文章目录
2、Partial-Final聚合(解决COUNT DISTINCT热点问题)
1、table.exec.mini-batch.enabled
2、table.exec.mini-batch.allow-latency
4、table.optimizer.reuse-sub-plan-enabled
一、MiniBatch的演进思路
1、MiniBatch版本
Flink 1.9.0 SQL(Blink Planner) 性能优化中一项重要的改进就是升级了微批模型,即 MiniBatch(也称作MicroBatch或MiniBatch2.0),在支持高吞吐场景发挥了重要作用。
MiniBatch与早期的MiniBatch1.0在微批的触发机制略有不同。原理同样是缓存一定的数据后再触发处理,以减少对State的访问,从而提升吞吐和减少数据的输出量
MiniBatch与早期的MiniBatch1.0对比如下:
1、MiniBatch1.0主要依靠在每个Task上注册的Timer线程来触发微批,需要消耗一定的线程调度性能。
2、MiniBatch是MiniBatch1.0的升级版,主要要基于事件消息来触发微批,事件消息会按您指定的时间间隔在源头插入。MiniBatch在元素序列化效率、反压表现、吞吐和延迟性能上都要优于胜于MiniBatch1.0
2、适用场景
微批处理是增加延迟来换取高吞吐的策略,如果您有超低延迟的要求,不建议开启微批处理。通常对于聚合的场景,微批处理可以显著的提升系统性能,建议开启。
3、普通聚合与MiniBatch聚合对比
A、Simple Aggregation普通聚合
在未开启任何聚合优化前,执行SQL():
SELECT key, SUM(value) FROM T GROUP BY key
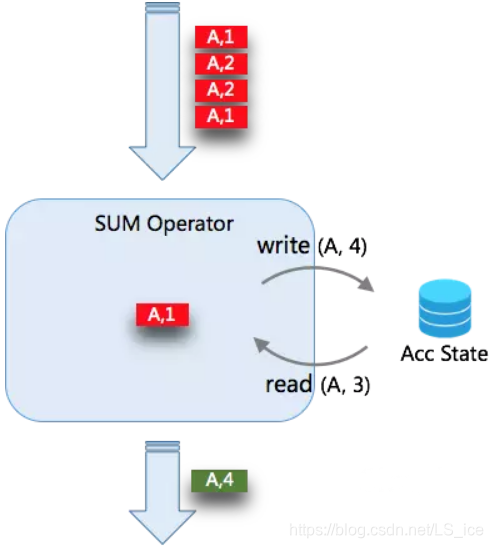
当未开启 MicroBatch 时,Aggregate 的处理模式是每来一条数据,查询一次状态,进行聚合计算,然后写入一次状态。当有 4条数据时,需要操作 2*4 次状态
B、MiniBatch Aggregation微批聚合
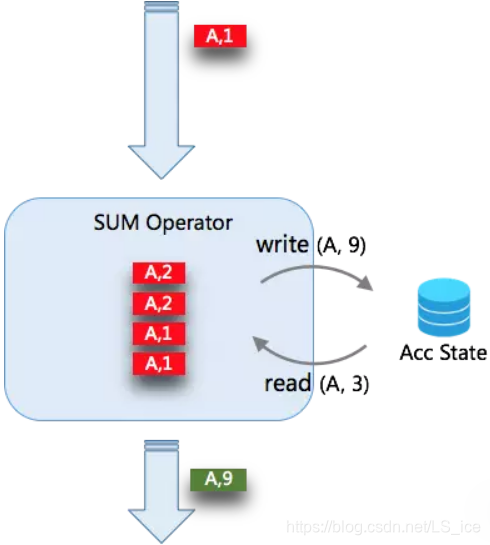
当开启 MicroBatch 时,对于缓存下来的 N 条数据一起触发,同 key 的数据只会读写状态一次。例如下缓存的 4 条 A 的记录,只会对状态读写各一次。所以当数据的 key 的重复率越大,攒批的大小越大,那么对状态的访问会越少,得到的吞吐量越高。
二、MiniBatch作用的SQL语句
MiniBatch主要作用于聚合(Group By)语句中,且不带window的场景(即分类2)。
我们先看下聚合分类:
分类1、 window agg
示例:select count(a) from t group by tumble(ts, interval ’10’ second), b
解析:以10秒翻转窗口和字段b聚合,MiniBatch不能作用的场景
分类2、group agg
示例:select count(a) from t group by b
解析:以字段a聚合,MiniBatch可以作用的场景
分类3、over agg
示例:select count(a) over (partition by b order by c) from t
解析:over window,MiniBatch不能作用的场景
三、MiniBatch三类优化手段
上一章节我们说明了MiniBatch只能作用于分类2(group aggregate且不带window场景),这个聚合场景下,微批处理具有三类优化手段:
- Local-Global聚合(本地-全局聚合)
- Partial-Final聚合(解决COUNT DISTINCT热点问题)
- Incremental增量聚合
1、Local-Global聚合(本地-全局聚合)
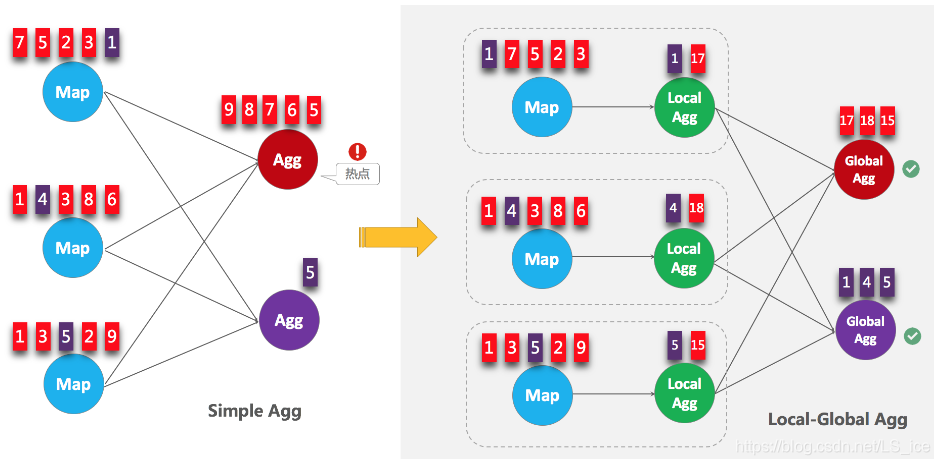
Local-Global聚合优化与Spark Structrued Streaming聚合思路类似:
- 上游节点本地攒一批数据进行聚合(localAgg),并输出这次微批的增量值(Accumulator)
- 第二阶段再将收到的Accumulator合并(merge),得到最终的结果(globalAgg)
