一、程序的开始和结束
1、main 函数由谁来调用?
(1)裸机阶段
我们在裸机的时候,会有一段汇编用作引导代码。提前配置好C语言的编程环境。
(2)操作系统阶段
编译器在编译的时候,帮我们添加了引导代码,准确的说是在链接的时候,由链接器将编译器中准备好的引导代码给连接进去。
(3)运行程序时候的加载器(./a.out 执行我们可执行程序的时候)
加载器是操作系统中的程序,当我们去执行一个程序时(譬如./a.out,譬如代码中用exec族函数来运行)加载器负责将这个程序加载到内存中去执行这个程序。
总结:编译链接时:链接器 程序运行时:加载器
(4)argc 和 argv 的传参与 exec族函数 有关。
2、程序如何结束
(1)正常结束:return 0 return -1, exit、_exit、
(2)非正常结束:自己或他人发信号终止进程。
比如当我们程序在死循环之后,我们利用 Ctrl + C 就可以强制退出。(这也算是一个信号)
3、atexit注册进程终止处理函数
- 实验代码
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void func1(void)
{
printf("func1\n");
}
void func2(void)
{
printf("func2\n");
}
int main(void)
{
printf("hello world.\n");
// 当进程被正常终止时,系统会自动调用这里注册的func1执行
atexit(func2);
atexit(func1);
printf("test for atexit \n");
//return 0;
//exit(0);
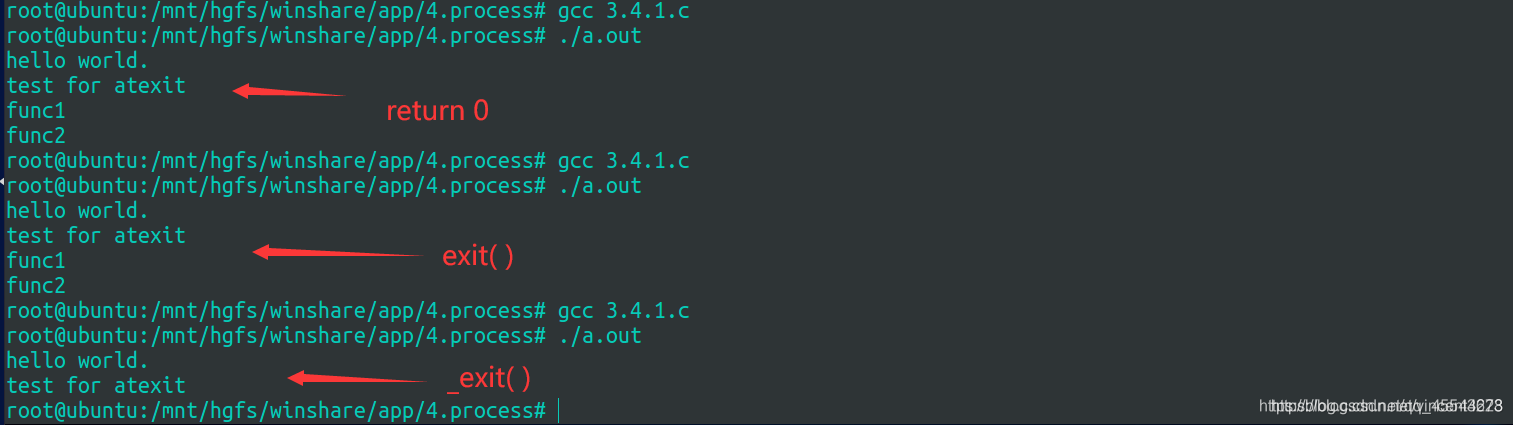
_exit(0);
}
注:
(1)atexit注册多个进程终止处理函数,先注册的后执行(先进后出,和栈一样)
(2)return、exit和_exit的区别:return和exit效果一样,都是会执行进程终止处理函数,但是用_exit终止进程时并不执行atexit注册的进程终止处理函数。
二、进程环境
1、环境变量
(1)使用 export 命令 可以查看当前系统中所有的环境变量。
(2)每一个进程当中,都会有一份所有环境变量的备份——叫做进程环境表,也就是说我们当前进程中可以直接使用这些环境变量。
进程环境表本质其实就是字符串(是一个指针),environ 是一个二重指针,用来指向它。
(3)程序当中通过 environ 全局变量使用环境变量。
#include <stdio.h>
int main(int argc,char *argv[])
{
extern char **environ ; // 我们只需要外部声明即可,在链接阶段会帮我们找到的
int i = 0;
while(NULL != environ)
{
printf("%s\n",environ[i]);
i++;
}
return 0;
}
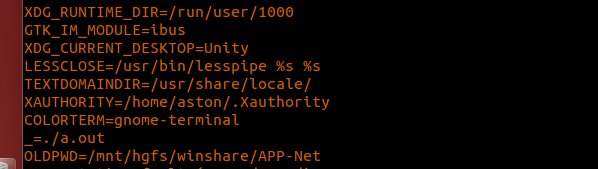
注意: 当我们的程序当中使用了环境变量,那么程序就和环境变量有关了。
(所以我们有时候代码不可以直接拿过来使用,因为环境变量有可能不同)
(4)使用一些特定的 库函数 来对环境变量进行操作。这些库函数只针对我们当前进程当中的环境变量备份有效。
clearenv(3),
getauxval(3),
putenv(3), setenv(3), unsetenv(3), capabilities(7), environ(7)
2、进程运行的虚拟地址空间
