我们都知道在浏览器的网址栏位输入www.baidu.com,点下回车后,会呈现出百度的首页。那么深层次的探究一下,这期间是如何做到资源的正确请求的,还发生了什么事情呢?
网络模型
在回答问题之前,我们先回顾一下网络模型。我们平时常见的网络模型有以下两种:
1. OSI(Open System Interconnection)的七层模型
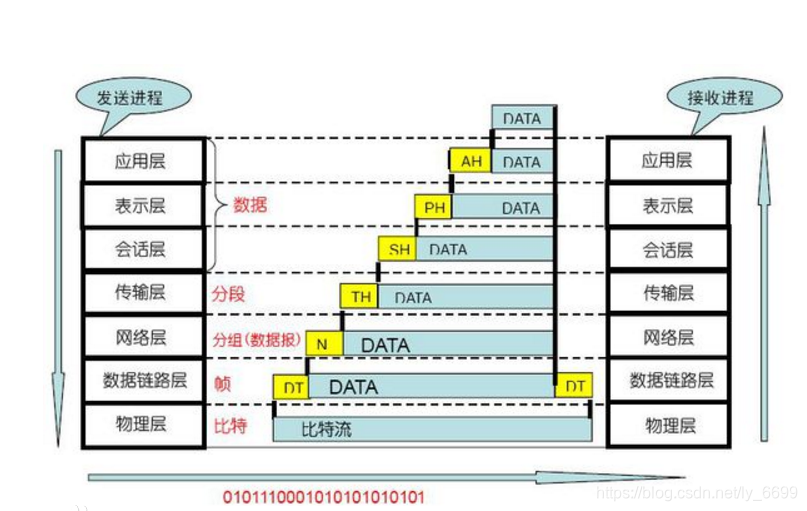
2. TCP/IP的四层模型:
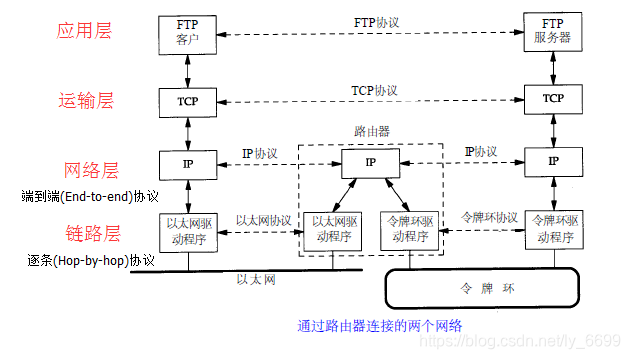
其中关于应用层,传输层,网络层的详解,我在之前博客已经写过,感兴趣的可以通过链接点击了解。现在我们就以四层模型为例,正式进入话题。
发生过程
通过四层模型的图解,我们应该知道,输入网址后会大概发生以下几个过程:
- 应用层使用DNS解析域名,得到目标IP地址。接下来就通过DNS查找目标IP获取内容,如果本地存有这个的IP,则直接使用;如果没有,则会向上级DNS服务器请求帮助,直至获得目标IP的内容。DNS域名解析详细过程在下文中讲解。
- 应用层将请求的信息装载入HTTP的请求报文(向下封装过程),包含了请求首行(方法+url)+请求头(+空行)+请求主体,然后由应用层发起这个HTTP请求。
- 传输层接收到应用层传递下来的数据,并分割成以报文段为单位的数据包进行管理,并为它们编号,方便服务器接收时能准确地还原报文信息。通过三次握手和目标端口建立安全通信。
- 网络层接收传输层传递的数据,进行路由(IP查找目标网络+ARP查找目标主机),即根据IP通过ARP协议获得目标计算机物理地址—MAC。当通信的双方不在同一个局域网时,需要多次中转才能到达最终的目标,在中转的过程中需要通过下一个中转站的MAC地址来搜索下一个中转目标。
- 找到目标MAC地址以后,就通过数据链路层将数据发送到服务器端,这时才开始真正的传输请求信息,传输完成以后请求结束。
- 服务器接收数据后,从下到上层层将数据解包分离,直到应用层。
- 在服务器上查找客户端请求的资源,将数据装载入HTTP响应报文并原路返回,响应报文中包括一个重要的信息——状态码,如200,404,500。
- 浏览器接收到报文内容查看状态码。200的话就根据响应报文内容解析并渲染页面,其他状态码的话展示相应错误。
- 释放TCP连接,此次请求完成。
DNS域名解析
DNS域名解析的查找过程主要有以下几个步骤:
1.浏览器缓存- 浏览器会缓存DNS记录一段时间
2.系统缓存- 若在浏览器中没有找到需要的记录,浏览器会做一个系统调用,利用gethostbyname,获得系统的缓存中的记录
3.路由器缓存- 若系统缓存没有,则会将查询请求发送至路由器,它一般会有自己的DNS缓存。
4.ISP DNS缓存- 接下来要check的就是ISP缓存DNS的服务器,在这一般能找到相应的缓存记录。
5.递归搜索- 你的ISP的DNS服务器从根域名服务器开始进行递归搜索
如果还想了解更详细的解析过程,我还写了一篇DNS域名解析过程的博客,欢迎关注查看哈~