备注:
Hive 版本 2.1.1
一.Hive关系模型概述
Hive的数据模型不传统关系数据库类似,均属于关系型数据模型。
将数据理解为行数据和列字段的二维表格,利用类SQL(结构化查询语言)进行数据操作。
Hive元数据信息存储在关系数据库中,实际数据存储依赖HDFS。
Hive通过以下模型来组织HDFS上的数据:
1.数据库(Database)
2.表(Table)
3.分区(Partition)
4.桶(Bucket)
1.1.Database
Database是Hive数据模型的最上层,跟关系数据库中的Database意义相似
通过Database来逻辑划分Hive表的命名空间,避免表同名冲突
Hive默认自带的Database名为default
HDFS存储路径由配置决定,一个Database一个子目录

1.2 Table
Hive中的表和关系型数据库中的表在概念上很类似
每个表在HDFS中都有相应的目录用来存储表的数据
1.2.1 管理表和外部表
根据数据是否受Hive管理,分为:
Managed Table(管理表)
External Table(外表)
区别:
-
Managed Table:
HDFS存储数据受Hive管理,在统一的路径下: ${hive.metastore.warehouse.dir}/{database_name}.db/{tablename}
Hive对表的删除操作影响实际数据的删除 -
External Table:
HDFS存储路径不受Hive管理,只是Hive元数据不HDFS数据路径的一个映射
Hive对表的删除操作仅仅删除元数据,实际数据不受影响扫描二维码关注公众号,回复: 12470460 查看本文章
1.2.2 永久表和临时表
Permanent Table是指永久存储在HDFS之上的表,默认创建表为永久表
Temporary Table是指仅当前Session有效的表,数据临时存放在用户的临时目录下,当前session退出后即删除
临时表比较适合于比较复杂的SQL逻辑中拆分逻辑块,或者临时测试
注意:
如果创建临时表时,存在不之同名的永久表,则临时表的可见性高于永久表,即对表的操作是临时表的,用永久表无效
临时表不支持分区
1.3 Partition
基于用户指定的分区列的值对数据表进行分区
表的每一个分区对应表下的相应目录,所有分区的数据都是存储在对应的目录中
–: ${hive.metastore.warehouse.dir}/{database_name}.db/{tablename}/{partitionkey}={value}
分区的优点:
- 分区从物理上分目录划分不同列的数据
- 用于查询的剪枝,提升查询的效率
可以多级Partition,即指定多个Partition字段,但所有Partition的数据不可无限扩展(多级目录造成HDFS小文件过多影响性能)
1.4 Bucket
桶作为另一种数据组织方式,弥补Partition的短板(不是所有的列都可以作为Partition Key)
通过Bucket列的值进行Hash散列到相应的文件中,重新组织数据,每一个桶对应一个文件
桶的优点:
1) 有利于查询优化,比如SMB Join
2) 对于抽样非常有效
桶的数量一旦定义后,如果更改,只会修改Hive元数据,实际数据不会重新组织
二.数据定义语言(DDL)
DDL数据定义语言(Data Definition Language)
Hive支持的DDL语义包括对数据模型(Database/Table)等的以下操作:
- CREATE
- DROP
- SHOW
- DESCRIBE
- ALTER
2.1 HiveQL保留关键字
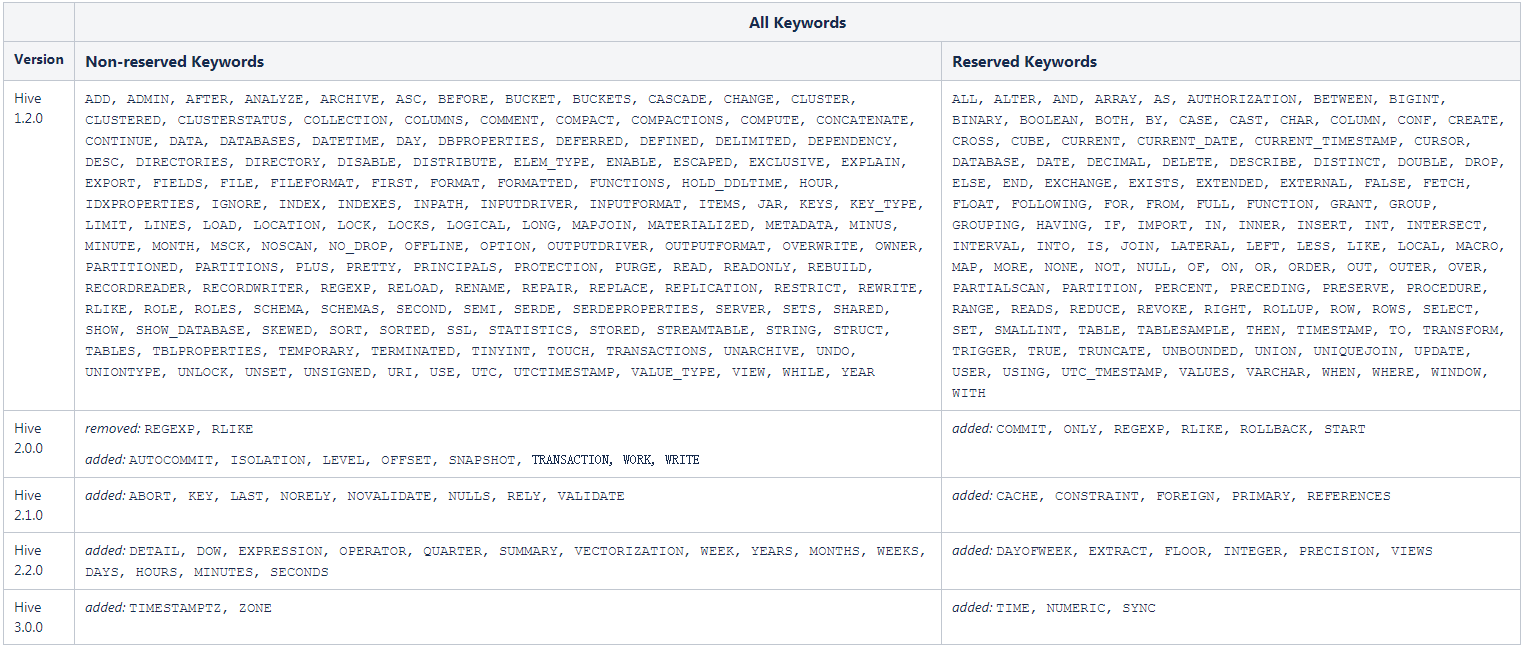
HiveQL不建议使用保留关键字,如果一定要使用,需要进行转义。
如果遇到一定要使用,可以用反引号来转义。
hive>
>
> create table user_info (userid string,name string,age int,from string);
NoViableAltException(132@[])
at org.apache.hadoop.hive.ql.parse.HiveParser.columnNameTypeOrPKOrFK(HiveParser.java:32232)
at org.apache.hadoop.hive.ql.parse.HiveParser.columnNameTypeOrPKOrFKList(HiveParser.java:28392)
at org.apache.hadoop.hive.ql.parse.HiveParser.createTableStatement(HiveParser.java:5281)
at org.apache.hadoop.hive.ql.parse.HiveParser.ddlStatement(HiveParser.java:3112)
at org.apache.hadoop.hive.ql.parse.HiveParser.execStatement(HiveParser.java:2266)
at org.apache.hadoop.hive.ql.parse.HiveParser.statement(HiveParser.java:1318)
