本文部分内容来自于:
http://officeopenxml.com/anatomyofOOXML-xlsx.php
http://officeopenxml.com/SScontentOverview.php
http://officeopenxml.com/SSstyles.php
本篇内容过长,且纯英文,预计阅读时间3小时。
不想深入了解的,请直接看The Grid章节,在下一篇博客中,将会演示如何使用POI的EvemtModel模式读取数据,其中就重点用到了The Grid章节中的内容
Package Structure
A SpreadsheetML or .xlsx file is a zip file (a package) containing a number of “parts” (typically UTF-8 or UTF-16 encoded) or XML files.
The package may also contain other media files such as images.
The structure is organized according to the Open Packaging Conventions as outlined in Part 2 of the OOXML standard ECMA-376.
You can look at the file structure and the files that comprise a SpreadsheetML file by simply unzipping the .xlsx file.
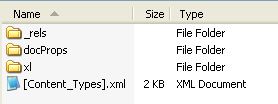
The number and types of parts will vary based on what is in the spreadsheet, but there will always be a [Content_Types].xml, one or more relationship parts, a workbook part , and at least one worksheet.
The core data of the spreadsheet is contained within the worksheet part(s), discussed in more detail at xsxl Content Overview.
Content Types
Every package must have a [Content_Types].xml, found at the root of the package.
This file contains a list of all of the content types of the parts in the package.
Every part and its type must be listed in [Content_Types].xml.
The following is a content type for the main content part:
<Override PartName="/xl/workbook.xml" ContentType="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet.main+xml"/>
It’s important to keep this in mind when adding new parts to the package.
Relationships
Every package contains a relationships part that defines the relationships between the other parts and to resources outside of the package.
This separates the relationships from content and makes it easy to change relationships without changing the sources that reference targets.
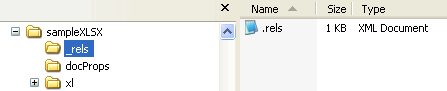
For an OOXML package, there is always a relationships part (.rels) within the _rels folder that identifies the starting parts of the package, or the package relationships.
For example, the following defines the identity of the start part for the content:
<Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/officeDocument" Target="xl/workbook.xml"/>.
There are also typically relationships within .rels for app.xml and core.xml.
In addition to the relationships part for the package, each part that is the source of one or more relationships will have its own relationships part.
Each such relationship part is found within a _rels sub-folder of the part and is named by appending '.rels' to the name of the part.
Typically the main content part (workbook.xml) has its own relationships part (workbook.xml.rels).
It will contain relationships to the other parts of the content, such as sheet1.xml, sharedStrings.xml, styles.xml, theme1.xml, as well as the URIs for external links.
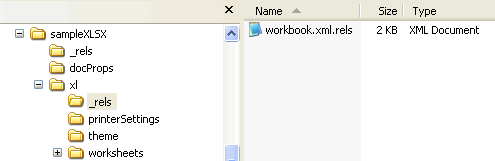
A relationship can be either explicit or implicit.
For an explicit relationship, a resource is referenced using the Id attribute of a <Relationship> element.
That is, the Id in the source maps directly to an Id of a relationship item, with an explicit reference to the target.
For example, a worksheet might contain a hyperlink such as this:
<w:hyperlink ref="A11" r:id="rId4">
The r:id=“rId4” references the following relationship within the relationships part for the worksheet (worksheet1.xml.rels).
<Relationship Id="rId4" Type="http://. . ./hyperlink" Target="http://www.google.com/" TargetMode="External"/>
For an implicit relationship, there is no such direct reference to a <Relationship> Id.
Instead, the reference is understood.
Parts Specific to SpreadsheetML Documents
Below is a list of the possible parts of a SpreadsheetML package that are specific to SpreadsheetML spreadsheets.
Keep in mind that a spreadsheet may only have a few of these parts.
For example, if a spreadsheet has no pivot table, then a pivot table part will not be included in the package.
