Shell三剑客(grep、sed、awk)
一、grep
grep的一些正则表达式的链接,之前写过,所以这篇就不多描述了(点击这里跳转)
grep命令——检索和过滤文件内容 (在文件中去查找并显示包含指定字符串的行)
语法结构: grep 选项 查找条件 目标文件
选项:
-i 查找内容时忽略大小写
-v 条件反转 (和所写的条件正好完全相反)
-n 显示行号
二、sed流编辑器
(1)sed简介:
sed是一种流编辑器,它是文本处理中非常适中的工具,能够完美的配合正则表达式使用,功能不同凡响。处理时,把当前处理的’行‘存储在临时缓冲区中,又称为 ‘模式空间’(pattern space) ,接着使用sed命令再去处理缓冲区中的内容,处理完成后,把缓冲区的内容输出到屏幕上,接着再去处理下一行,这样不断重复,知道处理到文件的末尾,文件内容并没有改变(也可以加选项,去直接修改文件,或者使用重定向指定文件,存储数据)
sed主要用来自动编辑一个或多个文件,简化对文件的反复操作,编写转换程序等
(2)工作流程:
- 读取——执行——显示
- 常见用法:
sed [选项] ‘操作’ 参数
sed [选项] -f scriptfile 参数
参数就是文件,也就是指定的待处理的文本文件列表
- 常见选项
1. -e<script>或 expression=<script>:一选项中的指定的 script来处理输入的文本文件
2. -f<script文件>或 file=<script文件>:以选项中指定的script文件来处理输入的文本文件
3. -h或 help:显示帮助
4. -n或 quiet或——silent:仅显示script处理后的结果
5. -V或 version:显示版本信息
6. -i 直接编辑文本文件(加了这个选项后,你的操作会直接修改文本文件)
- 常见操作
1. a\ 在当前行下面插入文本。
2. i\ 在当前行上面插入文本。
3. c\ 把选定的行改为新的文本。
4. d 删除,删除选择的行。
5. D 删除模板块的第一行。
6. s 替换指定字符
7. h 拷贝模板块的内容到内存中的缓冲区。
8. H 追加模板块的内容到内存中的缓冲区。
9. g 获得内存缓冲区的内容,并替代当前模板块中的文本。
10. G 获得内存缓冲区的内容,并追加到当前模板块文本的后面。
11. l 列表不能打印字符的清单。
12. n 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。
13. N 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。
14. p 打印模板块的行。
15. P(大写) 打印模板块的第一行。
16. q 退出Sed。
17. b lable 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。
18. r file 从file中读行。
19. t label if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
20. T label 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
21. w file 写并追加模板块到file末尾。
22. W file 写并追加模板块的第一行到file末尾。
23. ! 表示后面的命令对所有没有被选定的行发生作用。
24. = 打印当前行号码。
25. # 把注释扩展到下一个换行符以前。
- sed替换标记
1. g 表示行内全面替换。
2. p 表示打印行。
3. w 表示把行写入一个文件。
4. x 表示互换模板块中的文本和缓冲区中的文本。
5. y 表示把一个字符翻译为另外的字符(但是不用于正则表达式)
6. \1 子串匹配标记
7. & 已匹配字符串标记
- sed元字符集
1. ^ 匹配行开始
2. $ 匹配行结束
3. . 匹配一个非换行符的任意字符
4. * 匹配0个或多个字符
5. [] 匹配一个指定范围内的字符
6. [^] 匹配一个不在指定范围内的字符
7. \(..\) 匹配子串,保存匹配的字符
8. & 保存搜索字符用来替换其他字符
9. \< 匹配单词的开始
10. \> 匹配单词的结束
11. x\{
m\} 重复字符x,m次
12. x\{
m,\} 重复字符x,至少m次
13. x\{
m,n\} 重复字符x,至少m次,不多于n次
sed用法示例
创建测试文件: (之后的测试都是按这个文本来的,直接复制就行)
[root@localhost ~]# cat test.txt
he was short and fat.
He was wearing a blue polo shirt with black pants.
The home of Football on BBC Sport online.
the tongue is boneless but it breaks bones.12!
google is the best tools for search keyword.
The year ahead will test our political establishment to the li
PI=3.141592653589793238462643383249901429
a wood cross!
Actions speak louder than words
#woood #
#woooooood #
AxyzxyzxyzxyzC
I bet this place is really spooky late at night!
Misfortunes never come alone/single.
I shouldn't have lett so tast.
(1)输出符合条件的文本
——输出所有内容,等同于cat test.txt
——输出第三行

