目录
CNN卷积神经网络
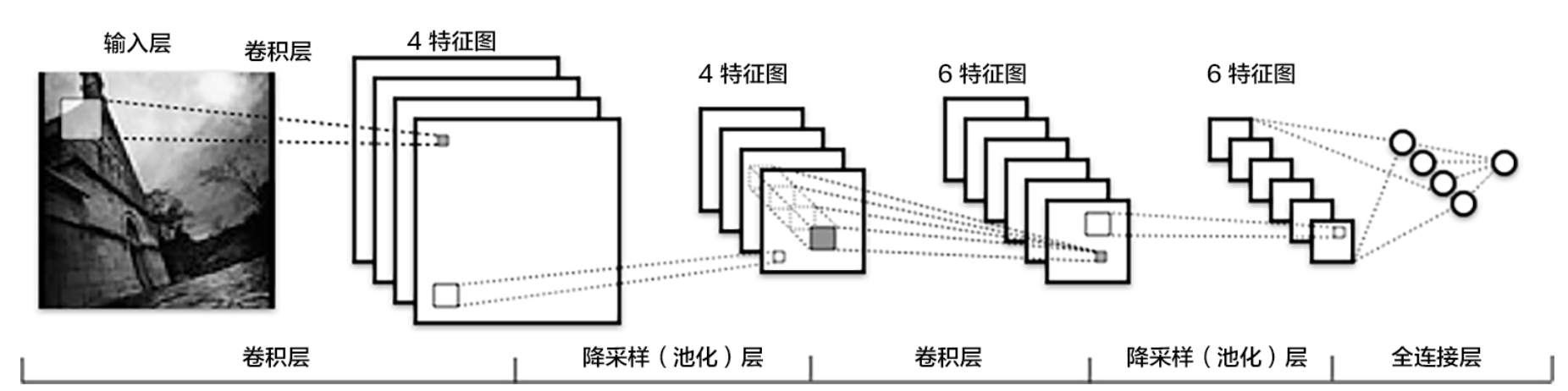
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification),因此也被称为“平移不变人工神经网络(Shift-Invariant Artificial Neural Networks, SIANN)” 。
对卷积神经网络的研究始于二十世纪80至90年代,时间延迟网络和LeNet-5是最早出现的卷积神经网络;在二十一世纪后,随着深度学习理论的提出和数值计算设备的改进,卷积神经网络得到了快速发展,并被应用于计算机视觉、自然语言处理等领域。
卷积神经网络仿造生物的视知觉(visual perception)机制构建,可以进行监督学习和非监督学习,其隐含层内的卷积核参数共享和层间连接的稀疏性使得卷积神经网络能够以较小的计算量对格点化(grid-like topology)特征,例如像素和音频进行学习、有稳定的效果且对数据没有额外的特征工程(feature engineering)要求。
CNN模型特性
局部连接
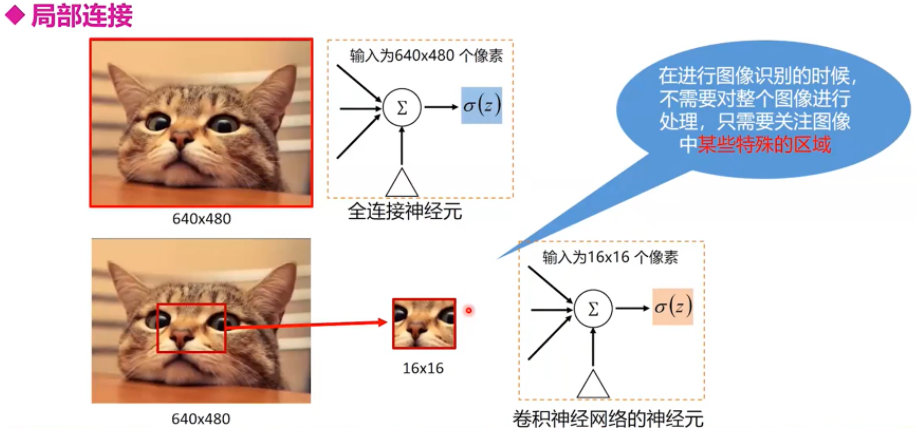
传统的网络在数据的处理上具有一个致命的缺点:可扩展性差。
在应对图像,视频数据的处理时,假设输入的大小是一个 1000 ∗ 1000 ∗ 3 1000*1000*3 1000∗1000∗3的RGB图像,那么输入层是由 3 ∗ 1 0 6 3*10^6 3∗106个神经元组成,假设(实际上也大致应该)隐藏层同样由 3 ∗ 1 0 6 3*10^6 3∗106个神经元构成,那么对于全连接层的前馈网络来说,权重矩阵一共有 3 ∗ 1 0 6 ∗ 3 ∗ 1 0 6 = 9 ∗ 1 0 12 3*10^6*3*10^6=9*10^{12} 3∗106∗3∗106=9∗1012个参数,而这还是没有计算后面更多的隐藏层的结果,显然,参数的训练过程会变的及其耗时。
所以,卷积层的设计初衷是为了减少参数训练量,提高训练效率,由此引出局部连接,而不是全连接。而采用局部连接,隐藏层的每个神经元仅与图像中 10 ∗ 10 10*10 10∗10的局部图像相连接,那么此时的权值参数数量为 10 ∗ 10 ∗ 1 0 6 = 1 0 8 10*10*10^6 = 10^8 10∗10∗106=108,将直接减少4个数量级。
权值共享
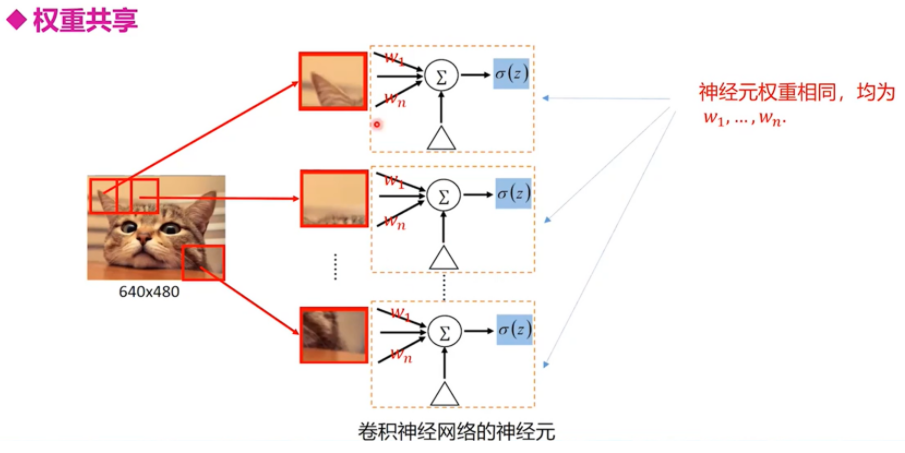
尽管减少了几个数量级,但参数数量依然较多。能不能再进一步减少呢?能!方法就是权值共享。具体做法是,在局部连接中隐藏层的每一个神经元连接的是一个 10 × 10 10 × 10 10×10的局部图像,因此有 10 × 10 10 × 10 10×10个权值参数,将这 10 × 10 10 × 10 10×10个权值参数共享给剩下的神经元,也就是说隐藏层中 1 0 6 10^6 106个神经元的权值参数相同,那么此时不管隐藏层神经元的数目是多少,需要训练的参数就是这 10 × 10 10 × 10 10×10个权值参数(也就是卷积核(也称滤波器)的大小),如上图。
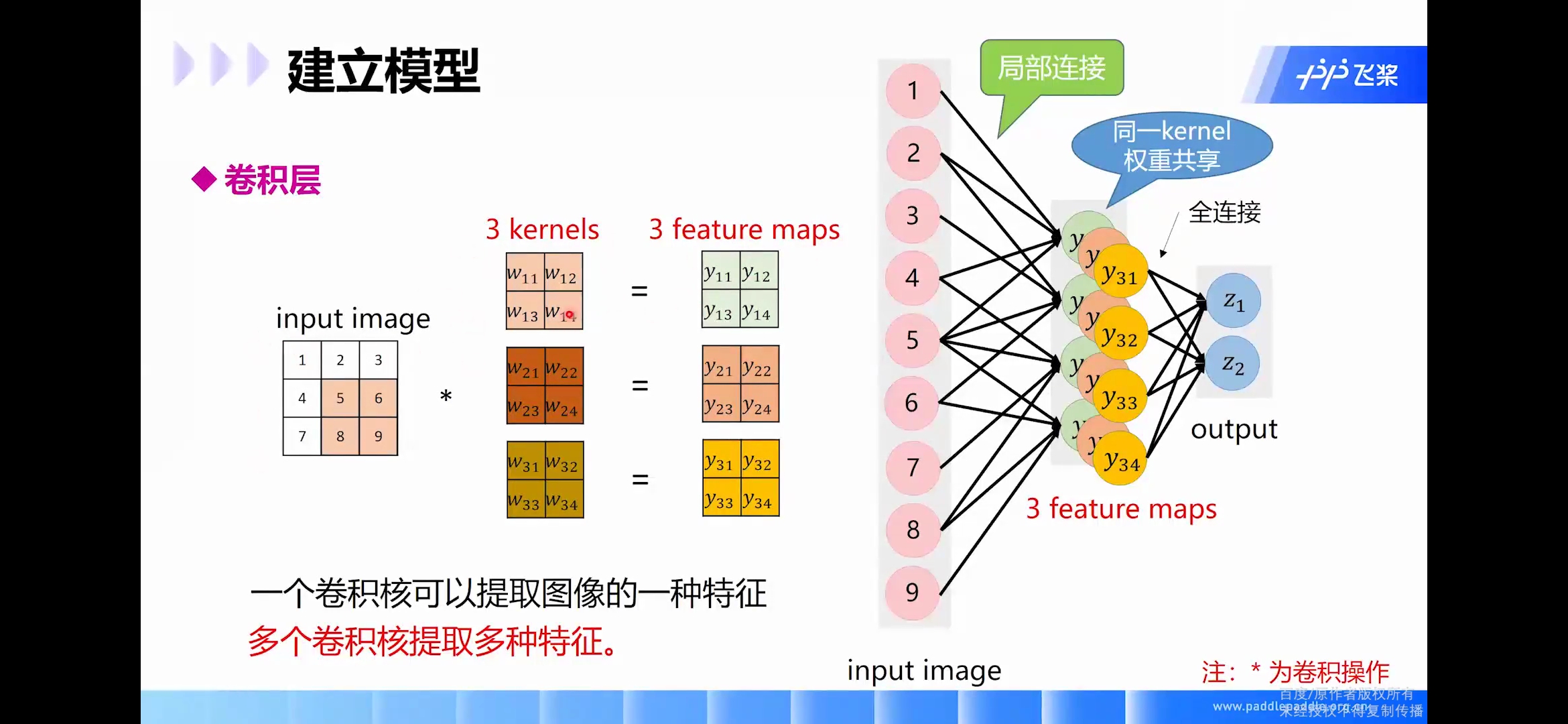
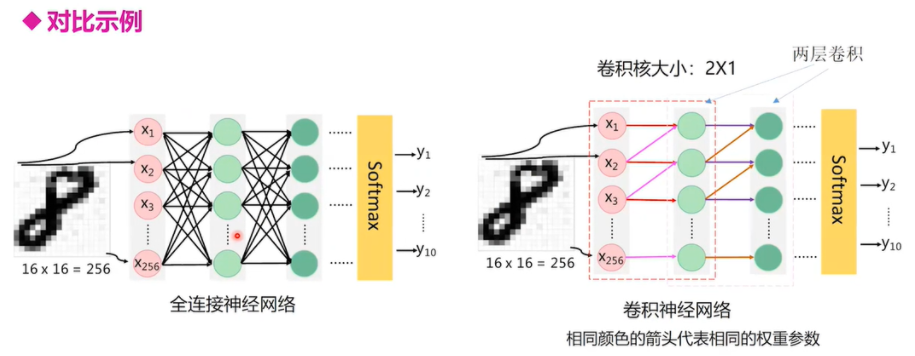
卷积对比全连接
