ArrayDeque
ArrayDeque是Deque接口的一个实现,使用了可变数组,所以没有容量上的限制。同时,ArrayDeque是线程不安全的,在没有外部同步的情况下,不能再多线程环境下使用。
ArrayDeque是Deque的实现类,可以作为栈来使用,效率高于Stack;也可以作为队列来使用,效率高于LinkedList。需要注意的是,ArrayDeque不支持null值。
ArrayDeque 初识
说明书和继承关系
还是按照国际惯例,先看一下ArrayDeque 的说明书,其实往往很多时候你的困惑都在说明书里写着呢,但是在此之前我们还是先看一下它的继承关系,让我们有一个大概的认识
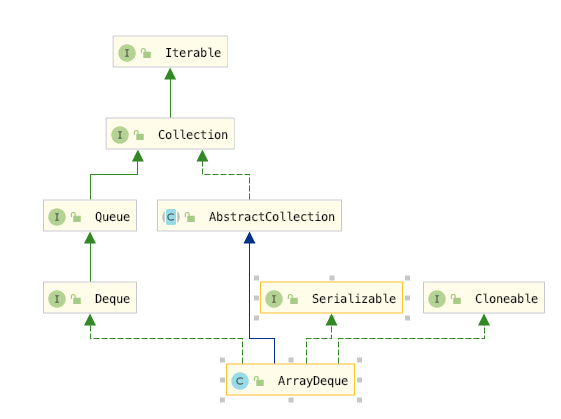
我们看到ArrayDeque 是通过实现Deque接口从而具有了Deque队列的功能,因为ArrayDeque的Deque是继承了Queue的接口,所以ArrayDeque同时有了Queue的功能,需要注意的是因为ArrayDeque是一个双向队列,队列的两端都可以进行添加删除弹出等操作,所有我们可以将双向队列当成Stack 来使用,当然LinkedList 也是可以当做栈来使用的。
/**
* Resizable-array implementation of the {@link Deque} interface. Array
* deques have no capacity restrictions; they grow as necessary to support
* usage. They are not thread-safe; in the absence of external
* synchronization, they do not support concurrent access by multiple threads.
* Null elements are prohibited. This class is likely to be faster than
* {@link Stack} when used as a stack, and faster than {@link LinkedList}
* when used as a queue.
* 实现了Deque接口的可变数组,ArrayDeque 没有容量的限制,容量会按需扩展。
* ArrayDeque 不是线程安全的,在没有外部加锁同步的情况下,它们不支持多线程并发访问,NULL 值是不允许的
* 这个类的如果被当做Stack 使用的话,性能是比Stack类好的,如果是作为Queue的话性能也是比LinkedList好的
* <p>Most {@code ArrayDeque} operations run in amortized constant time.
* Exceptions include {@link #remove(Object) remove}, {@link
* #removeFirstOccurrence removeFirstOccurrence}, {@link #removeLastOccurrence
* removeLastOccurrence}, {@link #contains contains}, {@link #iterator
* iterator.remove()}, and the bulk operations, all of which run in linear time.
* ArrayDeque 的许多操作除了删除和遍历操作(就是上面列举出来的)其他操作的均摊时间复杂度都是在常数级的
* <p>The iterators returned by this class's {@code iterator} method are
* <i>fail-fast</i>: If the deque is modified at any time after the iterator
* is created, in any way except through the iterator's own {@code remove}
* method, the iterator will generally throw a {@link
* ConcurrentModificationException}. Thus, in the face of concurrent
* modification, the iterator fails quickly and cleanly, rather than risking
* arbitrary, non-deterministic behavior at an undetermined time in the
* future.
* ArrayDeque 的iterator 方法返回的iterators是fail-fast的(这个已经解释过很多次了,这里就不再解释了)
* <p>Note that the fail-fast behavior of an iterator cannot be guaranteed
* as it is, generally speaking, impossible to make any hard guarantees in the
* presence of unsynchronized concurrent modification. Fail-fast iterators
* throw {@code ConcurrentModificationException} on a best-effort basis.
* Therefore, it would be wrong to write a program that depended on this
* exception for its correctness: <i>the fail-fast behavior of iterators
* should be used only to detect bugs.</i>
*/
public class ArrayDeque<E> extends AbstractCollection<E>implements Deque<E>, Cloneable, Serializable
{
/**
* 存储队列中元素的数组,队列的容量就是数组的长度,它永远是2的指数幂
* 这个数组中不允许存储NULL 值
*/
transient Object[] elements; // non-private to simplify nested class access
/**
* The index of the element at the head of the deque (which is the
* element that would be removed by remove() or pop()); or an
* arbitrary number equal to tail if the deque is empty.
