文章目录
一、SPI简介
概念来自百度百科:SPI是串行外设接口(Serial Peripheral Interface)的缩写,是一种高速的,全双工,同步的通信总线,并且在芯片的管脚上只占用四根线,节约了芯片的管脚,同时为PCB的布局上节省空间,提供方便,正是出于这种简单易用的特性,越来越多的芯片集成了这种通信协议。
简单来说就是,SPI是一种通信接口,通过SPI可以与其它通信设备进行SPI通信,类似于I2C。
我们将从以下角度来了解SPI:
引脚说明–>互连示例–>通信原理
通信模式选择:时钟相位和时钟极性的选择
.
1.1 引脚说明:
其实通过前面的简介就可以大致推出SPI的引脚情况:“全双工”,这说明有两根数据线;“同步”,则说明有一根时钟线;在此基础上,SPI还有一根片选线,用于多设备进行SPI通信时选择相应的从设备。
SPI通过4根线进行通信,分别是MISO、MOSI、SCLK、CS
MISO(Master input Slave output) 主设备数据输入,从设备数据输出。
MOSI(Master output Slave input) 主设备数据输出,从设备数据输入。
SCLK (SPI clock) 时钟信号,由主设备产生。
CS(Chip select) 从设备片选信号,由主设备控制。
下面通过互连示例进一步理解SPI的引脚功能,同时理解SPI的通信模式:
.
1.2 互连示例:
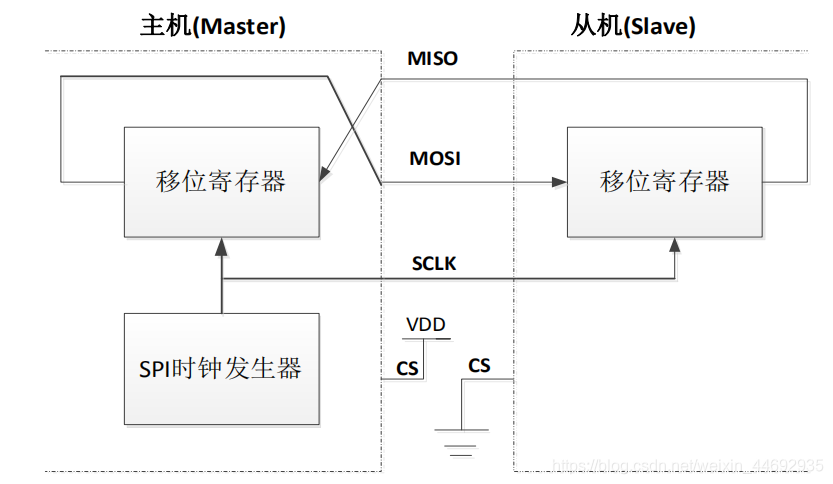
两个设备通过MISO、MOSI、SCLK、CS连接进行SPI通信,其中,提供SCLK时钟信号的设备作为主机。
主机和从机各自提供一个移位寄存器,通过MOSI与MISO彼此连接,且受SCLK时序控制。两设备每接收一个时钟信号,移位寄存器移位:主机移位寄存器通过MOSI向从机移位寄存器发送一位数据的同时,也通过MISO接收一位来自从机移位寄存器移出的数据。同样的,从机移位寄存器通过MISO向主机移位寄存器发送一位数据的同时,也通过MOSI接收一位来自主机移位寄存器移出的数据。
这样,每接收一个SCLK信号,两设备通过SPI实现一次一位数据的交换。那么经过8次时钟信号的改变,就可以完成8位数据(也就是1个字节Byte)的传输。
而CS片选线的作用,就是将CS为高的设备作为主机,将CS为低的作为从机。
也就是说,只有片选信号为预先规定的使能信号时(一般默认为低电位),对此芯片的操作才有效,这就允许在同一总线上连接多个SPI设备成为可能
也就是说,当有多个从设备的时候,因为每个从设备上都有一个片选引脚接入到主设备机中,当我们的主设备和某个从设备通信时将需要将从设备对应的片选引脚电平拉低

1.3 通信原理:
在上面互连示例中已经把通信原理大致讲清楚了,这里只做稍微补充。
可能有人会问,如果两个设备之间进行SPI通信的实质是进行数据交换,那如何实现单纯的数据的收和发呢?