| Part | Description |
|---|---|
| Calculation Chain | When the values of cells are calculated from formulas, the order of calculation can be affected by the order in which the values are calculated. This part contains specifies the ordering. A package can contain only one such part. |
| Chartsheet | Contains a chart that is stored in its owne sheet. A package can contain multiple such parts, referenced from the workbook part. |
| Comments | Contains the comments for a given worksheet. Since there may be more than one worksheet, there may be more than one comments part. (可能是每个sheet的名称) |
| Connections | A spreadsheet may have connections to external data sources. This part contains such connections, explaining both how to get such externnal data and how the connection is used within the workbook. There may be only one such part. |
| Custom Property | Contains user-defined data. There may be zero or more such parts. |
| Customer XML Mappings | Contains a schema for an XML file, and information on the behavior to be used when allowing the schema to be mapped into the spreadsheet. There may be only one such part. |
| Dialogsheet | Contains information about a legacy customer dialog box for a user form. There may be zero or more such parts. |
| Drawings | Contains the presentation and layout information for one or more drawing elements that are present in the worksheet. There should be drawings part for each worksheet that has a drawing. |
| External Workbook References | Contains information about data referenced in other spreadsheet packages. For example, a spreadsheet may have a cell whose value is calculated from data in another spreadsheet. There may be zero or more such parts. |
| Metadata | Contains information relating to a cell whose value is related to one or more other cells via Online Analytical Processing (OLAP) technology. |
| Pivot Table | Contains the definition of a pivot table. It describes the particulars of the layout of the pivot table, indicating what fields are on the row axis, the column axis, and values areas of the pivot table. And it indicates formatting for the pivot table. There is a pivot table part for each pivot table within the package. |
| Pivot Table Cache Definition | The pivot table cache definition defines each field in the pivot cache records part (i.e., the underlying data), including field name and information about the data contained in the field. There is a pivot table cahe definition part for each pivot table within the package. |
| Pivot Table Cache Records | Contains the underlying data for a pivot table. There will be zero or one such part for each pivot table in the package. |
| Query Table | Contains information that describes how the source table is connected to an external data source and defines the properties that are used when the table is refreshed from the source. There may be one such part for each table. |
| Shared String Table | Contains one occurrence of each unique string that occurs in any worksheet within the workbook. There is one such part for a package. |
| Shared Workbook Revision Log | Contains information about edits performed on individual cells in the workbook’s worksheets. There should be one such part for each editing session |
| Shared Workbook User Data | Contains a list of all users that are sharing the workbook. A package contained zero or one such part. |
| Single Cell Table Definition | Contains information on how to map non-repeating elements from a custom XML file into cells in a worksheet. There may be one such part per worksheet. |
| Styles | Contains all the characteristics for all cells in the workbook, including numeric and text formatting, alignment, font, color, and border. A package contains no more than one such part. |
| Table Definition | A spreadsheet can contain regions that have clearly labeled columns, rows, and data regions. Such regions are called tables, and each worksheet can have zero or more tables. For each table in a worksheet there must be a table definitions part containing a description of the table. (The data for the table is stored in the corresponding worksheet part.) |
| Volatile Dependencies | Cells can contain real-time data formulas that return values that change over time and that require connectivity to programs outside of the workbook. In cases where those programs are not available, the formulas can use information stored in the volatile dependencies part. A package can have only one such part. |
| Workbook | Contains data and references to all of the worksheets. There must be one and only one workbook part. |
| Worksheet | Contains all the data, formulas, and characteristics of a given worksheet. There is one such part for each worksheet in the package. |
Parts Shared by Other OOXML Documents
There are a number of part types that may appear in any OOXML package.
Below are some of the more relevant parts for SpreadsheetML documents.
| Part | Description |
|---|---|
| Embedded package | Contains a complete package, either internal or external to the referencing package. For example, a SpreadsheetML document might contain a Wordprocessing or PresentationML document. |
Extended File Properties (often found at docProps/app.xml) |
Contains properties specific to an OOXML document–properties such as the template used, the number of pages and words, and the application name and version. |
| File Properties, Core | Core file properties enable the user to discover and set common properties within a package–properties such as creator name, creation date, title. Dublin Core properties (a set of metadate terms used to describe resources) are used whenever possible. |
| Image | Spreadsheets often contain images. An image can be stored in a package as a zip item. The item must be identified by an image part relationship and the appropriate content type. |
| Theme | DrawingML is a shared language across the OOXML document types. It includes a theme part that is included in SpreadsheetML documents when the spreadsheet uses a theme. The theme part contains information about a document’s theme, that is, such information as the color scheme, font and format schemes. |
Spreadsheet Content Overview
A SpreadsheetML document is a package containing a number of different parts, mostly XML files.
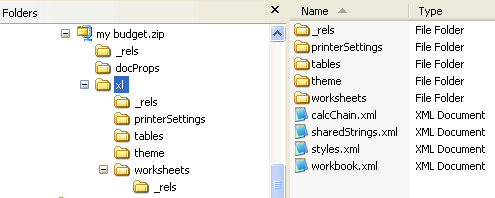
However, most of the actual content is found within one or more worksheet parts (one for each worksheet), and one sharedStrings part.
For Microsoft Excel, the content is found within an xl folder, and the worksheets are within a worksheet sub-folder.
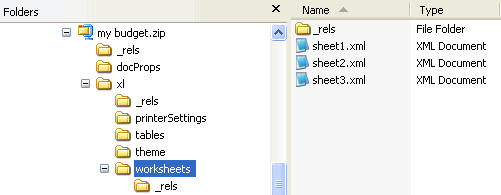
The workbook part contains no actual content but merely some properties of the spreadsheet, with references to the separate worksheet parts which contain the data.