at org.apache.hadoop.hive.ql.parse.ParseDriver.parse(ParseDriver.java:218)
at org.apache.hadoop.hive.ql.parse.ParseUtils.parse(ParseUtils.java:75)
at org.apache.hadoop.hive.ql.parse.ParseUtils.parse(ParseUtils.java:68)
at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:564)
at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:1425)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1493)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1339)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1328)
at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:239)
at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:187)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:409)
at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:836)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:772)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:699)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:313)
at org.apache.hadoop.util.RunJar.main(RunJar.java:227)
FAILED: ParseException line 1:58 cannot recognize input near 'from' 'string' ')' in column name or primary key or foreign key
hive>
> create table user_info (userid string,name string,age int,`from` string);
OK
Time taken: 0.106 seconds
hive> desc user_info;
OK
userid string
name string
age int
from string
Time taken: 0.05 seconds, Fetched: 4 row(s)
hive>
> select userid,name,age,`from` from user_info;
OK
Time taken: 0.072 seconds
2.2 Database相关DDL操作
2.2.1 SHOW 命令
SHOW命令用于列出符合条件的数据库
语法:
SHOW (DATABASES|SCHEMAS) [LIKE‘identifier_with_wildcards’];
测试:
hive>
>
> show databases;
OK
cloudera_manager_metastore_canary_test_db_hive_hivemetastore_217bfbe198cbd3fb75336aa552ed30b1
default
test
Time taken: 0.028 seconds, Fetched: 3 row(s)
hive>
> show databases like 'te*';
OK
test
Time taken: 0.026 seconds, Fetched: 1 row(s)
2.2.2 DESCRIBE命令
DESCRIBE命令用于描述Database定义
语法:
DESCRIBE DATABASE [EXTENDED] db_name;
测试:
hive> describe database test;
OK
test hdfs://nameservice1/user/hive/warehouse/test.db root USER
Time taken: 0.031 seconds, Fetched: 1 row(s)
hive> describe database extended test;
OK
test hdfs://nameservice1/user/hive/warehouse/test.db root USER
Time taken: 0.03 seconds, Fetched: 1 row(s)
2.2.3 CREATE命令
CREATE命令用于创建数据库
语法:
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[MANAGEDLOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
LOCATION命令是用于外部表
MANAGEDLOCATION 用于hive的管理表
测试:
-- comment测试
hive>
> create database db_test2 comment 'this is db_test2';
OK
Time taken: 0.056 seconds
hive> describe database extended db_test2;
OK
db_test2 this is db_test2 hdfs://nameservice1/user/hive/warehouse/db_test2.db root USER
Time taken: 0.035 seconds, Fetched: 1 row(s)
-- LOCATION 测试
hive>
> create database db_test3 location '/tmp/db_test3.db';
OK
Time taken: 0.058 seconds
hive> describe database extended db_test3;
OK
db_test3 hdfs://nameservice1/tmp/db_test3.db root USER
Time taken: 0.029 seconds, Fetched: 1 row(s)
-- MANAGEDLOCATION 测试
hive> create database db_test4 location '/tmp/db_test4.db';
OK
Time taken: 0.053 seconds
hive> describe database extended db_test4;
OK
db_test4 hdfs://nameservice1/tmp/db_test4.db root USER
Time taken: 0.031 seconds, Fetched: 1 row(s)
hive>
-- with dbproperties 测试
hive> create database db_test1 with dbproperties ('my_db1' = 'Oracle','my_db2' = 'Hive');
OK
Time taken: 0.056 seconds
hive> describe database extended db_test1;
OK
db_test1 hdfs://nameservice1/user/hive/warehouse/db_test1.db root USER {my_db1=Oracle, my_db2=Hive}
Time taken: 0.03 seconds, Fetched: 1 row(s)
2.2.4 DROP命令
DROP用于删除数据库
语法:
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name[RESTRICT|CASCADE];
默认参数为RESTRICT,当数据库不为空的时候,drop database会失败。如果需要删除不为空的数据库,需要使用 cascade;
测试:
hive>
> use db_test1;
OK
Time taken: 0.026 seconds
hive> create table emp1 as select * from test.emp;
Query ID = root_20201203135935_8d50db00-b827-447a-b620-67ccde7f86e3
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1606698967173_0018, Tracking URL = http://hp1:8088/proxy/application_1606698967173_0018/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1606698967173_0018
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 0
2020-12-03 13:59:43,004 Stage-1 map = 0%, reduce = 0%
2020-12-03 13:59:50,207 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.77 sec
MapReduce Total cumulative CPU time: 3 seconds 770 msec
Ended Job = job_1606698967173_0018
Stage-4 is filtered out by condition resolver.
Stage-3 is selected by condition resolver.
Stage-5 is filtered out by condition resolver.