当要发送数据时,直接发送数据,尽管发送的同时会接收到从机发送的数据,忽略即可。 当要接收数据时,向从机发送一些无关紧要的(空)数据(比如0Xff),自然从机接收数据的同时会发送数据给主机。
这样就实现了数据的收和发。
.
1.4 通信模式的选择:
时钟极性CPOL是用来配置SCLK的电平出于哪种状态时是空闲态或者有效态,时钟相位CPHA是用来配置数据采样是在第几个边沿:
CPOL=0,表示当SCLK=0时处于空闲态,所以有效状态就是SCLK处于高电平时;
CPOL=1,表示当SCLK=1时处于空闲态,所以有效状态就是SCLK处于低电平时;
CPHA=0,表示数据采样是在第1个边沿,数据发送在第2个边沿;
CPHA=1,表示数据采样是在第2个边沿,数据发送在第1个边沿;
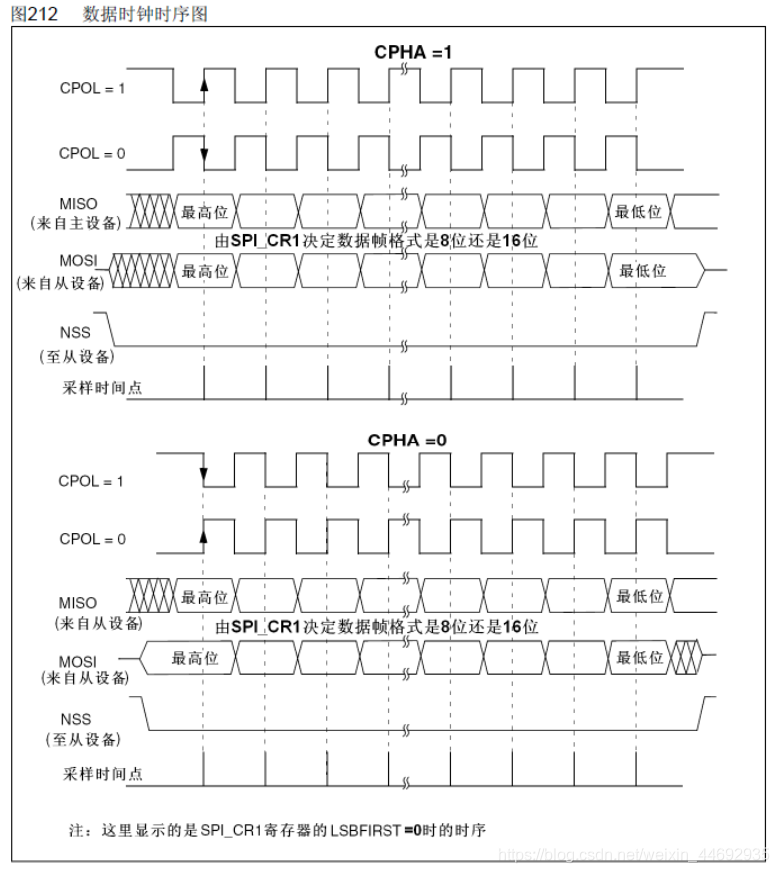
对于SPI的四种通信模式,总结起来,就是:
CPOL=0,CPHA=0:此时空闲态时,SCLK处于低电平,数据采样是在第1个边沿,也就是SCLK由低电平到高电平的跳变,所以数据采样是在上升沿;
CPOL=0,CPHA=1:此时空闲态时,SCLK处于低电平,数据发送是在第1个边沿,也就是SCLK由低电平到高电平的跳变,所以数据采样是在下降沿;
CPOL=1,CPHA=0:此时空闲态时,SCLK处于高电平,数据采集是在第1个边沿,也就是SCLK由高电平到低电平的跳变,所以数据采集是在下降沿;
CPOL=1,CPHA=1:此时空闲态时,SCLK处于高电平,数据发送是在第1个边沿,也就是SCLK由高电平到低电平的跳变,所以数据采集是在上升沿。
以上便是SPI的简介。
.
