古语有云
不积跬步,无以至千里。
不积小流,无以成江海。
尽管我们感觉现在的时代生活越来越不容易,尽管世界充满着:“还在相信只要努力就会成功吗?”。
从历史的长河来看,我们如今的时代不过是沧海中的一粟。那些经过上千年沉淀和传承下来的智慧依然是人生中正确的导向。
大家好,我是中国茫茫几百万程序员大军中的一员,也是非计算机专业大专IT培训出生的程序员,在迷惘和失落的时候,心中依然坚信着老祖宗传下来的智慧:
契而舍之,朽木不折。
锲而不舍,金石可镂。
前言
在做一篇文章分析之前,总会做大量的功课。这篇文章也是一样,最开始看到ThreadLocal,我并不明白它的好处在哪里。网上文章一大堆的说着看似正确却又不正确的结论,于是我打算自己来搞明白。
ThreadLocal的作用,在我的理解中它就是一个key。而线程可以是一个存储容器,当我们需要把东西存入一个线程对象里面的时候,就需要用ThreadLocal当成一把key,需要存储的目标值为value。类似HashMap一样,将这对key-value组成的键值对存入线程里。
目前能理解到它的好处在于,线程隔离,重点在于隔离两个字。我们可以通过它将目标数据储存在每一个的线程里面隔离保护,实现线程范围内的方法间的变量传递。
结构
本章将会从设计源头上讲起,为什么要设计,要怎样设计,设计方案有什么好处和坏处。怎样处理设计上带来的坏处。
总体思路为:为什么要做(目的),要怎样去做(实践),怎样做到最好(方法)。
线程中的容器
目前个人理解,如果线程中拥有了自己的容器,那么可以安全的隔离保护数据,多线程环境下,不会被其他线程干扰。
因此,为了使线程拥有一个存储数据的功能,那么不可避免的是线程内部必须要有一个存储容器,不论是List、Map等等。如果选用List,对于不同变量关联不同类型的对象时,显然控制起来是复杂的。而Map通过key-value的特点可以很好的满足这种特性需求。当线程具有了容器功能,那么在线程生命周期内,不论进行到哪个方法,都可以获得这个Map,并取出里面的值。
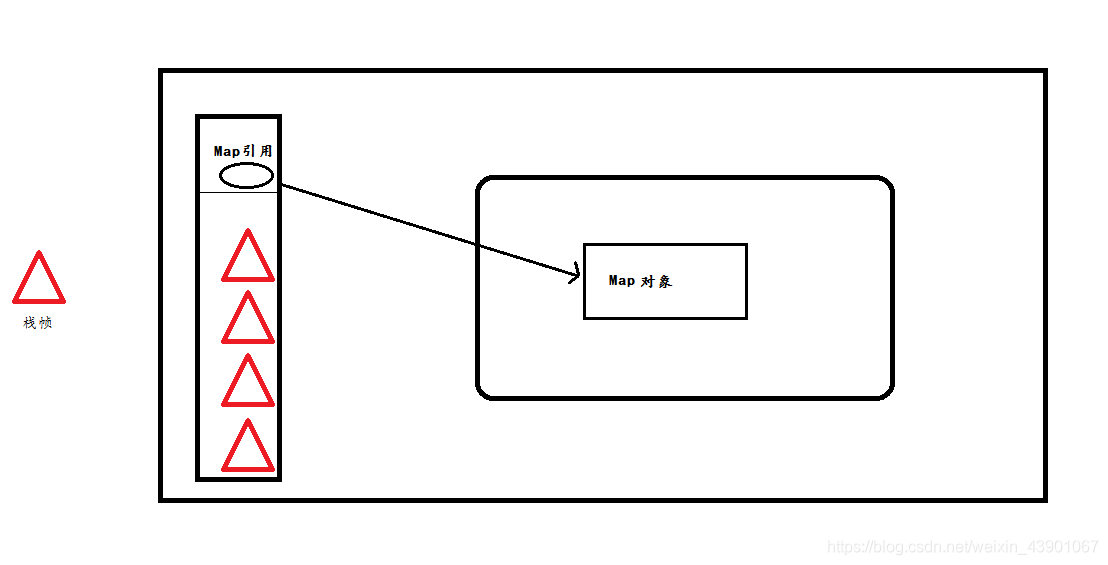
如上图所示,线程每调用一个方法,便会压入一个栈帧,这些栈帧与Map都在同一个栈内,所以不论在线程运行到哪个方法,都可以调用Map对象,它解决了方法间的数据传递,隔离了多线程环境中的并发安全问题。
用过HashMap的人都知道,它是key-value键值对形式组成的。现在线程中有了Map,并且我们要存入一个目标value值,那么key用什么来标记呢?ThreadLocal对象就是解决这个问题,一个ThreadLocal对象 对应一个 value。
那么可以怎么用呢?与传统方法相比有什么好处呢?