* 队列头部元素的下标,如果head 和 tail 相等说明队列是空的
*/
transient int head;
/**
* 队列尾部元素的下标
*/
transient int tail;
/**
* The minimum capacity that we'll use for a newly created deque.
* Must be a power of 2.
*/
private static final int MIN_INITIAL_CAPACITY = 8;
}
ArrayDeque 的操作方法主要有一下这些,后面我们我们讲解一些方法的源码的实现,搞清楚整个ArrayDeque是怎样运转的
1.添加元素
addFirst(E e)在数组前面添加元素
addLast(E e)在数组后面添加元素
offerFirst(E e) 在数组前面添加元素,并返回是否添加成功
offerLast(E e) 在数组后天添加元素,并返回是否添加成功
2.删除元素
removeFirst()删除第一个元素,并返回删除元素的值,如果元素为null,将抛出异常
pollFirst()删除第一个元素,并返回删除元素的值,如果元素为null,将返回null
removeLast()删除最后一个元素,并返回删除元素的值,如果为null,将抛出异常
pollLast()删除最后一个元素,并返回删除元素的值,如果为null,将返回null
removeFirstOccurrence(Object o) 删除第一次出现的指定元素
removeLastOccurrence(Object o) 删除最后一次出现的指定元素
3.获取元素
getFirst() 获取第一个元素,如果没有将抛出异常
getLast() 获取最后一个元素,如果没有将抛出异常
4.队列操作
add(E e) 在队列尾部添加一个元素
offer(E e) 在队列尾部添加一个元素,并返回是否成功
remove() 删除队列中第一个元素,并返回该元素的值,如果元素为null,将抛出异常(其实底层调用的是removeFirst())
poll() 删除队列中第一个元素,并返回该元素的值,如果元素为null,将返回null(其实调用的是pollFirst())
element() 获取第一个元素,如果没有将抛出异常
peek() 获取第一个元素,如果返回null
5.栈操作
push(E e) 栈顶添加一个元素
pop(E e) 移除栈顶元素,如果栈顶没有元素将抛出异常
6.其他
size() 获取队列中元素个数
isEmpty() 判断队列是否为空
iterator() 迭代器,从前向后迭代
descendingIterator() 迭代器,从后向前迭代
contain(Object o) 判断队列中是否存在该元素
toArray() 转成数组
clear() 清空队列
clone() 克隆(复制)一个新的队列
ArrayDeque 源码
构造方法
/**
* Constructs an empty array deque with an initial capacity sufficient to hold 16 elements.
* 创建一个空的Deque
*/
public ArrayDeque() {
elements = new Object[16];
}
/**
* Constructs an empty array deque with an initial capacity
* sufficient to hold the specified number of elements.
* 创建一个指定大小的Deque ,足以容纳指定个数的元素
* @param numElements lower bound on initial capacity of the deque
*/
public ArrayDeque(int numElements) {
allocateElements(numElements);
}
// 创建一个包含指定集合元素的Deque
public ArrayDeque(Collection<? extends E> c) {
allocateElements(c.size());
addAll(c);
}
可以看到默认的无参构造创建的是一个大小为16的数组来容纳的队列里的元素,但是当我们指定容量的时候,并没有直接创建一个指定容量大小的数组,而是调用了一个方法,而且我们从其构造方法的描述信息上也可以得到一些信息,那就是足够容纳,所以证明至少是要大于我们指定的容量的,那到底是多大呢,接下来我们就看一下这个方法。
/**
* Allocates empty array to hold the given number of elements.
* 创建一个空的数组容纳指定个数的元素
* @param numElements the number of elements to hold
*/
private void allocateElements(int numElements) {
elements = new Object[calculateSize(numElements)];
}
我们看到这个方法调用了另外一个方法calculateSize(numElements),参数就是我们传进去的整数,通过下面的计算返回返回大于numElements的最小2的指数幂
/**
* The minimum capacity that we'll use for a newly created deque.
* Must be a power of 2.
*/
private static final int MIN_INITIAL_CAPACITY = 8;
private static int calculateSize(int numElements) {
int initialCapacity = MIN_INITIAL_CAPACITY;
// Find the best power of two to hold elements.
// Tests "<=" because arrays aren't kept full.