——输出第三到五行

——输出所有奇数行 (n 表示读入下一行)

——输出所有偶数行

——输出1-5奇数行


——输出第四行至第一个包含the的行(也就是第四行开始,一直筛选到下一个包含the的行,这里是第五行就有the,所以筛选了两行)
——输出包含the的所在行的行号(= 用来输出行号,只显示行号)

——输出以PI开头的行(^以PI开头)

——输出以数字结尾的行($就是以什么什么结尾)

——输出包含单词wood的行<单词>表示单词边界(即想要筛选包含单词的行就要使用\<wood\>这种的)
(2)删除符合条件的文本 ’d’
nl ——计算文件的行数
也就是说可以配合nl然后操作sed去删除指定的行数
——删除第三行 (因为全截图的话就太大了,所以之后都是局部截图,主要是知道效果即可)

——删除三到五行

——删除包含cross的行

——删除不包含cross的行 (!即相反的意思!d即是反向删除不带cross的行)

——删除开头为小写字母的行
——删除以’ . ‘结尾的行('/\.$/d' ,这个d前面的/容易打成\,操作时要注意)
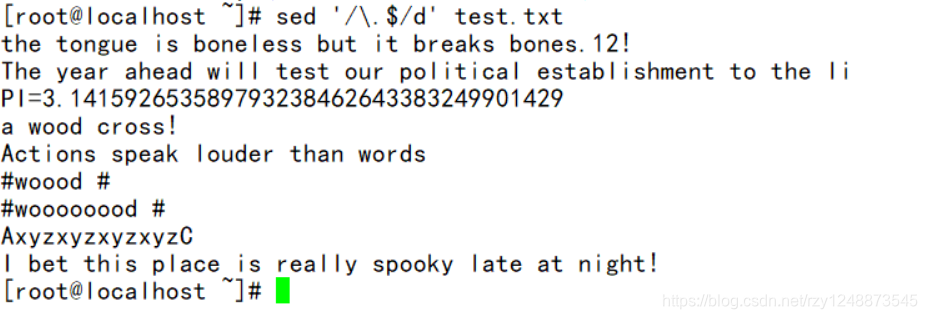
——删除空行
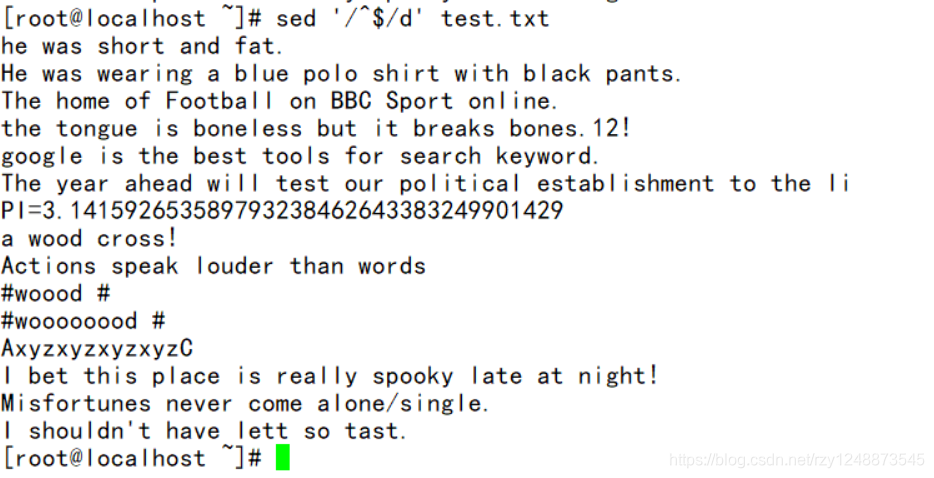
——删除重复的空行(这个等同与cat -s test.txt,)
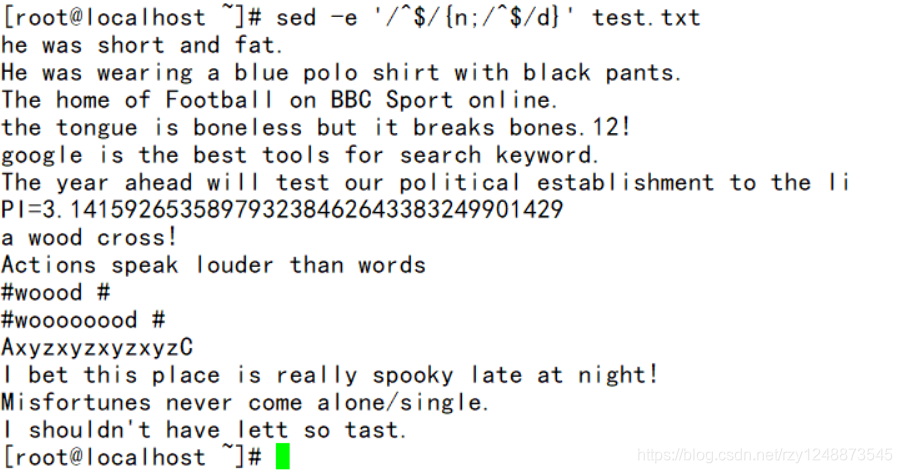
(3)替换符合条件的文本
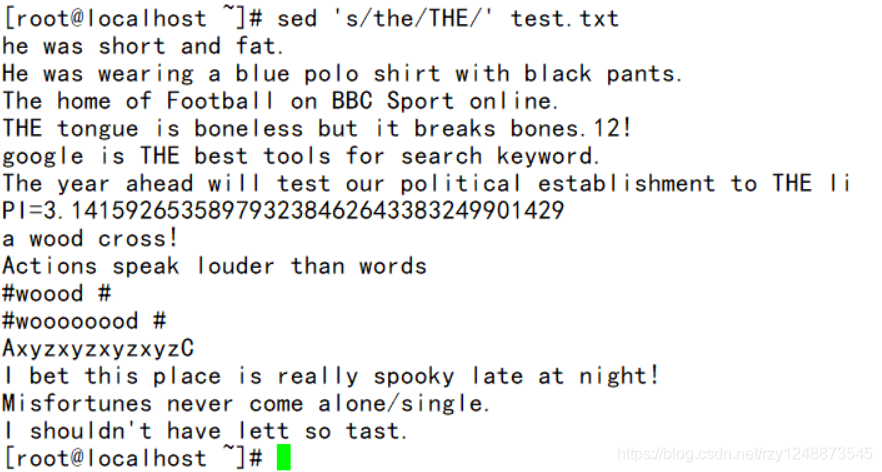
——将每行的第一个the替换为THE
——将每行中的第二个l替换为L