<workbook . . .>
. . .
<workbookPr . . ./>
<sheets>
<sheet name="sheet1" r:id="rId1">
<sheet name="sheet2" r:id="rId2">
<sheet name="sheet3" r:id="rId3">
</sheets>
. . .
</workbook>
A worksheet can be either a grid, a chart, or a dialog sheet.
The Grid(主要用到这些)
A grid of cells (or a “cell table”) is the most common type or worksheet.
Cells can contain text, booleans, numbers, dates, and formulas.
It is important to understand from the outset that most text values are not stored within a worksheept part.
In an effort to minimize duplication of values, a cell value that is a string is stored separately in the shareStrings part.(There is an exception to this generalization, however. A cell can be of type inlineStr, in which case the string is stored in the cell itself, within an is element.)
All other cell values–booleans, numbers, dates, and formulas (as well as the values of formulas) are stored within the cell.
Some properties for the sheet are at the beginning of the root <worksheet> element.
The number and sizes of the columns of the grid are defined within a <cols>.
And then the core data of the worksheet follows within the <sheetData> element.
The sheet data is divided into rows (<row>), and within each row are cells (<c>).
Rows are numbered or indexed, beginning with 1, with the r attribute (e.g., row r="1").
Each cell in the row also has a reference attribute which combines the row number with the column to make the reference attribute (e.g., <c r="D3">).
If a cell within a row has no content, then the cell is omitted from the row definition.
<worksheet . . .>
. . .
<cols>
<col min="1" max="1" width="26.140625" customWidth="1"/>
. . .
</cols>
<sheetData>
<row r="1">
<c r="A1" s="1" t="s">
<v>0</v>
. . .
</c>
</row>
. . .
</sheetData>
. . .
<mergeCells count="1">
<mergeCell ref="B12:J16"/>
</mergeCells>
<pageMargins . . ./>
<pageSetup . . ./>
<tableParts ccount="1">
<tableParts count="1">
</tablePart r:id="rId2"/>
</worksheet>
The make-up of a cell is important in understanding the overall architecture of the spreadsheet content.
Each cell specifies its type with the t attribute.
Possible values include:
bfor booleandfor dateefor errorinlineStrfor an inline string (i.e., not stored in the shared strings part, but directly in the cell)nfor numbersfor shared string (so stored in the shared strings part and not in the cell)strfor a formula (a string representing the formula)
When a cell is a number, then the value is stored in the <v> element as a child of <c> (the cell element).
<c r="B2" s="5" t="n">
<v>400</v>
</c>
A date is the same, though the date is stored as a value in the ISO 8601 format.
For inline strings, the value is within an <is> element.
But of course the actual text is further nested within a t since the text can be formatted.
<c r="C4" s="2" t="inlineStr">
<is>
<t>my string</t>
</is>
</c>
For a formula, the formula itself is stored within an f element as a child element of <c>.
Following the formula is the actual calculated value within a <v> element.
<c r="B9" s="3" t="str">
<f>SUM(B2:B8)</f>
<v>2105</v>
</c>
When the data type of the cell is s for shared string, then the string is stored in the shared strings part.
However, the cell still contains a value within a <v> element, and that value is the index (zero-based) of the stored string in the shared strings part.
So, for example, in the example below, the actual string is the 9th occurrence of the <si> element within the shared strings part.
<c r="C1" s="4" t="s">
<v>8</v>
</c>
The shared string part may look like this:
(感觉shared string应该是类似于常量的东西)
<sst xmls="http://schemas.openmlformats.org/spreadsheetml/2006/main" count="19" uniqueCount="13">
<si><t>Expenses</t></si>
<si><t>Amount</t></si>
<si><t>Food</t></si>
<si><t>Totals</t></si>
<si><t>Entertainment</t></si>
<si><t>Car Payment</t></si>
<si><t>Rent</t></si>
<si><t>Utilities</t></si>
<si><t>Insurance</t></si>
<si><t>Date Paid</t></si>
. . .
</sst>
Tables
Data on a worksheet can be organized into tables.
Tables help provide structure and formatting to the data by having clearly labeled columns, rows, and data regions.
Rows and columns can be added easily, and filter and sort abilities are automatically added with the drop down arrows.
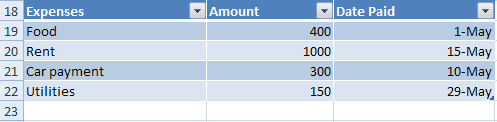
The actual table data for the cells is usually stored in the worksheet part as any other data, but the definition of the table is stored in a separate table part which is referenced from the worksheet in which the table appears.
<worksheet . . .>
. . .
<sheetData>
. . .
</sheetData>
. . .
