理解 PageRank 算法
前言
眾所周知,Google 最令人佩服的就是他的搜尋引擎,而要知道,要做到一個良好的搜尋引擎,當然希望能對網頁進行相關性,重要性等等的排名。講到這就不得不提到本篇的主角 PageRank 算法。PageRank 算法就是對網頁進行排名的算法,是由 Google 的創始人,CEO Larry Page 發明的。接下來就來理解 PageRank 的基本原理。
正文
PageRank 思想
PageRank 中的 page 可以理解為網頁。這個算法的思想就是假設有一個隨意的用戶,打開瀏覽器後,隨便選擇一個網頁。然後看看這個網頁以後,跳到其中一個由這個網頁指向的下一個網頁,一直繼續下去。PageRank 想要做的就是估計所有網頁中任一被這個用戶瀏覽到的概率,所謂排名的體現在於,越容易被訪問到的網頁就被認為是相對重要,排名比較高的網頁。
PageRank 機制
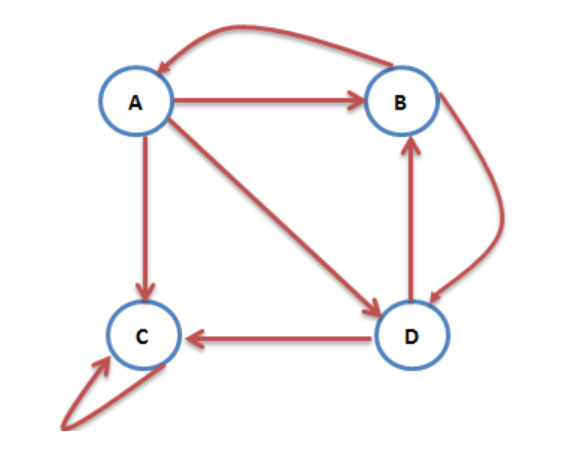
我們把網絡看做是一個有向圖,一個個網頁就看作圖上的個個頂點。如果網頁 A 有鏈接到網頁 B,那就有一條邊由 A 指向 B。且看下圖:
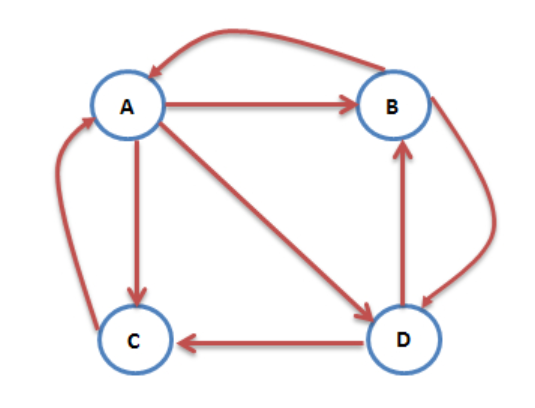
這個例子有 4 個網頁 A,B,C,D。假設用戶位於網頁 A,那麼就各有 1/3 的概率下個網頁會跳到 B,C,D。PageRank 算法的前提假設是對於任意點(網頁),如果有 k 條出邊,則跳轉至任意一個出邊的概率就是 1/k。
使用 PageRank 算法時我們用矩陣來表示。如果圖有 n 個頂點,則我們的初始轉移矩陣大小就是 n*n 記為 M,對於任意邊,表示法為若點 i 有邊指向點 j,則 M[j][i] = 1/k,其餘為 0。上圖的轉移矩陣如下:

一開始,每個網頁對於用戶來說都是隨機訪問的,因此概率都是 1/n,這邊就是 1/4。這時要引入 V0,就是一個 n 維的列向量。接著拿 VO 右乘 M,得到 V1 如下:
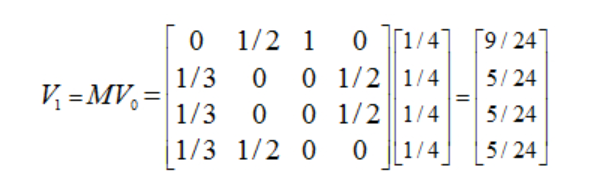
然後就是不斷地迭代上一步,而最終矩陣會收斂,也就是 V·n = M·V(n-1),我們就將這個收斂的結果作為每個網頁重要性的指標,表示被用戶訪問的概率。以這個例子來說,最終會得到穩定結果 V = [3/9, 2/9, 2/9, 2/9]。

