spring batch ItemReader详解
github地址:
https://github.com/a18792721831/studybatch.git
文章列表:
ItemReader
批处理通过Tasklet完成具体的任务,Chunk类型的Tasklet定义了标准的读、处理、写的执行步骤。ItemReader是实现读的重要组件,Spring Batch框架提供了丰富的读组件。
spring batch框架默认提供了丰富的Reader实现,如果不能满足需求可以快速方便地实现自定义的数据读取,对于已经存在的读服务,框架提供了复用现有服务的能力,避免重复开发。
spring batch框架为保证job的可靠性、稳定性,在读数据阶段提供了另外一个重要的特性是对读数据状态的保存,在spring bacth框架内置的Reader实现中通过与执行上下文进行读数据的状态交互,可以高效的保证job的重启和错误处理。
ItemReader是Step中对资源的读处理,spring batch框架已经提供了各种类型的读实现。
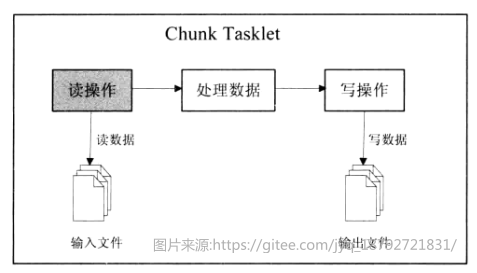
ItemReader
所有的读操作需要实现ItemReader接口。
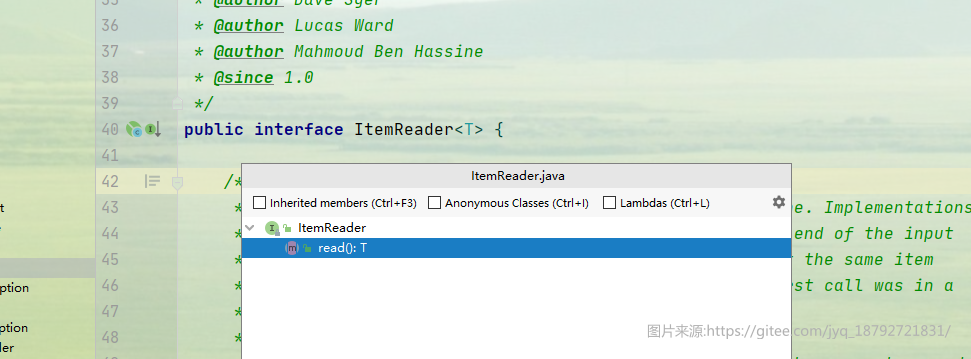
ItemStream
spring batch框架同时提供了另外一个接口ItemStream。ItemStream接口定义了读操作与执行上下文ExecutionContext交互的能力。可以将已经读的条数通过该接口存放在执行上下文ExecutionContext中(ExecutionContext中的数据在批处理comiit的时候会通过JobRepository持久化到数据库)。这样当Job发生异常,重新启动的时候,读操作可以跳过已经成功读过的数据,继续从上次出错的地方开始读。
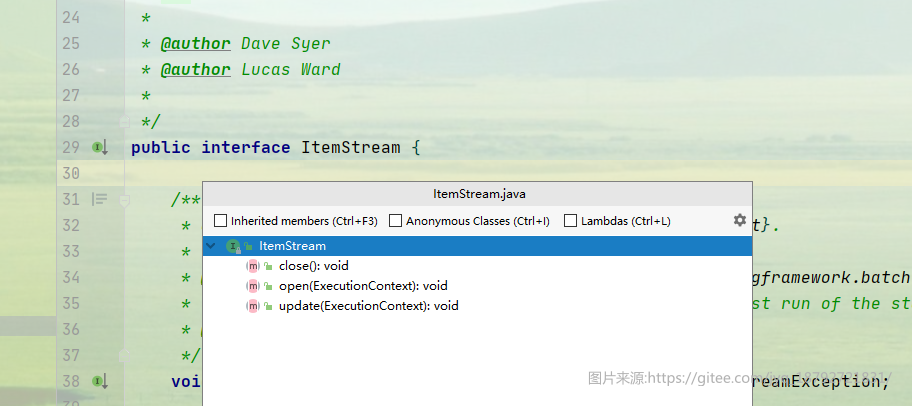
- open:根据参数executionContext打开需要读取资源的stream,可以根据持久化在上下文executionContext中的数据重新定位需要重新读取的记录处。
- update:将需要持久化的数据存放在执行上下文executionContext中
- close:关闭读取的资源
spring batch框架提供的读组件都实现了ItemStream接口。
系统读组件
| ItemReader | 说明 |
|---|---|
| ListItemReader | 读取List类型数据,只能读一次 |
| ItemReaderAdapter | ItemReader适配器,可以服用现有的读操作 |
| FlatFileItemReader | 读Flat类型文件 |
| StaxEventItemReader | 读XML类型文件 |
| JdbcCursorItemReader | 基于Jdbc游标方式读取数据库 |
| HibernateCursorItemReader | 基于Hibernate游标方式读取数据库 |
| StoredProcedureItemReader | 基于存储过程读取数据库 |