<tableParts count="1">
<tableParts count="1">
</tablePart r:id="rId2"/>
</worksheet>
Within the rels part for the worksheet is the following:
<Relationship Id="rId2" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/table" Target=".. /tables/table1.xml"/>
The table part is shown below.
The content of the table part is below.
<table xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main" id="1" name="Table1" displayName="Table1" ref="A18:C22" totalRowShown="0">
<autoFilter ref="A18:C22"/>
<tableColumns count="3">
tableColumn id="1" name="Expenses"
tableColumn id="2" name="Amount"
tableColumn id="3" name="Date Paid"
</tableColumns>
<tableStyleInfo name="TableStyleMedium9" showFirstColumn="0" showLastColumn="0" showRowStripes="1" showColumnStripes="0"/>
</table>
The ref attribute in red above defines the range of cells within the worksheet that comprise the table.
Pivot Tables
Pivot tables are used to aggregate data, and to summarize and display it in an understandable layout.
For example, suppose I have a large spreasheet which captures the sales of four products in four cities.
I may have a column for the product, date, quantity sold, city, and state.
Each day has an entry for each product in each city, or 16 entries per day.
So even with only 4 products in 4 cities, I could have 5840 rows of data for a year.
What if wanted to determine what city had the most sales in the spring months?
What product was improving?
What city had the greatest sales of red widgets?
Pivot tables help to summarize the data and quickly provide the answers to these questions.

Pivot tables have a row axis, a column axis, a values area, and a report filter area.
Each table also has a field list from which users can select which fields to include in the pivot table.
Below is a pivot table that summarizes the sales and revenue by product.
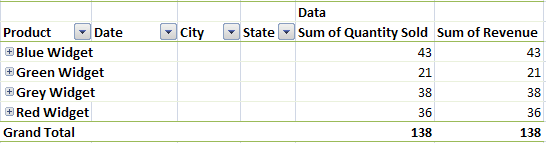
A pivot table is comprised of the following components.
- There is the underlying data that the pivot table summarizes. This data may be on the same worksheet as the pivot table, on a different worksheet, or it may be from an external source.
- A cache or copy of that data is created in a part called the pivotCacheRecords part; a cache is needed when, e.g., the external data source is unavailable.
- There is a pivotCacheDefinition part that defines each field in the pivot table and contains shared items, much like the sharedStrings part contains strings to remove redundancy in a worksheet.
- The pivotTable part defines the layout of the pivot table itself, specifying what fields are on the row axix, the column axix, the report filter, and the values area.

The workbook points to and owns the pivotCacheDefinition part.
There is the reference in the workbook to the cache of data for the pivot table, following the references to the worksheets:
<pivotCaches>
<pivotCache cacheId="13" r:id="rId4"/>
</pivotCaches>
The rels part for the workbook contains that reference:
<Relationship Id="rId4" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/pivotCacheDefinition" Target="pivotCache/pivotCacheDefinition1.xml"/>
The pivotCacheDefinition part in turn points to the pivotCacheRecords part.
<pivotCacheDefinition xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main" xmlns:r="http://schemas.openxmlformats.org/spreadsheetml/2006/relationships" r:id="rId1" refreshBy="XXXX" refreshedDate="41059.666109143516" createdVersion="1" refreshedVersion="3" recordCount="32" upgradeOnRefresh="1">
. . .
</pivotCacheDefinition>
The rels part for the pivotCacheDefinition contains that reference:
<Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/pivotCacheRecord" Target="pivotCacheRecords1.xml"/>
The pivotCacheDefinition part also references the source data in its
<cacheSource> element:
<cacheSource type="worksheet">
<worksheetSource ref="A1:F33" sheet="Sheet1"/>
</cacheSource>
The worksheet that contains the pivot table references the pivotTable part.
(There may be more than one, since a worksheet can have more than one pivot table.)
The rels part for the worksheet contains that reference:
<Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/pivotTable" Target="../pivotTables/pivotTable1.xml"/>
The pivotTable part references the pivotCacheDefinitions part.
The rels part for the pivotTable part contains that reference:
<Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/pivotCacheDefinition" Target="../pivotCache/pivotCacheDefinition1.xml"/>
pivotCacheDefinition
Now let’s look briefly at these parts and try to make sense out of them.
Let’s begin with the pivotCacheDefinition.
As mentioned above, it specifies the location of the source data.
It also defines each field (such as data type and formatting to be used) in the source data, including those not used in the pivot table.
(What fields are actually used is specified in the pivot table part.) And it is used as a cache for shared strings, just as the SharedStrings part is used to store strings that appear in worksheets.
The definition of the six fields in our example worksheet is below.