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
if (initialCapacity < 0) // Too many elements, must back off
initialCapacity >>>= 1;// Good luck allocating 2 ^ 30 elements
}
return initialCapacity;
}
这也和类注释中的信息进行了印证,也就说明了为什么队列的容量永远是2的指数幂,而且我们知道队列的最小容量是8
addFirst addLast 和add 方法
我们前面在类注释信息中看到,Queue 是不允许null 值的,这是怎么做到的呢,是因为所有的方法都加了null 值检测,因为可以添加元素的就下面几个方法,我们看到下面的几个方法确实都判断了元素是否为null
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
elements[head = (head - 1) & (elements.length - 1)] = e;
if (head == tail)
doubleCapacity();
}
我们先看一下addFirst的实现,首先进行了null 值检测,然后计算了head 的值,也就是队列的头部的所在,但是这个计算head 方式有点迷啊,为啥呢,我们假设我们的数组大小是16,head 的默认值是0(int 的默认值),那head = (head - 1) & (elements.length - 1) 计算出来的值是15,也就是说我们的head 是数组的末尾。那么我们知道下一次的时候head 的下标就是15了
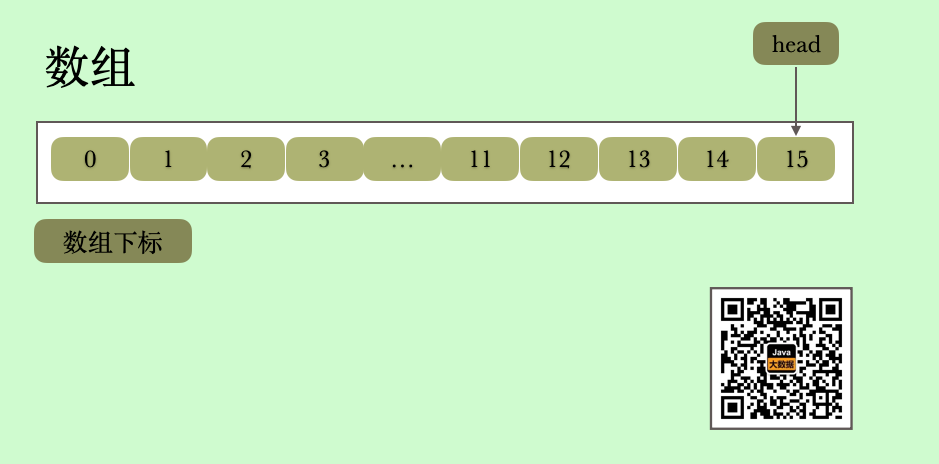
其实这个现象我们在学习Stack 的时候就看到了,我们认为栈顶应该是数组下标为0或者至少是数组的左端,其实栈顶是数组的右端,因为这样可以避免在弹出栈顶元素之后需要移动数组中的剩余元素
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
elements[tail] = e;
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();
}
我们看到addLast方法第一行也是进行了NULL 检测,我们知道tail的默认值是0,所以我们看到Queue的的尾部竟然是数据的头部。然后判断tail 和 head 是否相等,如果是的话则证明队列满了性需要扩容了
/**
* Inserts the specified element at the end of this deque.
* <p>This method is equivalent to {@link #addLast}.
* @param e the element to add
* @return {@code true} (as specified by {@link Collection#add})
* @throws NullPointerException if the specified element is null
*/
public boolean add(E e) {
addLast(e);
return true;
}
然后我们看到add 方法其实是调用的是addLast 方法。
从上面的方法我们对addFirst和addLast(add) 的解释我们知道添加元素的过程是一个从两边向中间的过程,现在我们就用图模拟一下这个过程
@Test
public void createQueue() {