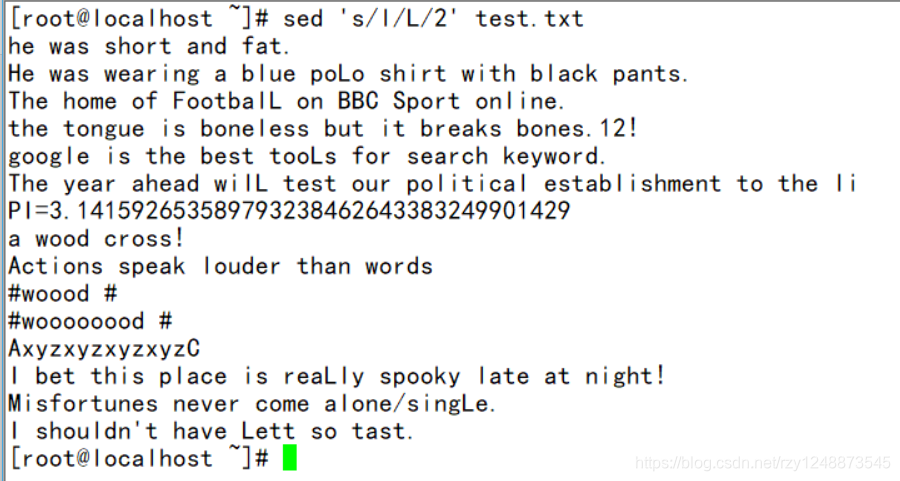
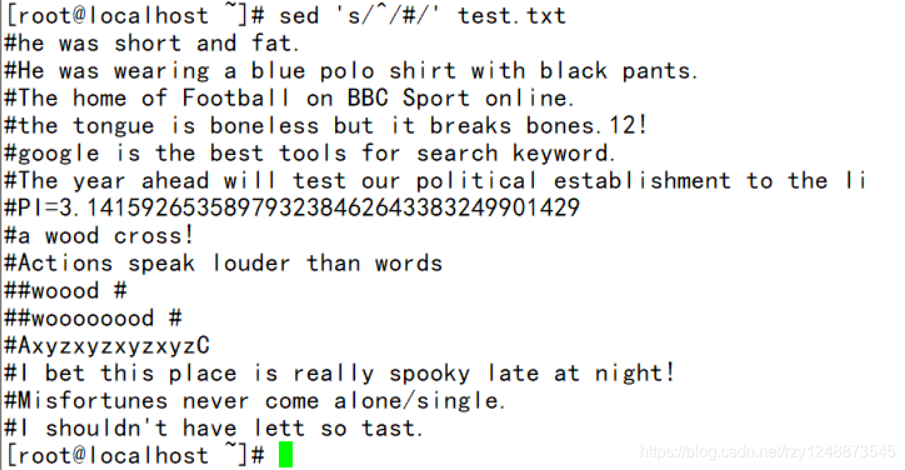
——每行开始添加#字符(其实就是把开头换成#)
——将3-5行的所有的the替换为THE(3,5就是三到五行,后面加了g就是所有的意思)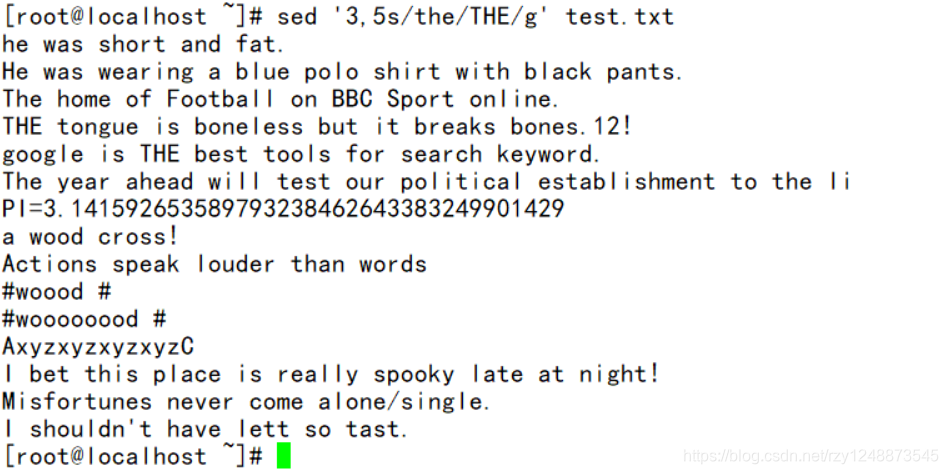
(4)迁移符合条件的文本
操作符:
- H 复制到剪贴板;
- g,G 将剪贴板中的数据覆盖/追加到指定行;
- w 保存为文件;
- r 读取指定文件;
- a 追加指定内容
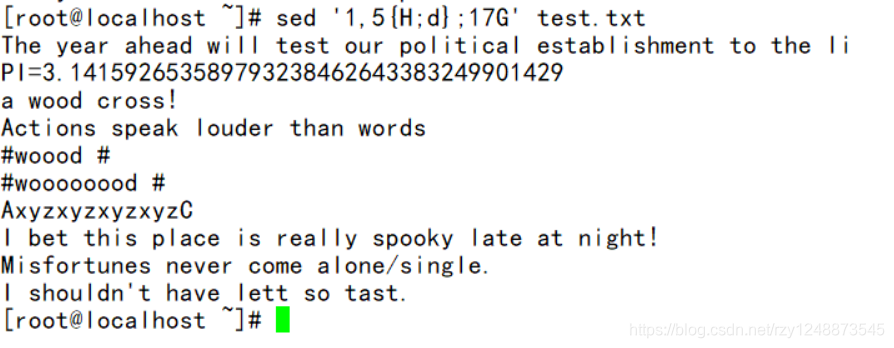
——将包含the的行,迁移到行尾(;用于多个操作,和管道符差不多,H复制到剪贴板---d删除---$G追加到行尾)

