mysql数据存储结构
系统将为每一个表单独的生成一个table_name.ibd的文件,在此文件中,存储与该表相关的数据、索引、表的内部数据字典信息。表结构文件则以.frm结尾,这与存储引擎无关。
示意图

什么是索引
索引本质上是一种数据结构
为什么要有索引
搜索引擎只能扫描整个表的每一行,并依次对比判断索引的值是否等于条件值。我们知道,单纯的内存运算是很快的,但从磁盘中取数据到内存中是相对慢的,当表中有大量数据时,内存与磁盘交互次数大大增加,这就导致了查询效率低下。通过索引可以快速找到想要的数据
不使用索引和使用索引的对比案例
不使用索引情况:
先简单介绍一下磁盘的I/O与预读。磁盘读取数据,考的是机械运动,每次读取数据花费的时间可以分成:寻道时间、旋转延迟、传输时间三个部分。寻道时间指的是磁臂移动到指定磁盘所需要的时间,主流的磁盘一般在5ms以下;旋转延迟指的是我们经常说的磁盘转速,比如一个磁盘7200转,表示的就是每分钟磁盘能转7200次,转换成秒也就是120次每秒,旋转延迟就是1/120/2=4.17ms;传输时间指的是从磁盘读取出数据或将数据写入磁盘的时间,一般都在零点几毫秒,相对于前两个,可以忽略不计。那么访问一次磁盘的时间,即一次磁盘I/O的时间约等于5+4.17=9.17ms,9ms左右,听起来还是不错的哈,但数据库百万级别的数据过一遍就达到了9000s。要是你做的查询功能的等待时间到了这种级别基本可以打包回家了。 但是如果用了索引
使用索引
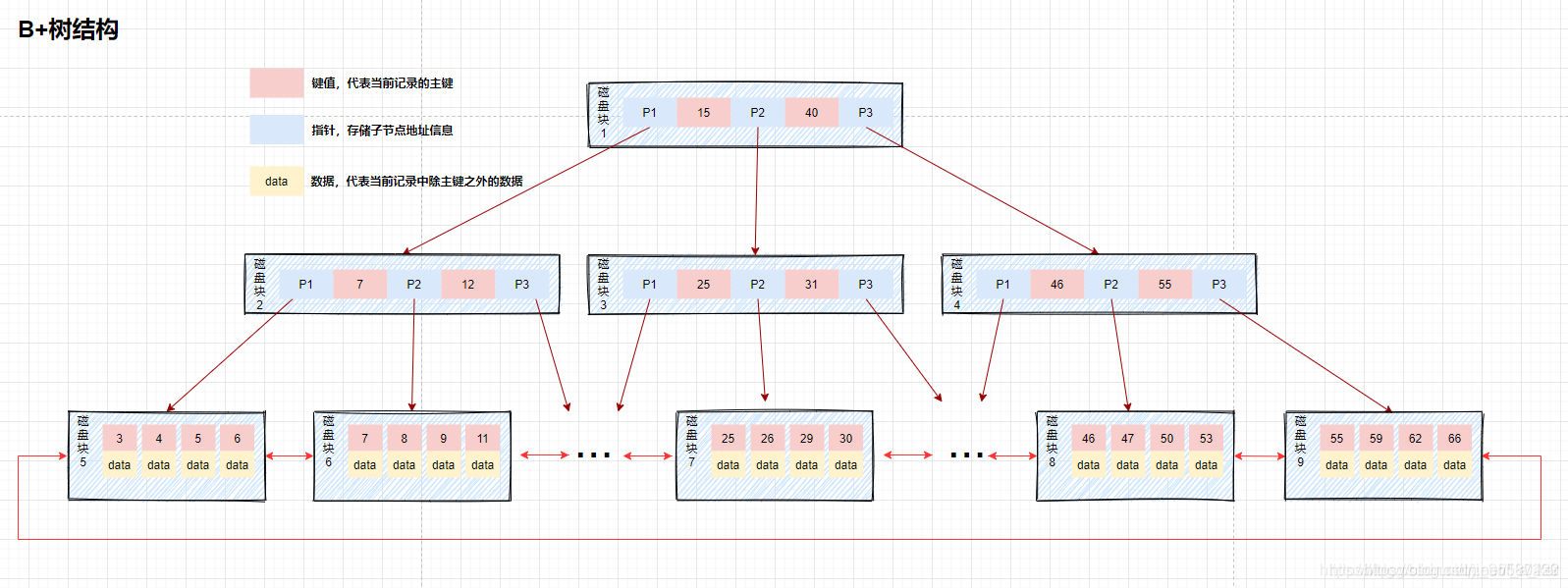