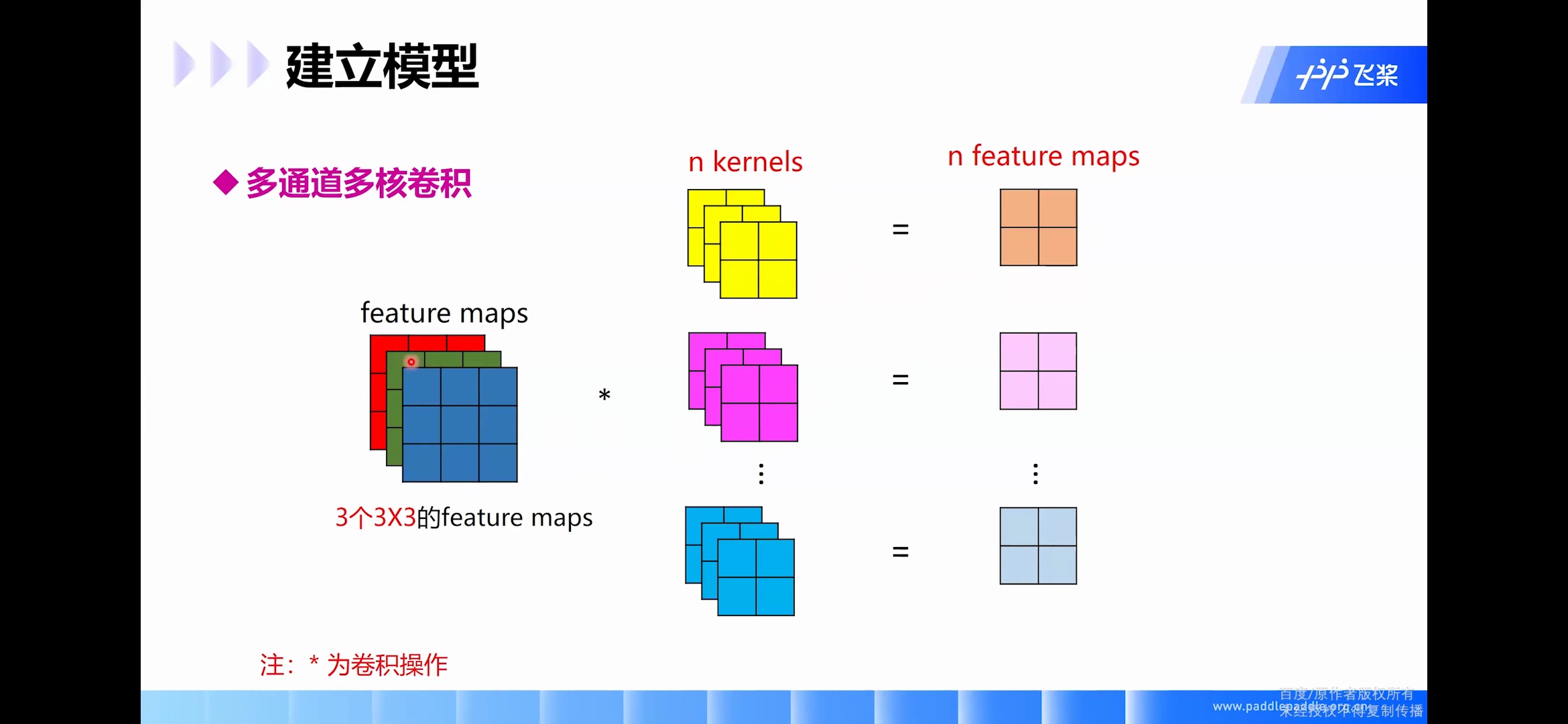
多通道卷积
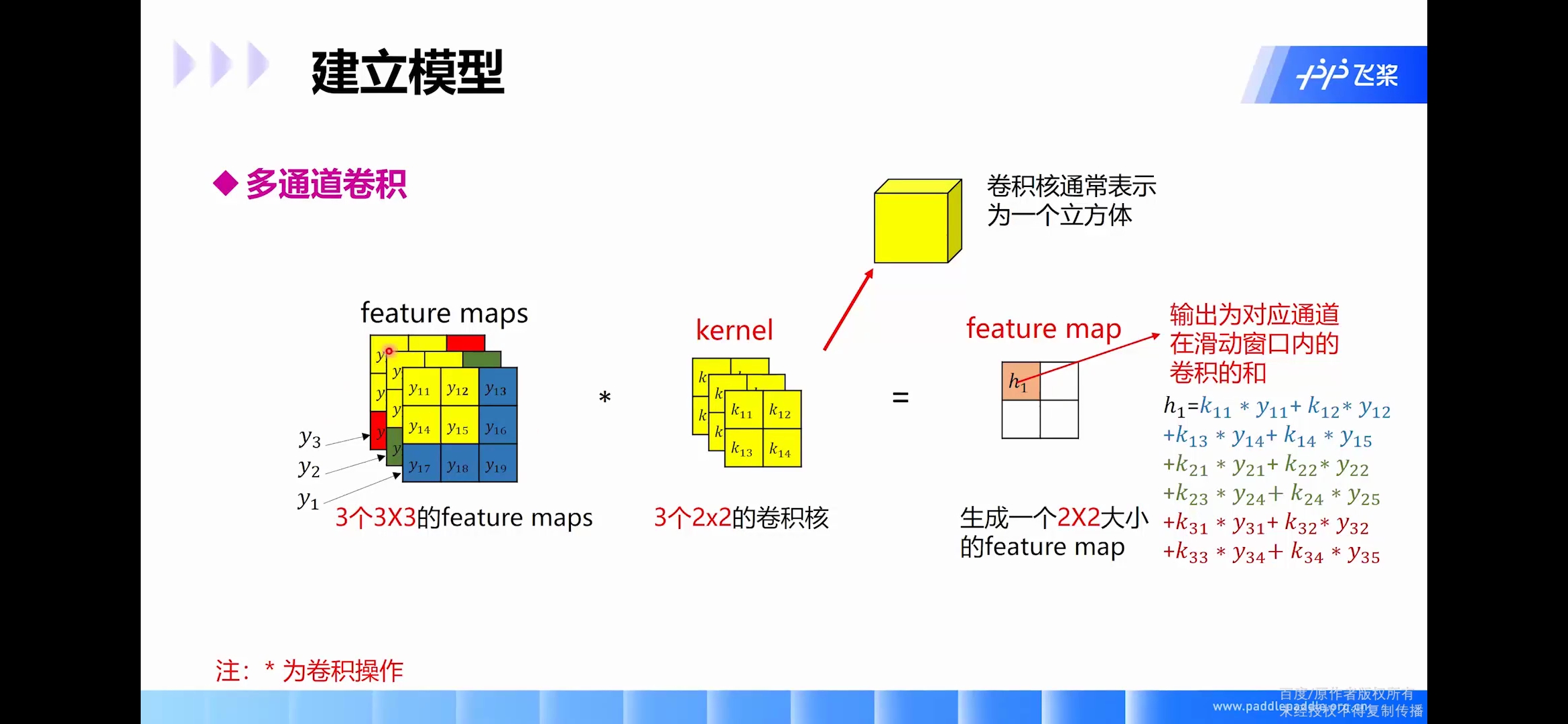
多通道多核卷积
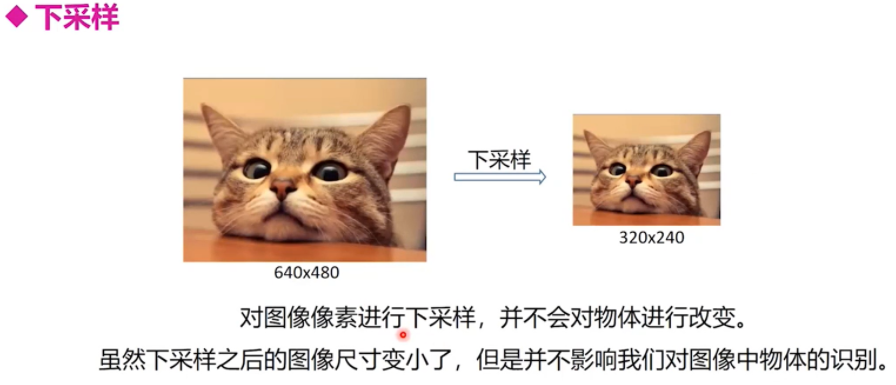
下采样
但是,这样仅提取了图像的一种特征,如果要多提取出一些特征,可以增加多个卷积核,不同的卷积核能够得到图像的不同映射下的特征,称之为Feature Map。如果有100个卷积核,最终的权值参数也仅为100 × 100 = 10^4个而已。另外,偏置参数也是共享的,同一种滤波器共享一个。
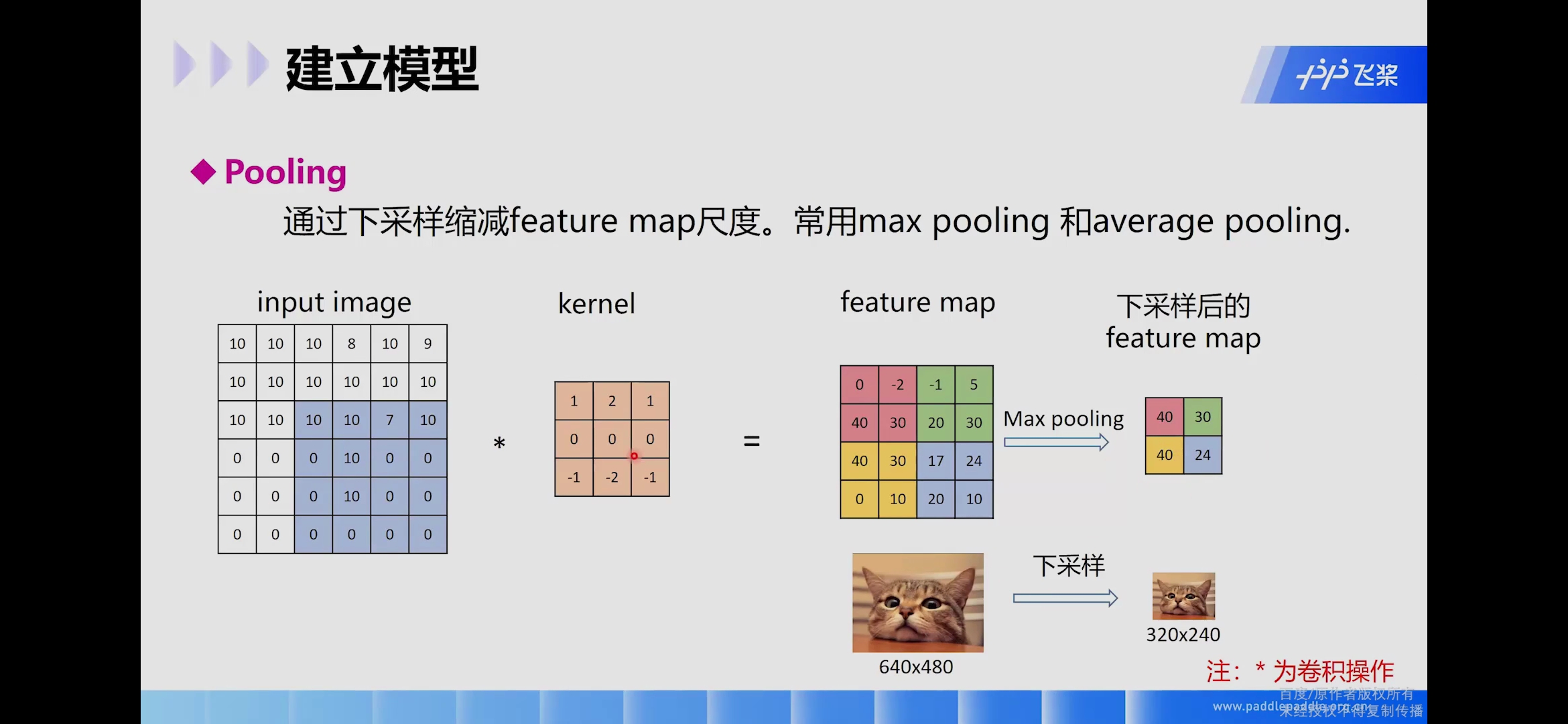
池化层的作用是对原始特征信号进行抽象,从而大幅度减少训练参数,另外还可以减轻模型过拟合的程度。
池化层一般使用mean-pooling(平均值)或者max-pooling(最大值)
pooling层(池化层)的输入一般来源于上一个卷积层,主要有以下几个作用:
-
保留主要的特征,同时减少下一层的参数和计算量,防止过拟合;
-
保持某种不变性,包括translation(平移),rotation(旋转),scale(尺度)
卷积神经网络的核心思想是:局部感受野(local field),权值共享以及时间或空间亚采样这三种思想结合起来,获得了某种程度的位移、尺度、形变不变性。
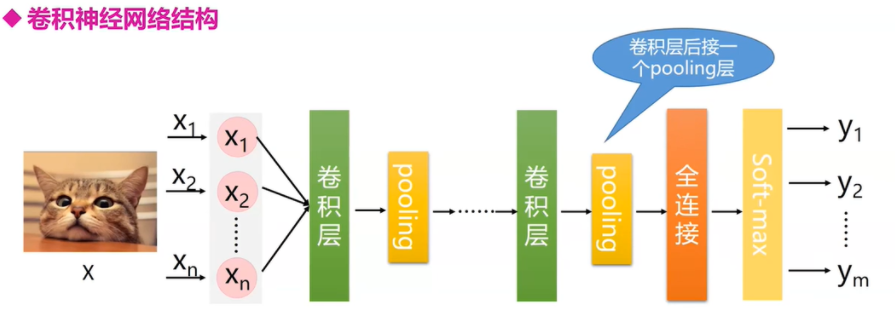
CNN网络结构
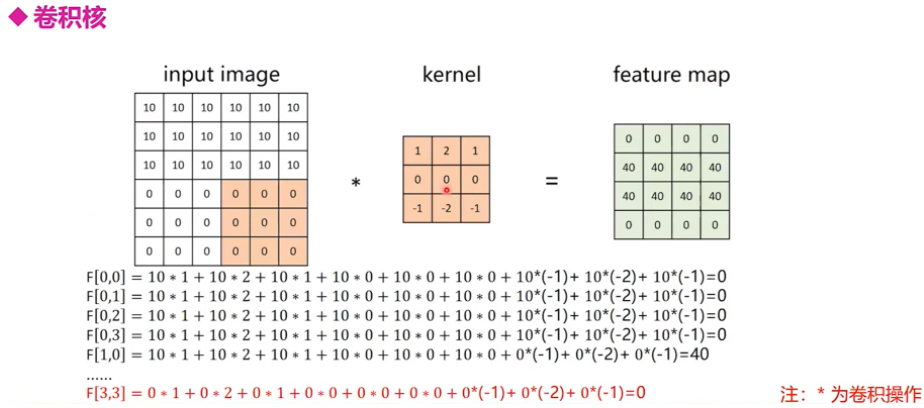
卷积过程
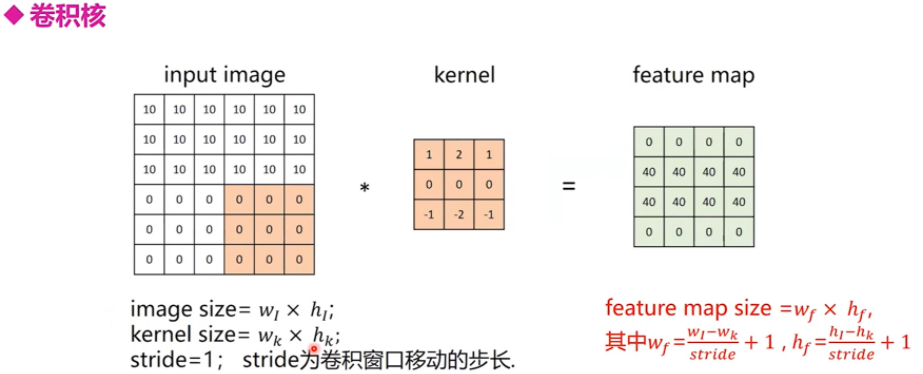
下面是卷积过程的示意图以及卷积后的尺寸计算方法:
LeNet
LeNet-5是一个较简单的卷积神经网络。下图显示了其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用高斯径向基作为输出层得到最后的分类类型。
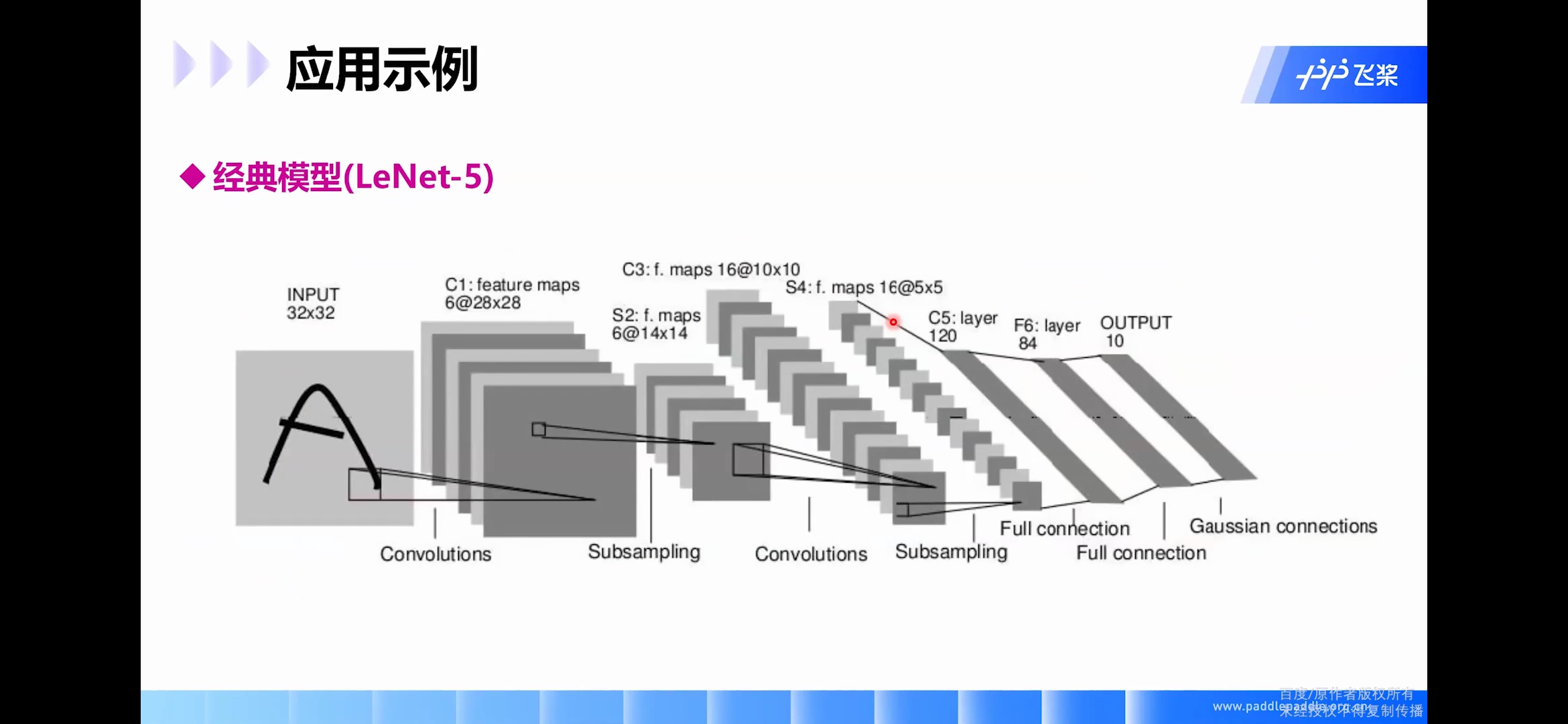
LeNet-5 这个网络虽然很小,但是它包含了深度学习的基本模块:卷积层,池化层,全连接层。
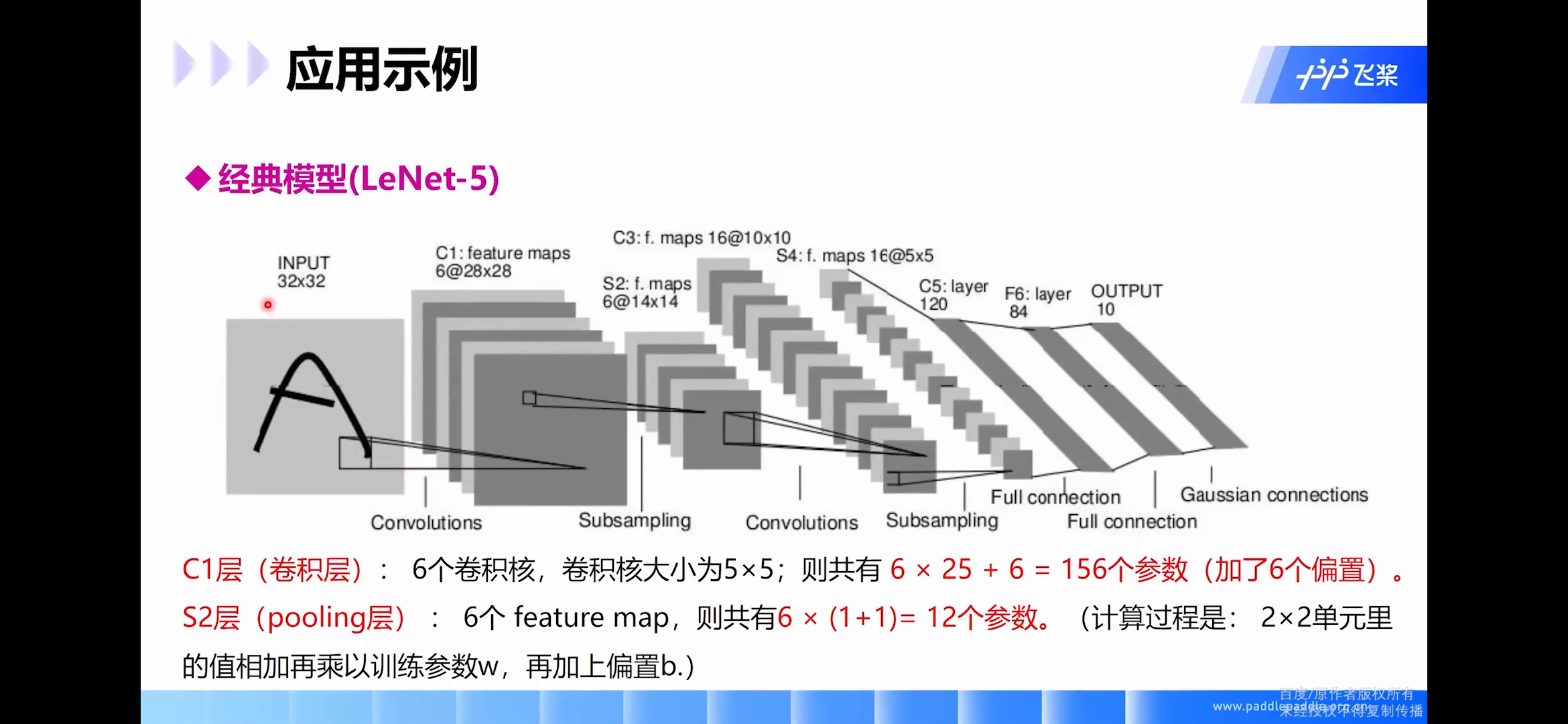
C1卷积层
-
输入图片: 32 ∗ 32 32*32 32∗32
-
卷积核大小: 5 ∗ 5 5*5 5∗5
-
卷积核种类: 6 6 6
-
输出featuremap大小: 28 ∗ 28 ( 32 − 5 + 1 ) = 28 28*28 (32-5+1)=28 28∗28(32−5+1)=28
-
神经元数量: 28 ∗ 28 ∗ 6 28*28*6 28∗28∗6
-
可训练参数: ( 5 ∗ 5 + 1 ) ∗ 6 (5*5+1) * 6 (5∗5+1)∗6(每个滤波器 5 ∗ 5 = 25 5*5=25 5∗5=25个unit参数和一个bias参数,一共 6 6 6个滤波器)
-
连接数: ( 5 ∗ 5 + 1 ) ∗ 6 ∗ 28 ∗ 28 = 122304 (5*5+1)*6*28*28=122304 (5∗5+1)∗6∗28∗28=122304