用法
如果要解决方法间的变量传递,那么有两种情况:
1. 同一个类中方法间的变量传递
2. 不同类中方法间的变量传递
针对第一个问题,传统方法用成员变量就可以解决了。
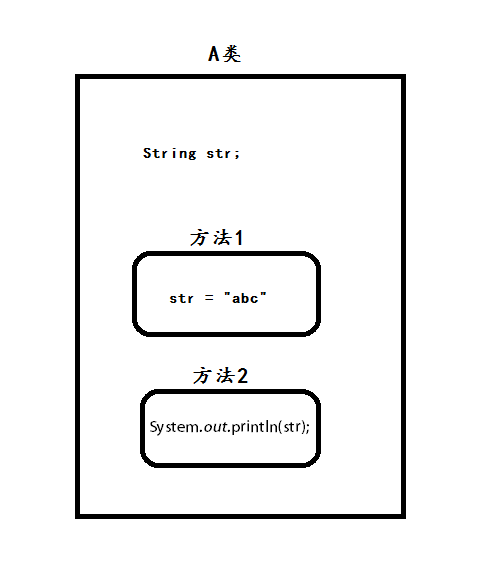
比如上图中要在方法1和方法2中共享一个变量,那么我们定义一个成员变量就可以解决了。在方法1中赋值,方法2中取值。
如果用ThreadLocal可以这样使用。
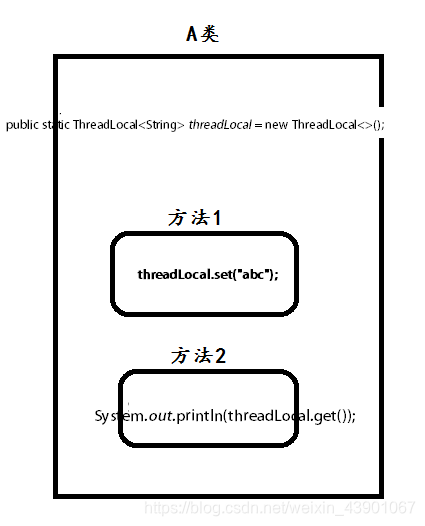
这个也实现了在方法1中赋值,在方法2中取值。
针对第二个问题,如果是在不同类中的方法间数据传递,传统方法需要怎么实现呢?

在已有的调用链中,我们可能需要将参数一层一层的向下传递,直至到达目标方法。 如果你说用static静态变量也可以解决,但是这样无疑会产生多线程安全问题。
如果是用ThreadLocal怎么实现呢?