<pivotCacheDefinition . . .>
<cacheSource type="worksheet">
>worksheetSource ref="A1:F33" sheet="Sheet1"/>
</cacheSource>
<cacheFields count="6">
<cacheField name="Product" numFmtId="0">
<sharedItems count="4">
<s v="Green Widget"/>
<s v="Red Widget"/>
<s v="Grey Widget"/>
<s v="Blue Widget"/>
</sharedItems>
</cacheField>
<cacheField name="Quantity Sold" numFmtId="0">
<sharedItems containsSemiMixedTypes="0" containsString="0" containsNumber="1" containsInteger="1" minValue="1" maxValue="9"/>
</cacheField>
<cacheField name="Date" numFmtId="14">
<sharedItems containsSemiMixedTypes="0" containsNoDate="0" containsDate="1" containsString="0" minDate="2012-03-04T00:00:00" maxDate="2012-03-06T00:00:00 count=2">
<d v="2012-03-04T00:00:00"/>
<d v="2012-03-05T00:00:00"/>
</sharedItems>
</cacheField>
<cacheField name="Revenue" numFmtId="165">
<sharedItems containsSemiMixedTypes="0" containsString="0" containsNumber="1" containsInteger="1" minValue="1" maxValue="9"/>
</cacheField>
<cacheField name="City" numFmtId="0">
<sharedItems count="4">
<s v="Rochester"/>
<s v="Albany"/>
<s v="Pittsburgh"/>
<s v="Philadelphia"/>
</sharedItems>
</cacheField>
<cacheField name="State" numFmtId="0">
<sharedItems count=2">
<s v="NY"/>
<s v="PA"/>
</sharedItems>
</cacheField>
</cacheFields>
</pivotCacheDefinition>
The first field defined above is the product field.
It consists of shared string values.
If the field does not have shared string values (such as the second field defined above–the Quantity Sold field), then the values are stored directly in the pivotCacheRecords part.
pivotCacheRecords
Let’s look at the pivotCacheRecords part to see how the field definitions relate to the cached data.
Below are the first two rows of data in the cache.
<pivotCacheRecords . . .>
<r>
<x v="0"/>
<n v="2"/>
<x v="0"/>
<n v="2"/>
<x v="0"/>
<x v="0"/>
</r>
<r>
<x v="1"/>
<n v="3"/>
<x v="0"/>
<n v="3"/>
<x v="0"/>
<x v="0"/>
</r>
. . .
</pivotCacheRecords>
This corresponds to the data from the worksheet shown below.

Note first that each record (<r>) of the cached data has the same number of values as are defined in the pivotCacheDefinition–in our case, six.
Within each record are the following possible elements:
<x> - indicating the index value referencing an item for the field as defined in the pivotCacheDefinition
<s> - indicating a string value is being expressed inline in the record
<n> - indicating a numeric value is being expressed inline in the record
Looking at the two sample records from the pivotCacheRecords above, we know from the pivotCacheDefinition that the six values are product, quantity, date, revenue, city, and state in that order.
The Product field in the first record is <x v="0"/>, so the value (0) is an index into the items listed in the product field.
The first one listed (index 0) is Green Widget.
The second or quantity field value is <n v="2"/>, so the value (2) is a numeric value expressed inline.
The third or date field value is <x v="0"/>, so the value (0) is an index into the items listed in the date field (2012-03-04T00:00:00 or 3/4). Etc.
pivotTable
Now let’s look at the pivotTable part.
The root element is the <pivotTableDefinition> element.
There are several components within this.
First, the location of the pivot table on the worksheet is specified.
The location is straightforward.
Note that both the first header and data columns are specified.
<pivotTableDefinition . . .>
<location ref="B37:G43 firstHeaderRow="1" firstDataRow="2" firstDataCol="4"/>
</cacheSource>
The order of items for fields and other field information for each field is then specified by <pivotField> elements within a <pivotFields>.
<pivotFields count="6">
<pivotField axis="axisRow" compact="0" outline="0" subtotalTop="0" showAll="0" includeNewItemsFilter="1">
<items count="5">
<item sd="0" x="3"/>
<item sd="0" x="0"/>
<item sd="0" x="2"/>
<item sd="0" x="1"/>
<item t="default"/>
</items>
</pivotField>
<pivotField dataField="1" compact="0" outline="0" subtotalTop="0" showAll="0" includeNewItemsFilter="1"/>
<pivotField axis="axisRow" compact="0" numFmtId="14" outline="0" subtotalTop="0" showAll="0" includeNewItemsFilter="1">
<items count="3">
<item sd="0" x="0"/>
<item sd="0" x="1"/>
<item t="default"/>
</items>
</pivotField>
. . .
</pivotFields count="6">
From the pivotCacheDefinition we know that the first <pivotField> above is the product. It has 5 items listed.
The first one is <item sd="0" x="3"/>.
The sd attribute indicates whether the item is hidden.
A value of 0 means the item is not hidden.
The x attribute is the index for the items in the <cacheField> for the product in the pivotCacheDefinition.
The <cacheField> is shown below.