ArrayDeque<String> brothers = new ArrayDeque<>(7);
// 第一次插入
brothers.addFirst("老大");
brothers.addLast("老八");
// 第二次插入
brothers.addFirst("老二");
brothers.addLast("老七");
// 第三次插入
brothers.addFirst("老三");
brothers.addLast("老六");
}
这里有一家八兄弟今天要上山大虎,俗话说上阵父子兵,大虎亲兄弟,老爹为了一碗水端平,按照兄弟实力两两一组进行分配,既为了公平也为了安全,要是把老七和老八分一组,那就不知道到到底是喂老虎还是打老虎了。奈何老爹数据结构没学好好,还是把老大和老二安排在一起了。
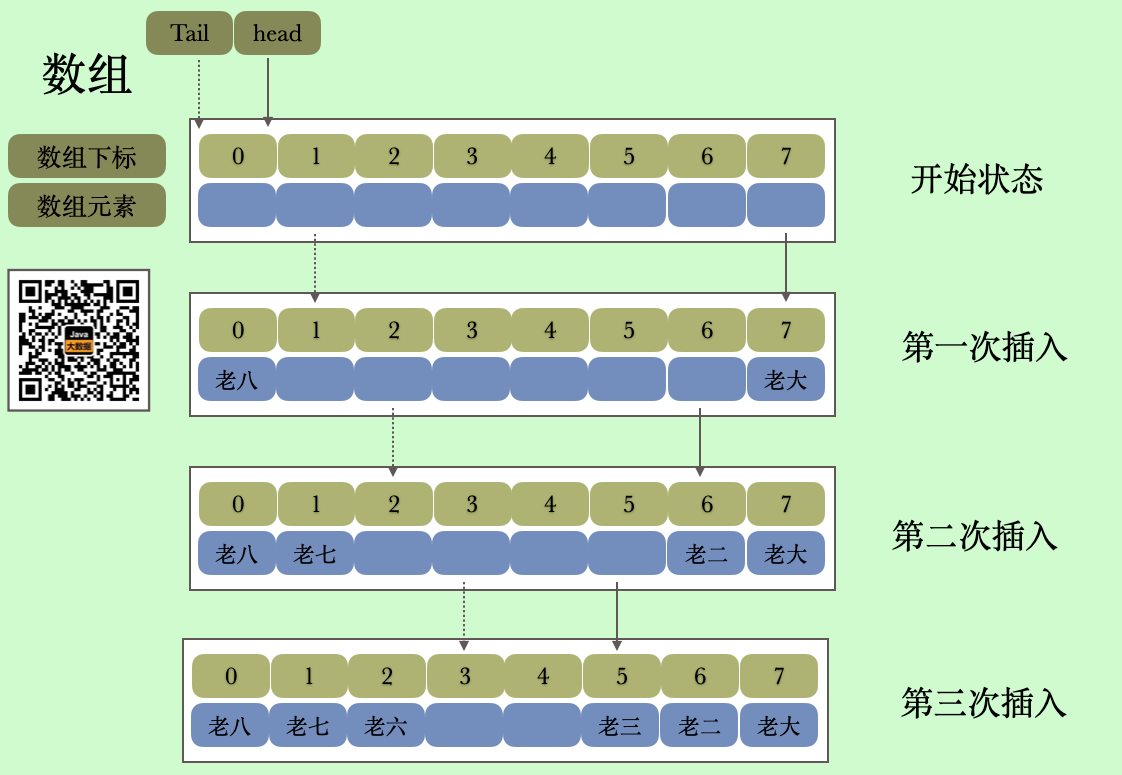
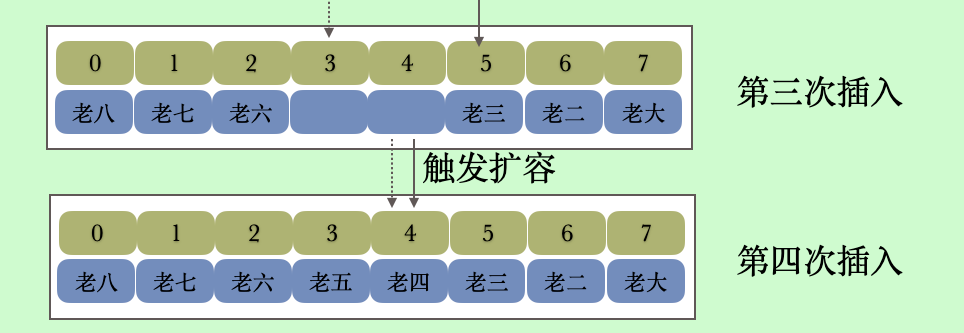
其实我们从上面清楚的看到两个指针在想中间靠拢,我们看到第三次插入之后tail=3 head=4,如果下一次插入的时候也就是第四次插入,当老五查进去的时候head 就会等于tail 等于4,这个时候则触发扩容,后面我们单独看扩容方法。
@Test
public void createQueue() {
ArrayDeque<String> brothers = new ArrayDeque<>(7);
// 第一次插入
brothers.addFirst("老大");
brothers.addLast("老八");
// 第二次插入
brothers.addFirst("老二");
brothers.addLast("老七");
// 第三次插入
brothers.addFirst("老三");
brothers.addLast("老六");
// 第四次插入
brothers.addFirst("老四");
// 老四插入进去的时候就会触发扩容
brothers.addLast("老五");
System.out.println(brothers);
}
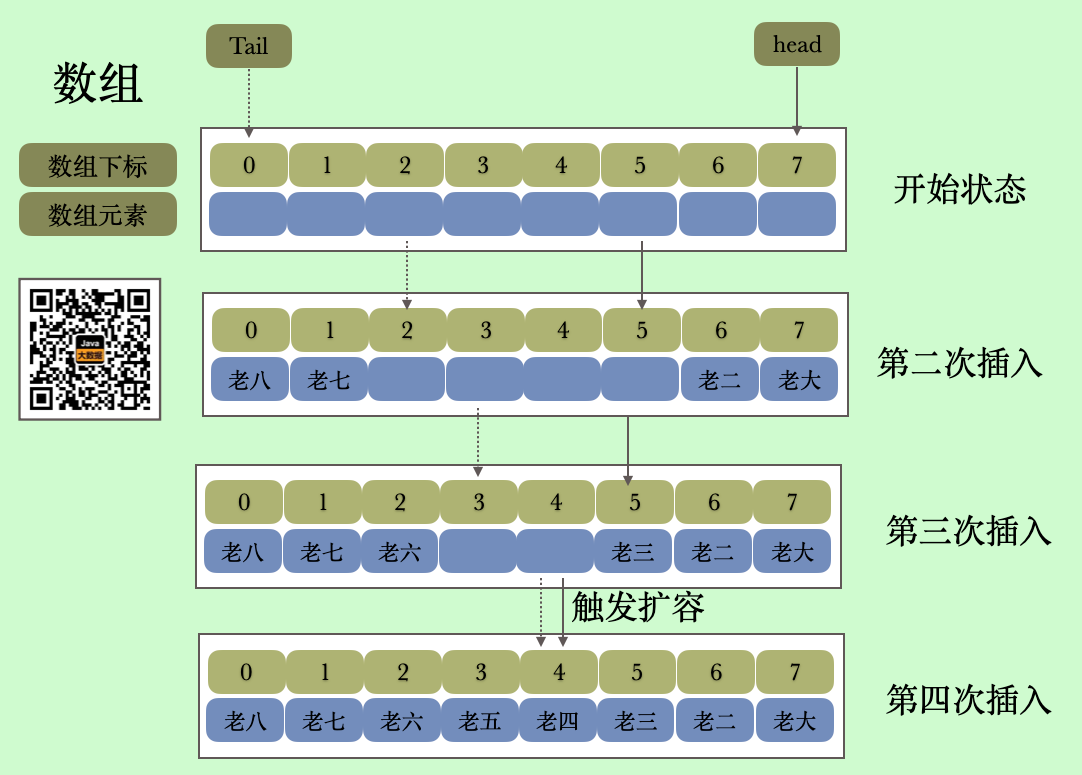
输出[老四, 老三, 老二, 老大, 老八, 老七, 老六, 老五]
你有没有觉得好奇这个输出好像有点奇怪啊,并不是直接按照数组下标从小到大输出。而是先从head 输出到数组的最后一位,然后从下标为0的地方开始输出到tail,假设我们使用第三次插入之后的结果描述一下输出的话
首先从左到右输出从head 开始到数组结尾的数据,也就是head右半部分,然后从左到右输出0到tail 的数据,也就是head 的左半部分。大家考虑一下为什么要这样设计,接下来我们看一下访问元素的方法
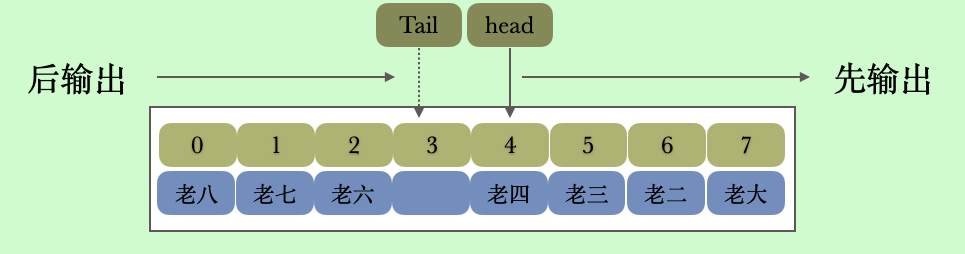
getFirst 和 getLast 方法
我们针对下面的数据解释一下getFirst 和 getLast方法
getFirst
/**
* @throws NoSuchElementException {@inheritDoc}
*/
public E getFirst() {
@SuppressWarnings("unchecked")
E result = (E) elements[head];
if (result == null)
throw new NoSuchElementException();
return result;
}
因为head 就是指向当前队列的头部,所以直接使用elements[head] 即可返回队列头部的元素
getLast
/**
* @throws NoSuchElementException {@inheritDoc}
*/
public E getLast() {