- 原理图解:
LocalGlobal本质上能够靠localAgg的预聚合筛除部分倾斜数据,从而降低globalAgg的热点,提升性能。可以结合下图理解LocalGlobal如何解决数据倾斜的问题
- 适用场景:
LocalGlobal适用于提升如SUM、COUNT、MAX、MIN和AVG等普通聚合的性能,能提高算子吞吐量,也能有效解决常见数据热点问题
- 源码Rule规则:TwoStageOptimizedAggregateRule(两阶段聚合规则)
- 物理计划算子:上述规则内部#createTwoStageAgg()创建了StreamExecLocalGroupAggregate、StreamExecGlobalGroupAggregate物理计划节点,分别对应Local、Global微批聚合实现
- 实现函数Fuction:MiniBatchLocalGroupAggFunction、MiniBatchGlobalGroupAggFunction,分别对应Local、Global微批聚合实现
- 需要的额外配置:
table.optimizer.agg-phase-strategy开启(默认值已为AUTO开启,所以不用配置)
- 如何判断是否生效:
FLink Web UI观察最终生成的拓扑图的节点名字中是否包含GlobalGroupAggregate或LocalGroupAggregate
2、Partial-Final聚合(解决COUNT DISTINCT热点问题)
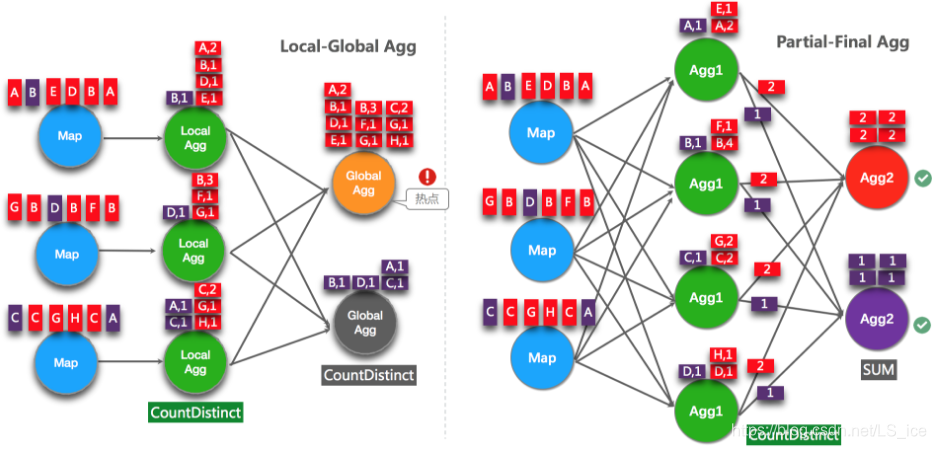
上一小节的Local-Global优化能针对常见普通聚合有较好的效果(如SUM、COUNT、MAX、MIN和AVG)。但是对于COUNT DISTINCT收效不明显,原因是COUNT DISTINCT在local聚合时,对于DISTINCT KEY的去重率不高,导致在Global节点仍然存在热点
实时计算历史版本中,用户为了解决COUNT DISTINCT的热点问题,通常会手动改写成两层聚合(增加按distinct key取模的打散层),自FLink1.9.0版本开始,实时计算提供了COUNT DISTINCT自动打散,即Partial-Final优化,您无需自行改写为两层聚合。Partial-Final和Local-Global的原理对比参见下图。
- 适用场景:
使用COUNT DISTINCT且聚合节点性能无法满足时。
- 说明:
PartialFinal优化方法不能在包含UDAF的Flink SQL中使用。
数据量不大的情况下不建议使用PartialFinal优化方法。PartialFinal优化会自动打散成两层聚合,引入额外的网络Shuffle,在数据量不大的情况下,可能反而会浪费资源。
一个Partial-Final优化过程示例:
原SQL:
SELECT day, COUNT(DISTINCT buy_id) as cnt FROM T GROUP BY day,
对所需DISTINCT字段buy_id模1024自动打散后,SQL:
SELECT day, SUM(cnt) total
FROM (
SELECT day, MOD(buy_id, 1024), COUNT(DISTINCT buy_id) as cnt
FROM T GROUP BY day, MOD(buy_id, 1024))
GROUP BY day
- 源码Rule规则:SplitAggregateRule(拆分聚合规则,注意是作用于logical逻辑计划阶段,拆分出来的两个聚合GROUP还会参与local-global等优化)
- 需要的额外配置:
table.optimizer.distinct-agg.split.enabled开启(默认值已为false,需要设置为true)
table.optimizer.distinct-agg.split.bucket-num(默认值1024,可以根据业务数据量和热点情况,设置这个取模值)
- 如何判断是否生效:
FLink Web UI观察最终生成的拓扑图的节点名中是否包含Expand节点,或者原来一层的聚合变成了两层的聚合
3、Incremental增量聚合
