文章目录
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、方差的偏差的解释
期望值与真实值之间的波动程度,衡量的是稳定性
期望值与真实值之间的一致差距,衡量的是准确性
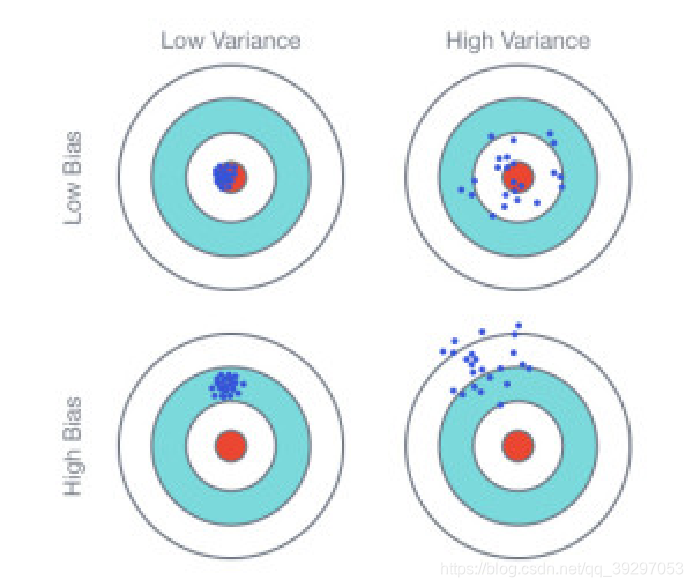
如图所示,图中的蓝色点位预测结果,越靠近靶心越准备。对于预测结果的性质描述:
图一:低偏差第方差
图二:低偏差高方差
图三:低偏差高方差
图四:高偏差高方差
优化监督学习=优化模型的泛化误差,模型的泛化误差可分解为偏差、方差与噪声之和 Err = bias + var + irreducible error
二、什么情况下引发高方差?
过高复杂度的模型,对训练集进行过拟合
带来的后果就是在训练集合上效果非常好,但是在校验集合上效果极差
更加形象的理解就是用一条高次方程去拟合线性数据
如何解决高方差问题?
在模型复杂程度不变的情况下,增加更多数据
在数据量不变的情况下,减少特征维度
在数据和模型都不变的情况下,加入正则化
以上方法是否一定有效?
增加数据如果和原数据分布一致,无论增加多少必定解决不了高方差
减少的特征维度如果是共线性的维度,对原模型没有任何影响
正则化通常都是有效的
三、什么情况下引发高偏差?
模型不准确
训练集的数据质量不高
如何解决高偏差问题?
尝试获得更多的特征
从数据入手,进行特征交叉,或者特征的embedding化
尝试增加多项式特征
从模型入手,增加更多线性及非线性变化,提高模型的复杂度
尝试减少正则化程度λ
以上方法是否一定有效?
特征越稀疏,高方差的风险越高
正则化通常都是有效的
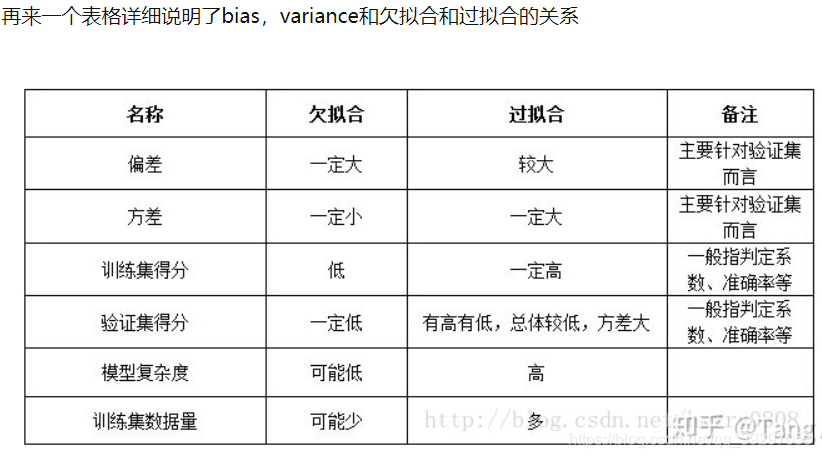
方差,偏差与欠拟合和过拟合的对比
PS:
神经网络的拟合能力非常强,因此它的训练误差(偏差)通常较小; 但是过强的拟合能力会导致较大的方差,使模型的测试误差(泛化误差)增大; 因此深度学习的核心工作之一就是研究如何降低模型的泛化误差,这类方法统称为正则化方法。
dropout
dense中的normalization
数据的shuffle