Neural Architecture Search: A Survey (神经网络结构搜索)
这是一篇入门综述,我们一起看看吧~
(abstract:本文主要是对于搜索策略的介绍)
搜索策略(search strategy)
包括:随机搜索、贝叶斯优化、进化算法,强化学习(RL)和基于梯度的方法。从历史来看,在几十年前很多研究者已使用进化算法探索神经网络结构以及他们的参数。Yao 有对2000年以前的 此类方法的 review。
1. 贝叶斯优化:
引领了最先进的视觉架构、在无数据增强的条件下,在CIFAR-10 数据集上有优异的成绩,并且使第一个自动调整的网络胜过了人类专家设计的网络。在Zoph 和 Le(2017)通过基于强化学习的搜索策略 在CIFAR-10上获得和Penn Treebank基准相近的表现之后,NAS成为机器学习社区的主流研究课题。虽然Zoph和Le(2017)使用大量的计算资源来实现这一结果(800个GPU持续三到四周),但在他们的工作之后,已经快速并且陆续的发布了各种各样的方法,期望降低计算成本并实现进一步的性能改进。
2.强化学习:
为了将NAS定义为强化学习(RL)问题,可以认为**神经结构的生成 是 agent(智能体) 的 action,**动作空间与搜索空间相同。agent 的reward 来自于训练后的网络结构对没见过的数据的性能(第四部分讲性能时重点讲解)。不同的强化学习方法区别在于他们如何体现 agent 的 policy 以及他们如何优化, Zoph 和 Le (2017) 使用循环神经网络 (RNN)策略按顺序采样一个字符串,该字符串反过来对神经体系结构进行编码。他们最初使用 REINFORCE 策略梯度训练此网络算法,但在后续工作中使用Proximal Policy Optimization(PPO)策略优化代替。Baker等人 使用 Q-learning来训练一个policy,该policy 依次选择一个层的类型和相应的超参数。
这些方法的另一理解是将其视为一个顺序决策过程。在这个过程中, policy 对 action 进行采样,并以此生成网络结构, 环境的 state 包括已采样的 action 以及在最后的 action 之后获得的 reward。 然而,由于在此顺序过程中没有发生与环境的交互(没有观察到外部状态,也没有中间奖励),我们更直观地将架构抽样过程解释为单个动作的顺序生成; 这将RL问题简化为无状态的 multi-armed bandit 问题。
Cai 提出了一种相似的方法,他将NAS化为顺序决策过程: 在他们的方法里, state 是当前没完全训练的网络结构, reward 是对网络结构性能的评估, action 是对 function-preserving mutations, 的一种应用,称其为 网络态(具体要看section 4), 接着是训练网络一段时间。 为了处理可变长度的网络结构, 他们使用双向LSTM 将网络结构编码成一个固定长度的表示。 基于这个编码表示, actor网络 来决定采取的 action(即加什么 cell)。上述两个部分组成了 policy, 该policy 使用 强化学习的 policy gradient 算法来端到端的训练。我们注意到 这种方法不会重复采样同一种state(即网络结构),所以 policy 需要对架构空间具有很强的泛化性。
3.进化算法
RL的一种替代方法是使用神经进化算法,**这种方法使用进化算法来优化神经网络结构。**我们所知道的第一种设计神经网络的方法可以追溯到近三十年:Miller等人使用遗传算法改进网络架构并使用反向传播来优化其权重。自那时起,许多神经进化方法使用遗传算法来优化神经结构及其权重;
4.然而,当扩展到具有数百万权重的当代神经架构用于监督学习任务时,基于SGD的权重优化方法做的比进化算法好。因此,最近的神经进化方法再次使用基于梯度的方法来优化权重,并且仅使用进化算法来优化神经结构本身。进化算法演化了一组模型,即一组(可能是训练过的)网络; 在每个进化步骤中,对来自这组模型中的至少一个模型进行采样,并作为父类通过对父类突变来生成后代。在NAS的上下文中,突变是局部的操作,例如添加或移除层,改变层的超参数,添加跳过连接,以及改变训练超参数。在对后代进行训练之后,评估它们的合适度(例如,在验证集上的表现)并将它们添加到群体中。
神经进化方法在如何对父类进行采样,以及更新种群和产生后代方面存在差异。例如,Real等人,Real等人和Liu等人使用 tournament 选择来对父类进行采样,而Elsken等人使用 inverse density 从 a multi-objective Pareto front 采样父类。Real等人从群体中移除了最坏的个体,同时Real等人发现**移除最老的个体(**这会减少贪婪(个人感觉是能减小搜索空间的样子)))是有益的,而Liu等人根本不会移除个体。为了产生后代,大多数方法随机初始化子网络,而Elsken等人采用拉马克式继承,即知识(以学习过的权重的形式)通过使用网络态射从父网络传递给其子网。Real等人还让后代继承其父母的所有参数,这些参数不受所应用的突变的影响; 虽然这种继承不是能够严格保证的,但与随机初始化相比,它也可以加速学习。此外,它们还允许改变学习速率,这可以被视为一种在NAS过程中优化学习率的方式。我们参考 Stanley et al. (2019)进行最近对神经进化方法的深入回顾。
比较
Real等人比较了 RL,进化算法和随机搜索(RS),得出的结论是RL和进化算法在最终测试精度方面表现同样出色,进化算法具有更好的性能和更小的模型。 RL和进化算法在实验中都略优于RS:在CIFAR-10上的 test error 大约是4%,而RL和进化算法大约是3.5%(在“model augmentation”之后, 深度和滤波器的数量都增加了,增强后的search space 和 没增强的 search space 相差大约2%)。Liu报告出的差异甚至更小,他的实验是RS在CIFAR-10上的test error 为3.9%,在Imagenet数据集上的TOP-1 验证error是21%,而基于进化的算法分别是3.75% 和 20.3%。
**贝叶斯优化(BO)**是用于超参数优化的最流行的方法之一,但由于经典的BO工具箱是基于高斯过程的 并且关注低维度的连续优化问题,因此它尚未被许多研究组应用于NAS。Swersky等人和Kandasamy等人为了使用经典的基于GP的BO方法,为 架构搜索空间推导了核函数,但到目前为止还没有实现新的最好的性能。相比之下,有些工作使用基于树或者随机森林的方法来在非常高维的空间中高效的搜索,并且在很多问题上取得了优异的效果(同时优化网络结构 和 他们的超参数)。虽然没有完整的比较,但初步的证据表明这些方法也可以超越进化算法。
5.网络结构搜索空间也可以使用分层的方法研究,比如:进化算法的组合、基于顺序模型的优化。Negrinho和Gordon以及Wistuba利用其搜索空间的树形结构并使用 Monte Carlo Tree Search.。 Elsken等人提出了一种简单但性能良好的爬山算法,该算法通过贪婪地向更好的架构方向移动而不需要更复杂的探索机制来发现更好的架构。
与上面的不需要梯度的优化方法不同的是,Liu 等 提出搜索空间的连续松弛来是基于梯度的优化成为可能,作者在一个特定的层不固定一个单一的操作卷积 或者 Pooling,而是计算一组操作的凸集。 具体就是:对于一个输入x,输出y 的计算公式为 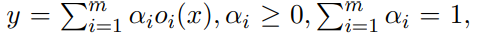
此处的凸系数αi可以有效的确定网络结构参数。然后, Liu等 通过交替的梯度下降,在训练集上训练参数,在验证集合上训练结构参数。最后,通过在每层取αi的最大值得到离散的网络结构。Shin和Ahmed也采用基于梯度的神经架构优化,但他们只考虑分别优化层的超参数或连接模式。