| IbatisPagingItemReader | 基于Ibaties分页读取数据库 |
| JpaPagingItemReader | 基于Jpa分页读取数据库 |
| JdbcPagingItemReader | 基于Jdbc分页读取数据库 |
| HibernatePagingItemReader | 基于Hibernate分页读取数据库 |
| JmsItemReader | 读取JMS队列 |
| IteratorItemReader | 迭代方式读组件 |
| MultiResourceItemReader | 多文件读组件 |
| MongoItemReader | 基于分布式文件存储的数据库MongoDB读组件 |
| Neo4jItemReader | 面向网络的数据库Neo4j的读组件 |
| ResourcesItemReader | 基于批量资源的读组件,每次读取返回资源对象 |
| AmqpItemReader | 读取AMQP队列组件 |
| Repository | 基于spring Data的读组件 |
读数据库
企业将数据存放在数据库中,友好的批处理框架需要友好的对数据库的读、薛支持。spring batch框架对读数据库提供了非常好的支持,包括基于JDBC和ORM(Object-Relational-Mapping)的读取方式;基于游标和分页的读取数据的ItemReader组件。
JdbcCursirItemReader
spring batch框架提供了对Jdbc读取支持的组件JdbcCursorItemReader。核心作用是将数据库中的记录转换为Java对象。通过引用PreparedStatement、RowMapper、PreparedStatementSetter等关键接口实现。在JdbcCursorItemReader将数据库记录转换为Java对象时,主要有两个过程:1.首先根据PreparedStatement从数据库中获取结果集ResultSet;其次使用RowMapper将结果集ResultSet转换为Java对象。
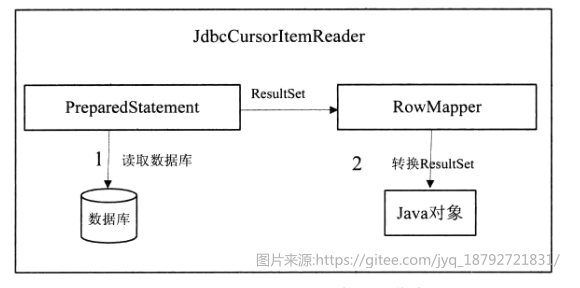
jdbcCursorItemReader的关键属性
| JdbcCursorItemReader | 类型 | 说明 |
|---|---|---|
| dataSource | DataSource | 数据源,通过该属性指定使用的数据库信息 |
| driverSupportsAbsolute | Boolean | 数据库驱动是否支持结果集的绝对定位。默认值:false |
| fetchSize | int | 设置ResultSet每次向数据库取的行数。默认值:-1 |
| ignoreWarnings | Boolean | 是否忽略SQL执行期间的警告信息,true表示忽略警告。默认值:true |
| maxRows | int | 设置结果集最大行数。默认值:-1(不限制) |
| preparedStatementSetter | PreparedStatementSetter | sql语句参数准备,可以使用springbatch提供的,也可以自己实现 |
