0x00 前言
终于!终于!终于!时隔多年后,终于要认真学一次了!
先放正则相关的图,留存查询

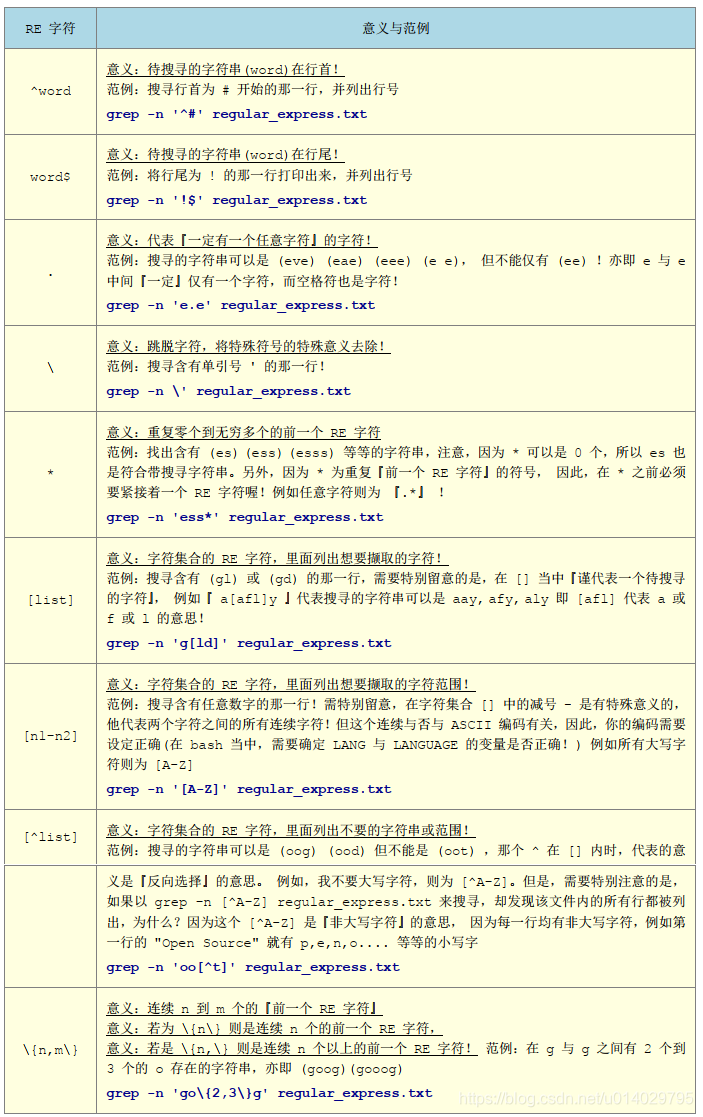


另外一定要注意:语系编码对正则同样是有影响的!
三剑客的功能非常强大,但我们只需要掌握他们分别擅长的领域即可
grep擅长查找功能sed擅长取行和替换awk擅长取列
0x01 grep
grep是日常用的最多的也是最熟悉的了
[root@localhost ~]grep --help
Usage: grep [OPTION]... PATTERN [FILE]...
Search for PATTERN in each FILE or standard input.
PATTERN is, by default, a basic regular expression (BRE).
Example: grep -i 'hello world' menu.h main.c
Regexp selection and interpretation:
-E, --extended-regexp PATTERN is an extended regular expression (ERE)
-F, --fixed-strings PATTERN is a set of newline-separated fixed strings
-G, --basic-regexp PATTERN is a basic regular expression (BRE)
-P, --perl-regexp PATTERN is a Perl regular expression
-e, --regexp=PATTERN use PATTERN for matching
-f, --file=FILE obtain PATTERN from FILE
-i, --ignore-case ignore case distinctions
-w, --word-regexp force PATTERN to match only whole words
-x, --line-regexp force PATTERN to match only whole lines
-z, --null-data a data line ends in 0 byte, not newline
Miscellaneous:
-s, --no-messages suppress error messages
-v, --invert-match select non-matching lines
-V, --version display version information and exit
--help display this help text and exit
Output control:
-m, --max-count=NUM stop after NUM matches
-b, --byte-offset print the byte offset with output lines
-n, --line-number print line number with output lines
--line-buffered flush output on every line
-H, --with-filename print the file name for each match
-h, --no-filename suppress the file name prefix on output
--label=LABEL use LABEL as the standard input file name prefix
-o, --only-matching show only the part of a line matching PATTERN
-q, --quiet, --silent suppress all normal output
--binary-files=TYPE assume that binary files are TYPE;
TYPE is 'binary', 'text', or 'without-match'
-a, --text equivalent to --binary-files=text
-I equivalent to --binary-files=without-match
-d, --directories=ACTION how to handle directories;
ACTION is 'read', 'recurse', or 'skip'
-D, --devices=ACTION how to handle devices, FIFOs and sockets;
ACTION is 'read' or 'skip'
-r, --recursive like --directories=recurse
-R, --dereference-recursive
likewise, but follow all symlinks
--include=FILE_PATTERN
search only files that match FILE_PATTERN
--exclude=FILE_PATTERN
skip files and directories matching FILE_PATTERN
--exclude-from=FILE skip files matching any file pattern from FILE
--exclude-dir=PATTERN directories that match PATTERN will be skipped.
-L, --files-without-match print only names of FILEs containing no match
-l, --files-with-matches print only names of FILEs containing matches
-c, --count print only a count of matching lines per FILE
-T, --initial-tab make tabs line up (if needed)
-Z, --null print 0 byte after FILE name
Context control:
-B, --before-context=NUM print NUM lines of leading context
-A, --after-context=NUM print NUM lines of trailing context
-C, --context=NUM print NUM lines of output context
-NUM same as --context=NUM
--group-separator=SEP use SEP as a group separator
--no-group-separator use empty string as a group separator
--color[=WHEN],
--colour[=WHEN] use markers to highlight the matching strings;
WHEN is 'always', 'never', or 'auto'
-U, --binary do not strip CR characters at EOL (MSDOS/Windows)
-u, --unix-byte-offsets report offsets as if CRs were not there
(MSDOS/Windows)
'egrep' means 'grep -E'. 'fgrep' means 'grep -F'.
Direct invocation as either 'egrep' or 'fgrep' is deprecated.
When FILE is -, read standard input. With no FILE, read . if a command-line
-r is given, - otherwise. If fewer than two FILEs are given, assume -h.
Exit status is 0 if any line is selected, 1 otherwise;
if any error occurs and -q is not given, the exit status is 2.