详细说明:对输入图像进行第一次卷积运算(使用 6 个大小为 5 ∗ 5 5*5 5∗5 的卷积核),得到6个C1特征图(6个大小为 28 ∗ 28 28*28 28∗28的 feature maps, 32 − 5 + 1 = 28 32-5+1=28 32−5+1=28)。我们再来看看需要多少个参数,卷积核的大小为 5 ∗ 5 5*5 5∗5,总共就有 6 ∗ ( 5 ∗ 5 + 1 ) = 156 6*(5*5+1)=156 6∗(5∗5+1)=156个参数,其中+1是表示一个核有一个bias。对于卷积层C1,C1内的每个像素都与输入图像中的 5 ∗ 5 5*5 5∗5个像素和1个bias有连接,所以总共有 156 ∗ 28 ∗ 28 = 122304 156*28*28=122304 156∗28∗28=122304个连接(connection)。有 122304 122304 122304个连接,但是我们只需要学习 156 156 156个参数,主要是通过局部连接和权值共享实现的。
S2池化层
-
输入: 28 ∗ 28 28*28 28∗28
-
采样区域: 2 ∗ 2 2*2 2∗2
-
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
-
采样种类:6
-
输出featureMap大小: 14 ∗ 14 ( 28 / 2 ) 14*14(28/2) 14∗14(28/2)
-
神经元数量: 14 ∗ 14 ∗ 6 14*14*6 14∗14∗6
-
可训练参数: 2 ∗ 6 2*6 2∗6(和的权+偏置)
-
连接数: ( 2 ∗ 2 + 1 ) ∗ 6 ∗ 14 ∗ 14 (2*2+1)*6*14*14 (2∗2+1)∗6∗14∗14
S2中每个特征图的大小是C1中特征图大小的1/4。
详细说明:第一次卷积之后紧接着就是池化运算,使用 2 ∗ 2 2*2 2∗2核 进行池化,于是得到了S2,6个 14 ∗ 14 14*14 14∗14的 特征图(28/2=14)。S2这个pooling层是对C1中的 2 ∗ 2 2*2 2∗2区域内的像素求和乘以一个权值系数再加上一个偏置,然后将这个结果再做一次映射。于是每个池化核有两个训练参数,所以共有 2 x 6 = 12 2x6=12 2x6=12个训练参数,但是有 5 ∗ 14 ∗ 14 ∗ 6 = 5880 5*14*14*6=5880 5∗14∗14∗6=5880个连接。
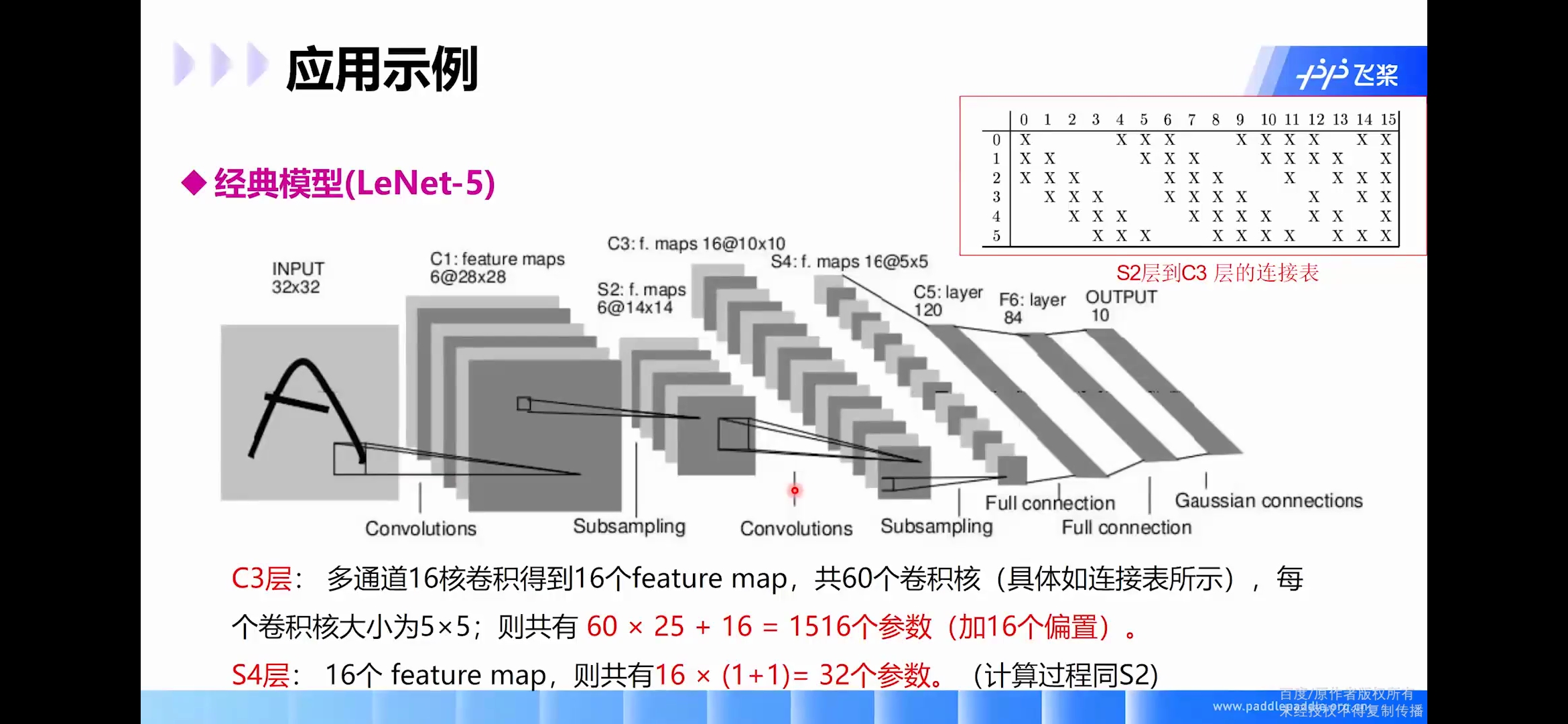
C3卷积层
-
输入:S2中所有6个或者几个特征map组合
-
卷积核大小: 5 ∗ 5 5*5 5∗5
-
卷积核种类:16
-
输出featureMap大小: 10 ∗ 10 ( 14 − 5 + 1 ) = 10 10*10 (14-5+1)=10 10∗10(14−5+1)=10
C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的特征map的不同组合。
存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入。则:可训练参数: 6 ∗ ( 3 ∗ 5 ∗ 5 + 1 ) + 6 ∗ ( 4 ∗ 5 ∗ 5 + 1 ) + 3 ∗ ( 4 ∗ 5 ∗ 5 + 1 ) + 1 ∗ ( 6 ∗ 5 ∗ 5 + 1 ) = 1516 6*(3*5*5+1)+6*(4*5*5+1)+3*(4*5*5+1)+1*(6*5*5+1)=1516 6∗(3∗5∗5+1)+6∗(4∗5∗5+1)+3∗(4∗5∗5+1)+1∗(6∗5∗5+1)=1516