PageRank 缺陷 — 終止點問題
PageRank 算法要收斂到一個穩定結果,首先必須要先建立在一個前提 :
圖必須是強連通的,也就是說任意點都要能由另外一個任意點可達。意味的是任一網頁都要能到達任一網頁。
然而,常理就可知道這是不可能的,因為有些網頁不指向任何網頁。這樣的情況下,當用戶到達這個網頁,就會面臨走投無路的窘境。這會導致前面所有累積的概率全部歸零。以上面例子繼續,如果我們把 C 指向 A 的邊拿掉,C 變成我們說的終止點,如下圖:
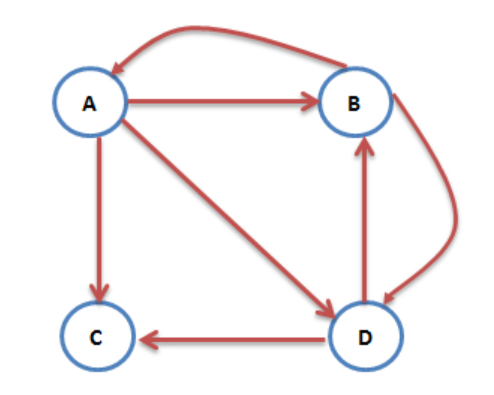
轉移矩陣變成如下:
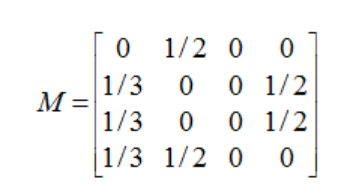
學過基本線性代數的就會知道,以這個 M 迭代,最後會變成全 0 的列向量,因為 M 中有全 0 的列。

PageRank 缺陷 — 陷阱問題
PageRank 算法還有一個缺點。試想這種情況,如果今天有一個網頁,不指向任何其他網頁,卻唯獨指向自己,會發生什麼事。這就好像是,用戶到達這個網頁後,一直覺得自己有下一個網頁可以訪問,但每次嘗試訪問卻又都回到當前網頁,就像一個死循環一樣,用戶掉入了陷阱。這同樣導致前面所有迭代和累積全都失去意義,最終概率會全部累積到陷阱點,其他網頁都會變成 0,這麼一來將完全失去 PageRank 對網頁排名的意義。以上面例子繼續,如果圖變成如下:
不斷迭代會得到這樣的結果:

解決 PageRank 缺陷
我們忽略了一個問題,就是我們的用戶不是一個傻子。當碰到陷阱點或終止點時,他不會傻傻地停留在當前網頁乾等待,他會偷偷在瀏覽器上的地址欄中輸入任一非當前網頁的其他的網址。那你會想說,這個隨意輸入的地址可能又是當前網頁啊 ? 是的,所以這邊假設用戶每一步查看當前網頁的概率為 a,那麼不查看網頁,也就是在地址欄輸入的概率為 (1-a),於是 PageRank 算法的公式就變成這樣:
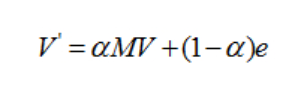
為了驗證這樣確實解決的上述的缺陷,以陷阱問題中的圖做計算,假設 a = 80%,最終會得到這樣的解果:

這樣的結果其實是合理的,因為 c 網頁除了由別人有機會可以訪問到以外,自己也有機會訪問的自己,相當於比其他網頁多了被訪問到的機會,因此權重自然也就應該大些。
結語
這篇關於 PageRank 算法的就說到這邊,應該還算完整也不難理解。若對本篇有認為不正確的部分也歡迎各位大牛們多多指教!