Report bugs to: [email protected]
GNU Grep home page: <http://www.gnu.org/software/grep/>
General help using GNU software: <http://www.gnu.org/gethelp/>
[root@localhost ~]
grep的用法
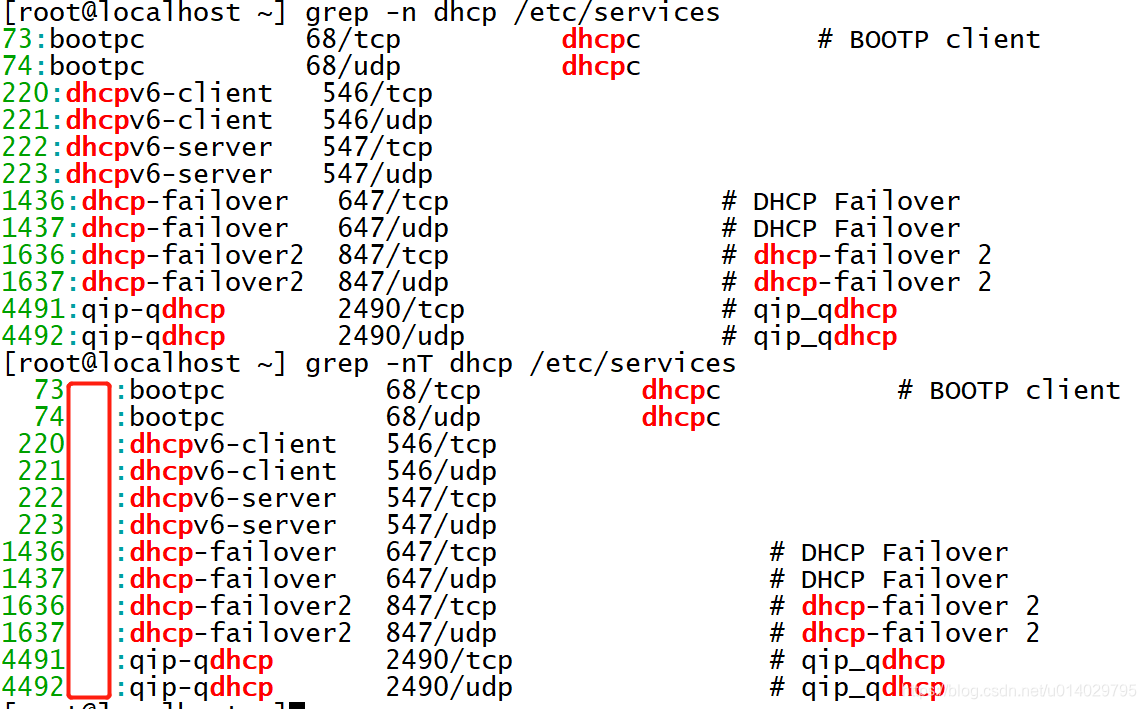
命令还是非常多的,把重要的一个一个来试试,不加任何选项,DHCP关键词,/etc/services文本文件

不区分大小写查找,使用-i
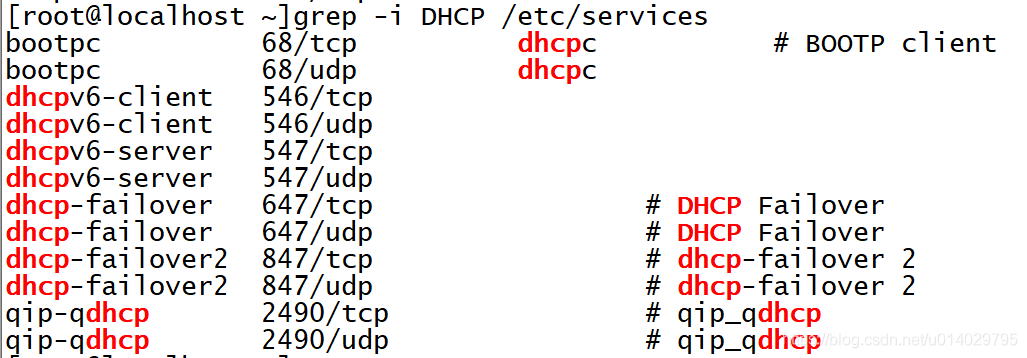
一定要匹配上整个单词的查找,包含或者前后有其余单词字符的均不匹配,使用-w

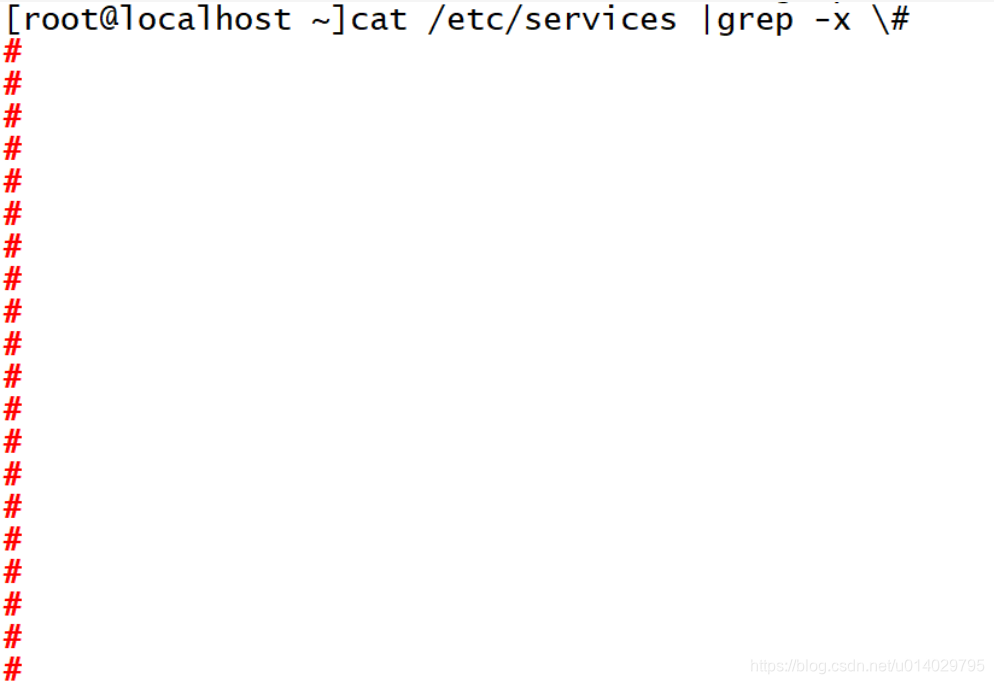
匹配注释的空行,这里由于#是特殊符号,需要转义,使用-x,匹配整行数据
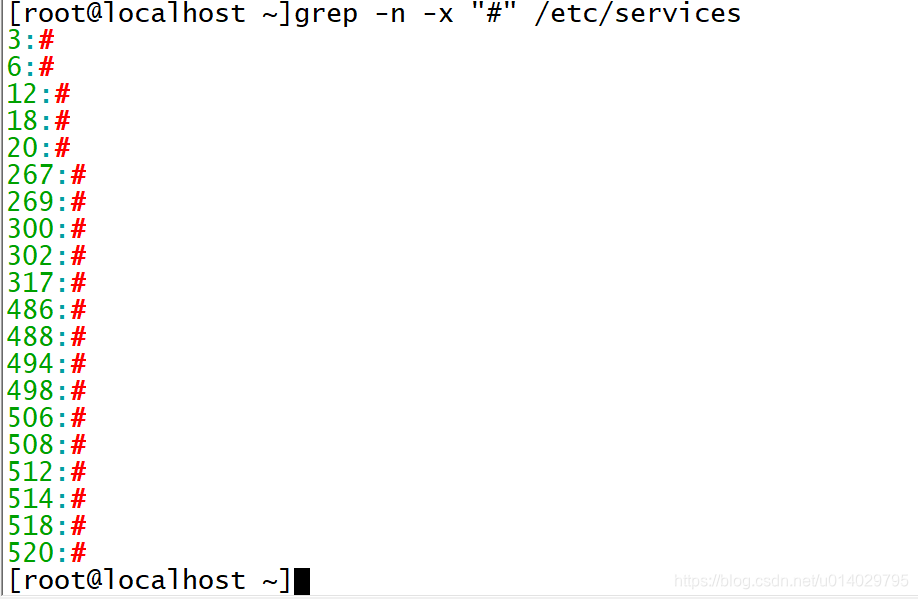
匹配注释的空行,并显示这些注释行的行号,使用-n
统计匹配注释的空行的数量,使用-c
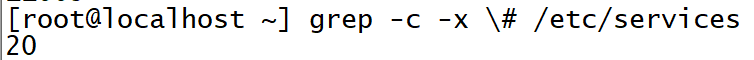
匹配以#开头的行数,使用-e参数,但是只能接受一个参数的正则
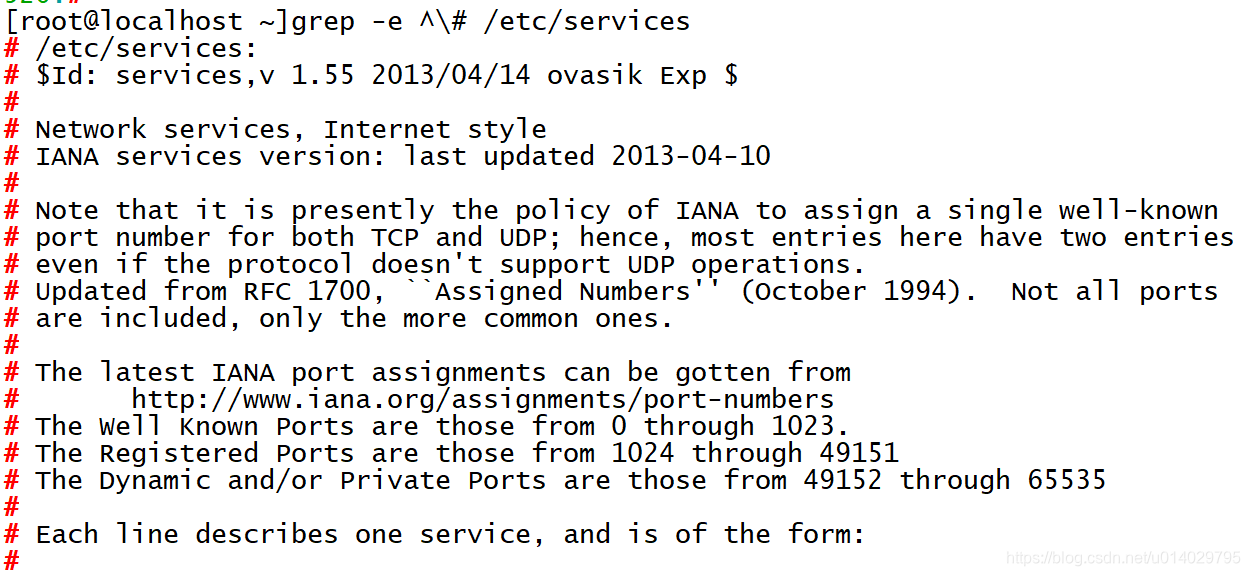
匹配ARP或者DHCP关键字的行数,使用-E使用扩展正则,可以使用多个参数进行正则匹配

输出没有#号的行,使用-v
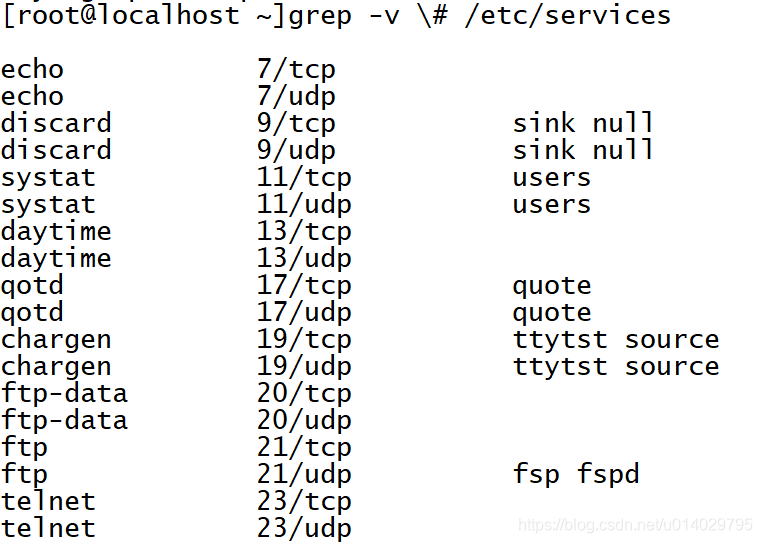
匹配前10个#开头的行数,使用-m

显示DHCP所在的字符数

这里将/etc/services分成两部分,每部分6000行
[root@localhost ~]split -l 6000 /etc/services services-
[root@localhost ~]ll services-a*
-rw-r--r-- 1 root root 343604 Feb 11 15:06 services-aa
-rw-r--r-- 1 root root 326689 Feb 11 15:06 services-ab