Launching Job 3 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1606698967173_0019, Tracking URL = http://hp1:8088/proxy/application_1606698967173_0019/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1606698967173_0019
Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0
2020-12-03 14:00:01,664 Stage-3 map = 0%, reduce = 0%
2020-12-03 14:00:08,877 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 1.62 sec
MapReduce Total cumulative CPU time: 1 seconds 620 msec
Ended Job = job_1606698967173_0019
Moving data to directory hdfs://nameservice1/user/hive/warehouse/db_test1.db/emp1
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Cumulative CPU: 3.77 sec HDFS Read: 9801 HDFS Write: 816 HDFS EC Read: 0 SUCCESS
Stage-Stage-3: Map: 1 Cumulative CPU: 1.62 sec HDFS Read: 3024 HDFS Write: 677 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 390 msec
OK
Time taken: 34.73 seconds
hive>
> drop database db_test1;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database db_test1 is not empty. One or more tables exist.)
hive>
> drop database db_test1 restrict;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database db_test1 is not empty. One or more tables exist.)
hive>
> drop database db_test1 cascade;
OK
Time taken: 0.118 seconds
hive>
> show databases;
OK
cloudera_manager_metastore_canary_test_db_hive_hivemetastore_217bfbe198cbd3fb75336aa552ed30b1
db_test2
db_test3
db_test4
default
test
Time taken: 0.032 seconds, Fetched: 6 row(s)
hive>
2.2.5 ALTER 命令
ALTER用于修改Database属性
语法:
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...); -- (Note: SCHEMA added in Hive 0.14.0)
ALTER (DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role; -- (Note: Hive 0.13.0 and later; SCHEMA added in Hive 0.14.0)
ALTER (DATABASE|SCHEMA) database_name SET LOCATION hdfs_path; -- (Note: Hive 2.2.1, 2.4.0 and later)
ALTER (DATABASE|SCHEMA) database_name SET MANAGEDLOCATION hdfs_path; -- (Note: Hive 4.0.0 and later)
2.2.6 Use命令
USE database_name; 切换到指定Database
2.3 Table相关DDL操作
2.3.1 Create命令
语法:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [column_constraint_specification] [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
data_type
: primitive_type
| array_type
| map_type
| struct_type
| union_type -- (Note: Available in Hive 0.7.0 and later)
primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later)
| STRING
| BINARY -- (Note: Available in Hive 0.8.0 and later)
| TIMESTAMP -- (Note: Available in Hive 0.8.0 and later)
| DECIMAL -- (Note: Available in Hive 0.11.0 and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later)
| DATE -- (Note: Available in Hive 0.12.0 and later)
| VARCHAR -- (Note: Available in Hive 0.12.0 and later)
| CHAR -- (Note: Available in Hive 0.13.0 and later)
array_type
: ARRAY < data_type >
map_type
: MAP < primitive_type, data_type >
struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...>
union_type
: UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later)
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| JSONFILE -- (Note: Available in Hive 4.0.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
column_constraint_specification:
: [ PRIMARY KEY|UNIQUE|NOT NULL|DEFAULT [default_value]|CHECK [check_expression] ENABLE|DISABLE NOVALIDATE RELY/NORELY ]
default_value:
: [ LITERAL|CURRENT_USER()|CURRENT_DATE()|CURRENT_TIMESTAMP()|NULL ]
constraint_specification:
: [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, CONSTRAINT constraint_name FOREIGN KEY (col_name, ...) REFERENCES table_name(col_name, ...) DISABLE NOVALIDATE
[, CONSTRAINT constraint_name UNIQUE (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, CONSTRAINT constraint_name CHECK [check_expression] ENABLE|DISABLE NOVALIDATE RELY/NORELY ]