(1)操作系统中的每个进程都在一个独立的地址空间中运行。每个进程都以为自己是操作系统当中唯一的进程。但事实上他们是分时复用的。
(2)在32位系统当中,我们操作系统给都每个进程都分配了 4G 的逻辑内存空间。但是实际上的内存空间是我们实际的内存条的大小。
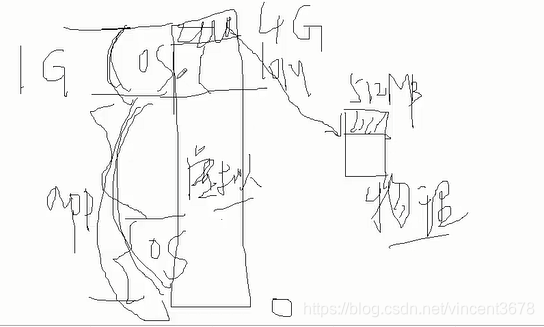
逻辑上我们给每个进程分配 4G 的内存空间,但是实际上我们的进程可能连 2MB 都没有使用到。就是我允许它用到 4G ,但是它撑死也用不到。
(3)0-1G为OS,1-4G为应用(APP)
(4)虚拟地址到物理地址空间的映射的意义
-
进程隔离:每个进程都以为只有自己一个进程 ,这样就保证了 qq 不会窃取支付宝的信息
-
提供多个进程同时运行:
之前跑裸机代码的时候,我们链接的时候必须将虚拟地址对应到实际的物理地址上运行。因为裸机代码当时只有一个程序在运行,我们可以进行手动对应。
但是当我们运行多个程序的时候,我们根本不知道我们程序对应哪一块的实际地址。
在操作系统当中,我们的程序都是从 0 地址开始,真正对应的物理地址是多少不需要我们来操心,操作系统会帮我们做好。
注:
可以提供 虚拟地址到物理地址空间的映射的操作系统,被我们称为高级系统。里面的程序叫做进程
单片机当中的一些 RTOS 不可以提供这种映射,我们称之为低级系统,里面的程序叫做任务。
举例:
之前的非智能手机上面装的就是 RTOS 系统,它上面的软件是固定死的,不能在线安装,只能重新烧录
三、进程的正式引入
1、进程的定义
进程和程序的区别:
程序:是一份源代码,静静躺在硬盘当中。(静态事物)
进程:程序经过编译之后生成的二进制文件,从而被执行的过程
(1)他是一个动态过程而不是静态实物
(2)进程就是程序的一次运行过程,一个静态的可执行程序a.out的一次运行过程(./a.out去运行到结束)就是一个进程。
(3)进程控制块PCB(process control block),内核中专门用来管理一个进程的数据结构。
(4)进程 ID
利用 ps 命令,来打印我们操作系统当中正在运行的进程
ps (当前终端正在运行的)
ps -a (所有终端运行的)
ps -aux (整个操作系统当中运行的进程)
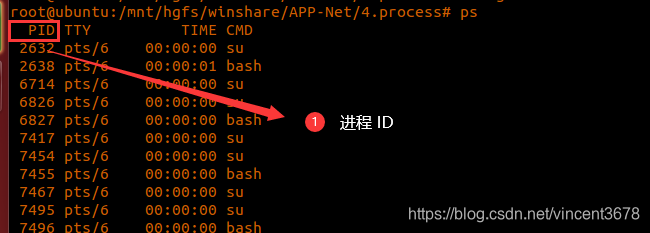
getpid:当前进程自己的ID
getppid:当前进程的父进程的ID。(parent)
getuid :当前进程的用户ID。(user)geteuid (有效用户ID)
getgid::当前进程的组ID。(group)getegid (有效组ID)
测试代码:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main(void)
{
pid_t p1 = -1, p2 = -1;
printf("hello.\n");
p1 = getpid(); //获取进程的ID号
printf("pid = %d.\n", p1);
p2 = getppid(); //获取进程的父进程
printf("parent id = %d.\n", p2);
return 0;
}

我们可以查到我们当前进程的父进程是 bash
2、多进程调度的特点
(1)操作系统同时运行多个进程,因为随着芯片处理速度越来越快,而我们一般进程也用不掉这么多速度,所以我们希望它可以进行多个进程。
(2)宏观上的并行 和 微观上的串行。因为单核的cpu,每个瞬间只能执行一个任务。
(3)实际上现代操作系统最小的调度单元是线程而不是进程。
注:多进程运行存在一个问题:哪一个任务优先级比较高?
