
课程很不错,需要的来。
项目来源:
天下之道论到极致,百姓的柴米油盐;人生冷暖论到极致,男人女人的一个情字
短视频情感传话号项目,细分领域的赚钱门道【视频课程】
项目大纲:
1。抖音传话号底层逻辑
2。抖音传话号的具体操作
3。项目分析
4。总结和归纳
纸上得来终觉浅,重要的是给你一个思路,给你一个方向,发现你身上的闪光点,打造属于你自己的管道收入,你能赚到10元,就能赚到100元,把自己丢出去,不断试错,才能快速成长,比如你现在可以立刻创建一个抖音传话的账号,快速执行,想到就立马去做,祝大家2021年,牛年大吉。















一、 Map
1.1 Map 接口
在 Java 中, Map 提供了键——值的映射关系。映射不能包含重复的键,并且每个键只能映射到一个值。
以 Map 键——值映射为基础,java.util 提供了 HashMap(最常用)、 TreeMap、Hashtble、LinkedHashMap 等数据结构。
衍生的几种 Map 的主要特点:
HashMap:最常用的数据结构。键和值之间通过 Hash函数 来实现映射关系。当进行遍历的 key 是无序的
TreeMap:使用红黑树构建的数据结构,因为红黑树的原理,可以很自然的对 key 进行排序,所以 TreeMap 的 key 遍历时是默认按照自然顺序(升序)排列的。
LinkedHashMap: 保存了插入的顺序。遍历得到的记录是按照插入顺序的。
1.2 Hash 散列函数
Hash (散列函数)是把任意长度的输入通过散列算法变换成固定长度的输出。Hash 函数的返回值也称为 哈希值 哈希码 摘要或哈希。Hash作用如下图所示:
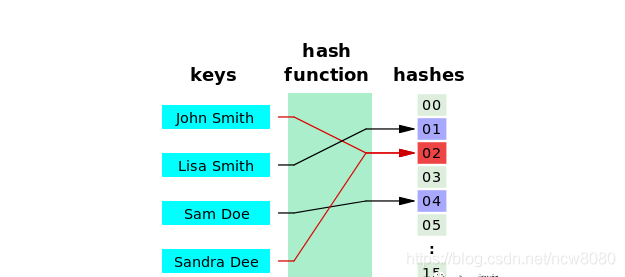
Hash 函数可以通过选取适当的函数,可以在时间和空间上取得较好平衡。
解决 Hash 的两种方式:拉链法和线性探测法
interface Entry<K,V>
在 HashMap 中基于链表的实现
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
用树的方式实现:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
1.4 Map 约定的 API
1.4.1 Map 中约定的基础 API
基础的增删改查:
int size(); // 返回大小
boolean isEmpty(); // 是否为空
boolean containsKey(Object key); // 是否包含某个键
boolean containsValue(Object value); // 是否包含某个值
V get(Object key); // 获取某个键对应的值
V put(K key, V value); // 存入的数据
V remove(Object key); // 移除某个键
void putAll(Map<? extends K, ? extends V> m); //将将另一个集插入该集合中
void clear(); // 清除
Set<K> keySet(); //获取 Map的所有的键返回为 Set集合
Collection<V> values(); //将所有的值返回为 Collection 集合
Set<Map.Entry<K, V>> entrySet(); // 将键值对映射为 Map.Entry,内部类 Entry 实现了映射关系的实现。并且返回所有键值映射为 Set 集合。
boolean equals(Object o);
int hashCode(); // 返回 Hash 值
default boolean replace(K key, V oldValue, V newValue); // 替代操作
default V replace(K key, V value);
1.4.2 Map 约定的较为高级的 API
default V getOrDefault(Object key, V defaultValue); //当获取失败时,用 defaultValue 替代。
default void forEach(BiConsumer<? super K, ? super V> action) // 可用 lambda 表达式进行更快捷的遍历
default void replaceAll(BiFunction<? super K, ? super V, ? extends V> function);
default V putIfAbsent(K key, V value);
default V computeIfAbsent(K key,
Function<? super K, ? extends V> mappingFunction);
default V computeIfPresent(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction);
default V compute(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction)
default V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction)
1.4.3 Map 高级 API 的使用
getOrDefault() 当这个通过 key获取值,对应的 key 或者值不存在时返回默认值,避免在使用过程中 null 出现,避免程序异常。
ForEach() 传入 BiConsumer 函数式接口,表达的含义其实和 Consumer 一样,都 accept 拥有方法,只是 BiConsumer 多了一个 andThen() 方法,接收一个BiConsumer接口,先执行本接口的,再执行传入的参数的 accept 方法。
Map<String, String> map = new HashMap<>();
map.put("a", "1");
map.put("b", "2");
map.put("c", "3");
map.put("d", "4");
map.forEach((k, v) -> {
System.out.println(k+"-"+v);
});
}
1.5 从 Map 走向 HashMap
HashMap 是 Map的一个实现类,也是 Map 最常用的实现类。
1.5.1 HashMap 的继承关系
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
在 HashMap 的实现过程中,解决 Hash冲突的方法是拉链法。因此从原理来说 HashMap 的实现就是 数组 + 链表(数组保存链表的入口)。当链表过长,为了优化查询速率,HashMap 将链表转化为红黑树(数组保存树的根节点),使得查询速率为 log(n),而不是链表的 O(n)。
二、HashMap
首先 HashMap 由 Doug Lea 和 Josh Bloch 两位大师的参与。同时 Java 的 Collections 集合体系,并发框架 Doug Lea 也做出了不少贡献。
2.1 基本原理
对于一个插入操作,首先将键通过 Hash 函数转化为数组的下标。若该数组为空,直接创建节点放入数组中。若该数组下标存在节点,即 Hash 冲突,使用拉链法,生成一个链表插入。