——将1-5行迁移到17行后
——将包含the的行另存为新文件(w就是另存为,另存为到out.file)
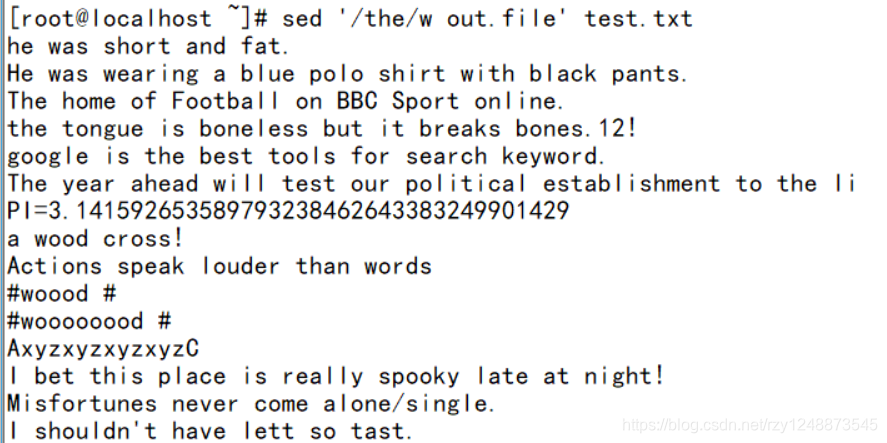