所以就涉及到了进程的调度。
四、父子进程(老进程和新进程)
1、fork函数创建子进程
1、为什么要创建子进程?
(1)每一次程序的运行都需要一个进程
(2)多进程实现宏观上的并行
2、fork的内部原理
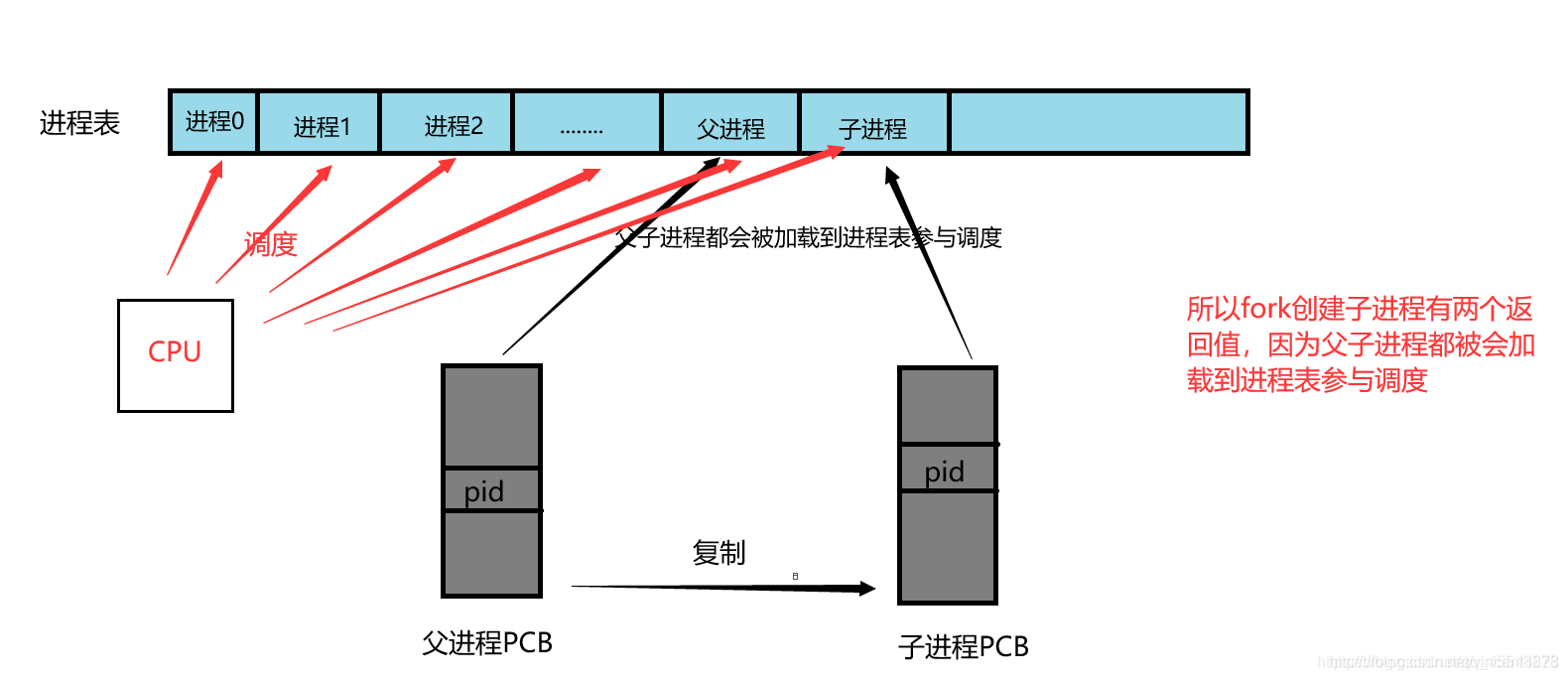
(1)进程的分裂生长模式。
如果操作系统需要一个新进程来运行一个程序,那么操作系统会用一个现有的进程来复制生成一个新进程。
老进程叫父进程,复制生成的新进程叫子进程。子进程有自己独立的PCB子,被内核同等调度。
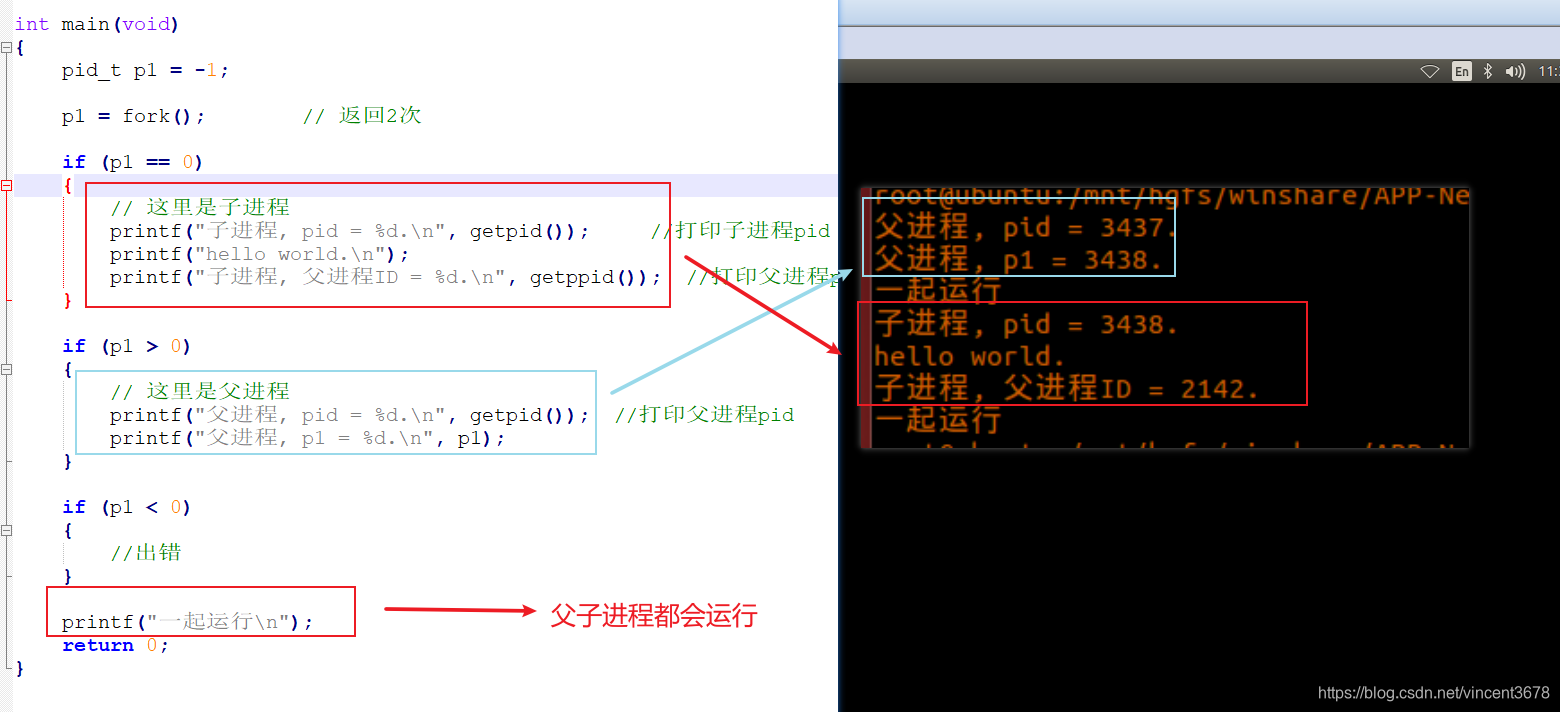
(2)fork的演示
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main(void)
{
pid_t p1 = -1;
p1 = fork(); // 返回2次
if (p1 == 0)
{
// 这里是子进程
printf("子进程, pid = %d.\n", getpid()); //打印子进程pid
printf("hello world.\n");
printf("子进程, 父进程ID = %d.\n", getppid()); //打印父进程pid
}
if (p1 > 0)
{
// 这里是父进程
printf("父进程, pid = %d.\n", getpid()); //打印父进程pid
printf("父进程, p1 = %d.\n", p1);
}
if (p1 < 0)
{
//出错
}
pritf("一起运行");
return 0;
}
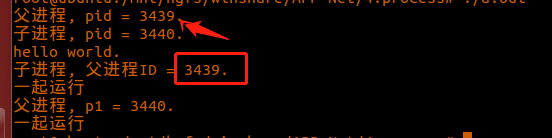
总结:
1、fork 函数的两次返回,将父子进程分割开来。
2、在 父子进程之外的地方,两个进程都要运行。
3、可以看出子进程的父进程id 是2142(这种情况属于孤儿进程),或者是 3439 。

4、当 fork 函数返回值>0的时候,其实它的数值等于子进程的id。
5、可以看出父子进程,运行的顺序并不确定。
2、父子进程对文件的操作
第一种情况:子进程继承父进程中打开的文件
注:只 open 一次,并且在fork() 之前open, 所以只利用一个文件描述符
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdlib.h>
int main(void)
{
// 首先打开一个文件
int fd = -1;
pid_t pid = -1;
fd = open("1.txt", O_RDWR | O_TRUNC);
if (fd < 0)
{
perror("open");