-
连接数: 10 ∗ 10 ∗ 1516 = 151600 10*10*1516=151600 10∗10∗1516=151600
详细说明:第一次池化之后是第二次卷积,第二次卷积的输出是C3,16个 10 x 10 10x10 10x10的特征图,卷积核大小是 5 ∗ 5 5*5 5∗5 我们知道S2 有6个 14 ∗ 14 14*14 14∗14 的特征图,怎么从6 个特征图得到 16个特征图了? 这里是通过对S2 的特征图特殊组合计算得到的16个特征图。具体如下:

C3的前6个feature map(对应上图第一个红框的6列)与S2层相连的3个feature map相连接(上图第一个红框),后面6个feature map与S2层相连的4个feature map相连接(上图第二个红框),后面3个feature map与S2层部分不相连的4个feature map相连接,最后一个与S2层的所有feature map相连。卷积核大小依然为 5 ∗ 5 5*5 5∗5,所以总共有 6 ∗ ( 3 ∗ 5 ∗ 5 + 1 ) + 6 ∗ ( 4 ∗ 5 ∗ 5 + 1 ) + 3 ∗ ( 4 ∗ 5 ∗ 5 + 1 ) + 1 ∗ ( 6 ∗ 5 ∗ 5 + 1 ) = 1516 6*(3*5*5+1)+6*(4*5*5+1)+3*(4*5*5+1)+1*(6*5*5+1)=1516 6∗(3∗5∗5+1)+6∗(4∗5∗5+1)+3∗(4∗5∗5+1)+1∗(6∗5∗5+1)=1516个参数。而图像大小为 10 ∗ 10 10*10 10∗10,所以共有151600个连接。
S4池化层
-
输入: 10 ∗ 10 10*10 10∗10
-
采样区域: 2 ∗ 2 2*2 2∗2
-
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
-
采样种类:16
-
输出featureMap大小: 5 ∗ 5 ( 10 / 2 ) 5*5(10/2) 5∗5(10/2)
-
神经元数量: 5 ∗ 5 ∗ 16 = 400 5*5*16=400 5∗5∗16=400
-
可训练参数: 2 ∗ 16 = 32 2*16=32 2∗16=32(和的权+偏置)
-
连接数: 16 ∗ ( 2 ∗ 2 + 1 ) ∗ 5 ∗ 5 = 2000 16*(2*2+1)*5*5=2000 16∗(2∗2+1)∗5∗5=2000
S4中每个特征图的大小是C3中特征图大小的1/4
详细说明:S4是pooling层,窗口大小仍然是 2 ∗ 2 2*2 2∗2,共计16个feature map,C3层的16个 10 x 10 10x10 10x10的图分别进行以 2 x 2 2x2 2x2为单位的池化得到16个 5 x 5 5x5 5x5的特征图。这一层有 2 x 16 2x16 2x16共32个训练参数, 5 x 5 x 5 x 16 = 2000 个 5x5x5x16=2000个 5x5x5x16=2000个连接。连接的方式与S2层类似。
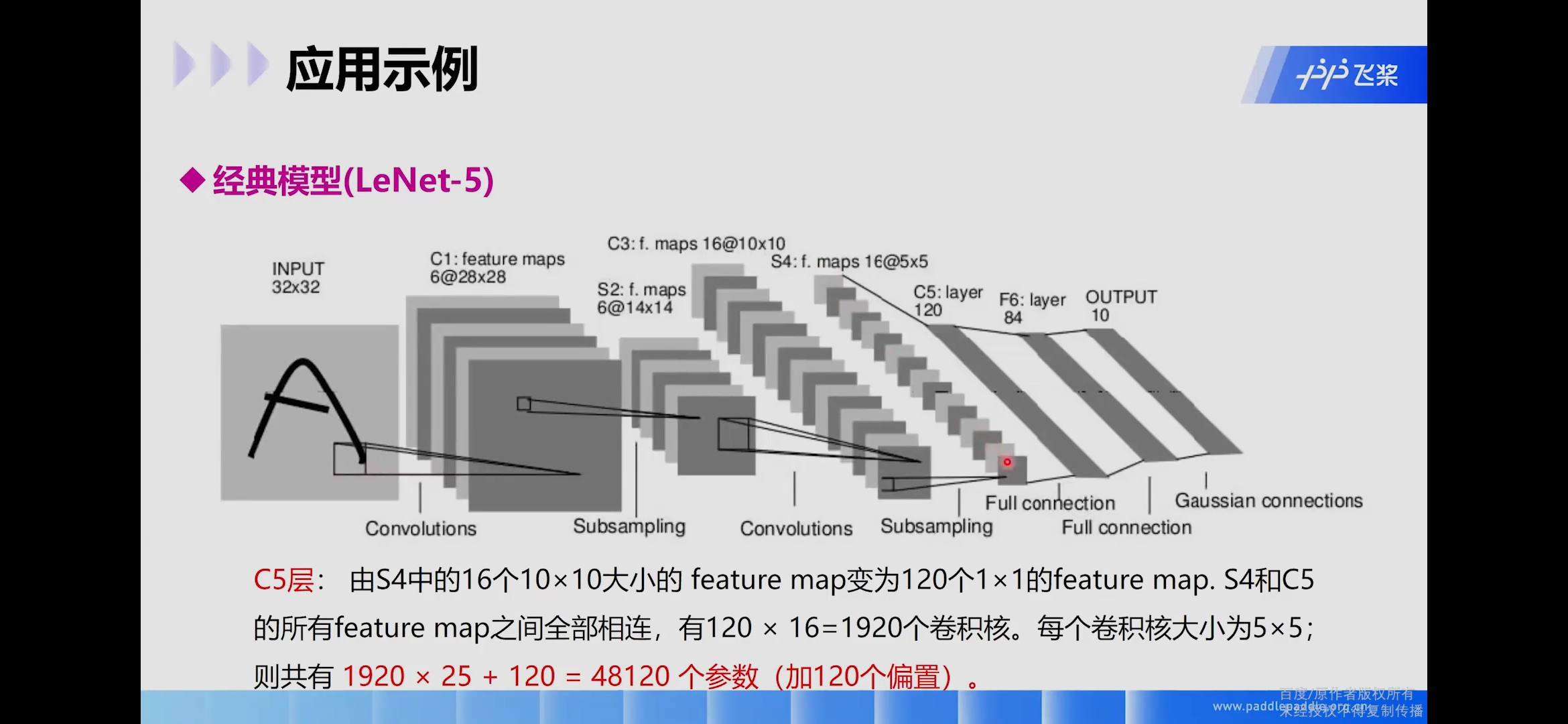
C5卷积层
-
输入:S4层的全部16个单元特征map(与s4全相连)
-
卷积核大小: 5 ∗ 5 5*5 5∗5
-
卷积核种类:120
-