| queryTimeout | int | 查询超时时间。默认值:-1(永不超时) |
| rowMapper | RowMapper | 将结果集ResultSet转换为指定的Pojo对象类。需要实现RowMapper接口。 |
| saveSate | Boolean | 是否将当前Reader的状态保存到jobRepository中,记录当前读取到数据库的行数。 |
| sql | String | 需要执行的sql |
| useSharedExtendedConnection | Boolean | 不同游标间是否共享数据库连接,如果共享则必须在同一个事物当中,否则使用不同的事务。默认:false |
| verifyCursorPosition | Boolean | 处理完当前行后,是否校验游标位置。默认值:true |
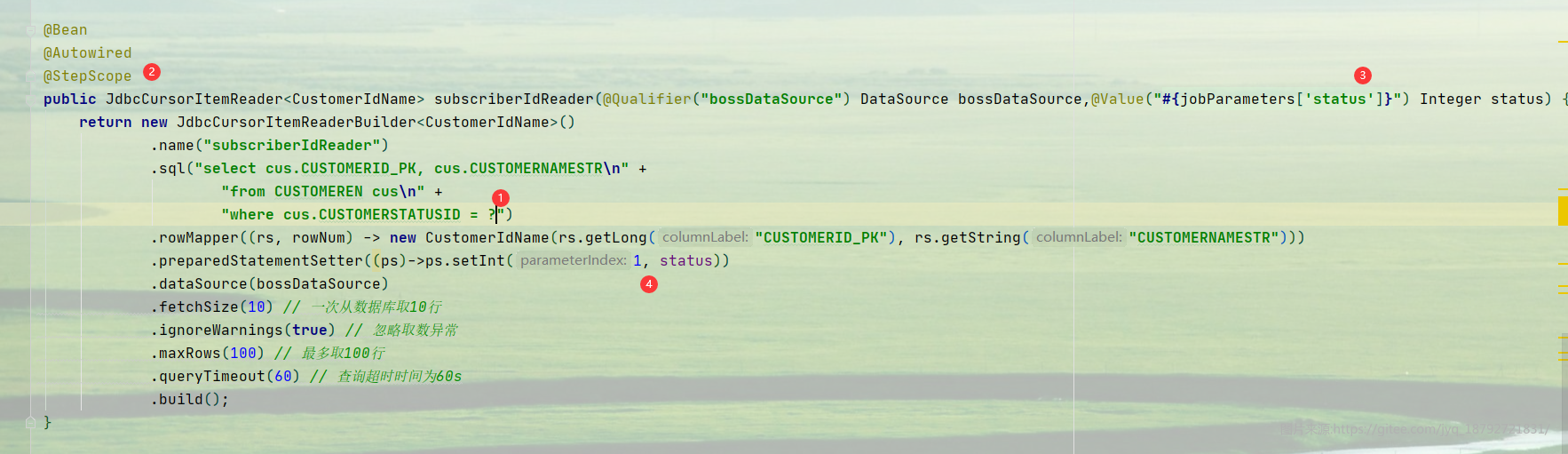
配置JdbcCursorItemReader
使用JdbcCursorItemReader至少需要配置dataSource、sql、rowMapper三个属性。因为我自己使用的是多数据源,其中mysql是spring batch元数据的存储数据库,真正读取数据使用的是oracle数据库。所以引入alibaba的durid数据库连接池,用于方便的配置多数据源。
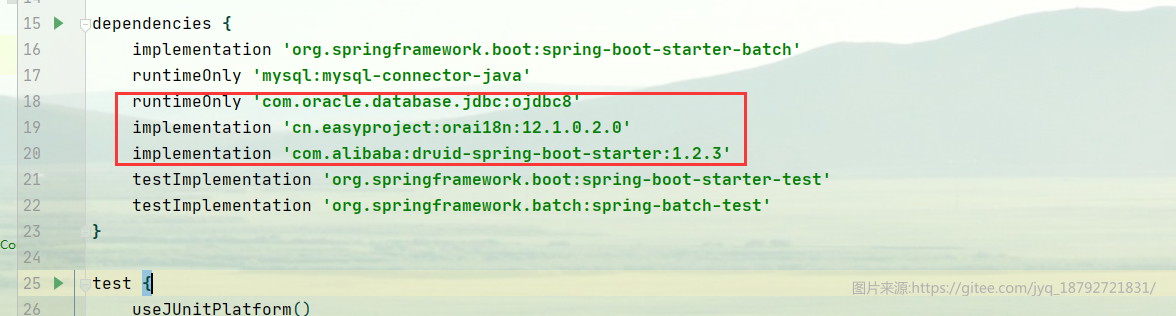
这里有一个问题,oracle数据源,如果没有引入i18n的jar,会提示空指针异常。断点调试,会给出正确的提示,数据库编码不正确,需要引入i18n。
接着需要配置多个配置
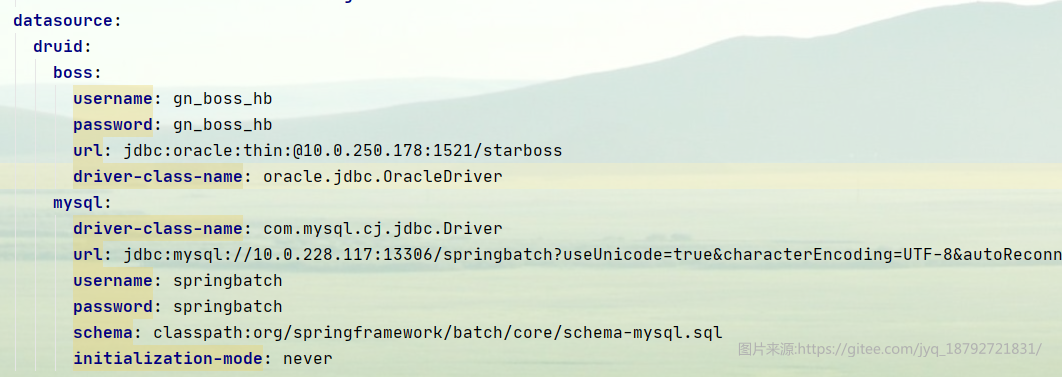
在配置类中,将数据源交给spring容器
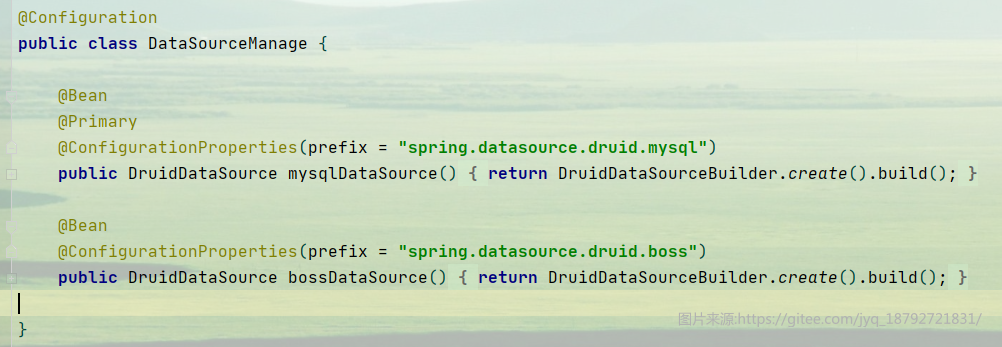
这样,我们就能愉快的使用多数据源了
在配置jobRepository的时候,需要指定mysql数据库
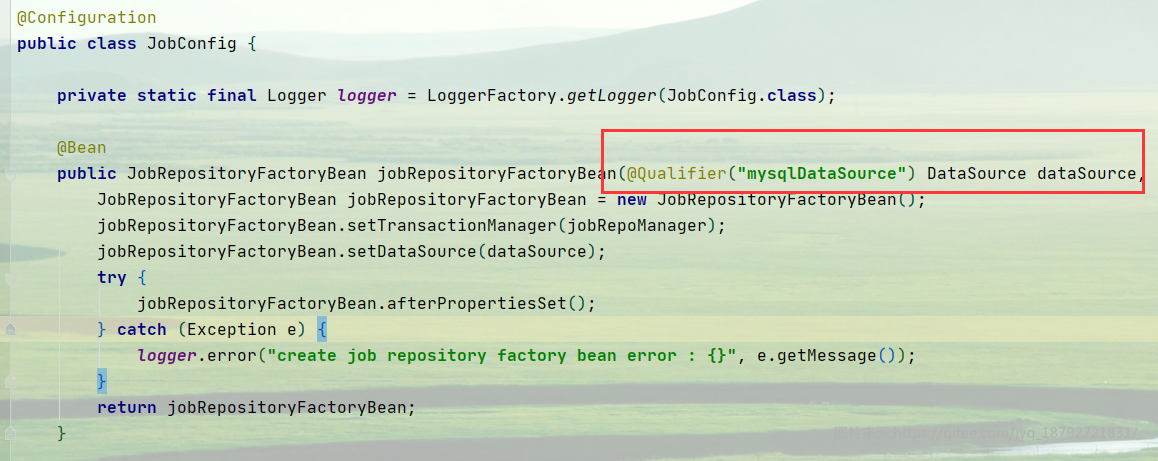
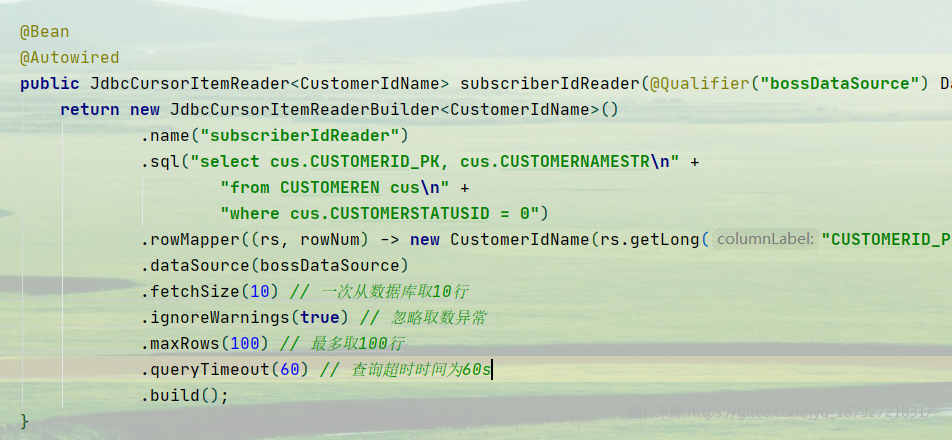
在创建ItemReader的时候,需要指定oracle数据库
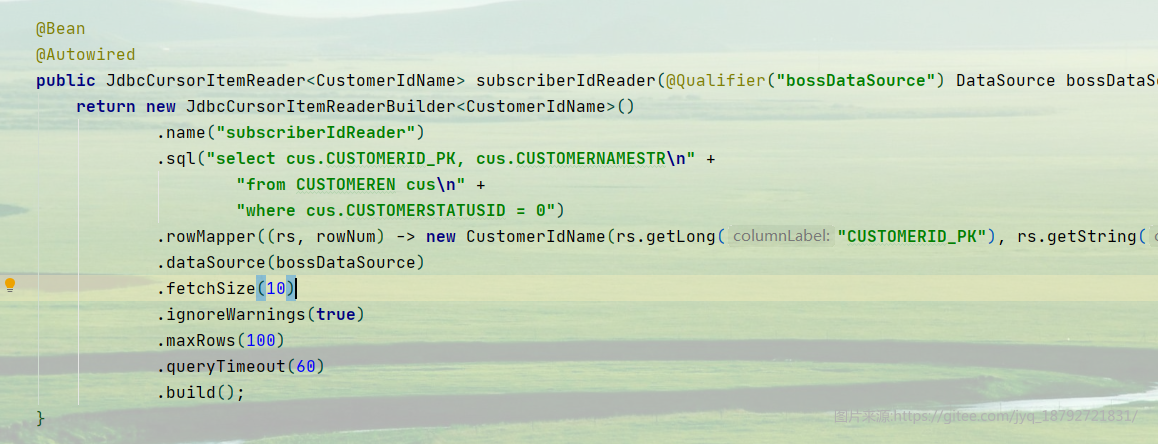
接下来就用一个小例子,体验下。
首先创建实体,我们引入lombok插件。
创建实体
创建读取器
处理器非常的简单
写入器也很简单
创建好job就可以运行了
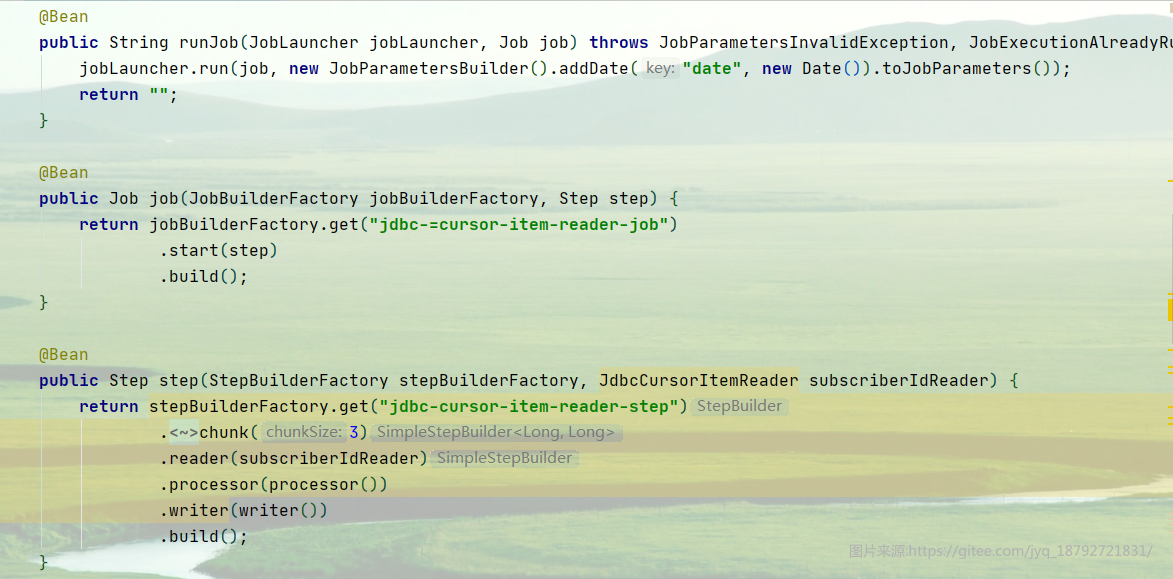
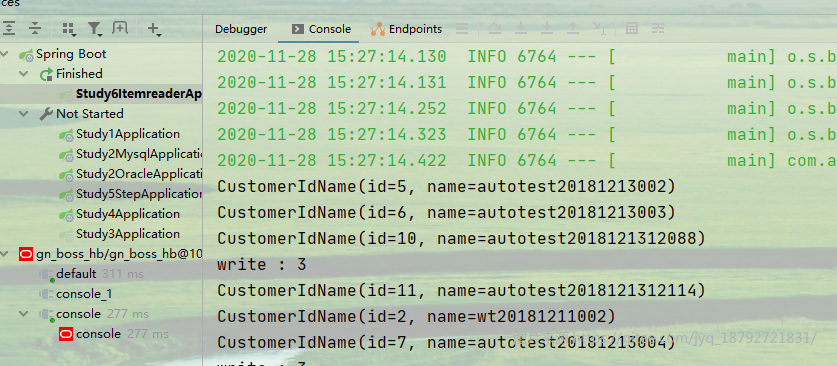
执行结果
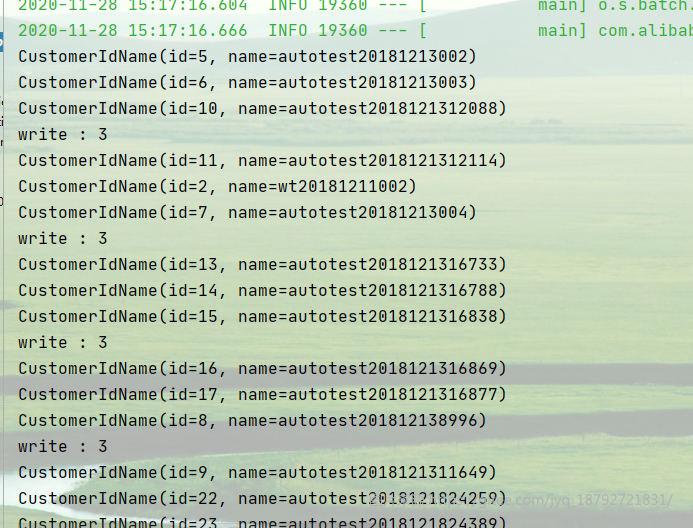
jdbc三大核心特点,我们只用了两个,分别是SQL、rowmapper。还有一个是statement.
我们修改刚才的SQL,只需要指定状态的。刚才SQL中,状态是写死的。状态通过jobParameter传入。