return -1;
}
// fork创建子进程
pid = fork();
if (pid > 0)
{
// 父进程中
printf("parent.\n");
write(fd, "hello", 5);
sleep(1);
}
else if (pid == 0)
{
// 子进程
printf("child.\n");
write(fd, "world", 5);
sleep(1);
}
else
{
perror("fork");
exit(-1);
}
close(fd);
return 0;
}

测试结论是:接续写,打印出hello world。
实际上本质原因是父子进程之间的fd对应的文件指针是相同的(很像O_APPEND标志后的样子)
第二种情况:父子进程各自独立打开同一文件实现共享
注:open两次,分别在自己的情况下 open,相当于各自利用各自的文件指针。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdlib.h>
int main(void)
{
// 首先打开一个文件
int fd = -1;
pid_t pid = -1;
// fork创建子进程
pid = fork();
if (pid > 0)
{
// 父进程中
fd = open("1.txt", O_RDWR | O_TRUNC);
if (fd < 0)
{
perror("open");
return -1;
}
printf("parent.\n");
write(fd, "hello", 5);
sleep(1);
}
else if (pid == 0)
{
// 子进程
fd = open("1.txt", O_RDWR|O_TRUNC);
if (fd < 0)
{
perror("open");
return -1;
}
printf("child.\n");
write(fd, "world", 5);
sleep(1);
}
else
{
perror("fork");
exit(-1);
}
close(fd);
return 0;
}

结论是:分别写。
原因是父子进程分离后才各自open的1.txt,这时候这两个进程的PCB已经独立了,文件表也独立了,因此2次读写是完全独立的。
为什么只剩下 world 了呢?
因为先执行父进程,然后执行子进程,在子进程 open 的时候,里面的 O_TRUNC 参数已经将文件清空。
3、总结
父进程在没有fork之前自己做的事情对子进程有很大影响
但是父进程fork之后在自己的if里做的事情就对子进程没有影响了。