匹配这两个文件中的FTP行,带-H显示文件名
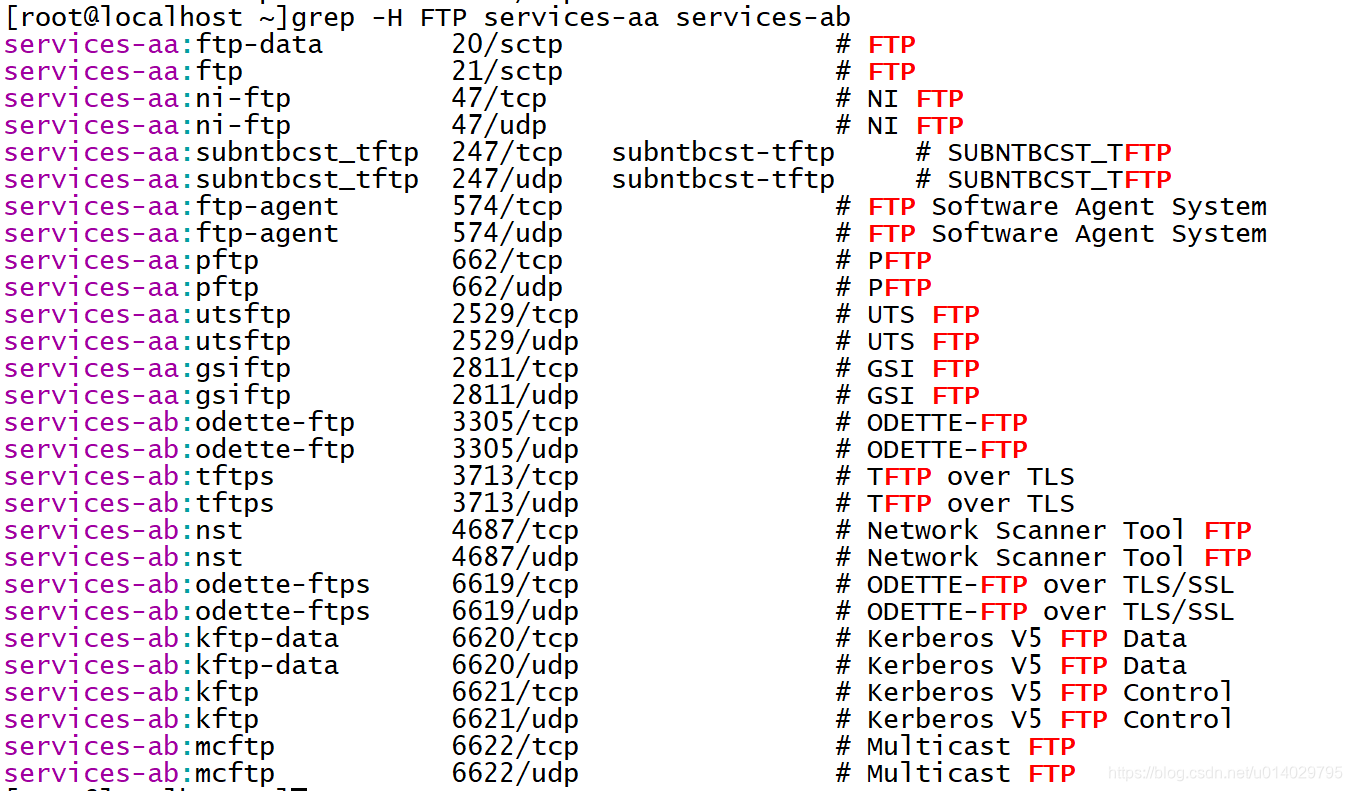
匹配这两个文件中的FTP行,带-h不显示文件名

只匹配关键字及其出现的行数,使用-o

使用-q,查找后无任何输出,一般用于shell内进行流程控制
[root@localhost ~]echo "if grep -q DHCP /etc/services; then echo 1; else echo 2;fi" > 1.sh && chmod 777 1.sh
[root@localhost ~]./1.sh
1
[root@localhost ~]echo "if grep -q aaaaaaaa /etc/services; then echo 1; else echo 2;fi" > 1.sh && chmod 777 1.sh
[root@localhost ~]./1.sh
2
对二进制文件进行处理时的操作
#二进制文件出错
[root@localhost ~] grep abc /bin/ls
Binary file /bin/ls matches
#忽略二进制文件
[root@localhost ~] grep -I abc /bin/ls
#以文本模式读取二进制文件
[root@localhost ~] grep -a abc /bin/ls
ignoring invalid value of environment variable QUOTING_STYLE: %signoring invalid width in environment variable COLUMNS: %signoring invalid tab size in environment variable TABSIZE: %sabcdfghiklmnopqrstuvw:xABCDFGHI:LNQRST:UXZ1 - +FORMAT (e.g., +%H:%M) for a 'date'-style format
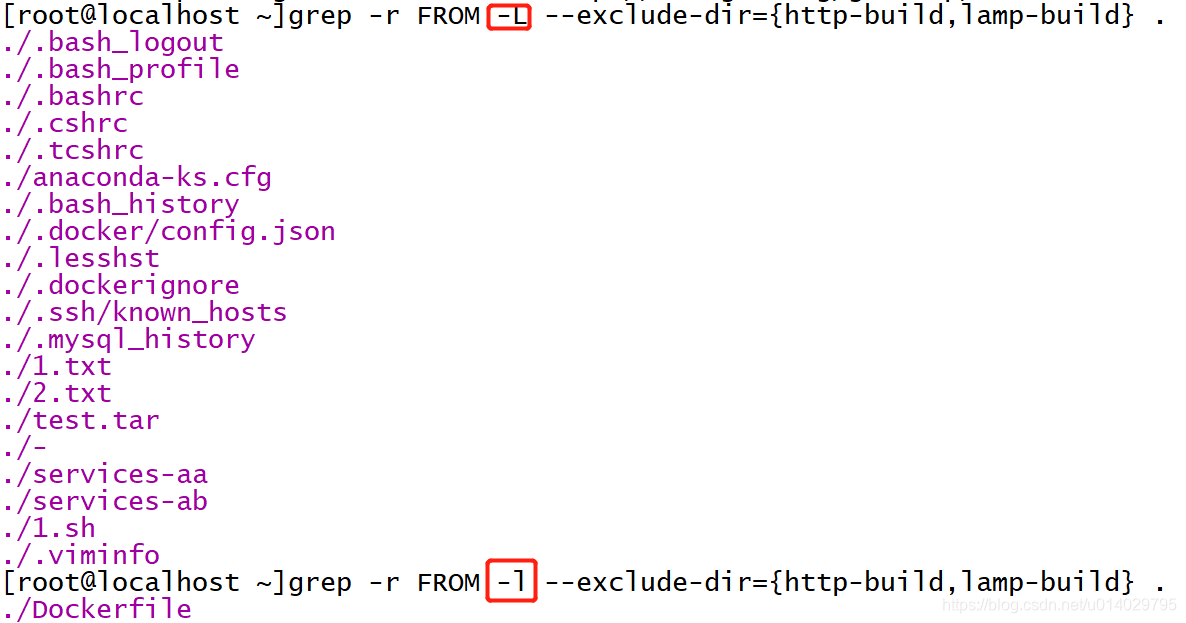
在目录所有的文件下查找DHCP,使用-r,跳过符号链接,如果使用-R则不跳过。