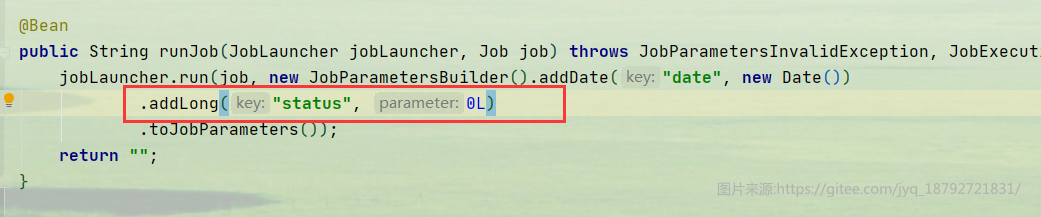
启动
我们换个状态试试
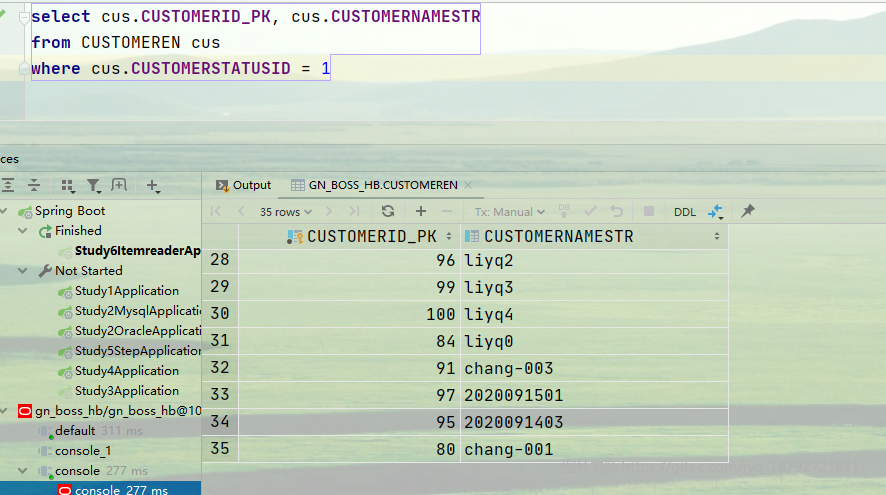
刚好35个
JdbcPagingItemReader
spring batch框架提供了对jdbc分页读取支持的组件JdbcPagingItemReader。JdbcPagingItemReader实现ItemReader接口,核心作用是将数据库中的记录通过分页的方式转换为Java对象。在JdbcPagingItemReader将数据库记录转换为Java对象时主要有两步工作:首先根据SimpleJdbcTemplate与PagingQueryProvider从数据库中根据分页的大小获取结果集ResultSet;其次使用RowMapper将结果集Result转换为Java对象。
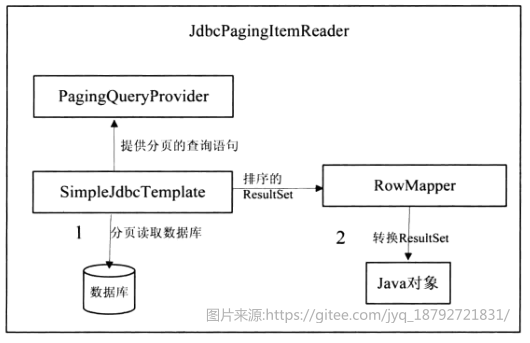
JdbcPagingItemReader关键接口
| 关键类 | 说明 |
|---|---|
| DataSource | 提供读取数据库的数据源信息 |
| SimpleJdbcTemplate | 提供标准的Spring的jdbc模板,根据分页信息查询数据库,返回排序后的结果集ResultSet |
| PagingQueryProvider | 根据分页信息生成每次需要查询的SQL语句 |
| RowMapper | 负责将结果集ResultSet转换为Java对象 |
JdbcPagingItemReader关键属性
| JdbcPagingItemReader | 类型 | 说明 |
|---|---|---|
| dataSource | DataSource | 数据源,通过该属性执行使用的数据库信息 |
| fetchSize | int | 设置ResultSet每次向数据库取的行数。默认值:-1 |
| queryProvider | PagingQueryProvider | 分页查询SQL语句生成器,负责根据分页信息生成每次需要执行的SQL语句 |
| parameterValues | Map<String,Object> | 设置定义的SQL语句中的参数 |
| rowMapper | RowMapper | 将结果集ResultSet转换为指定的Pojo对象类,需要实现RowMapper接口,有提供BeanPropertyRowMapper |
| pageSize | int | 分页大小,默认值:10 |
spring batch框架为了支持PagingQueryProvider,根据不同的数据库类型提供多种实现,为了便于开发者屏蔽不同的数据库类型,spring batch框架提供了友好的工厂类SqlPagingQueryProviderFactoryBean为不同的数据库类型提供PagingQueryProvider的实现类。
| SqlPagingQueryProviderFactoryBean | 类型 | 说明 |
|---|---|---|