——在包含the每行后添加文件hostname内容(/the/r就是包含the的每行后面都加上/etc/hostname的内容,也就是读取了指定文件的内容)

——在第3行后插入新行,内容为New (a也就是添加了指定内容)

(5)使用脚本编辑文件
使用sed脚本,将多个编辑指令存放到文件中(每一行一条编辑指令),通过 -f 的方式调用
——将1-5行迁移到17行后
使用sed: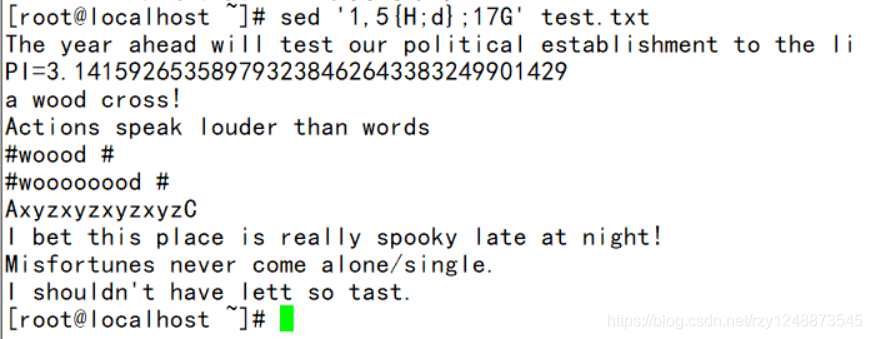
使用脚本:
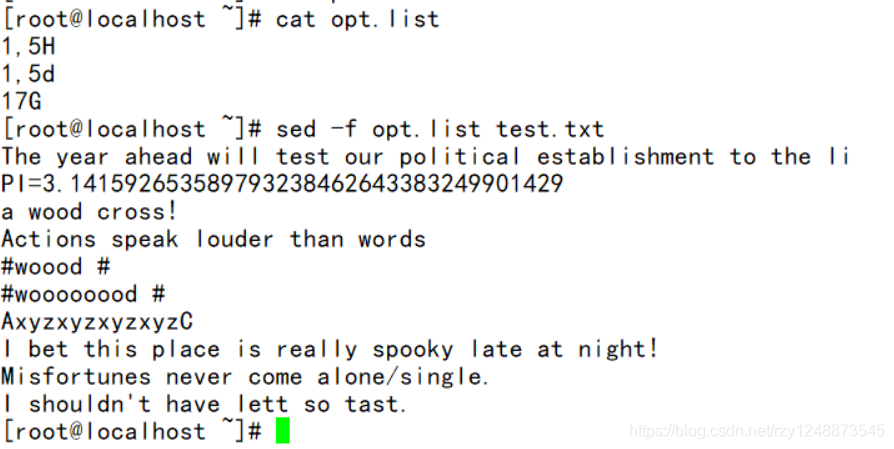
效果其实是一样的
三、awk工具
简介:
awk是行处理器,相比较屏幕处理的优点,在处理庞大文件时不会出现内存溢出或是处理缓慢的问题,通常用来格式化文本信息
(1)awk工作流程
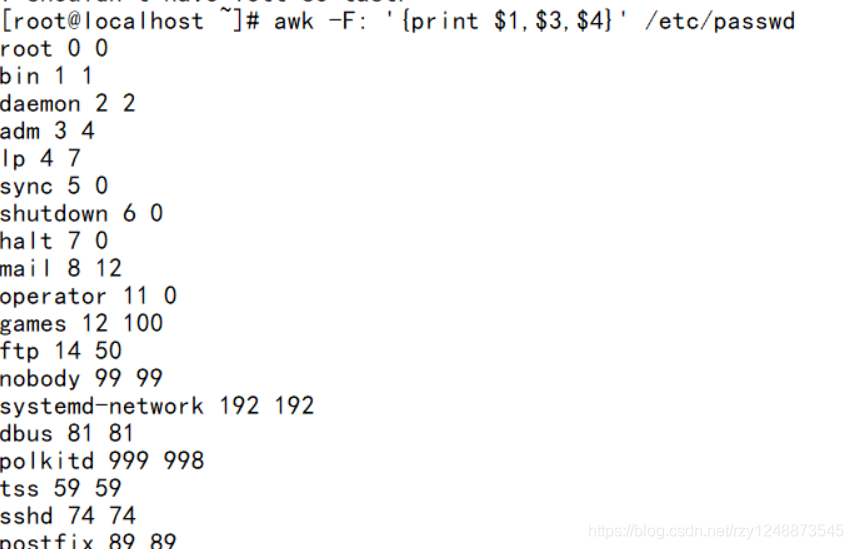
#awk -F ‘:’ ‘{print $1,$3,$4}’ /etc/passwd
按这条命令来说:
- awk命令会
逐行读取文件的内容进行处理 - awk以’:’为分隔符,将第1行数据格式化为7段,每段数据存入$1–$7变量中。$0存储这1行数据,-F即是按什么字符来分割,这里写的就是-F:,说明以:来分割
- 一行处理完成继续处理下一行,直到此文件读取结束
执行完命令后的结果:
(2)awk常见用法
- awk 选项 ‘模式或条件 { 编辑指令 }’ 文件1 文件2 …
- awk -f 脚本文件 文件1 文件2 …
(3)特殊的内建变量
$0 表示整个当前行
$1 每行第一个字段
NF 字段数量变量
NR 每行的记录号,多文件记录递增
FNR 与NR类似,不过多文件记录不递增,每个文件都从1开始
\t 制表符
\n 换行符
FS BEGIN时定义分隔符
RS 输入的记录分隔符, 默认为换行符(即文本是按一行一行输入)
~ 匹配,与==相比不是精确比较(包括)
!~ 不匹配,不精确比较
== 等于,必须全部相等,精确比较
!= 不等于,精确比较
&& 逻辑与
|| 逻辑或
+ 匹配时表示1个或1个以上
/[0-9][0-9]+/ 两个或两个以上数字
/[0-9][0-9]*/ 一个或一个以上数字
FILENAME 文件名
OFS 输出字段分隔符, 默认也是空格,可以改为制表符等
ORS 输出的记录分隔符,默认为换行符,即处理结果也是一行一行输出到屏幕
-F'[:#/]' 定义三个分隔符
{
print} 类似于显示的意思,后面可以跟$位置变量显示相应的字段
用法示例:
(1)按行输出文本
——输出1-3行内容(NR==即是指定行数)