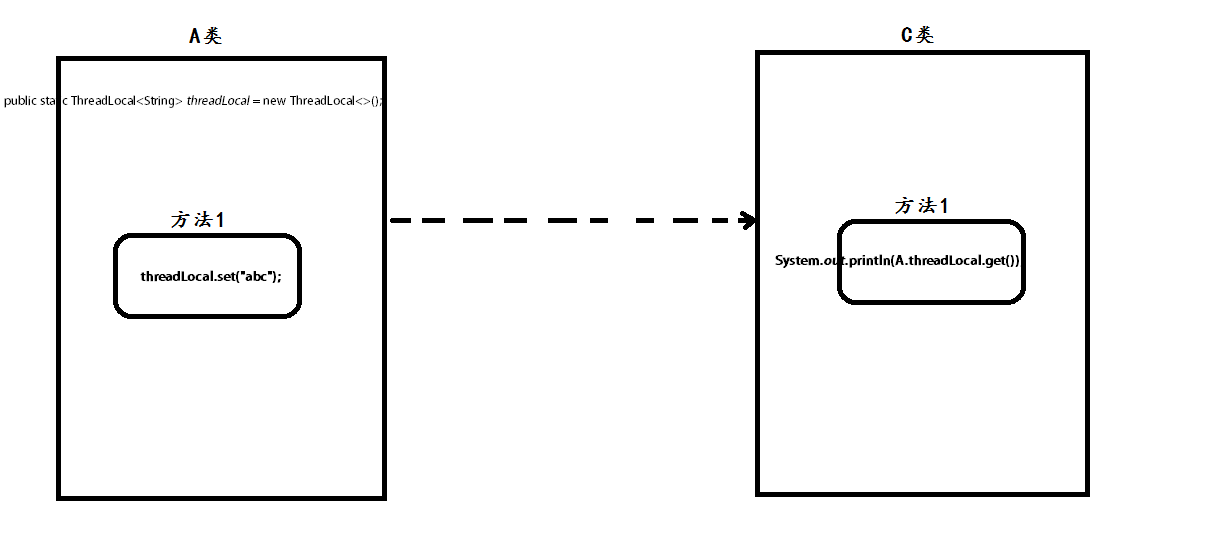
这时只需要获得threadLocal的这个key,就可以在其他地方获取当前线程内用这个key存储的数据。
对于ThreadLocal而言,为什么官方建议用private修饰?
如果用private修饰,那么这个线程生命周期内值传递的作用范围仅限于这个类中了,对于其他类而言,就无法通过通过这个key来获取value了,这样的话与创建一个成员变量还有什么区别呢?我觉得它更大的作用在于不管在哪个类中,只要在线程栈方法调用范围内,都可以获取到才对。
所以我觉得使用private提供了对变量的保护,而获取ThreadLocal对象我们可以编写一个get方法获取,整个线程栈的其他方法都可以通过获取这个ThreadLocal对象,来获得对应的value值。
上面体会到了ThreadLocal的用法和好处,可以在任何地方获取线程内存储的变量值,实现了方法间的变量传递,实现了多线程之间的绝对隔离。
下面来剖析它们的组成成分。这个Map是长成什么样子的?
ThreadLocal.ThreadLocalMap
threadLocalMap 是ThreadLoca类中的一个内部类,是专门为线程设计的一个具有map特点的容器,这个ThreadLoca可以和HashMap进行类比。
- 它们的底层都是通过数组实现的
- 它们都是通过hash算法来定位的
- 它们都有相同的优点和缺陷
在Thread类中持有了成员变量ThreadLocal.ThreadLocalMap,因此让线程实现了容器的功能。
那么该容器的实现细节是怎样的?
一、ThreadLocalMap
这个类是ThreadLocal的内部类,但是ThreadLocal并不持有这个变量。意思就是,生产它却不持有它。
首先来看下ThreadLocalMap的变量组成。
// 它有一个Entry数组
private Entry[] table;
// 数组的初始化容量是16,并且必须是2的幂
private static final int INITIAL_CAPACITY = 16;
// 这个变量计量着实际元素个数
private int size = 0;
// 和HashMap一样的负载因子,默认为0;
private int threshold;
从变量组成来看,它和HashMap的内部组成并无差异,都是维护着一个Entry数组,不过这两个Entry数组并不一样。
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
从Entry的构成中可以看出,它以ThreadLocal对象作为Key,并且实现了一个弱引用。Object就是实际要存储的值。
弱引用与内存泄漏
如果不设计成弱引用,那么每个线程中的ThreadLocalMap的Entry会强引用ThreadLocal对象。

如上图所示,也就意味着这个ThreadLocal对象的生命周期和引用它时间最长的那个线程的生命周期一致了。而常常实际应用中的线程池中,核心线程会和应用的周期一样长,从而导致了线程中的Map对ThreadLocal一直保持引用,ThreadLocal对象无法释放,造成了内存泄漏。
而如果是设计成弱引用,那么线程的生命周期再长也不会一直保持对ThreadLocal对象的引用,ThreadLocal对象会自己随着生命周期阶段该回收时就被回收了。
如果ThreadLocal对象被回收后,那么这些线程对它的引用就会变成了null了,但是ThreadLocal对象作为key对应Value值却还在线程中,如果线程一直存活,那么对于Value值来说,它也是很容易引起内存泄漏的。(想想许多线程都挂载着一个无用的Value都可怕,内存不泄露才怪!)