在除了http-build和lamp-build目录外查找FROM关键字,使用--exclude-dir

只显示匹配上的文件名,使用-l,显示没有匹配上的文件名使用-L
在使用-n,-H等参数时,可以使开头加上tab,然并卵
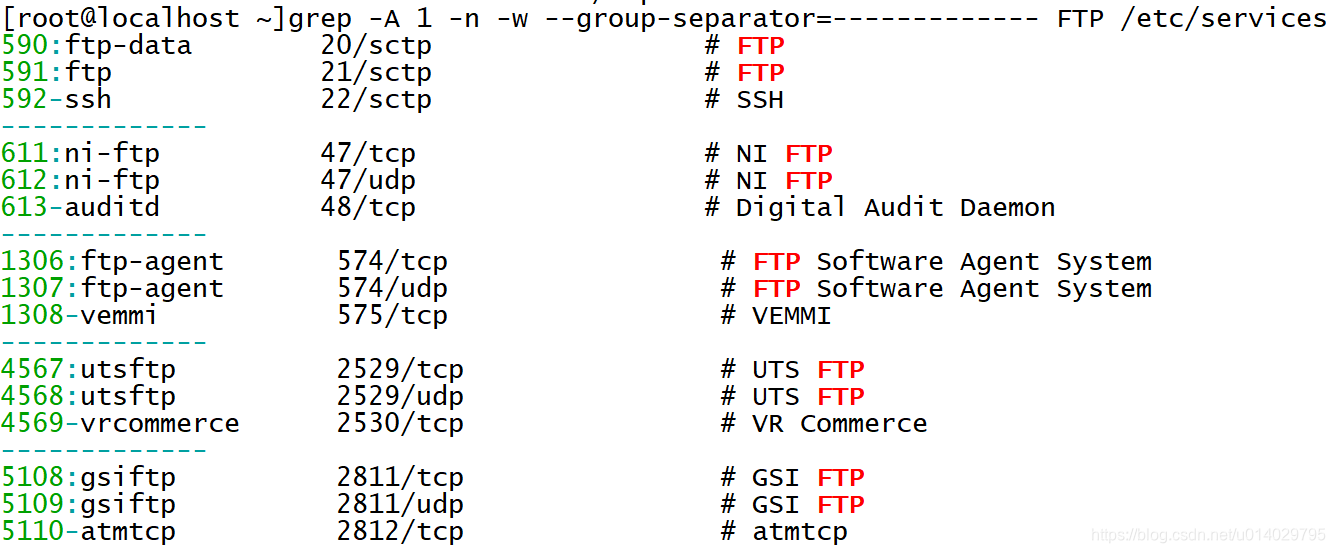
-A是显示匹配后和它后面的n行

-B是显示匹配行和它前面的n行

-C是匹配行和它前后各n行

在使用了-A -B -C的查寻结果后增加分隔符,使用--group-separator
还有一些感觉不太常用的方法,比如-z、-Z,-u、-U等都找不到合适的例子来演示,但是我感觉到这grep已经够用了!
0x02 sed
命令没有grep多,但是用于替换和进行行数的操作很方便
[root@localhost ~]sed --help
Usage: sed [OPTION]... {
script-only-if-no-other-script} [input-file]...
-n, --quiet, --silent
suppress automatic printing of pattern space
-e script, --expression=script
add the script to the commands to be executed
-f script-file, --file=script-file
add the contents of script-file to the commands to be executed
--follow-symlinks
follow symlinks when processing in place
-i[SUFFIX], --in-place[=SUFFIX]
edit files in place (makes backup if SUFFIX supplied)
-c, --copy
use copy instead of rename when shuffling files in -i mode
-b, --binary
does nothing; for compatibility with WIN32/CYGWIN/MSDOS/EMX (
open files in binary mode (CR+LFs are not treated specially))
-l N, --line-length=N
specify the desired line-wrap length for the `l' command
--posix
disable all GNU extensions.
-r, --regexp-extended
use extended regular expressions in the script.
-s, --separate
consider files as separate rather than as a single continuous
long stream.
-u, --unbuffered
load minimal amounts of data from the input files and flush
the output buffers more often
-z, --null-data
separate lines by NUL characters
--help
display this help and exit
--version
output version information and exit
除此之外在man grep中还可以找到一些常见的方法,详细用法看示例
a,在下面增加i,在上面增加d,删除c,整行修改s,部分修改p,打印y,单字替换w,将内容写入新文件r,将新文件插入原文件q,匹配退出
sed的用法
先用最常见的-e,拷贝/etc/passwd的前五行到本目录下形成文件passwd
在第二行下面增加数据
[root@localhost ~]cat passwd | sed -e '2a test!'
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
test!
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
在第二行上面增加数据
[root@localhost ~]cat passwd | sed -e '2i test!'
root:x:0:0:root:/root:/bin/bash
test!