| dataSource | DataSource | 数据源,通过该属性指定使用的数据库信息 |
| databaseType | String | 指定数据库的类型,如果不显示指定该类型,则自动通过dataSource属性获取数据库的信息 |
| ascending | Bioolean | 查询语句是否升序。默认值:是 |
| fromClause | String | 定义查询语句的from部分 |
| selectClause | String | 定义查询语句的select部分 |
| sortKey | String | 定义查询语句排序的关键字段 |
| whereClause | String | 定义查询语句的where字段 |
使用jdbcPagingItemReader至少需要配置dataSource,queryProvider,rowMapper三个属性。
dataSource指定访问的数据源,queryProvider用于定义分页查询的SQL语句,rowMapper用于将结果集ResultSet转换为Java业务对象。
实例
创建一个jdbcPagingItemReader

创建step和job
启动

执行结果
完整代码如下
@EnableBatchProcessing
@Configuration
public class JdbcPagingItemReaderJobConf {
@Bean
public String runJob(JobLauncher jobLauncher,Job job) throws JobParametersInvalidException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException {
jobLauncher.run(job,new JobParametersBuilder()
.addDate("date", new Date())
.addLong("status", 1L)
.toJobParameters());
return "";
}
@Bean
public Job job(JobBuilderFactory jobBuilderFactory,Step step) {
return jobBuilderFactory.get("jdbc-paging-item-reader-job")
.start(step)
.build();
}
@Bean
public Step step(StepBuilderFactory stepBuilderFactory, JdbcPagingItemReader reader) {
return stepBuilderFactory.get("jdbc-paging-item-reader-step")
.<CustomerIdName, CustomerIdName>chunk(4)
.reader(reader)
.processor((Function) item -> {
System.out.println(item);
return item;
})