Note that the value of the item at index 3 is Blue Widget, so Blue Widget should appear first in the pivot table if and where the product field is shown.
<cacheField name="Product" numFmtId="0">
<sharedItems count="4">
<s v="Green Widget"/>
<s v="Red Widget"/>
<s v="Grey Widget"/>
<s v="Blue Widget"/>
</sharedItems>
</cacheField>
The second item has an index of 0, or “Green Widget”, the third is 2 or “Grey Widget,” and the fourth is 1 or “Red Widget.”
Note that <item t="default"/> indicates a subtotal or total.
Following the <pivotFields> collection is the <rowFields> collection.
This collection specifies what fields are actually in the pivot table on the row axis, and in what order.
In our example, when we fully expand the first row, we see that a row consists of first a product, then a city, followed by a state, and then a date.
These are the row fields.

Following the index order in the <pivotFields> collection, this is 0, 4, 5, 2. The corresponding <rowFields> looks like this.
<rowFields count="4">
<field x="0"/>
<field x="4"/>
<field x="5"/>
<field x="2"/>
</rowFields>
After the <rowFields> collection is the <rowItems> collection.
This is a collection of all the values in the row axis.
There is an <i> element for each row in the pivot table.
And for each <i> there are as many <x> elements as there are item values in the row.
The v attribute is a zero-based index referencing a <pivotField> item value.
If there is no v then the value is assumed to be 0.
The value of grand for t indicates a grand total as the last row item value.
<rowItems count="5">
<i>
<x/>
</i>
<i>
<x v="1"/>
</i>
<i>
<x v="2"/>
</i>
<i>
<x v="3"/>
</i>
<i t="grand">
<x/>
</i>
</rowItems>
The <colFields> collection follows, indicating which fields are on the column axis of the pivot table.
Here again <x> is an index into the <pivotField> collection.
<colFields count="1">
<field x="-2"/>
</colFields>
The <colItems> collection follows, listing all of the values on the column axis.
<colItems count="2">
<i>
<x/>
</i>
<i i="1">
<x v="1"/>
</i>
</colItems>
There may also be a <pageFields> collection which describes which fields are found in the report filter area.
Finally, there is a <dataFields> collection, which describes what fields are found in the values area of the pivot table.
In our example, there are two fields in the values area – sum of quantity sold and sum of revenue.
Below is the collection.
The fld attribute is the index of the field being summarized.
<dataFields count="2">
<dataField name="Sum of Quantity Sold" fld="1" baseField="0" baseItem="0"/>
<dataField name="Sum of Revenue" fld="3" baseField="0" baseItem="0"/>
</dataFields>
Spreadsheet Styles(也会用到一部分)
Spreadsheets can be styled using styles, themes, and direct formatting.
There are cell styles, table styles, and pivot styles.
However, unlike in WordprocessingML, styling XML never appears with the content in a worksheet.
The formatting is always stored separately within a single styles part for the workbook.
There is also a single theme part for the entire workbook.
A cell style can specify number format, cell alignment, font information, cell borders, and background/foreground fills.
Table styles specify formatting for regions of a table, such as, e.g., headers are bold or a gray fill should be applied to alternating rows.
Pivot table styles specify formatting for regions of a pivot table, such as colors for totals or for the row axis.
Themese define a set of colors, font information, and effects on shapes.
A style or formatting element can define a color, font, or effect by referencing a theme, but of course that format may change if the thme is changed.
Text-Level Formatting
Before getting to the styles applied to a worksheet, however, let’s first cover formatting at the text level, that is, not formatting applied to the entire cell, but formatting that might change from word to word, such as different colors or effects.
For example, see cell A13 below, with blue color for the first word and orange underline for the second.
Obviously this cannot be accomplished with a cell style.
This formatting is done within the shared string part where the text of the cell is stored.

Let’s look at the XML for the first cell in row 13 of the worksheet part.
We know from the type attribute for the cell t="s" that the text is stored in the shared strings part, and from <v="25"/> we know that string is the 26th string or . (Remember that it is a zero-based index.)
<row r="13">
<c r="A13" t="s">
<v>25</v>
</c>
. . .
</row>
The XML for the string is below.
Note that the formatting is applied directly within the string item, just as direct formatting is applied to text runs (<r>) using run properties (<rPr>) within wordprocessingML (docx) documents.
<si>
<r>
<rPr>
<sz val="11"/>
<color theme="4"/>
<rFont val="Calibri"/>
<family val="2"/>
<scheme val="minor"/>
</rPr>
<t>Blue</t>
</r>
<r>
<rPr>
<sz val="11"/>
<color theme="1"/>
<rFont val="Calibri"/>
<family val="2"/>
<scheme val="minor"/>
</rPr>
<t xml:space="preserve"> </t>
</r>
<r>
<rPr>
<u/>
<sz val="11"/>
<color theme="9"/>
<rFont val="Calibri"/>
<family val="2"/>
<scheme val="minor"/>
</rPr>
<t>Widget</t>
</r>
</si>
Cell-Level Formatting
Now let’s return to cell styles.