建表常用选项:
1) 文件格式
2) 字段类型选择
3) 字段默认值
4) 约束相关
5) 分区
6) 分桶
2.3.1.1 建表测试语句-文件格式及分隔符测试
textfile文件格式是默认的文件格式,除非hive.default.fileformat被修改为其他的值。
使用DELIMITED 子句进行读取 分隔的文件。
使用 ‘ESCAPED BY’ 子句 (例如 ESCAPED BY ‘’) 启用对分隔符字符的转义。
使用 ‘NULL DEFINED AS’ 子句 (default is ‘\N’)还可以指定自定义空格式。
创建一个文件格式为textfile的表,包含数值类型、字符类型、时间类型,且表和表的列均有注释,分隔符为’|’。
hive>
> CREATE TABLE `t1`(
> `id` int COMMENT 'id',
> `name` string COMMENT '名字',
> `login_date` timestamp COMMENT '登陆时间')
> comment "登陆日志表"
> row format delimited fields terminated by '|'
> stored as textfile;
OK
Time taken: 0.126 seconds
hive> show create table t1;
OK
CREATE TABLE `t1`(
`id` int COMMENT 'id',
`name` string COMMENT '名字',
`login_date` timestamp COMMENT '登陆时间')
COMMENT '登陆日志表'
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'='|',
'serialization.format'='|')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://nameservice1/user/hive/warehouse/test.db/t1'
TBLPROPERTIES (
'transient_lastDdlTime'='1606991328')
Time taken: 0.105 seconds, Fetched: 18 row(s)
2.3.1.2 外部表测试
外部表,HDFS存储路径不受Hive管理,只是Hive元数据不HDFS数据路径的一个映射
Hive对表的删除操作仅仅删除元数据,实际数据不受影响
-- 创建hdfs目录
hadoop fs -mkdir /tmp/external_table
hive>
>
> create external table ext_table(key int comment 'key column',value string) location '/tmp/external_table';
OK
Time taken: 0.084 seconds
hive> show create table ext_table;
OK
CREATE EXTERNAL TABLE `ext_table`(
`key` int COMMENT 'key column',
`value` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://nameservice1/tmp/external_table'
TBLPROPERTIES (
'transient_lastDdlTime'='1606991901')
Time taken: 0.052 seconds, Fetched: 13 row(s)
hive>
2.3.1.3 临时表测试
临时表退出不可用
hive>
> create temporary table user_tmp(userid string,name string,age int,`from` string);
OK
Time taken: 0.069 seconds
hive> show create table user_tmp;
OK
CREATE TEMPORARY TABLE `user_tmp`(
`userid` string,
`name` string,
`age` int,
`from` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://nameservice1/tmp/hive/root/81bb0df0-0b98-4f01-a840-0c092c854bc5/_tmp_space.db/664b988b-8175-4d00-bddf-459295213638'
TBLPROPERTIES (
)
Time taken: 0.035 seconds, Fetched: 15 row(s)
hive> exit
> ;
[root@hp1 mysql]# hive
WARNING: Use "yarn jar" to launch YARN applications.
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/jars/log4j-slf4j-impl-2.8.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/jars/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/jars/hive-common-2.1.1-cdh6.3.1.jar!/hive-log4j2.properties Async: false
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive> use test;
OK
Time taken: 1.185 seconds
hive> show create table user_tmp;
FAILED: SemanticException [Error 10001]: Table not found user_tmp
hive>
2.3.1.4 分区表及分桶测试
分区测试:
hive>
> create table test_part (id int,name string) partitioned by(date_in string);
OK
Time taken: 0.394 seconds
hive>
> show create table test_part;
OK
CREATE TABLE `test_part`(
`id` int,
`name` string)
PARTITIONED BY (
`date_in` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://nameservice1/user/hive/warehouse/test.db/test_part'
TBLPROPERTIES (
'transient_lastDdlTime'='1606992622')
Time taken: 0.294 seconds, Fetched: 15 row(s)
hive>
hive>
> alter table test_part add partition(date_in='2018-10-28');
OK
hive> show create table test_part;
OK
CREATE TABLE `test_part`(
`id` int,
`name` string)
PARTITIONED BY (
`date_in` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://nameservice1/user/hive/warehouse/test.db/test_part'
TBLPROPERTIES (
'transient_lastDdlTime'='1606992622')
Time taken: 0.057 seconds, Fetched: 15 row(s)
hive>
分桶测试:
hive>
> create table test_bucket(userid bigint,key int,value string) partitioned by (date_in string) clustered by (userid) sorted by (userid) into 32 buckets;