增量聚合是对partial-final和local-global拆分出来的聚合物理算子进行进一步优化,例如对一个带有COUNT DISTINCT和聚合场景,同时开启partial-final和local-global优化配置,最后会得到4个以上相关算子。
如果上一个聚合算子的输出字段(partial)与下一个聚合算子(local)的输入字段一样,就可以匹配上IncrementalAggregateRule,进行算子的合并。如图:
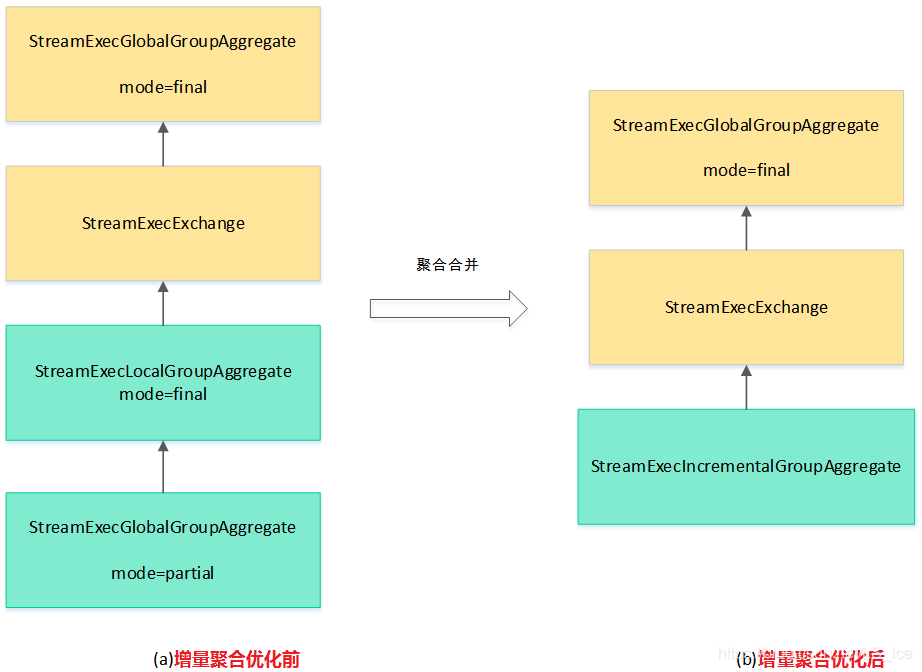
- 源码Rule规则:IncrementalAggregateRule(增量聚合规则,注意是作用于physical物理计划阶段)
- 物理计划算子:上述规则内部#onMatch()创建了StreamExecIncrementalGroupAggregate、StreamExecGlobalGroupAggregate物理计划节点,分别对应Local、Global微批聚合实现
- 实现函数Fuction:MiniBatchGlobalGroupAggFunction
- 需要的额外配置:
table.optimizer.incremental-agg-enabled开启(默认值已为true,所以不用修改)
- 如何判断是否生效:
FLink Web UI观察最终生成的拓扑图的节点名中是否包含IncrementalGroup节点
四、如何开启MiniBatch
1、table.exec.mini-batch.enabled
public static final ConfigOption<Boolean> TABLE_EXEC_MINIBATCH_ENABLED =
key("table.exec.mini-batch.enabled")
.defaultValue(false)
.withDescription("Specifies whether to enable MiniBatch optimization. " +
"MiniBatch is an optimization to buffer input records to reduce state access. " +
"This is disabled by default. To enable this, users should set this config to true. " +
"NOTE: If mini-batch is enabled, 'table.exec.mini-batch.allow-latency' and " +
"'table.exec.mini-batch.size' must be set.");
解析:MiniBatch开关配置,默认为false关闭,优化时需要设置为true
作用的物理计划算子:
①、StreamExecGroupAggregate(普通group by聚合,且未开启local-global本地至全局两阶段聚合优化,对应的物理计划算子,后续讲解)
②、StreamExecGlobalGroupAggregate(普通group by聚合,开启了local-global本地至全局两阶段聚合优化,对应的物理计划算子)
2、table.exec.mini-batch.allow-latency
public static final ConfigOption<String> TABLE_EXEC_MINIBATCH_ALLOW_LATENCY =
key("table.exec.mini-batch.allow-latency")
.defaultValue("-1 ms")
.withDescription("The maximum latency can be used for MiniBatch to buffer input records. " +
"MiniBatch is an optimization to buffer input records to reduce state access. " +
"MiniBatch is triggered with the allowed latency interval and when the maximum number of buffered records reached. " +
"NOTE: If " + TABLE_EXEC_MINIBATCH_ENABLED.key() + " is set true, its value must be greater than zero.");