@SuppressWarnings("unchecked")
E result = (E) elements[(tail - 1) & (elements.length - 1)];
if (result == null)
throw new NoSuchElementException();
return result;
}
因为tail 就是指向当前队列的尾部的下一个元素,所以需要使用elements[tail-1] 才能返回队列尾部元素。
@Test
public void createQueue() {
ArrayDeque<String> brothers = new ArrayDeque<>(7);
// 第一次插入
brothers.addFirst("老大");
brothers.addLast("老八");
// 第二次插入
brothers.addFirst("老二");
brothers.addLast("老七");
// 第三次插入
brothers.addFirst("老三");
brothers.addLast("老六");
// 第四次插入
brothers.addFirst("老四");
brothers.addLast("老五");
System.out.println(brothers);
String laosi = brothers.getFirst();
String laowu = brothers.getLast();
System.out.println(laosi);
System.out.println(laowu);
System.out.println(brothers);
}
输出结果
[老四, 老三, 老二, 老大, 老八, 老七, 老六, 老五]
老四
老五
[老四, 老三, 老二, 老大, 老八, 老七, 老六, 老五]
pollFirst 和 pollLast
其实我们知道poll 和get 的区别就是获取元素之后是否删除该元素,我们还是直接从代码的输出结果上看区别吧
@Test
public void createQueue() {
ArrayDeque<String> brothers = new ArrayDeque<>(7);
// 第一次插入
brothers.addFirst("老大");
brothers.addLast("老八");
// 第二次插入
brothers.addFirst("老二");
brothers.addLast("老七");
// 第三次插入
brothers.addFirst("老三");
brothers.addLast("老六");
// 第四次插入
brothers.addFirst("老四");
brothers.addLast("老五");
System.out.println(brothers);
String laosi = brothers.pollFirst();
String laowu = brothers.pollLast();
System.out.println(laosi);
System.out.println(laowu);
System.out.println(brothers);
}
输出结果
[老四, 老三, 老二, 老大, 老八, 老七, 老六, 老五]
老四
老五
[老三, 老二, 老大, 老八, 老七, 老六]
我们看到pollFirst和pollLast 方法访问完元素之后也把元素从队列面删除了,接下来我们看一下源码实现
pollFirst
public E pollFirst() {
int h = head;
@SuppressWarnings("unchecked")
E result = (E) elements[h];