本质原因就是因为fork内部实际上已经复制父进程的PCB生成了一个新的子进程,并且fork返回时子进程已经完全和父进程脱离并且独立被OS调度执行。
子进程最终目的是要独立去运行另外的程序
五、进程的诞生和消亡
1、进程的诞生
(1)进程0和进程1 (操作系统自带)
(2)fork (我们自己创建)
(3)vfork (我们自己创建)
2、进程的消亡(涉及资源回收)
(1)正常终止和异常终止
(2)进程在运行时需要消耗系统资源(内存、IO),进程终止时理应完全释放这些资源(如果进程消亡后仍然没有释放相应资源则这些资源就丢失了)
(3)linux系统设计时规定:每一个进程退出时,操作系统会自动回收这个进程涉及到的所有的资源(譬如malloc申请的内容没有free时,当前进程结束时这个内存会被释放,譬如open打开的文件没有close的在程序终止时也会被关闭)。
但是操作系统只是回收了这个进程工作时消耗的内存和IO,而并没有回收这个进程本身占用的内存(8KB,主要是task_struct和栈内存)
(4)因为进程本身的8KB内存操作系统不能回收,需要别人来辅助回收,因此我们每个进程都需要一个帮助它收尸的人,这个人就是这个进程的父进程。
3、僵尸进程(子进程先于父进程结束)
(1)子进程结束后父进程此时并不一定立即就能帮子进程“收尸”,在这一段(子进程已经结束且父进程尚未帮其收尸)子进程就被成为僵尸进程
(2)子进程 除了 task_struct和栈外其余内存空间皆已清理(因为子进程自己结束后,操作系统回收)
(3)父进程可以使用wait 或 waitpid以显式回收子进程的剩余待回收内存资源并且获取子进程退出状态。
(4)父进程也可以不使用wait或者waitpid回收子进程,此时父进程结束时一样会回收子进程的剩余待回收内存资源。(这样设计是为了防止父进程忘记显式调用wait/waitpid来回收子进程从而造成内存泄漏)
4、孤儿进程(父进程先于子进程结束)
(1)父进程先于子进程结束,子进程成为一个孤儿进程。
(2)linux系统规定:所有的孤儿进程都自动成为一个特殊进程(进程1,也就是init进程)的子进程。
怎么查看 init 进程id呢? ps aux

六、父进程wait回收子进程
1、wait 函数的工作原理
(1)子进程结束时,系统向其 父进程发送 SIGCHILD 信号
(2)父进程调用 wait 函数后阻塞。(阻塞的意思就是,一直等待,什么也不做)(目的就是在等待子进程发送的 SIGCHILD 信号 )
(3)父进程被 SIGCHILD信号唤醒 ,然后去回收僵尸子进程
(4)父子进程是异步的。SIGCHILD 信号机制就是为了解决父子进程的异步运行问题,让父进程可以及时去回收僵尸子进程。
(5)若父进程没有任何子进程,则 wait 返回错误。
2、wait 函数实战