输出featureMap大小: 1 ∗ 1 ( 5 − 5 + 1 ) 1*1(5-5+1) 1∗1(5−5+1)
-
可训练参数/连接: 120 ∗ ( 16 ∗ 5 ∗ 5 + 1 ) = 48120 120*(16*5*5+1)=48120 120∗(16∗5∗5+1)=48120
详细说明:C5层是一个卷积层。由于S4层的16个图的大小为 5 x 5 5x5 5x5,与卷积核的大小相同,所以卷积后形成的图的大小为 1 x 1 1x1 1x1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有 ( 5 x 5 x 16 + 1 ) x 120 = 48120 (5x5x16+1)x120 = 48120 (5x5x16+1)x120=48120个参数,同样有48120个连接。

F6全连接层
-
输入:c5 120维向量
-
计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出。
-
可训练参数: 84 ∗ ( 120 + 1 ) = 10164 84*(120+1)=10164 84∗(120+1)=10164
详细说明:6层是全连接层。F6层有84个节点,对应于一个 7 x 12 7x12 7x12的比特图,-1表示白色,1表示黑色,这样每个符号的比特图的黑白色就对应于一个编码。该层的训练参数和连接数是 ( 120 + 1 ) x 84 = 10164 (120 + 1)x84=10164 (120+1)x84=10164。
结论
- LeNet-5是一种用于手写体字符识别的非常高效的卷积神经网络。
- 卷积神经网络能够很好的利用图像的结构信息。
- 卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定。
代码实现: paddle2.0实现CNN
如何根据据图像的视觉内容为图像赋予一个语义类别是图像分类的目标,也是图像检索、图像内容分析和目标识别等问题的基础。
这里利用利用飞桨paddlepaddle2.0动态图搭建一个卷积神经网络,对包含斑马线的马路和不包含斑马线的马路图像进行分类。
本实践所用数据集均来自互联网,请勿用于商务用途。
import os
import zipfile
import random
import paddle
import numpy as np
import matplotlib.pyplot as plt
import PIL.Image as Image
from paddle.io import Dataset
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable, Mapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sized
'''
Hyperparameters
'''
train_parameters = {
"input_size": [3, 50, 50], #输入图片的shape
"class_dim": 2, #分类数
"src_path":"data/data55791/Zebra.zip", #原始数据集路径
"target_path":"/home/aistudio/data/", #要解压的路径
"train_list_path": "/home/aistudio/data/train.txt", #train.txt路径