// Element is null if deque empty
if (result == null)
return null;
// 设置为空,切断和对该对象的引用,让垃圾回收器可以回收该对象
elements[h] = null; // Must null out slot
// 移动head,指向下一位。
head = (h + 1) & (elements.length - 1);
return result;
}
其实和getFirst方法基本一样,只不过多了重新设置head 和将以前head 的位置设置为null ,让数组不再引用该对象
public E pollLast() {
int t = (tail - 1) & (elements.length - 1);
@SuppressWarnings("unchecked")
E result = (E) elements[t];
if (result == null)
return null;
elements[t] = null;
tail = t;
return result;
}
和pollFirst的操作基本是一样的
toArray
public Object[] toArray() {
return copyElements(new Object[size()]);
}
我们知道该队列底层是通过数组实现的,那么为什么还要提供一个copyElements 方法返回数组呢,而不是直接返回数组呢?其实这就和该队列的设计有关了,toArray 方法返回我们我们是从队列到队列尾部这样一个有序的数组,但是ArrayDeque中存储元素的数组却不是有序的。例如下面的数据
toArray 方法的返回应该是这个样子的
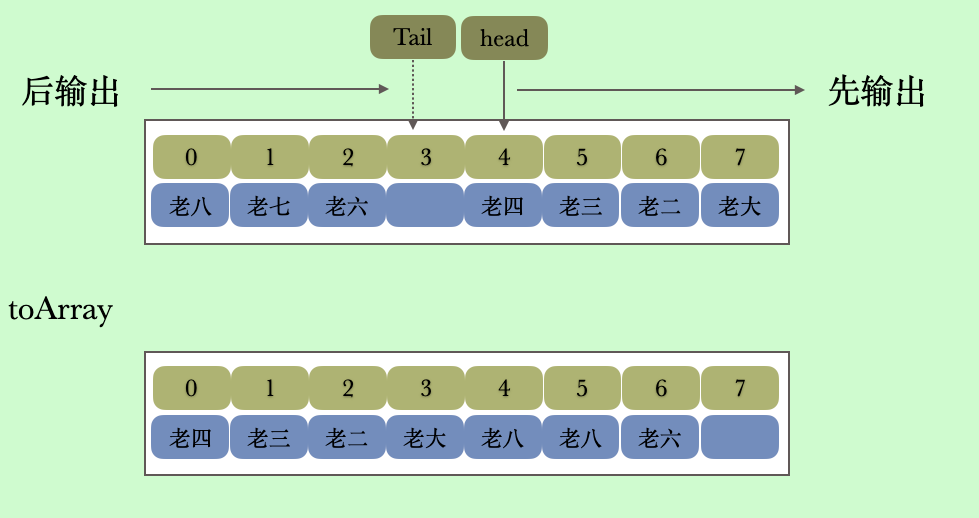
@Test
public void createQueue() {
ArrayDeque<String> brothers = new ArrayDeque<>(7);
// 第一次插入
brothers.addFirst("老大");
brothers.addLast("老八");
// 第二次插入
brothers.addFirst("老二");
brothers.addLast("老七");
// 第三次插入
brothers.addFirst("老三");
brothers.addLast("老六");
// 第四次插入
brothers.addFirst("老四");
brothers.addLast("老五");
System.out.println(brothers);
System.out.println(Arrays.toString(brothers.toArray()));
}
输出结果
[老四, 老三, 老二, 老大, 老八, 老七, 老六, 老五]
[老四, 老三, 老二, 老大, 老八, 老七, 老六, 老五]
其实我们从输出结果可以看出System.out.println(brothers); 和 System.out.println(Arrays.toString(brothers.toArray())); 是一样的,那我们可以看一下toArray的实现
/**
* Copies the elements from our element array into the specified array,
* in order (from first to last element in the deque). It is assumed
* that the array is large enough to hold all elements in the deque.