那怎么办呢?
remove()方法
如果上述问题可能产生内存泄漏,那么这个方法就是为防止内存泄漏而诞生的。看看它做了什么。
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread()); // 获取当前线程中挂载的map
if (m != null)
m.remove(this); // 调用ThreadLocalMap 的remove方法
}
// 下述为m.remove(this)的调用方法
private void remove(ThreadLocal<?> key) {
Entry[] tab = table; // 获取map中哈希桶
int len = tab.length;
int i = key.threadLocalHashCode & (len-1); // 算出当前ThreadLocal对象在这个map中的存放位置
//下方循环中,为了解决哈希冲突,采用的线性查探法。所以定位到的位置上可能不是当前ThreadLocal对象
对应的Entry。 所以加了判断如果该位置上的ThreadLocal对象内存地址和传入的key相等,才能确定位置。
for (Entry e = tab[i];e != null;e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
expungeStaleEntry(i); // 找到之后调用了这个方法
return;
}
}
}
// 继续往下看
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// expunge entry at staleSlot
tab[staleSlot].value = null; // 这里释放了value对象。由于key是弱引用会自动收回,所以无需手动释放。
tab[staleSlot] = null; // 然后释放了entry结点。
size--;
// 按理说可以结束了,但是下面它继续在释放。
// Rehash until we encounter null
Entry e;
int i;
// 这里循环遍历下一个结点,查看它的key是否为null,
for (i = nextIndex(staleSlot, len);(e = tab[i]) != null;i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == null) { // 也就是如果下一个key的ThreadLocal对象已经被回收了,那么它的value也应该被回收
e.value = null;
tab[i] = null;
size--;
} else {
// 如果下一个结点存在,则判断是否需要做位置校正。这是什么意思呢?
int h = k.threadLocalHashCode & (len - 1);
if (h != i) { // 如果这个结点计算出来的原定位为h,现在却是了i这个位置,说明这个结点是因为哈希冲突被顺延过来的。现在你前面的位置空出来了,你该回去了。
tab[i] = null; // 这里就说,这个位置腾出来吧,那腾出来了,这个Entry去哪儿呢 ?
// Unlike Knuth 6.4 Algorithm R, we must scan until
// null because multiple entries could have been stale.
// 于是这个entry又从原始位置h出开始重新定位,如果哈希冲突则顺延,不过它肯定不会再回到原来的位置上了。因为它原来位置前方肯定有空着的位置。
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
可以总结的是,remove方法做了什么事情。
- 释放了当前ThreadLocal对象绑定的value对象,并释放了map中响应的Entry结点。
- 检查这个位置后继结点是否存在其他ThreadLocal为null的现象,如果存在则释放。
- 如果后续位置中,存在因为哈希冲突顺延的结点,则对该结点重新定位。
为什么建议private static
这个缘由来自把ThreadLoad对象用static修饰。官方建议是threadLocal实例应该是private static的,这样可以节约内存消耗,避免重复的ThreadLocal对象生成。如果ThreadLoca对象是一个非静态变量,那么意味着每一个外部对象的产生,就意味着产生一个ThreadLocal。线程对不同外部对象的调用,那么访问到的ThreadLocal也不是同一个,除非外部对象是一个单例。当然这也不会造成什么异常,但是会增加内存的开销。
所以如果我们用static修饰,那么只会产生一个ThreadLocal对象,这也足够用了。
但是这样也有缺点,static变量对ThreadLocal对象保持着强引用,而static 变量从类加载的时候创建完成后会一直存在,这也会导致强引用会一直存在,从而有产生内存泄漏的危险,即使线程的Map中Entry对象对它保持着弱引用。这是什么意思呢?