"eval_list_path": "/home/aistudio/data/eval.txt", #eval.txt路径
"label_dict":{
'0':'zebra crossing','1':'others'}, #标签字典
"num_epochs": 20, #训练轮数
"train_batch_size": 64, #训练时每个批次的大小
"learning_strategy": {
#优化函数相关的配置
"lr": 0.001 #超参数学习率
},
'skip_steps': 2, #每N个批次打印一次结果
'save_steps': 10, #每N个批次保存一次模型参数
"checkpoints": "/home/aistudio/work/checkpoints" #保存的路径
}
一、数据准备
(1)解压原始数据集
(2)按照比例划分训练集与验证集
(3)乱序,生成数据列表
(4)定义数据读取器
#解压原始数据集
def unzip_data(src_path,target_path):
'''
解压原始数据集,将src_path路径下的zip包解压至target_path目录下
'''
if(not os.path.isdir(target_path + "zebra crossing")):
z = zipfile.ZipFile(src_path, 'r')
z.extractall(path=target_path)
z.close()
print('数据集解压完成')
else:
print('文件已存在')
def get_data_list(target_path,train_list_path,eval_list_path):
'''
生成数据列表
'''
data_list_path_1=target_path+"zebra crossing/"
data_list_path_2=target_path+"others/"
class_dirs = os.listdir(data_list_path_1)
all_data_list = []
for im in os.listdir(data_list_path_1):
img_path = target_path+"zebra crossing/" + im
all_data_list.append(img_path + '\t' + '0'+'\n')
for im in os.listdir(data_list_path_2):
img_path = target_path+"others/" + im
all_data_list.append(img_path + '\t' + '1' + '\n')
#对列表进行乱序
random.shuffle(all_data_list)
with open(train_list_path, 'a') as f1:
with open(eval_list_path, 'a') as f2:
for ind, img_path_label in enumerate(all_data_list):
#划分测试集和训练集
if ind % 10 == 0:
f2.write(img_path_label)
else:
f1.write(img_path_label)
print ('生成数据列表完成!')
