的写入流程,我们就可以知道:Get(通过ID去查Doc是实时的),Query(通过query去匹配Doc是近实时的)
因为segement文件是每隔一秒才生成一次的
Elasticsearch查询又分可以为三个阶段:
- QUERY_AND_FETCH(查询完就返回整个Doc内容)
- QUERY_THEN_FETCH(先查询出对应的Doc id ,然后再根据Doc id 匹配去对应的文档)
- DFS_QUERY_THEN_FETCH(先算分,再查询)
- 「这里的分指的是 词频率和文档的频率(Term Frequency、Document Frequency)众所周知,出现频率越高,相关性就更强」
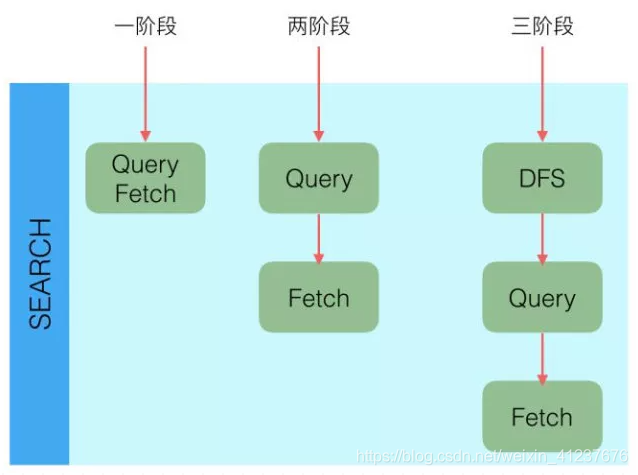
一般我们用得最多的就是QUERY_THEN_FETCH,第一种查询完就返回整个Doc内容(QUERY_AND_FETCH)只适合于只需要查一个分片的请求。
QUERY_THEN_FETCH总体的流程流程大概是:
- 客户端请求发送到集群的某个节点上。集群上的每个节点都是coordinate node(协调节点)
- 然后协调节点将搜索的请求转发到所有分片上(主分片和副本分片都行)
- 每个分片将自己搜索出的结果
(doc id)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。 - 接着由协调节点根据
doc id去各个节点上拉取实际的document数据,最终返回给客户端。
Query Phase阶段时节点做的事:
- 协调节点向目标分片发送查询的命令(转发请求到主分片或者副本分片上)
- 数据节点(在每个分片内做过滤、排序等等操作),返回
doc id给协调节点
Fetch Phase阶段时节点做的是:
- 协调节点得到数据节点返回的
doc id,对这些doc id做聚合,然后将目标数据分片发送抓取命令(希望拿到整个Doc记录) - 数据节点按协调节点发送的
doc id,拉取实际需要的数据返回给协调节点
原文地址: https://mp.weixin.qq.com/s?__biz=MzI4Njg5MDA5NA==&mid=2247486522&idx=1&sn=7b6080756d0711c646fb47d5db49fc97&chksm=ebd74d3bdca0c42d35f7eef97e4f925a20cc82b07ca7aeba21f83ba56135ab2dd1ad73238b72&token=1963867963&lang=zh_CN#rd