.writer(items -> System.out.println("write : " + items.size()))
.build();
}
@Bean
@Autowired
@StepScope
public JdbcPagingItemReader<CustomerIdName> reader(@Qualifier("bossDataSource") DataSource dataSource, @Value("#{jobParameters['status']}") Integer status) {
return new JdbcPagingItemReaderBuilder()
.name("jdbc-paging-item-reader")
.fetchSize(10)
.maxItemCount(100)
.selectClause("CUSTOMERID_PK, CUSTOMERNAMESTR")
.fromClause("CUSTOMEREN")
.sortKeys(Map.of("CUSTOMERID_PK", Order.ASCENDING))
.whereClause("CUSTOMERSTATUSID = :status")
.beanRowMapper(CustomerIdName.class)
.parameterValues(Map.of("status", status))
.dataSource(dataSource)
.rowMapper((rs, rowNum) -> new CustomerIdName(rs.getLong("CUSTOMERID_PK"), rs.getString("CUSTOMERNAMESTR")))
.build();
}
}
JpaPagingItemReader
JpaPagingItemReader实现ItemReader接口,核心作用将数据库中的记录通过ORM的分页方式转换为Java Bean对象。
JpaPagingItemReader关键属性
| JpaPagingItemReader属性 | 类型 | 说明 |
|---|---|---|
| maxItemCount | int | 设置结果集最大行数。默认值:Integer.MAX_VALUE |
| parameterValues | String | 执行SQL的参数值 |
| queryProvider | JpaQueryProvider | 生成JPQL的查询类 |
| queryString | String | JPQL查询语句 |
| entityManagerFactory | EntityManagerFactory | 用于创建实体管理类 |
| pageSize | int | 分页大小。默认值:10 |
使用JpaPagingItemReader至少需要配置entityManageFactory,queryString两个属性。
entityManagerFactory负责创建EntityManager,后者负责完成对实体的增删改查等操作,queryString用于指定查询的JPQL语句。
在上述例子的基础上,首先增加Jpa的starter.