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
在第二行下面增加两行数据
[root@localhost ~]cat passwd | sed -e '2a test test \
> haha haha'
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
test test
haha haha
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
将第二行换成*****
[root@localhost ~]cat passwd |sed -e '2c *********'
root:x:0:0:root:/root:/bin/bash
*********
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
删除第三行到最后一行
[root@localhost ~]cat passwd |sed -e '3,$d'
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
将所有的o换成大写的O
[root@localhost ~]cat passwd |sed -e 's/o/O/g'
rOOt:x:0:0:rOOt:/rOOt:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nOlOgin
daemOn:x:2:2:daemOn:/sbin:/sbin/nOlOgin
adm:x:3:4:adm:/var/adm:/sbin/nOlOgin
lp:x:4:7:lp:/var/spOOl/lpd:/sbin/nOlOgin
将第二行的o换成大写的O
[root@localhost ~]cat passwd |sed -e '2s/o/O/g'
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nOlOgin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
将第三行到第四行第一个的o换成大写的O
[root@localhost ~]cat passwd |sed -e 's/o/O/'
rOot:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nOlogin
daemOn:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nOlogin
lp:x:4:7:lp:/var/spOol/lpd:/sbin/nologin
将所有的数字都换成*,要注意,前后字符数量一致
[root@localhost ~]cat passwd |sed -e 'y/0123456789/**********/'
root:x:*:*:root:/root:/bin/bash
BIN:x:*:*:BIN:/BIN:/sBIN/nologin
daemon:x:*:*:daemon:/sbin:/sbin/nologin
adm:x:*:*:adm:/var/adm:/sbin/nologin
lp:x:*:*:lp:/var/spool/lpd:/sbin/nologin
在第二行插入分隔符文件
[root@localhost ~]cat a.txt
**********
[root@localhost ~]cat passwd |sed -e "2r a.txt"
root:x:0:0:root:/root:/bin/bash
BIN:x:1:1:BIN:/BIN:/sBIN/nologin
**********
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
查寻到关键字就退出
[root@localhost ~]cat passwd |sed -e '/nologin/q'
root:x:0:0:root:/root:/bin/bash
BIN:x:1:1:BIN:/BIN:/sBIN/nologin
-n选项为安静模式,一般和p方法一起用,打印出2-3行
[root@localhost ~]cat passwd |sed -n '2,3p'
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
将2-3行数据写入新文件,配合-n选项效果更好
[root@localhost ~]cat passwd |sed -n '2,3w test.txt'
[root@localhost ~]cat test.txt
BIN:x:1:1:BIN:/BIN:/sBIN/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
比如可以利用正则来获取IP地址
[root@localhost ~]ifconfig ens32|sed -n '2p'|sed -e 's/ *inet //'|sed -e 's/ *netmask.*//'
10.1.1.222
如果用的-i选项,则是不输出结果,直接修改原文件,使用的时候一定要注意
[root@localhost ~]cat passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
[root@localhost ~]sed -i '2s/bin/BIN/g' passwd ;cat passwd
root:x:0:0:root:/root:/bin/bash
BIN:x:1:1:BIN:/BIN:/sBIN/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sed命令的寻址
前面在介绍各个脚本命令时,我们一直忽略了对 address部分的介绍。对各个脚本命令来说,address用来表明该脚本命令作用到文本中的具体行,通过之前的显示应该有一定感觉了,再来总结下。
默认情况下,sed 命令会作用于文本数据的所有行。如果只想将命令作用于特定行或某些行,则必须写明 address 部分,表示的方法有以下 2 种:
- 以数字形式指定行区间;
- 用文本模式指定具体行区间。
以上两种形式都可以使用如下这 2 种格式,分别是:
[address]脚本命令
或者
address {
多个脚本命令
}
以数字形式指定行区间
```bash
[root@localhost ~]cat passwd |sed -n '2,3p'
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
以文本指定区间
[root@localhost ~]cat passwd |sed -n '/root/p'
root:x:0:0:root:/root:/bin/bash
使用多脚本命令把所有的uid前后都加上",gid前后加上',这里使用-f选项,调用脚本文件更方便
[root@localhost ~]cat sed.sh
/[0-9]/{
s//\"&\"/1
s//\'&\'/2
}
[root@localhost ~]cat passwd |sed -f sed.sh
root:x:"0":'0':root:/root:/bin/bash
BIN:x:"1":'1':BIN:/BIN:/sBIN/nologin
daemon:x:"2":'2':daemon:/sbin:/sbin/nologin
adm:x:"3":'4':adm:/var/adm:/sbin/nologin
lp:x:"4":'7':lp:/var/spool/lpd:/sbin/nologin
sed的多行处理
N命令会将下一行文本内容添加到缓冲区已有数据之后(之间用换行符分隔),从而使前后两个文本行同时位于缓冲区中,sed 命令会将这两行数据当成一行来处理。
[root@localhost ~] cat data2.txt
This is the header line.
This is the first data line.
This is the second data line.
This is the last line.
[root@localhost ~] sed '/first/{ N ; s/\n/ / }' data2.txt
This is the header line.
This is the first data line. This is the second data line.
This is the last line.
D 命令将缓冲区中第一个换行符(包括换行符)之前的内容删除掉。
[root@localhost ~]head -n 10 /etc/services | sed -e 's/\#//g' > services
[root@localhost ~]cat services
/etc/services:
$Id: services,v 1.55 2013/04/14 ovasik Exp $
Network services, Internet style
IANA services version: last updated 2013-04-10
Note that it is presently the policy of IANA to assign a single well-known
port number for both TCP and UDP; hence, most entries here have two entries
even if the protocol doesn't support UDP operations.
Updated from RFC 1700, ``Assigned Numbers'' (October 1994). Not all ports
删除匹配的第一个空白行,先匹配空行,然后使用N指定将下一行也加入缓冲区,然后利用下一行的Net关键字进行匹配删除匹配上的第一个换行符及之前的内容。
[root@localhost ~]cat services | sed -e '/^$/{N;/Net/D}'
/etc/services:
$Id: services,v 1.55 2013/04/14 ovasik Exp $
Network services, Internet style
IANA services version: last updated 2013-04-10
Note that it is presently the policy of IANA to assign a single well-known
port number for both TCP and UDP; hence, most entries here have two entries
even if the protocol doesn't support UDP operations.
Updated from RFC 1700, ``Assigned Numbers'' (October 1994). Not all ports
P命令打印多行数据,还是利用上面的例子,p会输出匹配上的内容,而P只输出匹配上内容当中的第一个换行符及之前的内容
[root@localhost ~]cat services | sed -n '/^$/{N;/Net/p}'
Network services, Internet style
[root@localhost ~]cat services | sed -n '/^$/{N;/Net/P}'
[root@localhost ~]
sed保持空间
相关的命令有5条
h将模式空间中的内容复制到保持空间H将模式空间中的内容附加到保持空间g将保持空间中的内容复制到模式空间G将保持空间中的内容附加到模式空间x交换模式空间和保持空间中的内容
通常,在使用 h 或 H 命令将字符串移动到保持空间后,最终还要用 g、G 或 x 命令将保存的字符串移回模式空间。保持空间最直接的作用是,一旦我们将模式空间中所有的文件复制到保持空间中,就可以清空模式空间来加载其他要处理的文本内容。
由于有两个缓冲区域,下面的例子中演示了如何用 h 和 g 命令来将数据在 sed 缓冲区之间移动。
[root@localhost ~]# cat data2.txt
This is the header line.
This is the first data line.
This is the second data line.
This is the last line.
[root@localhost ~]# sed -n '/first/ {h ; p ; n ; p ; g ; p }' data2.txt
This is the first data line.
This is the second data line.
This is the first data line.