#参数初始化
src_path = train_parameters['src_path']
target_path = train_parameters['target_path']
train_list_path = train_parameters['train_list_path']
eval_list_path = train_parameters['eval_list_path']
#解压原始数据到指定路径
unzip_data(src_path, target_path)
#每次生成数据列表前,首先清空train.txt和eval.txt
with open(train_list_path, 'w') as f:
f.seek(0)
f.truncate()
with open(eval_list_path, 'w') as f:
f.seek(0)
f.truncate()
#生成数据列表
get_data_list(target_path, train_list_path, eval_list_path)
文件已存在
生成数据列表完成!
class dataset(Dataset):
def __init__(self, data_path, mode='train'):
"""
数据读取器
:param data_path: 数据集所在路径
:param mode: train or eval
"""
super().__init__()
self.data_path = data_path
self.img_paths = []
self.labels = []
if mode == 'train':
with open(os.path.join(self.data_path, "train.txt"), "r", encoding="utf-8") as f:
self.info = f.readlines()
for img_info in self.info:
img_path, label = img_info.strip().split('\t')
self.img_paths.append(img_path)
self.labels.append(int(label))
else:
with open(os.path.join(self.data_path, "eval.txt"), "r", encoding="utf-8") as f:
self.info = f.readlines()
for img_info in self.info:
img_path, label = img_info.strip().split('\t')
self.img_paths.append(img_path)
self.labels.append(int(label))
def __getitem__(self, index):
"""
获取一组数据
:param index: 文件索引号
:return:
"""
# 第一步打开图像文件并获取label值
img_path = self.img_paths[index]
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1)) / 255
label = self.labels[index]
label = np.array([label], dtype="int64")
return img, label
def print_sample(self, index: int = 0):
print("文件名", self.img_paths[index], "\t标签值", self.labels[index])
def __len__(self):
return len(self.img_paths)
#训练数据加载
train_dataset = dataset('/home/aistudio/data', mode='train')
train_loader = paddle.io.DataLoader(train_dataset,
batch_size=train_parameters['train_batch_size'],
shuffle=True,
drop_last=True
)
#测试数据加载
eval_dataset = dataset('/home/aistudio/data', mode='eval')
eval_loader = paddle.io.DataLoader(eval_dataset,
batch_size=train_parameters['train_batch_size'],
shuffle=False
)
train_dataset.print_sample(200)
print(train_dataset.__len__())
eval_dataset.print_sample(0)
print(eval_dataset.__len__())
print(eval_dataset.__getitem__(10)[0].shape)
print(eval_dataset.__getitem__(10)[1].shape)
文件名 /home/aistudio/data/zebra crossing/67.png 标签值 0
397
文件名 /home/aistudio/data/others/30.png 标签值 1
45
(3, 50, 50)
(1,)
二、模型配置
卷积网络示例:
#定义卷积网络
class MyCNN(paddle.nn.Layer):
def __init__(self):
super(MyCNN,self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=3, #通道数
out_channels=16, #卷积核个数
kernel_size=3, #卷积核大小
stride=1) #卷积步长1, 特征图16*48*48
self.relu1 = paddle.nn.ReLU()
self.pooling1 = paddle.nn.MaxPool2D(kernel_size=2, #池化核大小
stride=2) #池化步长2, 特征图16*24*24
self.conv2 = paddle.nn.Conv2D(in_channels=16, #通道数
out_channels = 32, #卷积核个数
kernel_size=3, #卷积核大小
stride=1) #卷积步长1, 特征图32*22*22
self.pooling2 = paddle.nn.MaxPool2D(kernel_size=2, #池化核大小
stride=2) #池化步长2, 特征图32*11*11
self.fc = paddle.nn.Linear(32*11*11, 2)
self.out = paddle.nn.Softmax()
#网络的前向计算过程
def forward(self, input):
x = self.conv1(input)
x = self.relu1(x)
x = self.pooling1(x)
x = self.conv2(x)
x = self.pooling2(x)
# 卷积层的输出数据格式是[N, C, H, W](num, channel, height, weight),在输入全连接层时,需将特征图拉平会自动将数据拉平.
x = paddle.reshape(x, shape=[-1, 32*11*11])
x = self.fc(x)
out = self.out(x)
return out
三、模型训练
def draw_process(title,color,iters,data,label):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel(label, fontsize=20)
plt.plot(iters, data,color=color,label=label)
plt.legend()
plt.grid()
plt.show()
model = MyCNN()
model.train()
cross_entropy = paddle.nn.CrossEntropyLoss()
optimizer = paddle.optimizer.Adam(learning_rate=train_parameters['learning_strategy']['lr'],
parameters=model.parameters())
steps = 0
Iters, total_loss, total_acc = [], [], []
for epo in range(train_parameters['num_epochs']):
for _, data in enumerate(train_loader()):
steps += 1
x_data = data[0]
y_data = data[1]
predicts = model(x_data) # forward
loss = cross_entropy(predicts, y_data)
acc = paddle.metric.accuracy(predicts, y_data)
loss.backward() # backward
optimizer.step() # cal
optimizer.clear_grad()
if steps % train_parameters["skip_steps"] == 0:
Iters.append(steps)
total_loss.append(loss.numpy()[0])
total_acc.append(acc.numpy()[0])
#打印中间过程
print('epo: {}, step: {}, loss is: {}, acc is: {}'\
.format(epo, steps, loss.numpy(), acc.numpy()))
#保存模型参数
if steps % train_parameters["save_steps"] == 0:
save_path = train_parameters["checkpoints"]+"/"+"save_dir_" + str(steps) + '.pdparams'
print('save model to: ' + save_path)
paddle.save(model.state_dict(),save_path)
paddle.save(model.state_dict(), train_parameters["checkpoints"] + "/" + "save_dir_final.pdparams")
draw_process("trainning loss", "red",Iters,total_loss,"trainning loss")
draw_process("trainning acc", "green",Iters,total_acc,"trainning acc")
epo: 0, step: 2, loss is: [0.7148403], acc is: [0.5625]
epo: 0, step: 4, loss is: [0.6895498], acc is: [0.59375]
epo: 0, step: 6, loss is: [0.60709834], acc is: [0.6875]
epo: 0, step: 8, loss is: [0.7030651], acc is: [0.53125]
epo: 0, step: 10, loss is: [0.67844373], acc is: [0.46875]
save model to: /home/aistudio/work/checkpoints/save_dir_10.pdparams
epo: 0, step: 12, loss is: [0.49845123], acc is: [0.875]
epo: 1, step: 14, loss is: [0.5787455], acc is: [0.65625]
epo: 1, step: 16, loss is: [0.48128325], acc is: [0.84375]
epo: 1, step: 18, loss is: [0.5321136], acc is: [0.84375]
epo: 1, step: 20, loss is: [0.4660177], acc is: [0.9375]
save model to: /home/aistudio/work/checkpoints/save_dir_20.pdparams
epo: 1, step: 22, loss is: [0.44333333], acc is: [0.875]
epo: 1, step: 24, loss is: [0.3868885], acc is: [1.]
epo: 2, step: 26, loss is: [0.4308446], acc is: [0.96875]
epo: 2, step: 28, loss is: [0.39331633], acc is: [0.96875]
epo: 2, step: 30, loss is: [0.39981008], acc is: [0.9375]
save model to: /home/aistudio/work/checkpoints/save_dir_30.pdparams
epo: 2, step: 32, loss is: [0.4193061], acc is: [0.90625]
epo: 2, step: 34, loss is: [0.377001], acc is: [0.96875]
epo: 2, step: 36, loss is: [0.4178028], acc is: [0.90625]
epo: 3, step: 38, loss is: [0.39989206], acc is: [0.9375]
epo: 3, step: 40, loss is: [0.41626555], acc is: [0.90625]
save model to: /home/aistudio/work/checkpoints/save_dir_40.pdparams
epo: 3, step: 42, loss is: [0.36089516], acc is: [1.]
epo: 3, step: 44, loss is: [0.36414558], acc is: [0.96875]
epo: 3, step: 46, loss is: [0.37639767], acc is: [0.96875]
epo: 3, step: 48, loss is: [0.36954418], acc is: [0.96875]
epo: 4, step: 50, loss is: [0.375963], acc is: [0.96875]
save model to: /home/aistudio/work/checkpoints/save_dir_50.pdparams
epo: 4, step: 52, loss is: [0.4015602], acc is: [0.90625]
epo: 4, step: 54, loss is: [0.46315235], acc is: [0.84375]
epo: 4, step: 56, loss is: [0.33276558], acc is: [1.]
epo: 4, step: 58, loss is: [0.3827101], acc is: [0.9375]
epo: 4, step: 60, loss is: [0.43463326], acc is: [0.875]
save model to: /home/aistudio/work/checkpoints/save_dir_60.pdparams
epo: 5, step: 62, loss is: [0.381095], acc is: [0.9375]
epo: 5, step: 64, loss is: [0.4085356], acc is: [0.90625]
epo: 5, step: 66, loss is: [0.3803348], acc is: [0.9375]
epo: 5, step: 68, loss is: [0.3675652], acc is: [0.9375]
epo: 5, step: 70, loss is: [0.39328533], acc is: [0.90625]
save model to: /home/aistudio/work/checkpoints/save_dir_70.pdparams
epo: 5, step: 72, loss is: [0.47192407], acc is: [0.875]
epo: 6, step: 74, loss is: [0.3966875], acc is: [0.90625]
epo: 6, step: 76, loss is: [0.41393685], acc is: [0.90625]
epo: 6, step: 78, loss is: [0.40139204], acc is: [0.9375]
epo: 6, step: 80, loss is: [0.37965074], acc is: [0.9375]
save model to: /home/aistudio/work/checkpoints/save_dir_80.pdparams
epo: 6, step: 82, loss is: [0.38834658], acc is: [0.9375]
epo: 6, step: 84, loss is: [0.32356852], acc is: [1.]
epo: 7, step: 86, loss is: [0.32669067], acc is: [1.]