接着修改实体

配置Jpa的EntityManageFactory

配置reader
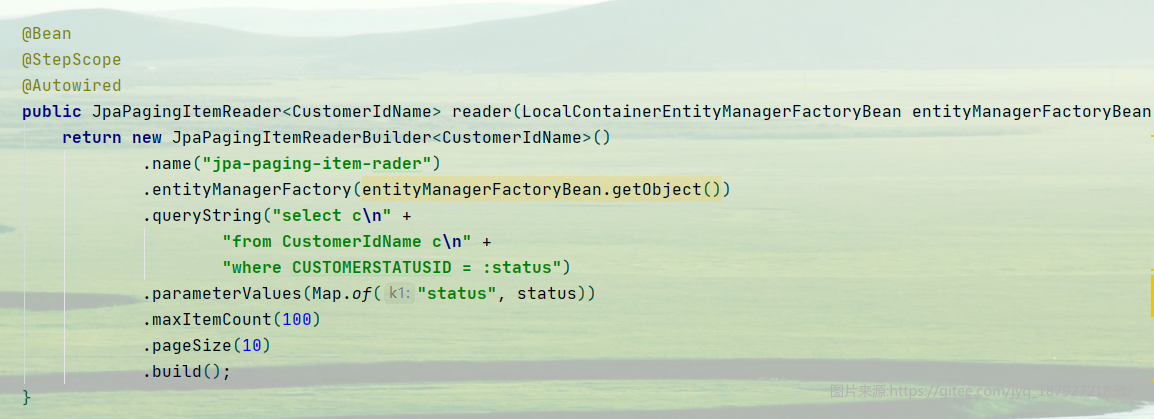
全部代码
@EnableBatchProcessing
@Configuration
public class JpaPagingItemReaderJobConf {
@Bean
public String runJob(JobLauncher jobLauncher, Job job) throws JobParametersInvalidException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException {
jobLauncher.run(job, new JobParametersBuilder()
.addDate("date", new Date())
.addLong("status", 0L)
.toJobParameters());
return "";
}
@Bean
public Job job(JobBuilderFactory jobBuilderFactory, Step step) {
return jobBuilderFactory.get("jpa-paging-item-reader-job")
.start(step)
.build();
}
@Bean
public Step step(StepBuilderFactory stepBuilderFactory, JpaPagingItemReader reader) {
return stepBuilderFactory.get("jpa-paging-item-reader-step")
.<CustomerIdName, CustomerIdName>chunk(5)
.reader(reader)
.processor((Function) item -> {
System.out.println(item);
return item;
})
.writer(items -> System.out.println("writer : " + items.size()))
.build();
}
@Bean
@StepScope
@Autowired
public JpaPagingItemReader<CustomerIdName> reader(LocalContainerEntityManagerFactoryBean entityManagerFactoryBean, @Value("#{jobParameters['status']}") Integer status) {
return new JpaPagingItemReaderBuilder<CustomerIdName>()
.name("jpa-paging-item-rader")
.entityManagerFactory(entityManagerFactoryBean.getObject())
.queryString("select c\n" +
"from CustomerIdName c\n" +
"where CUSTOMERSTATUSID = :status")
.parameterValues(Map.of("status", status))
.maxItemCount(100)
.pageSize(10)
.build();
}
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactoryBean(@Qualifier("bossDataSource") DataSource bossDataSource, EntityManagerFactoryBuilder builder) {
return builder
.dataSource(bossDataSource)
.packages(Study6ItemreaderApplication.class)
.build();
}
}
执行结果
修改参数,重新执行
和上面的执行结果没有任何相同的记录。
JpaCursorItemReader
使用JpaCursorItemReader至少需要配置entityManageFactory,queryString两个属性。
entityManagerFactory负责创建EntityManager,后者负责完成对实体的增删改查等操作,queryString用于指定查询的JPQL语句。
比如:
@EnableBatchProcessing
@Configuration
public class JpaCursorItemReaderJobConf {