Styles within spreadsheetML are implemented to minimize repetition, and this is done with collections.
Within the styles part there are the collections shown below.
<stylesheet xmls="http://schemas.openxmlformats.org/spreadsheetml/2006/main">
<numFmts/>
<fonts/>
<fills/>
<borders/>
<cellStyleXfs/>
<cellXfs/>
<cellStyles/>
<dxfs/>
<tableStyles/>
</stylesheet>
Most of the collections above (except for <dxfs> and <tableStyles>) relate to cells.
And the first four–numFmts, fonts, fills, and borders–contain all of the possible charateristics for every cell in the workbook.
Each may have many elements, each one defining the characteristics for a set of cells that have the same such characteristics.
For example, below is a sample of the <fills> for a workbook.
Every cell in the workbook will use one of these fill definitions.
<fills count="5">
<fill>
<patternFill patternType="none"/>
</fill>
<fill>
<patternFill patternType="gray125"/>
</fill>
<fill>
<patternFill patternType="solid">
<fgColor rgb="FFFFEB9C"/>
</patternFill/>
</fill>
<fill>
<patternFill patternType="solid">
<fgColor theme="5" tint="0.39997558519241921"/>
<bgColor indexed="65"/>
</patternFill/>
</fill>
<fill>
<patternFill patternType="solid">
<fgColor rgb="FFC6EFCE"/>
</patternFill/>
</fill>
</fills>
The <fill> for a particular cell is specified with a zero-based index into the above fills collection.
The same is true of the font for the cell, the number format, and the borders.
So the formatting for a cell can be specified with a list or collection of indices into these four collections.
And in fact, that is what the <cellXfs> is.
It contains a collection of groups of indices, one group for every combination of cell formatting characteristics found in the workbook.
Below is one such grouping.
<cellXfs count="14">
<xf numFmtId="0" fontId="0" fillId="0" borderId="0" xfId="0"/>
. . .
</cellXfs>
Every cell will have a reference to one <xf> in the <cellXfs> collection.
This is direct formatting for the cell.
To apply a style to the cell, the <xf> references the style using the xfId attribute.
The xfId attribute is an index into the <cellStyleXFs> collection, which collects the cell styles available to the user.
The <cellStyleXFs> contains one <xf> for each style.
Each such <xf> is tied to its name via an index (in its xfId attribute) from the <cellStyles> collection.
Let’s try and tie it all together by looking at a sample.
Consider row 10 in the sample below.
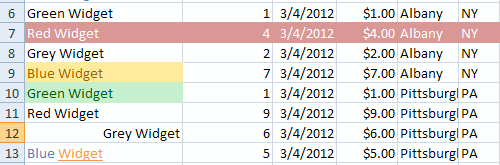
The first cell A10 has a cell style applied.
The XML for the cell in the worksheet is below.
<row r="10">
<c r="A10" s="12" t="s">
<v>6</v>
</c>
. . .
</row>
From the attribute s="12" we know that the cell’s formatting is stored at the 13th (zero-based index) <xf> within the <cellXfs> collection in the styles part.
The 13th <xf> is below.
<xf numFmtId="0" fontId="8" fillId="4" borderId="0" xfId="3"/>
So for this cell, the number format is the first (index value is 0) within the <numFmts> collection.
The cell uses the font format found within the 9th <font> in the <fonts> collection, the 5th <fill> within the <fills> collection (which references a theme for the green), and the first <border> within the <borders> collection.
This cell also applies a style (xfId="3")–the 4th <xf> within the <cellStyleXfs> collection.
The style is shown below.
<xf numFmtId="0" fontId="8" fillId="4" borderId="0" applyNumberFormat="0" applyBorder="0" applyAlignment="0" applyProtection="0"/>
The formatting of the style is same as the direct formatting, and the attributes applyNumberFormat, applyBorder, applyAlignment, and applyProtection, each with values of 0, tell us not to apply the corresponding values of the style but instead apply the values for the direct formatting.
In this case they are the same, so there is no difference anyway.
Table-Level Formatting
A table applies a table style by specifying a <tableStyleInfo> element within the table definition in the tables part.
For example, the following sample table definition specifies the TableStyleMedium9 style.
Note that it is specified by name.
Note also that not only is the style specified, but the specification also tells us which aspects of the style are turned on (e.g., showRowStripes=“1”) and which are turned off (e.g., showLastColumn=“0”).
Each table style is made up of a collection of formatting definitions, each of which corresponds to a particular region of the table–e.g., whole table, first column stripe, first row stripe, first column, header column, first header cell, etc.