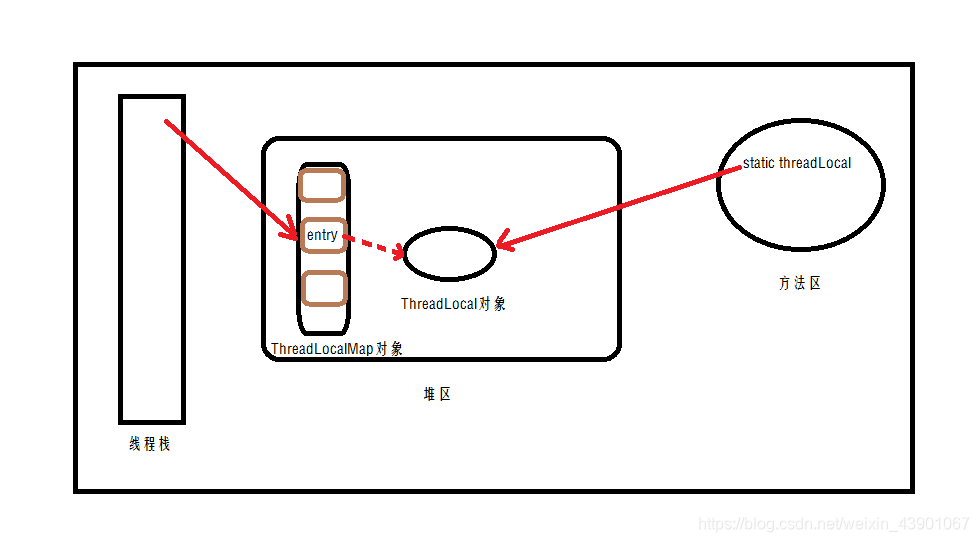
既然使用private static会造成内存泄漏,那为什么官方还要这样建议呢?如果这样做,那官方相近办法的设计弱引用还有什么意义呢?
我的个人想法是,这样做会产生内存泄漏是肯定的,但是只有一个对象的占用,相比产生许多ThreadLocal对象更能够节约内存吧。另外一点就是,在不使用static修饰的情况下,也可以达到相同的效果,比如外部对象是一个单例时,ThreadLocal对象也只有一个。所以设计成弱引用依然有它的作用。
get()方法
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t); // 获取线程内部的map
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this); // 如果不是null则获取结点
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result; //返回value值
}
}
return setInitialValue(); // 否初始化一个新的map,并创建结点,value初始值为null
}
set()方法
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t); // 获取线程内部map
if (map != null)
map.set(this, value); // 在现有map中添加结点
else
createMap(t, value); // 或者初始化一个map
}
ThreadLocalMap特点
(1) 只有数组结构
ThreadMap中维持着一个数组table,意味着它拥有数组结构。结点的定位也是依靠Hash算法定位,与HashMap不同的是,ThreadLocalMap中的Entry结点只有key-value结构,没有前后结点引用,所以它不存在链式结构。那么它是怎么处理Hash冲突的呢?
(2) 开放地址法之线性查探
ThreadLocalMap采用的开放地址法的线性查探,如果通过哈希定位计算出的位置上已经有结点存在了,那么向后顺延就好了,如果后面还有,则再向后延,直到找到为止。
是否存在找完了都没有合适的位置吗?
不会的,因为ThreadLocalMap也有负载因子,默认负载因子为 len * 2/3;
private void setThreshold(int len) {
threshold = len * 2 / 3;
}
扩容以后,原哈希桶中的元素怎么散列?
private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
int newLen = oldLen * 2; // 扩容倍数被2倍
Entry[] newTab = new Entry[newLen];
int count = 0;
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
if (e != null) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null; // Help the GC // 再散列前,先释放无效的结点。
} else {
int h = k.threadLocalHashCode & (newLen - 1); // 用新长度对每个结点重新定位
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
setThreshold(newLen);
size = count;
table = newTab;
}
总结
整个ThreadLocal 大概就是这么些了,有阐述不正确的,请指点一下,有疑惑的地方也可以一起讨论。