* 这里有一句话, in order (from first to last element in the deque) 以队列从头到尾的顺序
* @return its argument
*/
private <T> T[] copyElements(T[] a) {
if (head < tail) {
System.arraycopy(elements, head, a, 0, size());
} else if (head > tail) {
int headPortionLen = elements.length - head;
// 复制head 右边的数据(从左到右)
System.arraycopy(elements, head, a, 0, headPortionLen);
// 复制tail 左边的数据(从左到右)
System.arraycopy(elements, 0, a, headPortionLen, tail);
}
return a;
}
我们看到为了保持顺序,将队列里的元素分为了两部分进行复制。可以参考我们的图示,这里有个问题就是if(head<tail) 这个判断条件有点奇怪,我们知道head = tail 的时候就会触发扩容,那么扩容之后head 必然会大于tail。 那么到底什么时候会出现这种情况呢?那就是扩容的时候
doubleCapacity
其他很多方法的实现也简单,这里我们就不再去解释了。doubleCapacity 是我么看的左后一个方法了,我们知道当head 和 tail 相等的时候就要出发扩容了,那到底是怎么扩容的呢,就是我们下面的方法。
/**
* Doubles the capacity of this deque. Call only when full, i.e.,
* when head and tail have wrapped around to become equal.
* 当当head 和 tail 相等的时候,就容量翻倍
*/
private void doubleCapacity() {
assert head == tail;
int p = head;
int n = elements.length;
int r = n - p; // number of elements to the right of p
// 位元素,容量翻倍,如果超出int 类型限制,则为负数然后抛出异常
int newCapacity = n << 1;