这里(NR>=1)&&(NR<=3)和上面的NR==1,NR==3意思其实是一样的

——输出奇数行(%2求模运算,余数为1是奇数,0为偶数 )

——输出偶数行

——统计以/bin/bash结尾的行(和grep -c "/bin/bash$"其实是一样的,grep的更简单一点,看个人喜好)
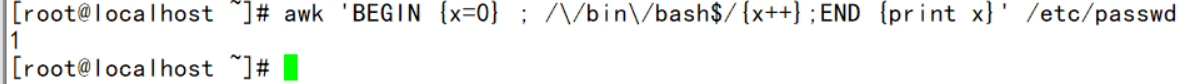
(2)按字段输出文本
(这个感觉更常用一点,用法(1)的grep也能做到)
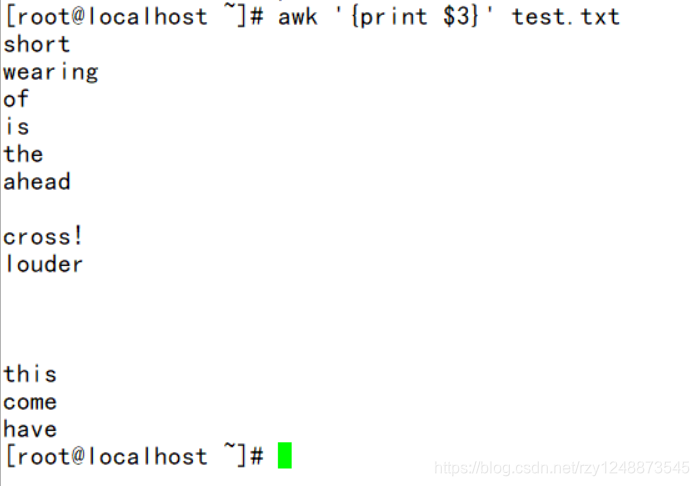
——输出每行中以空格分割的第3个字段(运用了位置变量与之配置,不加-F即默认是空格来分割)
——密码为空的行 (我这个没有密码为空的用户所以筛选不出来)
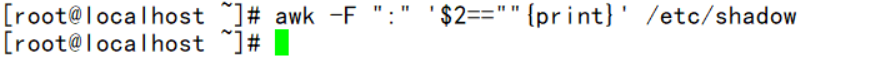
——输出第7个字段不是/bin/bsh也不是/sbin/nologin的行(!=就是不相同)

(3)通过管道符、双引号调用shell命令
示例1:
条件:调用wc -l 命令统计使用bash的用户个数
- 使用awk工具执行
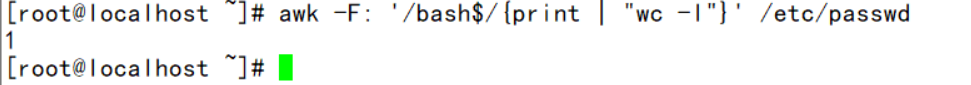
- 使用grep命令执行

(效果是一样的)
示例2:
条件:调用w命令,统计在线用户数
- 使用awk工具执行

- 使用常规命令执行
(所得减去2就是在线用户数量,可以先试试w这个命令,前两行是时间日期等)
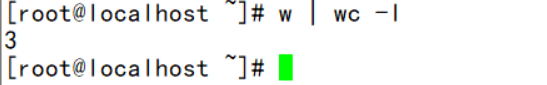

主要是看敲完命令后的效果,发现规律后就很好理解了,选项虽然多,但是好多也不常用,有时间的话记一下就可以,也不用全都记住,但是最起码给一个sed这类的表达式什么的得能看懂