pid_t wait(int *status);
输出型参数:int *status (相当于返回值)
status用来返回子进程结束时的状态,父进程通过wait得到status后就可以知道子进程的一些结束状态信息。
返回值: pid_t
就是本次wait回收的子进程的PID。
详解输出型参数:int *status (相当于返回值)
status用来返回子进程结束时的状态
一般的状态参数,我们在man 手册当中都可以查到对应的宏。
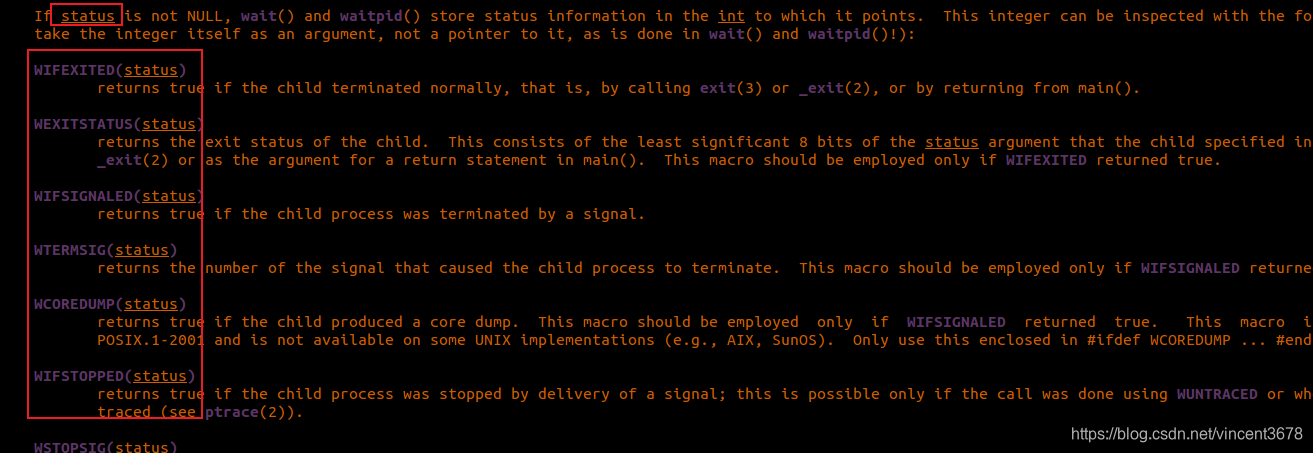
WIFEXITED、WIFSIGNALED、WEXITSTATUS这几个宏用来获取子进程的退出状态。
WIFEXITED:宏用来判断子进程是否正常终止(return、exit、_exit退出)
WIFSIGNALED:宏用来判断子进程是否非正常终止(被信号所终止)
WEXITSTATUS:宏用来得到正常终止情况下的进程返回值的
详解返回值:
(1)一个父进程,可以有多个子进程。比如在一个父进程下有三个子进程,一个在看电影,一个在聊qq,还有一个在记笔记。
(2)wait函数阻塞直到其中一个子进程结束,wait就会返回。
(3)这是时候,wait的返回值,就可以用来判断到底是哪一个子进程本次被回收了。
代码实践
注:由前面的经验可得,父子进程的运行顺序并不确定。然而我们希望 子进程先执行并且先结束。
解决:当我们在 if>0 的时候,即在父进程当中,使用 wait 函数,所以父进程被阻塞,所以肯定父进程后结束。
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdlib.h>
int main(void)
{
pid_t pid = -1;
pid_t ret = -1;
int status = -1;
pid = fork();
if (pid > 0)
{
// 父进程
printf("parent.\n");
ret = wait(&status);
printf("子进程已经被回收,子进程pid = %d.\n", ret);
printf("子进程是否正常退出:%d\n", WIFEXITED(status));
printf("子进程是否非正常退出:%d\n", WIFSIGNALED(status));
printf("正常终止的终止值是:%d.\n", WEXITSTATUS(status));
}
else if (pid == 0)
{
// 子进程
printf("child pid = %d.\n", getpid());
return 51;
//exit(0);
}
else
{
perror("fork");