.
.
二、针对STM32的SPI
我们将从以下角度来了解SPI:
引脚分配、代码配置
STM32的SPI非常复杂,反正我是看不懂,有兴趣的可以移步STM32F4xx中文参考手册第27章进行深入了解。这里主要讲解引脚分配和代码配置。
.
2.1 引脚分配:
我们从上文得知了SPI的引脚情况,在STM32中,MOSI和MISO引脚有固定的一些GPIO由复用映射得到,SCLK挂载在APB2下,CS片选线则是通过自定义GPIO来控制(需要在SPI初始化时通过配置NSS来决定CS片选线是由软件控制还是由硬件控制)
2.2 代码配置:
这个就是最简单的part了,与大多数外设的初始化配置类似(先初始化GPIO、在使能相应时钟,该复用的复用,中断按需开启),用相关结构体(SPI_InitStructure)初始化各参数,这里也不做赘述了。
下面通过STM与W25Q128进行SPI通讯的具体示例来进一步了解STM32的SPI,同时对W25Q128有一个基本的了解。
.
.
.
三、W25Q128
3.1 简介:
这里截取官方芯片手册的文档说明:

简单来说,W25Q128就是一块能够存储数据的Flash。
.
3.2 W25Q128与STM32的SPI通信:代码part
在STM32完成SPI的初始化配置之后,关于STM32的代码已经基本完成了,接下来就是W28Q128的相关代码的编写,进而实现二者之间的通讯。
由于代码量大,限于本博文篇幅,这里只摘取几个笔者自认为比较难理解的函数进行讲述,其余代码可在附件中查看,我都有给以详细的注释。
首先简要提一下初始化函数W25QXX_Init(),用于初始化芯片,主要就是控制该芯片片选线CS的GPIO引脚的初始化。
.
.
.
读取SPI Flash的函数W25QXX_Read(),作用是在指定地址开始读取指定长度的数据。
根据芯片手册,读操作之前需要先把片选拉低,然后再传入一个24位的地址(也就是要读取位置的地址),传入后芯片会从输出引脚自动把该地址上的数据传出,最后我们再把片选拉高,则完成一次数据的读取。
这里涉及到一个问题,地址是24bit的,而我们只有u32的变量或者u16之类的,自然我们要用u32的变量,于是多出了8位数据位。
所以在代码上我们要对地址位进行适当的移位后再进行传输。
//读取SPI FLASH
//在指定地址开始读取指定长度的数据
//pBuffer:数据存储区
//ReadAddr:开始读取的地址(24bit)
//NumByteToRead:要读取的字节数(最大65535)
//The Read Data instruction allows one or more data bytes to be sequentially read from the memory.
//The instruction is initiated by driving the /CS pin low and then shifting the instruction code “03h” followed by a
//24-bit address (A23-A0) into the DI pin. The code and address bits are latched on the rising edge of the CLK pin.
//After the address is received, the data byte of the addressed memory location will be shifted out
//on the DO pin at the falling edge of CLK with most significant bit (MSB) first.