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
// 创建新的数组
Object[] a = new Object[newCapacity];
// 还是分成两部分复制元素到新的数组,不过是把head 的右侧部分放在了tail 的左侧部分之前
System.arraycopy(elements, p, a, 0, r);
System.arraycopy(elements, 0, a, r, p);
// 重新设置变量
elements = a;
// head 回到了为当初的0,下次插入元素的时候就会回到数组下标最大的地方,这个时候我们看到head 就是小于tail
head = 0;
tail = n;
}
我们看到当我们下次插入元素的时候,在这里就是老五就会触发扩容
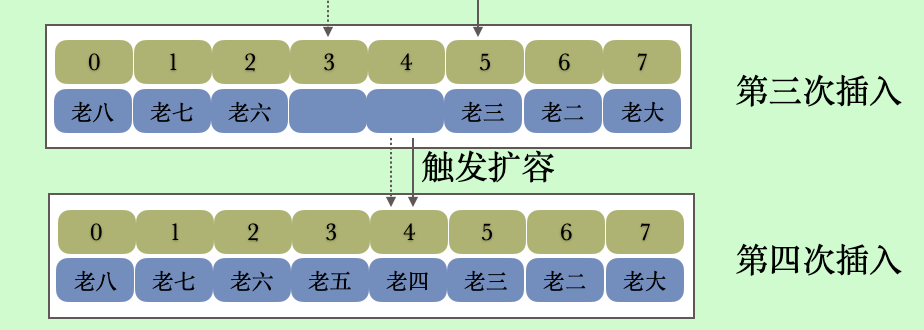
下面我们从画图演示一下扩容的过程
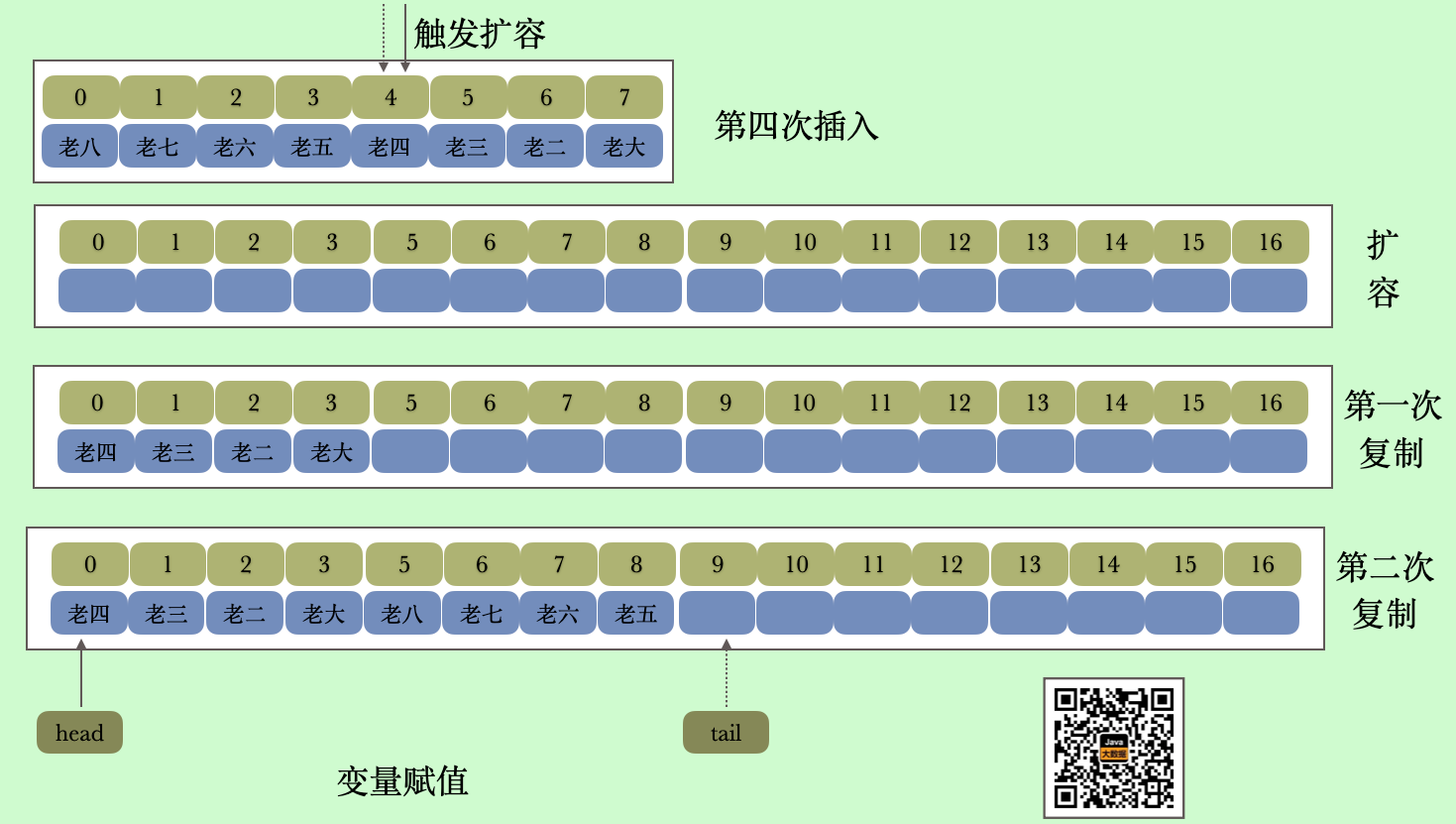
其实我们看到扩容的时候将队列的头部放在了尾部的左侧,其实相当于一次调整顺序。我们看到复制完之后head 是小于tail 的,也就是toArray 的if (head < tail) 判断
private <T> T[] copyElements(T[] a) {
if (head < tail) {
System.arraycopy(elements, head, a, 0, size());
} else if (head > tail) {
int headPortionLen = elements.length - head;
// 复制head 右边的数据(从左到右)
System.arraycopy(elements, head, a, 0, headPortionLen);
// 复制tail 左边的数据(从左到右)
System.arraycopy(elements, 0, a, headPortionLen, tail);
}
return a;
}
总结
Queue 我们介绍了很多了,不论是基于LinkedList 实现的队列还是双向队列底层都是基于链表实现的,因此在删除(弹出)的时候不会涉及到数据的迁移
但是基于数组的实现就会涉及到,所以为了避免数据的迁移,所以ArrayDeque采取了两端向中间的这样一种设计,避免了数据迁移,head 和 tail 相等的时候就需要扩容了。