解析:MiniBatch缓存数据最大的时间间隔,超过这个间隔,强制触发已聚合数据写出给下游,默认-1毫秒,可以根据需求和业务容忍的延迟,调整为5000毫秒等
作用的物理计划算子:StreamExecWatermarkAssigner(水印SQL物理计划),内部可以创建MiniBatchAssignerOperator,以上述配置的周期,将当前Watermark发送给下游,触发计算和写出
3、table.exec.mini-batch.size
public static final ConfigOption<Long> TABLE_EXEC_MINIBATCH_SIZE =
key("table.exec.mini-batch.size")
.defaultValue(-1L)
.withDescription("The maximum number of input records can be buffered for MiniBatch. " +
"MiniBatch is an optimization to buffer input records to reduce state access. " +
"MiniBatch is triggered with the allowed latency interval and when the maximum number of buffered records reached. " +
"NOTE: MiniBatch only works for non-windowed aggregations currently. If " + TABLE_EXEC_MINIBATCH_ENABLED.key() +
" is set true, its value must be positive.");
解析:MiniBatch缓存数据最大数目,超过这个数目,强制触发已聚合数据写出给下游,默认-1,可以根据需求和业务每秒数据量,调整为需要的值,例如50000
作用的物理计划算子:AggregateUtil中创建CountBundleTrigger(以数目为阈值的触发器,实现较为简单),其#onElement()方法会调用AbstractMapBundleOperator#finishBundle()结束一段聚合缓存,为核心逻辑,本文后面章节分析
注:table.exec.mini-batch.size与上一节table.exec.mini-batch.allow-latency为或关系,达到阈值触发聚合写出给下游
4、table.optimizer.reuse-sub-plan-enabled
public static final ConfigOption<Boolean> TABLE_OPTIMIZER_REUSE_SUB_PLAN_ENABLED =
key("table.optimizer.reuse-sub-plan-enabled")
.defaultValue(true)
.withDescription("When it is true, the optimizer will try to find out duplicated sub-plans and reuse them.");
解析:复用子查询,这个配置是一个通用的配置,并不只是作用于聚合SQL,建议开启,如果两个SQL语句的from表及project(select)后字段一模一样,就可以将两个逻辑节点合并为一个
示例:
Scan1、Scan2 与是统一个表名, Project1与Project2字段一样,Filter1与Filter2逻辑有区别,可以使用reuse-sub-plan这个优化
Join Join
/ \ / \
Filter1 Filter2 Filter1 Filter2
| | => \ /
Project1 Project2 Project1
| | |
Scan1 Scan2 Scan1
- 作用的物理计划算子:实现逻辑在SubplanReuser,感兴趣的读者可以深入分析
猜您喜欢& 往期精选▼
Spark Shuffle调优之调节map端内存缓冲与reduce端内存占比
Flink中Checkpoint和Savepoint 的 3 个不同点