OK
Time taken: 0.1 seconds
hive> show create table test_bucket;
OK
CREATE TABLE `test_bucket`(
`userid` bigint,
`key` int,
`value` string)
PARTITIONED BY (
`date_in` string)
CLUSTERED BY (
userid)
SORTED BY (
userid ASC)
INTO 32 BUCKETS
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://nameservice1/user/hive/warehouse/test.db/test_bucket'
TBLPROPERTIES (
'transient_lastDdlTime'='1606992907')
Time taken: 0.053 seconds, Fetched: 21 row(s)
2.3.2 SHOW命令
语法:
SHOW TABLES [IN database_name] [‘identifier_with_wildcards’]; // 列出表
SHOW CREATE TABLE ([db_name.]table_name|view_name); //列出表创建语句
SHOW PARTITIONS table_name; //列出表的所有分区
SHOW COLUMNS (FROM|IN) table_name[(FROM|IN) db_name]; //列出表的所有字段
2.3.3 DESCRIBE命令
语法:
DESCRIBE [EXTENDED|FORMATTED]table_name//描述表定义
DESCRIBE [EXTENDED|FORMATTED] table_name PARTITION partition_spec; //描述分区定义
测试:
hive>
> desc test_part;
OK
id int
name string
date_in string
# Partition Information
# col_name data_type comment
date_in string
Time taken: 0.097 seconds, Fetched: 8 row(s)
hive>
>
> desc test_part partition(date_in = '2018-10-28');
OK
id int
name string
date_in string
# Partition Information
# col_name data_type comment
date_in string
Time taken: 0.163 seconds, Fetched: 8 row(s)
hive>
2.3.4 DROP命令
语法:
DROP TABLE [IF EXISTS] table_name[PURGE];//删除表
默认drop的表是会到回收站里面,如果加上purge的话,会直接删除而不经过回收站。
2.3.5 TRUNCATE命令
语法:
TRUNCATE TABLE table_name[PARTITION partition_spec]; //清空表数据
同关系型数据库的截断表,生产环境谨慎使用。
2.3.6 ALTER命令
alter的语法非常强大,可以实现多种功能
语法:
ALTER TABLE table_name RENAME TO new_table_name; //重命名表
ALTER TABLE table_name SET TBLPROPERTIES table_properties; //修改表的属性
ALTER TABLE table_name SET TBLPROPERTIES ('comment' = new_comment); //修改表的备注
ALTER TABLE table_name [PARTITION partition_spec] SET SERDE serde_class_name [WITH SERDEPROPERTIES serde_properties];//增加SerDe属性
ALTER TABLE table_name [PARTITION partition_spec] UNSET SERDEPROPERTIES (property_name, ... );//删除SerDe属性
ALTER TABLE table_name CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name, ...)]
INTO num_buckets BUCKETS; //修改表的存储属性
ALTER TABLE table_name SKEWED BY (col_name1, col_name2, ...)
ON ([(col_name1_value, col_name2_value, ...) [, (col_name1_value, col_name2_value), ...]
[STORED AS DIRECTORIES]; //修改表的倾斜
ALTER TABLE table_name NOT SKEWED; //取消维护表的倾斜
/*维护表的约束相关*/
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY (column, ...) DISABLE NOVALIDATE;
ALTER TABLE table_name ADD CONSTRAINT constraint_name FOREIGN KEY (column, ...) REFERENCES table_name(column, ...) DISABLE NOVALIDATE RELY;
ALTER TABLE table_name ADD CONSTRAINT constraint_name UNIQUE (column, ...) DISABLE NOVALIDATE;
ALTER TABLE table_name CHANGE COLUMN column_name column_name data_type CONSTRAINT constraint_name NOT NULL ENABLE;
ALTER TABLE table_name CHANGE COLUMN column_name column_name data_type CONSTRAINT constraint_name DEFAULT default_value ENABLE;
ALTER TABLE table_name CHANGE COLUMN column_name column_name data_type CONSTRAINT constraint_name CHECK check_expression ENABLE;
ALTER TABLE table_name DROP CONSTRAINT constraint_name;
/*新增分区*/
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION 'location'][, PARTITION partition_spec [LOCATION 'location'], ...];
partition_spec:
: (partition_column = partition_col_value, partition_column = partition_col_value, ...)
/*交换分区*/
-- Move partition from table_name_1 to table_name_2
ALTER TABLE table_name_2 EXCHANGE PARTITION (partition_spec) WITH TABLE table_name_1;
-- multiple partitions
ALTER TABLE table_name_2 EXCHANGE PARTITION (partition_spec, partition_spec2, ...) WITH TABLE table_name_1;
/*删除分区*/
ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec[, PARTITION partition_spec, ...]