return -1;
}
return 0;
}

3、waitpid
pid_t waitpid(pid_t pid, int *status, int options);
参数:
pid_t pid :指定回收哪些子进程
int *status :判断子进程的消亡状态。
int options :一些参数:比如选择是否阻塞。
1、waitpid和wait差别
(1)基本功能一样,都是用来回收子进程
(2)waitpid可以 回收指定PID的子进程,而我们 wait 函数不可以,谁先结束就回收谁。
(3)waitpid可以阻塞式或非阻塞式两种工作模式。
非阻塞式:当我们 wait 的时候,我们不去等待,如果子进程没有提前结束,那就错过了回收机会。立即返回

2、写代码查看细节:
第一种: 使用 waitpid 来实现 wait 的效果。(不挑子进程)
ret = wait(&status);
ret = waitpid(-1, &status, 0);
分析参数:
-1: 因为子进程的id 都为正数,所以 -1 就表示我们 waitpid 不挑子进程。
&status :判断子进程的消亡状态
0 :表示使用默认的阻塞式。
第二种:回收特定的子进程。
因为当fork 返回值>0 的时候,其返回值的本质,其实就子进程的id。
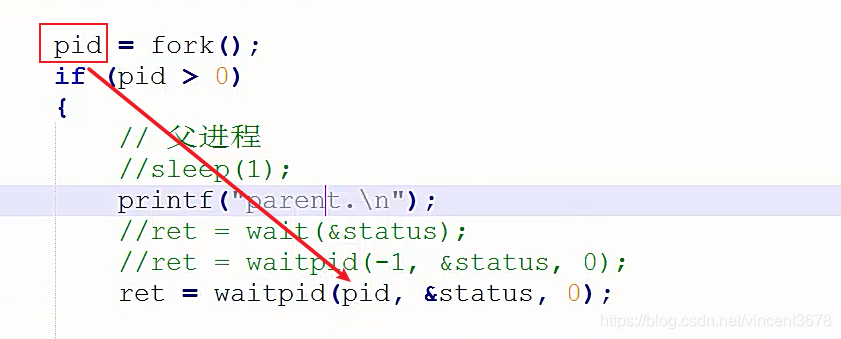
waitpid 返回值 ret:
如果当前进程并没有一个ID号为pid的子进程,则返回值为-1;(表示出错)
如果成功回收了pid这个子进程则返回值为回收的进程的PID。
第三种:非阻塞模式
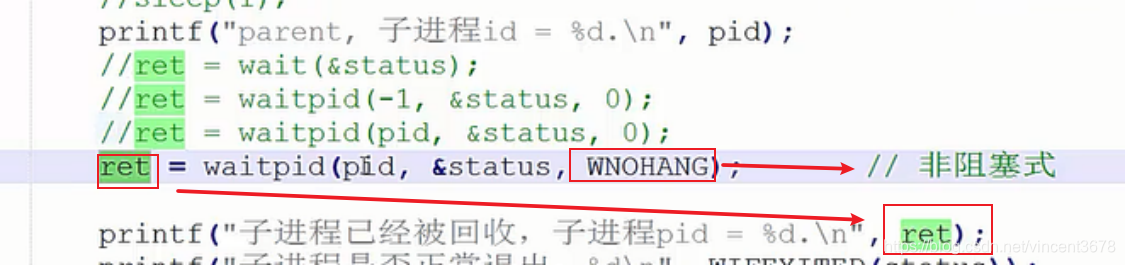
waitpid 返回值 ret:
此时如果父进程执行waitpid时,子进程已经先结束,则waitpid直接回收成功,返回值是回收的子进程的PID;
如果父进程waitpid时,子进程尚未结束,则父进程立刻返回(非阻塞),但是返回值为0(表示回收不成功)。
4、竟态初步引入
竞争状态:在多进程条件下,多个进程同时抢占系统资源(内存、CPU、文件IO)。
(1)比如说父进程先执行,还是子进程先执行?
(2)父进程先open文件,还是子进程先 open 文件?
竞争状态对OS来说是很危险的,此时OS如果没处理好就会造成结果不确定。
我们写程序时要尽量消灭竞争状态。
操作系统给我们提供了一系列的消灭竟态的机制,我们需要做的是在合适的地方使用合适的方法来消灭竟态。
(1)比如: 我们希望子进程先执行,我们可以在父进程当中添加 sleep(1) , 适当的让父进程延时。
七、exec 族函数(可以加载运行可执行程序)
1、为什么需要exec函数?