nnoDB存储引擎中页的大小为16KB,一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为〖10〗^3)。
也就是说一个深度为3的B+Tree索引可以维护10^3 * 10^3 * 10^3 = 10亿 条记录。(这种计算方式存在误差,而且没有计算叶子节点,如果计算叶子节点其实是深度为4了)
我们只需要进行三次的IO操作就可以从10亿条数据中找到我们想要的数据,这个时候建议直接跳锤DBA 该你吹牛逼的高光时刻来临了兄弟们。
索引的意义
索引(Index)是帮助MySQL高效获取数据的数据结构。
索引的结构(B+树)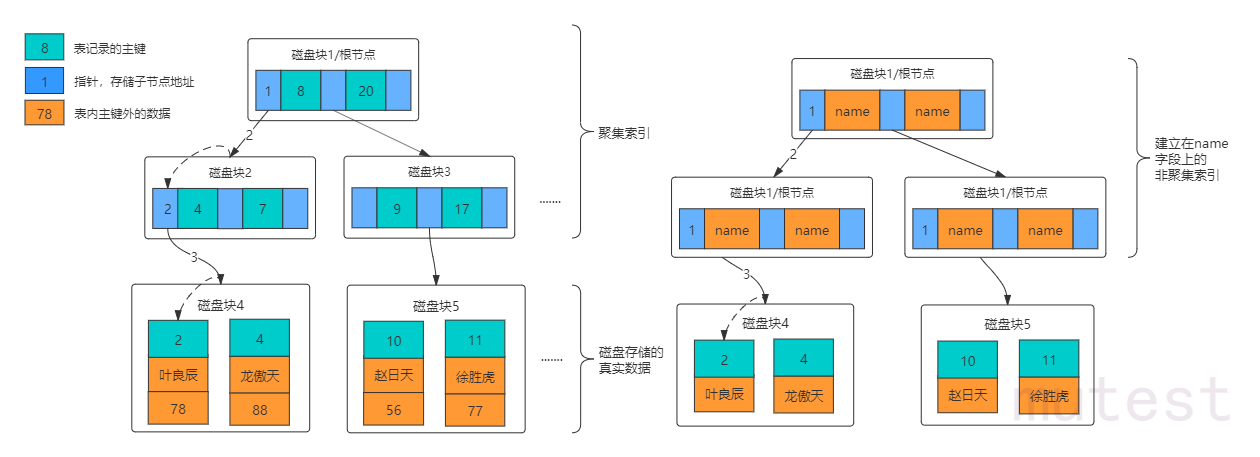
索引执行流程(聚簇索引)
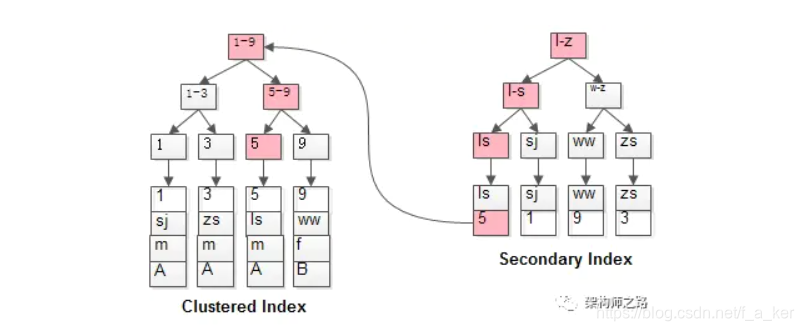
非聚簇索引需要回表哦(叶子节点存放主键id 查完后需要重新走一遍主键索引树)
索引的分类
- 按照叶子节点存放得的数据分为:聚簇索引(叶子节点存放一条记录的所有数据)(主键索引是聚簇索引),非聚簇索引(叶子节点存放主键id) 【非聚簇索引查完需要回表查询聚簇索引的树结构】
- 按照值是否会重复分为:唯一索引(主键索引是唯一索引) 和普通索引(没有任何限制 允许空值和重复值)
- 按照建立索引的字段数分为:单列索引和联合索引
- 全文索引:全文索引主要用来查找文本中的关键字,只能在 CHAR、VARCHAR 或 TEXT 类型的列上创建。在 MySQL 中只有 MyISAM 存储引擎支持全文索引。全文索引允许在索引列中插入重复值和空值。