[IGNORE PROTECTION] [PURGE]; -- (Note: PURGE available in Hive 1.2.0 and later, IGNORE PROTECTION not available 2.0.0 and later)
/*修改列的属性*/
ALTER TABLE table_name [PARTITION partition_spec] CHANGE [COLUMN] col_old_name col_new_name column_type
[COMMENT col_comment] [FIRST|AFTER column_name] [CASCADE|RESTRICT];
/*新增or替换 列 */
ALTER TABLE table_name
[PARTITION partition_spec] -- (Note: Hive 0.14.0 and later)
ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
[CASCADE|RESTRICT] -- (Note: Hive 1.1.0 and later)
2.3.6.1 重命名表
将 user_info表改名为 user_info_bak
hive>
> desc user_info;
OK
userid string
name string
age int
from string
Time taken: 0.056 seconds, Fetched: 4 row(s)
hive> alter table user_info rename to user_info_bak
> ;
OK
Time taken: 0.102 seconds
hive> desc user_info_bak;
OK
userid string
name string
age int
from string
Time taken: 0.053 seconds, Fetched: 4 row(s)
hive>
2.3.6.2 修改表的属性
修改表的备注信息
hive>
> alter table user_info_bak SET TBLPROPERTIES ('comment'='用户备份表');
OK
Time taken: 0.089 seconds
hive> show create table user_info_bak;
OK
CREATE TABLE `user_info_bak`(
`userid` string,
`name` string,
`age` int,
`from` string)
COMMENT '用户备份表'
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://nameservice1/user/hive/warehouse/test.db/user_info_bak'
TBLPROPERTIES (
'last_modified_by'='root',
'last_modified_time'='1606994861',
'transient_lastDdlTime'='1606994861')
Time taken: 0.06 seconds, Fetched: 18 row(s)
2.3.6.3 修改表的列
create table t2(id int,name varchar(50));
更改列名
-- 将id列名改为 user_id
hive>
> alter table t2 change id user_id int;
OK
Time taken: 0.094 seconds
修改列的长度
hive>
> alter table t2 change name name varchar(100);
OK
Time taken: 0.083 seconds
hive> desc t2;
OK
user_id int
name varchar(100)
Time taken: 0.052 seconds, Fetched: 2 row(s)
修改列的顺序
将name列调整到最前面
hive>
> alter table t2 change name name varchar(100) first;
OK
Time taken: 0.091 seconds
hive> desc t2;
OK
name varchar(100)
user_id int
Time taken: 0.054 seconds, Fetched: 2 row(s)
修改列的注释
hive>
> alter table t2 change name name varchar(100) comment '用户姓名';
OK
Time taken: 0.108 seconds
hive> desc t2;
OK
name varchar(100) 用户姓名
user_id int
Time taken: 0.052 seconds, Fetched: 2 row(s)
增加列
hive>
> alter table t2 add columns (login_date timestamp,last_update_date timestamp);
OK
Time taken: 0.078 seconds
hive> desc t2;
OK
name varchar(100) 用户姓名
user_id int
login_date timestamp
last_update_date timestamp
Time taken: 0.05 seconds, Fetched: 4 row(s)
hive>
删除列
hive的删除列 需要使用replace
hive>
> alter table t2 replace columns(user_id int,name varchar(100) comment '用户姓名',loagin_date timestamp);
OK
Time taken: 0.077 seconds
hive> desc t2;
OK
user_id int
name varchar(100) 用户姓名
loagin_date timestamp
Time taken: 0.054 seconds, Fetched: 3 row(s)
hive>
2.3.6.4 修改分区表的属性
新增分区
hive>
> alter table test_part add partition(date_in='2020-12-03');
OK
Time taken: 0.128 seconds
hive> desc test_part;
OK
id int
name string
date_in string
# Partition Information
# col_name data_type comment
date_in string
Time taken: 0.066 seconds, Fetched: 8 row(s)
hive>
删除分区
hive>
> alter table test_part drop partition(date_in='2020-12-03');
Dropped the partition date_in=2020-12-03
OK
Time taken: 0.451 seconds
参考
1.https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
2.http://blog.sina.com.cn/s/blog_6238358c0100pll4.html