(1)我们 fork 产生子进程的目的:是为了子进程执行新的程序。(并且是和父进程同时进行)(因为:在fork 子进程之后,操作系统会将其同时调用)。
(2)可以直接在子进程的 if 中写入新程序的代码。这样可以,但是不够灵活。
缺点:
我们只能把子进程程序的源代码,写入到 if当中。必须知道源代码,而且源代码太长了也不好控制
如果我们希望子进程来执行ls -la命令就不行了(没有源代码,只有编译好的可执行程序)
解决办法:使用 exec 族函数
2、exec族的6个函数介绍
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ..., char * const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[], char *const envp[]);
参数解析:
const char *path : 我们想要执行的 目标程序的全路径
const char *file :可以是file,也可以是path,只不过兼容了file。(可执行文件也是 file)
const char *arg :我们想给可执行程序传入的参数。 比如说ls -la中的-la
… : 代表可以拥有多个参数,但是我们要求最后一个参数必须是NULL。
(1)execl 和 execv 的区别
这两个函数是最基本的exec,都可以用来执行一个程序,区别是传参的格式不同。
execl是把参数列表(本质上是多个字符串,必须以NULL结尾)依次排列而成(l 其实就是list的缩写)execv是把参数列表事先放入一个字符串数组中,再把这个字符串数组传给execv函数。
execl("/bin/ls", "ls", "-l", "-a", NULL); / execl函数
char * const arg[] = {
"ls", "-l", "-a", NULL}; /execv函数
execv("/bin/ls", arg);
(2)execlp 和 execvp 和 execl 和 execv 的区别
这两个函数在上面2个基础上加了p,区别是:
(1)上面2个执行程序时,必须指定可执行程序的全路径(如果exec没有找到path这个文件则直接报错),
(2)而加了p的传递的可以是file,也可以是path,只不过兼容了file。
加了p的这两个函数会首先去找file,如果找到则执行执行,如果没找到则会去环境变量PATH所指定的目录下去找,如果找到则执行如果没找到则报错)
(3)execle 和 execvpe 和 execl 和 execv 的区别
这两个函数较基本exec来说加了e,函数的参数列表中也多了一个字符串数组envp形参,e就是environment环境变量的意思.
和基本版本的exec的区别就是:执行可执行程序时,会多传一个环境变量的字符串数组,给待执行的程序。
3、exec实战
第一种:使用execl和execv运行ls -l -a
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdlib.h>
int main(void)
{
pid_t pid = -1;
pid_t ret = -1;
int status = -1;
pid = fork();
if (pid > 0)
{
// 父进程
printf("parent, 子进程id = %d.\n", pid);
}
else if (pid == 0)
{
// 子进程
execl("/bin/ls", "ls", "-l", "-a", NULL); // execl函数
//char * const arg[] = {"ls", "-l", "-a", NULL}; //execv函数
//execv("/bin/ls", arg);
return 0;
}
else
{
perror("fork");
return -1;
}
return 0;
}
第二种:使用execl 运行自己写的程序
- hello.c
#include <stdio.h>
int main(int argc, char **argv)
{
int i = 0;
printf("argc = %d.\n", argc);
while (NULL != argv[i])
{
printf("argv[%d] = %s\n", i, argv[i]);
i++;
}
return 0;
}

- exec.c
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdlib.h>
int main(void)
{
pid_t pid = -1;
pid_t ret = -1;
int status = -1;
pid = fork();
if (pid > 0)
{
// 父进程
printf("parent, 子进程id = %d.\n", pid);
}
else if (pid == 0)
{
// 子进程
execl("hello", "aaa", "bbb", NULL); //使用execl函数
//char * const arg[] = {"aaa", "bbb", NULL}; //使用execv函数
//execv("hello", arg);
return 0;
}
else
{
perror("fork");
return -1;
}
return 0;
}
第三种:execlp和execvp
加p和不加p的区别是:
(1)不加p时需要全部路径+文件名,如果找不到就报错了。
(2)加了p之后会先帮我们到PATH所指定的路径下去找,再到当前目录找。
代码区别:
execl("/bin/ls", "ls", "-l", "-a", NULL);
execlp("ls", "ls", "-l", "-a", NULL);

第四种: execle 和 execvpe
(1)main函数的原型其实不止是int main(int argc, char **argv),而可以是int main(int argc, char **argv, char **env)第三个参数是一个字符串数组,内容是环境变量。
int main(int argc, char **argv);
int main(int argc, char **argv, char **env)
举例:
hello.c
注:
char **env : 是由系统的 父进程 传来的。
#include <stdio.h>
int main(int argc, char **argv, char **env)
{
int i = 0;
printf("参数总共有 %d \n",argc);
while(argv[i] != NULL)
{
printf("argv[%d] = %s\n",i,argv[i]);
i++;
}
i = 0;
while(env[i] != NULL)
{
printf("env[%d] = %s\n",i,env[i]);
i++;
}
return 0;
}
- exec.c
else if (pid == 0)
{
// 子进程
char * const envp[] = {
"AA = aaaa","BBs = bbb",NULL};
execle("hello", "aaa", "bbb", NULL, envp); //使用execl函数
//char * const arg[] = {"aaa", "bbb", NULL}; //使用execv函数
//execv("hello", arg);
return 0;
}

分析:环境变量的传参
(1)如果我们没有使用
execle来对他进行传递,那么默认是系统的父进程进行传递。
(2)如果我们指定,那么其环境变量,就是我们所指定的。