void W25QXX_Read(u8* pBuffer,u32 ReadAddr,u16 NumByteToRead)
{
u16 i;
W25QXX_CS=0; //使能器件
SPI1_ReadWriteByte(W25X_ReadData); //发送读取命令
SPI1_ReadWriteByte((u8)((ReadAddr)>>16)); //发送24bit地址,先右移16位,这一步发送的是24位地址中的[23:16]位
SPI1_ReadWriteByte((u8)((ReadAddr)>>8)); //同样的24位地址,右移8bit后,低八位的数据是原来24位地址中的[15:8]位
SPI1_ReadWriteByte((u8)ReadAddr); //最后直接发送24位地址的低八位,也就是原地址的低八位[7:0],至此,24位地址发送完毕
// 0000 0000 1111 1111 1111 1111 1111 1111
// 0000 0000 0000 0000 0000 0000 1111 1111
// 0000 0000 0000 0000 1111 1111 1111 1111
// 0000 0000 1111 1111 1111 1111 1111 1111
for(i=0;i<NumByteToRead;i++) //根据需要读取的长度NumByteToRead进行迭代
{
pBuffer[i]=SPI1_ReadWriteByte(0XFF); //循环读数
}
W25QXX_CS=1;
}
.
.
.
写入SPI Flash函数W25QXX_Write(),作用是在指定地址开始写入指定长度的数据,这个就比读操作要复杂得多了。
第一步:由于W25Q128每次读写操作的最小单元是sector(4k),所以我们首先判断我们要写入的是芯片的第几个sector、要写入的地址在该sector的起始地址上偏移了多少、以及该sector从写入地址起还剩余多少空间。
而一个sector(4K) = 4096Byte,所以写入地址WriteAddr对4096进行运算就可以得到上述值。
第二步:判断完sector的相关信息后,第二步紧接着判断要写入的数据长度是否大于剩余sector的空间长度,如果不大于,正常写,如果大于,同样也是先正常写入,但是后面需进行额外操作。这个额外操作将在第四步再次提到。
第三步:判断完长度后,我们还需要判断要写入区域是否已经擦除完毕,如果没有,先进行擦除,否则直接进行写入。
第四步:由于上述步骤中可能出现“要写入的数据长度大于剩余sector的空间长度”的情况,当时我们只是写入了该写入地址所在的sector部分,但是其后其实还有数据要处理,所以我们对相关的指针进行移位,进行相应运算,目的就是把多出来的数据也写入。
以上后四步需要迭代,直至数据被完全写入。
//写SPI FLASH
//在指定地址开始写入指定长度的数据
//该函数带擦除操作!
//pBuffer:数据存储区
//WriteAddr:开始写入的地址(24bit)
//NumByteToWrite:要写入的字节数(最大65535)
u8 W25QXX_BUFFER[4096]; //1KB = 1024Byte(字节),则4KB = 4096Byte,每个Byte是8bit,而w25q128的最小单元为一个sector,大小为4k
//字节也叫Byte,是计算机数据的基本存储单位。
//8bit(位)=1Byte(字节)
//1024Byte(字节)=1KB
//1024KB=1MB
//1024MB=1GB
//1024GB=1TB
void W25QXX_Write(u8* pBuffer,u32 WriteAddr,u16 NumByteToWrite)
{
u32 secpos; //要写入数据的sector是第几个sector
u16 secoff; //在该sector上的偏移量
u16 secremain; //该sector剩余的空间
u16 i; //用于迭代
u8 * W25QXX_BUF; //当要写入的sector有未擦除的数据,则需要先把要写入的数据存入该buffer
W25QXX_BUF=W25QXX_BUFFER; //用一个buf指针指向前面定义的W25QXX_BUFFER,操作该指针就是操作W25QXX_BUFFER,便于调用一些需要传入指针的函数
//第一步,用要写入数据的地址进行运算,得出要写哪个(第几个)sector、写入位置偏移该sector起始地址多少、在该写入位置后该sector还剩余多少空间
//每个最小单元是一个sector,也就是4096Byte,
//则先求出这是第几个sector,再求出在该sector上偏离了多少
secpos=WriteAddr/4096;//扇区地址 //第几个sector
secoff=WriteAddr%4096;//在扇区内的偏移 //在该sector上的偏移量