Each of these formatting definitions can be turned on or off.
<table xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main" id="1" name="Table1" displayName="Table1" ref="A18:C22" totalRowShown="0">
<autoFilter ref="A18:C22"/>
<tableColumns count="3">
tableColumn id="1" name="Expenses"
tableColumn id="2" name="Amount"
tableColumn id="3" name="Date Paid"
</tableColumns>
<tableStyleInfo name="TableStyleMedium9" showFirstColumn="0" showLastColumn="0" showRowStripes="1" showColumnStripes="0"/>
</table>
Annex G of the ECMA-376, 3rd Edition (June, 2011) OOXML specification defines built-in styles for cells, tables, and pivot tables, and style TableStyleMedium9 is among the built-in table styles.
The built-in table and pivot table styles are not stored in the styles part–only custom styles are.
Below is a custom style defined in the styles part, based on the TableStyleMedium9 style.
<tableStyles count="1" defaultTableStyle="TableStyleMedium9" defaultPivotStyle="PivotStyleLight16">
<tableStyle name="My Custom Table Style" pivot="0" count="3">
<tableStyleElement type="wholeTable" dxfId="2">
<tableStyleElement type="headerRow" dxfId="1">
<tableStyleElement type="firstColumn" dxfId="0">
</tableStyle>
</tableStyles>
The style looks like this:

The style definition above uses differential formatting records (<dxf> elements referenced from the dxfId attribute), which enables subsets of formatting to be specified instead of specifying all formatting.
Looking at the sample above, we see that the default style is the TableStyleMedium9 style.
From that we are altering three aspects – the wholeTable, headerRow, and firstColumn.
Each of these elements references (again using a zero-based index) the <dxfs> collection within the styles part.
For example, the <headerRow> element references the second <dxf> (dxfId=“1”).
It applies bold and a fill background color to the default table style defaultTableStyle="TableStyleMedium9".
<dxfs count="3">
<dxf>
<font>
<b val="0"/>
<i/>
<strike/>
</font>
<fill>
<patternFill>
<bgColor theme="2" tint="-0.2499465926081701"/>
</patternFill>
</fill>
</dxf>
<dxf>
<font>
<b/>
<i val="0"/>
<strike val="0"/>
</font>
<fill>
<patternFill>
<bgColor theme="8" tint="0.59996337778862885"/>
</patternFill>
</fill>
</dxf>
<dxf>
<fill>
<patternFill>
<bgColor theme="5" tint="0.59996337778862885"/>
</patternFill>
</fill>
<border>
<left style="hair">
<color auto="1"/>
</left>
<right style="hair">
<color auto="1"/>
</right>
<top style="hair">
<color auto="1"/>
</top>
<bottom style="hair">
<color auto="1"/>
</bottom>
<vertical style="hair">
<color auto="1"/>
</vertical>
<horizontal style="hair">
<color auto="1"/>
</horizontal>
</border>
</dxf>
</dxfs>
Conditional Formatting
Conditional formatting is a format such as cell shading or font color that a spreadsheet can apply automatically to cells if a specified condition is true.
For example, you can specify that a cell fill color should be red if the value in the cell is above 50.
It can be a very effective tool for visually highlighting important aspects of the data in a worksheet.
Conditional formatting rules are stored in the worksheet part, within a <conditionalFormatting> element after the <sheetData> element.
The range of cells to which the formatting applies is specified with the sqref attribute.
Each condition is within a <cfRule> element.
Multiple rules can be set, each with a different priority.
There are several different types of rules to specify different conditions.
For example, type="cellIs" will determine a cell format based on whether a cell value is greater than or less than a specified value, or between two values.
A type="dataBar" will display a bar of varying length within a cell based on the value in the cell.
Theses types are set with the type attribute on <cfRule>. A type="iconSet" will display an icon in the cell based upon the value in a cell.
Below is a sample table which applies two conditions to the cells B2:B7 - one which applies a pink color fill if the value of the cell is greater than 500 and the other which applies a green fill if the value is less than 300.
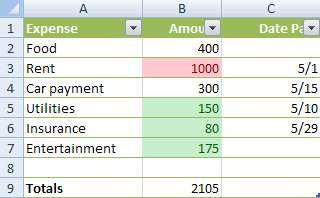
The XML for the conditions is below.
<conditionalFormatting sqref="B2:B7">
<cfRule type="cellIs" dxfId="0" priority="2" operator="greaterThan">
<formula>500</formula>
</cfRule>
<cfRule type="cellIs" dxfId="1" priority="1" operator="lessThan">
<formula>300</formula>
</cfRule>
</conditionalFormatting>
结语
一口气看到这里,说明你对Xlsx的格式已经有了基本的了解,其中,对于POI的eventmodel模式读取大文件Excel来说,最重要的就是The Grid章节。