这个例子的运行过程是这样的:
- sed脚本命令用正则表达式过滤出含有单词first的行;
- 当含有单词 first 的行出现时,h 命令将该行放到保持空间;
- p 命令打印模式空间也就是第一个数据行的内容;
- n 命令提取数据流中的下一行(This is the second data line),并将它放到模式空间;
- p 命令打印模式空间的内容,现在是第二个数据行;
- g 命令将保持空间的内容(This is the first data line)放回模式空间,替换当前文本;
- p 命令打印模式空间的当前内容,现在变回第一个数据行了。
讲道理,还没完全理解这个可以怎么high,留待将来
sed分支
通常,sed程序的执行过程会从第一个脚本命令开始,一直执行到最后一个脚本命令,sed 提供了 b 分支命令来改变命令脚本的执行流程,其结果与结构化编程类似。
b分支命令基本格式为:
[address]b [label]
其中,address 参数决定了哪些行的数据会触发分支命令,label 参数定义了要跳转到的位置。
#原文件
[root@localhost ~]cat services
/etc/services:
$Id: services,v 1.55 2013/04/14 ovasik Exp $
Network services, Internet style
IANA services version: last updated 2013-04-10
Note that it is presently the policy of IANA to assign a single well-known
port number for both TCP and UDP; hence, most entries here have two entries
even if the protocol doesnt support UDP operations.
Updated from RFC 1700, ''Assigned Numbers'' (October 1994). Not all ports
#将原文件中的services改为Services,但是当遇到Network时,就改为SERvices
[root@localhost ~]cat services | sed -e '{/Net/b jump;s/ser/Ser/g
> :jump
> s/ser/SER/g}'
/etc/Services:
$Id: Services,v 1.55 2013/04/14 ovasik Exp $
Network SERvices, Internet style
IANA Services version: last updated 2013-04-10
Note that it is presently the policy of IANA to assign a single well-known
port number for both TCP and UDP; hence, most entries here have two entries
even if the protocol doesnt support UDP operations.
Updated from RFC 1700, ''Assigned Numbers'' (October 1994). Not all ports
#如果上述看起来吃力就写成脚本
[root@localhost ~]cat services | sed -f sed.sh
/etc/Services:
$Id: Services,v 1.55 2013/04/14 ovasik Exp $
Network SERvices, Internet style
IANA Services version: last updated 2013-04-10
Note that it is presently the policy of IANA to assign a single well-known
port number for both TCP and UDP; hence, most entries here have two entries
even if the protocol doesn't support UDP operations.
Updated from RFC 1700, ``Assigned Numbers'' (October 1994). Not all ports
[root@localhost ~]cat sed.sh
{
/Net/b jump;s/ser/Ser/g
:jump
s/ser/SER/g
}
其实就像编程中的判断语句,当匹配上了条件,就跳过前面的语句,执行后面的语句。
当然除了向后跳,还可以像前跳,用于循环处理,比如替换所有的符号为*。
[root@localhost ~]cat services | sed -e '{/[[:punct:]]/b start;
>:start
>s/[[:punct:]]/\*/g}'
*etc*services*
*Id* services*v 1*55 2013*04*14 ovasik Exp *
Network services* Internet style
IANA services version* last updated 2013*04*10
Note that it is presently the policy of IANA to assign a single well*known
port number for both TCP and UDP* hence* most entries here have two entries
even if the protocol doesn*t support UDP operations*
Updated from RFC 1700* **Assigned Numbers** *October 1994** Not all ports
但是需要注入,如果b没有指定label则会直接跳到最后,下方中要讲的t命令也是如此。
t类似于 b 分支命令,t 命令也可以用来改变 sed 脚本的执行流程。
t 测试命令会根据 s 替换命令的结果,如果匹配并替换成功,则脚本的执行会跳转到指定的标签;反之,t 命令无效。
#将所有的数字换成*
[root@localhost ~]cat services | sed -e '{
> :start
> s/[[:digit:]]/\*/
> t start}'
/etc/services:
$Id: services,v *.** ****/**/** ovasik Exp $
Network services, Internet style
IANA services version: last updated ****-**-**
Note that it is presently the policy of IANA to assign a single well-known
port number for both TCP and UDP; hence, most entries here have two entries
even if the protocol doesn't support UDP operations.
Updated from RFC ****, ``Assigned Numbers'' (October ****). Not all ports
0x03 awk
感觉是一个比一个复杂,头痛!
awk主要是用于处理列的数据,查看help确实不多,但是看了下man,恐怖如斯
[root@localhost ~]awk --help
Usage: awk [POSIX or GNU style options] -f progfile [--] file ...
Usage: awk [POSIX or GNU style options] [--] 'program' file ...
POSIX options: GNU long options: (standard)
-f progfile --file=progfile
-F fs --field-separator=fs
-v var=val --assign=var=val
Short options: GNU long options: (extensions)
-b --characters-as-bytes
-c --traditional
-C --copyright
-d[file] --dump-variables[=file]
-e 'program-text' --source='program-text'
-E file --exec=file
-g --gen-pot
-h --help
-L [fatal] --lint[=fatal]
-n --non-decimal-data
-N --use-lc-numeric
-O --optimize
-p[file] --profile[=file]
-P --posix
-r --re-interval
-S --sandbox
-t --lint-old
-V --version
To report bugs, see node `Bugs' in `gawk.info', which is
section `Reporting Problems and Bugs' in the printed version.
gawk is a pattern scanning and processing language.
By default it reads standard input and writes standard output.
Examples:
gawk '{ sum += $1 }; END { print sum }' file
gawk -F: '{ print $1 }' /etc/passwd
awk命令的基本格式为:
awk [选项] '脚本命令' 文件名
选项就三个,还挺好理解
-Ffs ,指定以 fs 作为输入行的分隔符,awk 命令默认分隔符为空格或制表符。-ffile,从脚本文件中读取 awk 脚本指令,以取代直接在命令行中输入指令。-vvar=val,在执行处理过程之前,设置一个变量 var,并给其设备初始值为 val。
关键还是得在于脚本命令,由两部分组成,用起来和sed还是非常接近的
'匹配规则{执行命令}'
先看一个简单的案例
[root@localhost ~]cat services
/etc/services:
$Id: services,v 1.55 2013/04/14 ovasik Exp $
Network services, Internet style
IANA services version: last updated 2013-04-10
Note that it is presently the policy of IANA to assign a single well-known
port number for both TCP and UDP; hence, most entries here have two entries
even if the protocol doesnt support UDP operations.