secremain=4096-secoff;//扇区剩余空间大小 //该sector剩余的空间
//printf("ad:%X,nb:%X\r\n",WriteAddr,NumByteToWrite);//测试用
//第二步,判断要写入的数据长度是否大于剩余sector的空间长度,如果不大于,正常写,如果大于,需进行额外操作
if(NumByteToWrite<=secremain)secremain=NumByteToWrite; //不大于该sector剩余空间
while(1)
{
//第三步,判断要写入区域是否已经擦除完毕,如果没有,先进行擦除
//判断是否擦除
W25QXX_Read(W25QXX_BUF,secpos*4096,4096); //读出整个扇区的内容 //secpos*4096为该WriteAddr地址所在sector的起始地址
for(i=0;i<secremain;i++) //校验数据,判断该sector要写入区域是否被擦除,即从该WriteAddr地址开始到剩下的整个sector的内容是否为0XFF
{
if(W25QXX_BUF[secoff+i]!=0XFF)break; //需要擦除 //如果不是,break,i小于secremain,表明需要清除
}
//擦除or直接写入
if(i<secremain)//需要擦除 //正常情况下i应该等于secremain,如果小于,这表明上面迭代提前break,则要写的sector中有未擦除的内容
{
W25QXX_Erase_Sector(secpos); //擦除这个扇区 //把第secpos个sector整个擦除,也就是该WriteAddr地址所在的sector
for(i=0;i<secremain;i++) //擦除后再将要写入的数据复制进存储区(因为这是数组,所以要迭代复制数据)
{
W25QXX_BUF[i+secoff]=pBuffer[i];
}
W25QXX_Write_NoCheck(W25QXX_BUF,secpos*4096,4096); //上面把数据迭代复制进buffer后,这里再把数据buffer写入整个扇区
}
else
{
W25QXX_Write_NoCheck(pBuffer,WriteAddr,secremain); //已经确定要写入的区域已经被擦除过,可直接写入扇区剩余区间.
}
//第四步,系第二步的后续,如果要写入的数据长度大于剩余sector长度,则NumByteToWrite>secremain,进入下面这个part,否则不进入
if(NumByteToWrite==secremain)break;//写入结束了
else//写入未结束
{
//如果要写数据大于剩余空间,则从下一sector的起始位置开始写入数据
secpos++;//扇区地址增1
secoff=0;//偏移位置为0
//pBuffer系指针,指向一个存储着要写入数据的数组
//pBuffer指针向后移位secremain的长度,同时WriteAddr地址向后移位secremain的长度
//相当于要写入的最初数据和最初地址不变,但从下一sector开始写入数据,前一个sector的数据放弃不写入
//那么要写入的数据的长度就少了secremain的长度
pBuffer+=secremain; //指针偏移
WriteAddr+=secremain; //写地址偏移
NumByteToWrite-=secremain; //字节数递减
//现在再判断,现在要写入的数据长度是否还大于一个sector
//如果仍然大于,那么首先显然NumByteToWrite仍然大于secremain,下次还会进入该函数块
//同时,我们将secremain设为4096,也就是我们下次做完再次移位后,从sector的起始地址开始写入,则secremain自然就是4096了
//如此反复,直到最后能够直接写入为止
//注意,第四步的内容只是来控制相关指针的移位和数据的变化,但是数据还是会在前三步写入
//也就是说,如果要写入数据大于该sector剩余空间,首先和普通情况一样会把当前sector剩余部分写入数据
//只不过会额外进入第四步,也就是指针移位,进行下一个sector的继续写入
//毕竟数据量大,要在循环中不断执行不断写入直到最后数据写入完成
if(NumByteToWrite>4096)secremain=4096; //下一个扇区还是写不完
else secremain=NumByteToWrite; //下一个扇区可以写完了
}
}
}
.
说了这些个函数,和STM32与W25Q128的通信有什么关系呢?
首先,我们已经通过SPI初始化配置,建立了二者之间的连接。此时,已经可以完成收发数据的操作了。上面提到的两个函数例子,则是根据W25Q128的芯片手册编写的函数,通过这些函数,能够进行更为复杂的数据传输,比如连续读、连续写、擦除、etc.
以上。