epo: 7, step: 88, loss is: [0.38792324], acc is: [0.9375]
epo: 7, step: 90, loss is: [0.36782396], acc is: [0.9375]
save model to: /home/aistudio/work/checkpoints/save_dir_90.pdparams
epo: 7, step: 92, loss is: [0.38812172], acc is: [0.9375]
epo: 7, step: 94, loss is: [0.3658573], acc is: [0.9375]
epo: 7, step: 96, loss is: [0.4440922], acc is: [0.84375]
epo: 8, step: 98, loss is: [0.4009146], acc is: [0.90625]
epo: 8, step: 100, loss is: [0.3958037], acc is: [0.90625]
save model to: /home/aistudio/work/checkpoints/save_dir_100.pdparams
epo: 8, step: 102, loss is: [0.3636878], acc is: [0.96875]
epo: 8, step: 104, loss is: [0.3166331], acc is: [1.]
epo: 8, step: 106, loss is: [0.38049397], acc is: [0.90625]
epo: 8, step: 108, loss is: [0.4454681], acc is: [0.875]
epo: 9, step: 110, loss is: [0.37812898], acc is: [0.9375]
save model to: /home/aistudio/work/checkpoints/save_dir_110.pdparams
epo: 9, step: 112, loss is: [0.3890608], acc is: [0.9375]
epo: 9, step: 114, loss is: [0.38411546], acc is: [0.9375]
epo: 9, step: 116, loss is: [0.37230837], acc is: [0.9375]
epo: 9, step: 118, loss is: [0.40269265], acc is: [0.90625]
epo: 9, step: 120, loss is: [0.378777], acc is: [0.9375]
save model to: /home/aistudio/work/checkpoints/save_dir_120.pdparams
epo: 10, step: 122, loss is: [0.41352493], acc is: [0.90625]
epo: 10, step: 124, loss is: [0.3810607], acc is: [0.9375]
epo: 10, step: 126, loss is: [0.4024356], acc is: [0.9375]
epo: 10, step: 128, loss is: [0.37185824], acc is: [0.96875]
epo: 10, step: 130, loss is: [0.34863114], acc is: [0.96875]
save model to: /home/aistudio/work/checkpoints/save_dir_130.pdparams
epo: 10, step: 132, loss is: [0.36834487], acc is: [0.96875]
epo: 11, step: 134, loss is: [0.35307792], acc is: [1.]
epo: 11, step: 136, loss is: [0.33746833], acc is: [1.]
epo: 11, step: 138, loss is: [0.34770882], acc is: [0.96875]
epo: 11, step: 140, loss is: [0.44570982], acc is: [0.84375]
save model to: /home/aistudio/work/checkpoints/save_dir_140.pdparams
epo: 11, step: 142, loss is: [0.324299], acc is: [1.]
epo: 11, step: 144, loss is: [0.35401386], acc is: [0.96875]
epo: 12, step: 146, loss is: [0.36484715], acc is: [0.9375]
epo: 12, step: 148, loss is: [0.41307065], acc is: [0.90625]
epo: 12, step: 150, loss is: [0.41396645], acc is: [0.875]
save model to: /home/aistudio/work/checkpoints/save_dir_150.pdparams
epo: 12, step: 152, loss is: [0.41937834], acc is: [0.90625]
epo: 12, step: 154, loss is: [0.39101875], acc is: [0.9375]
epo: 12, step: 156, loss is: [0.33049732], acc is: [1.]
epo: 13, step: 158, loss is: [0.34717253], acc is: [0.96875]
epo: 13, step: 160, loss is: [0.34983632], acc is: [0.96875]
save model to: /home/aistudio/work/checkpoints/save_dir_160.pdparams
epo: 13, step: 162, loss is: [0.41715348], acc is: [0.875]
epo: 13, step: 164, loss is: [0.36826068], acc is: [0.96875]
epo: 13, step: 166, loss is: [0.39370814], acc is: [0.90625]
epo: 13, step: 168, loss is: [0.3459985], acc is: [0.96875]
epo: 14, step: 170, loss is: [0.5231124], acc is: [0.71875]
save model to: /home/aistudio/work/checkpoints/save_dir_170.pdparams
epo: 14, step: 172, loss is: [0.42154548], acc is: [0.875]
epo: 14, step: 174, loss is: [0.3616383], acc is: [0.96875]
epo: 14, step: 176, loss is: [0.33795384], acc is: [1.]
epo: 14, step: 178, loss is: [0.32765335], acc is: [1.]
epo: 14, step: 180, loss is: [0.39511302], acc is: [0.90625]
save model to: /home/aistudio/work/checkpoints/save_dir_180.pdparams
epo: 15, step: 182, loss is: [0.32860917], acc is: [1.]
epo: 15, step: 184, loss is: [0.3611826], acc is: [0.96875]
epo: 15, step: 186, loss is: [0.32611483], acc is: [1.]
epo: 15, step: 188, loss is: [0.39886945], acc is: [0.90625]
epo: 15, step: 190, loss is: [0.32558006], acc is: [1.]
save model to: /home/aistudio/work/checkpoints/save_dir_190.pdparams
epo: 15, step: 192, loss is: [0.34058478], acc is: [0.96875]
epo: 16, step: 194, loss is: [0.32105055], acc is: [1.]
epo: 16, step: 196, loss is: [0.34628418], acc is: [0.96875]
epo: 16, step: 198, loss is: [0.36386782], acc is: [0.9375]
epo: 16, step: 200, loss is: [0.4198296], acc is: [0.875]
save model to: /home/aistudio/work/checkpoints/save_dir_200.pdparams
epo: 16, step: 202, loss is: [0.35994518], acc is: [0.9375]
epo: 16, step: 204, loss is: [0.32529515], acc is: [1.]
epo: 17, step: 206, loss is: [0.34999248], acc is: [0.96875]
epo: 17, step: 208, loss is: [0.39178577], acc is: [0.9375]
epo: 17, step: 210, loss is: [0.33880088], acc is: [1.]
save model to: /home/aistudio/work/checkpoints/save_dir_210.pdparams
epo: 17, step: 212, loss is: [0.38001025], acc is: [0.96875]
epo: 17, step: 214, loss is: [0.36098343], acc is: [0.96875]
epo: 17, step: 216, loss is: [0.36401796], acc is: [0.9375]
epo: 18, step: 218, loss is: [0.35103482], acc is: [0.96875]
epo: 18, step: 220, loss is: [0.3711744], acc is: [0.9375]
save model to: /home/aistudio/work/checkpoints/save_dir_220.pdparams
epo: 18, step: 222, loss is: [0.35279295], acc is: [0.96875]
epo: 18, step: 224, loss is: [0.41620624], acc is: [0.875]
epo: 18, step: 226, loss is: [0.3760463], acc is: [0.9375]
epo: 18, step: 228, loss is: [0.32052496], acc is: [1.]
epo: 19, step: 230, loss is: [0.433306], acc is: [0.84375]
save model to: /home/aistudio/work/checkpoints/save_dir_230.pdparams
epo: 19, step: 232, loss is: [0.34577215], acc is: [0.96875]
epo: 19, step: 234, loss is: [0.33326238], acc is: [1.]
epo: 19, step: 236, loss is: [0.44692433], acc is: [0.84375]
epo: 19, step: 238, loss is: [0.3720621], acc is: [0.96875]
epo: 19, step: 240, loss is: [0.3663571], acc is: [0.96875]
save model to: /home/aistudio/work/checkpoints/save_dir_240.pdparams


四、模型评估
'''
模型预测
'''
model__state_dict = paddle.load('work/checkpoints/save_dir_final.pdparams')
model_eval = MyCNN()
model_eval.set_state_dict(model__state_dict)
model_eval.eval()
accs = []
for _, data in enumerate(eval_loader()):
x_data = data[0]
y_data = data[1]
predicts = model_eval(x_data)
acc = paddle.metric.accuracy(predicts, y_data)
accs.append(acc.numpy()[0])
print('模型在验证集上的准确率为:',np.mean(accs))
模型在验证集上的准确率为: 0.96875
五、模型预测
def load_image(img_path):
'''
预测图片预处理
'''
img = Image.open(img_path)
# print(img.mode)
if img.mode != 'RGB':
img = img.convert('RGB')
img = img.resize((50, 50), Image.ANTIALIAS)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1)) / 255 # HWC to CHW 并像素归一化
return img
model__state_dict = paddle.load('work/checkpoints/save_dir_final.pdparams')
model_predict = MyCNN()
model_predict.set_state_dict(model__state_dict)
model_predict.eval()
infer_path='work/1.jpg'
infer_img = Image.open(infer_path)
plt.imshow(infer_img) #根据数组绘制图像
plt.show() #显示图像
#对预测图片进行预处理
infer_img = load_image(infer_path)
# print(type(infer_img))
infer_img = infer_img[np.newaxis,:, : ,:] #reshape(-1,3,50,50)
infer_img = paddle.to_tensor(infer_img)
results = model_predict(infer_img)
print(results)
results = paddle.nn.functional.softmax(results)
print("Zebra crossing:{:.2f}, Others:{:.2f}" .format(results.numpy()[0][0],results.numpy()[0][1]))

Tensor(shape=[1, 2], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[[0.99834311, 0.00165686]])
Zebra crossing:0.73, Others:0.27