Updated from RFC 1700, ''Assigned Numbers'' (October 1994). Not all ports
#输出两个空行所对应的字母
[root@localhost ~]cat services | awk '/^$/{print "bbbbbbbb"}'
bbbbbbbb
bbbbbbbb
awk的用法
awk 'BEGIN{ commands } pattern{ commands } END{ commands }'
- 第一步:运行
BEGIN{ commands }语句块中的语句。 - 第二步:从文件或标准输入
(stdin)读取一行。然后运行pattern{ commands }语句块,它逐行扫描文件,从第一行到最后一行反复这个过程。直到文件所有被读取完成。 - 第三步:当读至输入流末尾时。运行
END{ commands }语句块。
BEGIN语句块在awk开始从输入流中读取行之前被运行,这是一个可选的语句块,比方变量初始化、打印输出表格的表头等语句通常能够写在BEGIN语句块中。
END语句块在awk从输入流中读取全然部的行之后即被运行。比方打印全部行的分析结果这类信息汇总都是在END语句块中完毕,它也是一个可选语句块。
pattern语句块中的通用命令是最重要的部分,它也是可选的。假设没有提供pattern语句块,则默认运行{ print },即打印每个读取到的行。awk读取的每一行都会运行该语句块。
这三个部分缺少任何一部分都可以。
接下来看个例子
[root@localhost ~]ll
total 56
-rw-r--r-- 1 root root 8 Feb 10 20:44 -
-rwxrwxrwx 1 root root 63 Feb 11 15:29 1.sh
-rw-r--r-- 1 root root 3 Feb 10 21:17 1.txt
-rw-r--r-- 1 root root 53 Feb 10 20:34 2.txt
-rw-------. 1 root root 1333 Jan 31 23:26 anaconda-ks.cfg
-rw-r--r-- 1 root root 11 Feb 12 11:01 a.txt
-rw-r--r-- 1 root root 274 Feb 9 15:04 Dockerfile
drwxr-xr-x 2 root root 24 Feb 8 20:20 http-build
drwxr-xr-x 2 root root 24 Feb 9 19:54 lamp-build
-rw-r--r-- 1 root root 183 Feb 12 10:42 passwd
-rw-r--r-- 1 root root 36 Feb 12 16:36 sed.sh
-rw-r--r-- 1 root root 429 Feb 12 15:04 services
-rw-r--r-- 1 root root 10240 Feb 10 21:28 test.tar
-rw-r--r-- 1 root root 73 Feb 12 10:58 test.txt
[root@localhost ~]ll | awk '{print $1}'
total
-rw-r--r--
-rwxrwxrwx
-rw-r--r--
-rw-r--r--
-rw-------.
-rw-r--r--
-rw-r--r--
drwxr-xr-x
drwxr-xr-x
-rw-r--r--
-rw-r--r--
-rw-r--r--
-rw-r--r--
-rw-r--r--
在这里awk后面没有BEGIN和END,跟着的是pattern,也就是每一行都会经过这个命令,在awk中$n,表示第几列,在这里表示打印每一行的第一列。
$0当前记录(这个变量中存放着整个行的内容)$1~$n当前记录的第n个字段,字段间由FS分隔FS输入字段分隔符 默认是空格或TabNF当前记录中的字段个数,就是有多少列NR已经读出的记录数,就是行号,从1开始,如果有多个文件话,这个值也是不断累加中。FNR当前记录数,与NR不同的是,这个值会是各个文件自己的行号RS输入的记录分隔符, 默认为换行符OFS输出字段分隔符, 默认也是空格ORS输出的记录分隔符,默认为换行符FILENAME当前输入文件的名字
打印每一行的行数
[root@localhost ~]ll | awk '{print NR "\t" $1}'
1 total
2 -rw-r--r--
3 -rwxrwxrwx
4 -rw-r--r--
5 -rw-r--r--
6 -rw-------.
7 -rw-r--r--
8 -rw-r--r--
9 drwxr-xr-x
10 drwxr-xr-x
11 -rw-r--r--
12 -rw-r--r--
13 -rw-r--r--
14 -rw-r--r--
15 -rw-r--r--
再来看一下格式化输出
[root@localhost ~]awk -F ':' '{printf("filename:%10s,linenumber:%s,columns:%s,linecontent:%s\n",FILENAME,NR,NF,$0)}' /etc/passwd
filename:/etc/passwd,linenumber:1,columns:7,linecontent:root:x:0:0:root:/root:/bin/bash
filename:/etc/passwd,linenumber:2,columns:7,linecontent:bin:x:1:1:bin:/bin:/sbin/nologin
filename:/etc/passwd,linenumber:3,columns:7,linecontent:daemon:x:2:2:daemon:/sbin:/sbin/nologin
filename:/etc/passwd,linenumber:4,columns:7,linecontent:adm:x:3:4:adm:/var/adm:/sbin/nologin
filename:/etc/passwd,linenumber:5,columns:7,linecontent:lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
filename:/etc/passwd,linenumber:6,columns:7,linecontent:sync:x:5:0:sync:/sbin:/bin/sync
filename:/etc/passwd,linenumber:7,columns:7,linecontent:shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
filename:/etc/passwd,linenumber:8,columns:7,linecontent:halt:x:7:0:halt:/sbin:/sbin/halt
filename:/etc/passwd,linenumber:9,columns:7,linecontent:mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
filename:/etc/passwd,linenumber:10,columns:7,linecontent:operator:x:11:0:operator:/root:/sbin/nologin
filename:/etc/passwd,linenumber:11,columns:7,linecontent:games:x:12:100:games:/usr/games:/sbin/nologin
filename:/etc/passwd,linenumber:12,columns:7,linecontent:ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
filename:/etc/passwd,linenumber:13,columns:7,linecontent:nobody:x:99:99:Nobody:/:/sbin/nologin
filename:/etc/passwd,linenumber:14,columns:7,linecontent:systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
filename:/etc/passwd,linenumber:15,columns:7,linecontent:dbus:x:81:81:System message bus:/:/sbin/nologin
filename:/etc/passwd,linenumber:16,columns:7,linecontent:polkitd:x:999:998:User for polkitd:/:/sbin/nologin
filename:/etc/passwd,linenumber:17,columns:7,linecontent:sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
filename:/etc/passwd,linenumber:18,columns:7,linecontent:postfix:x:89:89::/var/spool/postfix:/sbin/nologin
filename:/etc/passwd,linenumber:19,columns:7,linecontent:apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
awk也可以使用语法,比如if、while等都是借鉴于C语言。。。比如选择出/etc/passwd中uid小于5的用户名及uid
[root@localhost ~]cat /etc/passwd | awk -F ":" '$3<5 {print $1 "\t" $3}'
root 0
bin 1
daemon 2
adm 3
lp 4
比如可以借用变量,用来计算1到100的和
[root@localhost ~] awk 'BEGIN{for(i=1;i<=100;i++){test+=i}print test}'
5050
实在是太狠了,慢慢来吧,以后在实战中体会,嘿嘿。
最后再用awk获取ip地址,在处理数据上感觉比sed好用多了,强大!
[root@localhost ~]ifconfig ens32|awk '/inet /{print $2}'
10.1.1.222
最后,用大年三十和年初一完成的长篇攻略,祝大家牛年大吉,牛气冲天!