如果存在 Hash 冲突,使用拉链法插入,我们可以在这个链表的头部插入,也可以在链表的尾部插入,所以在 JDK 1.7 中使用了头部插入的方法,JDK 1.8 后续的版本中使用尾插法。
JDK 1.7 使用头部插入的可能依据是最近插入的数据是最常用的,但是头插法带来的问题之一,在多线程会链表的复制会出现死循环。所以 JDK 1.8 之后采用的尾部插入的方法。
在 HashMap 中,前面说到的 数组+链表 的数组的定义

transient Node<K,V>[] table;
static class Node<K,V> implements Map.Entry<K,V>
public HashMap() {
// 空参
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public HashMap(int initialCapacity) {
//带有初始大小的,一般情况下,我们需要规划好 HashMap 使用的大小,因为对于一次扩容操作,代价是非常的大的
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor); // 可以自定义负载因子 public HashMap(int initialCapacity, float loadFactor); // 可以自定义负载因子
三个构造函数,都没有完全的初始化 HashMap,当我们第一次插入数据时,才进行堆内存的分配,这样提高了代码的响应速度。
2.2 HashMap 中的 Hash函数定义
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); // 将 h 高 16 位和低 16 位 进行异或操作。
}
// 采用 异或的原因:两个进行位运算,在与或异或中只有异或到的 0 和 1 的概率是相同的,而&和|都会使得结果偏向0或者1。
这里可以看到,Map 的键可以为 null,且 hash 是一个特定的值 0。
Hash 的目的是获取数组 table 的下标。Hash 函数的目标就是将数据均匀的分布在 table 中。
让我们先看看如何通过 hash 值得到对应的数组下标。第一种方法:hash%table.length()。但是除法操作在 CPU 中执行比加法、减法、乘法慢的多,效率低下。第二种方法 table[(table.length - 1) & hash] 一个与操作一个减法,仍然比除法快。这里的约束条件为 table.length = 2^N。
table.length =16
table.length -1 = 15 1111 1111
//任何一个数与之与操作,获取到这个数的低 8 位,其他位为 0
上面的例子可以让我们获取到对应的下标,而 (h = key.hashCode()) ^ (h >>> 16) 让高 16 也参与运算,让数据充分利用,一般情况下 table 的索引不会超过 216,所以高位的信息我们就直接抛弃了,^ (h >>> 16) 让我们在数据量较少的情况下,也可以使用高位的信息。如果 table 的索引超过 216, hashCode() 的高 16 为 和 16 个 0 做异或得到的 Hash 也是公平的。
2.3 HashMap 的插入操作
上面我们已经知道如果通过 Hash 获取到 对应的 table 下标,因此我们将对应的节点加入到链表就完成了一个 Map 的映射,的确 JDK1.7 中的 HashMap 实现就是这样。让我们看一看 JDK 为实现现实的 put 操作。
定位到 put() 操作。