@Bean
public String runJob(JobLauncher jobLauncher, Job job) throws JobParametersInvalidException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException {
jobLauncher.run(job, new JobParametersBuilder()
.addLong("status", 0L)
.addDate("date", new Date())
.toJobParameters());
return "";
}
@Bean
public Job job(JobBuilderFactory jobBuilderFactory, Step step) {
return jobBuilderFactory.get("jpa-cursor-item-reader-job")
.start(step)
.build();
}
@Bean
public Step step(StepBuilderFactory stepBuilderFactory, JpaCursorItemReader reader) {
return stepBuilderFactory.get("jpa-cursor-item-reader-step")
.<CustomerIdName, CustomerIdName>chunk(2)
.reader(reader)
.processor((Function<CustomerIdName, CustomerIdName>) item -> {
System.out.println(item);
return item;
})
.writer(items -> System.out.println("writer : " + items.size()))
.build();
}
@Bean
@StepScope
public JpaCursorItemReader<CustomerIdName> reader(LocalContainerEntityManagerFactoryBean entityManagerFactoryBean, @Value("#{jobParameters['status']}") Integer status) {
return new JpaCursorItemReaderBuilder<CustomerIdName>()
.name("jpa-cursor-item-reader")
.entityManagerFactory(entityManagerFactoryBean.getObject())
.queryString("select c\n" +
"from CustomerIdName c\n" +
"where CUSTOMERSTATUSID = :status")
.parameterValues(Map.of("status", status))
.maxItemCount(100)
.build();
}
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactoryBean(@Qualifier("bossDataSource") DataSource bossDataSource, EntityManagerFactoryBuilder builder) {
return builder
.dataSource(bossDataSource)
.packages(Study6ItemreaderApplication.class)
.build();
}
}
执行结果
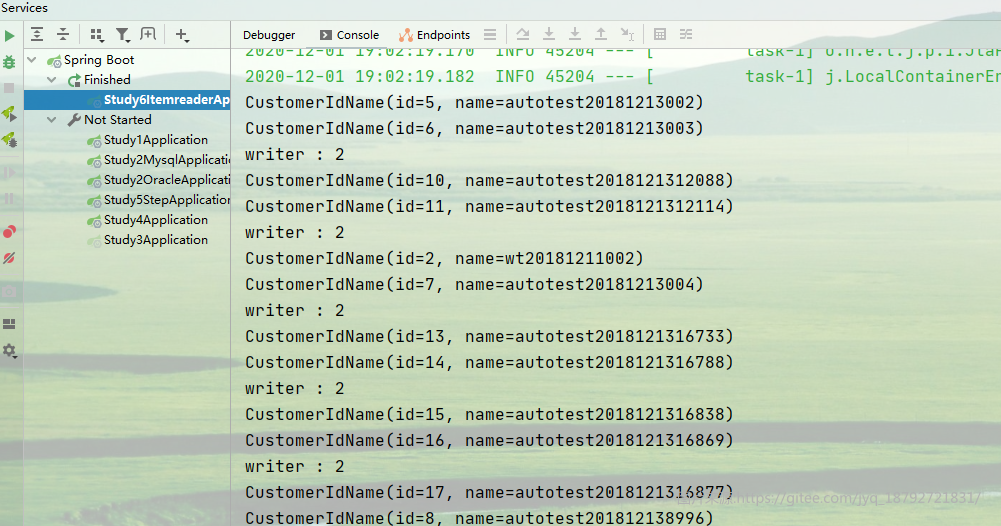
MyBatisCursorItemReader
比起jpa,在查询方面,可能mybatis的xml能更加直观的展示原生的查询SQL。所以,我个人认为,spring batch的reader里面,最好用,最直观,效率最高的可能是mybatis的ItemReader.
MyBatisCursorItemReader和前面的JpaCursorItemReader类似,也需要指定数据源和SQL。在MyBatis中配置的是SqlSessionFactory.
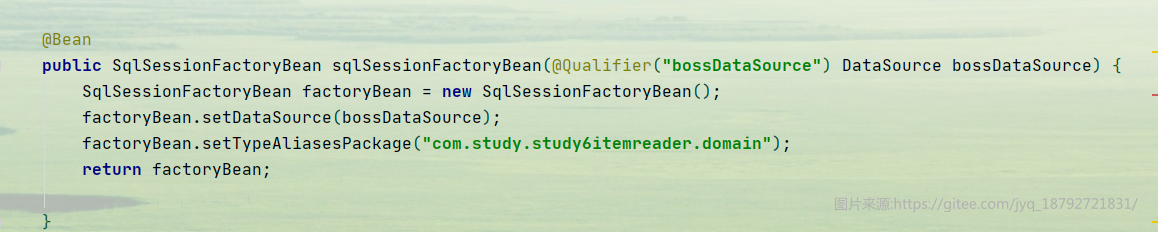
这里我们创建了MyBatis的创建信息类,接着创建SqlSessionFactory即可。
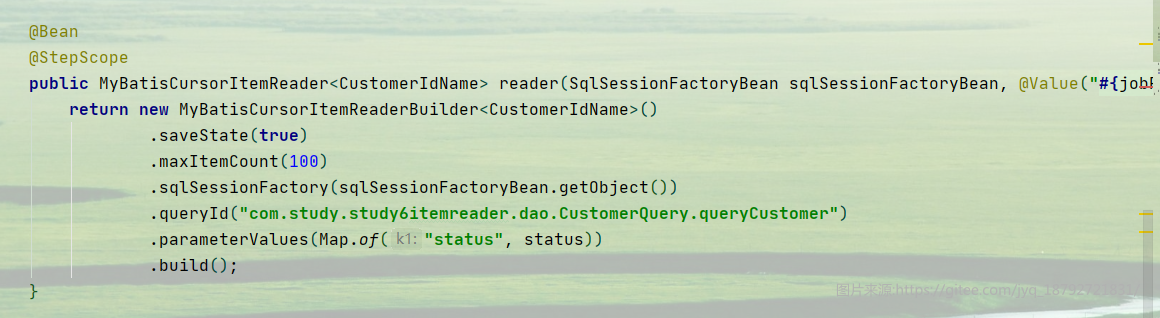
这里面需要指定queryId,这个queryId就是mybatis中指定的id
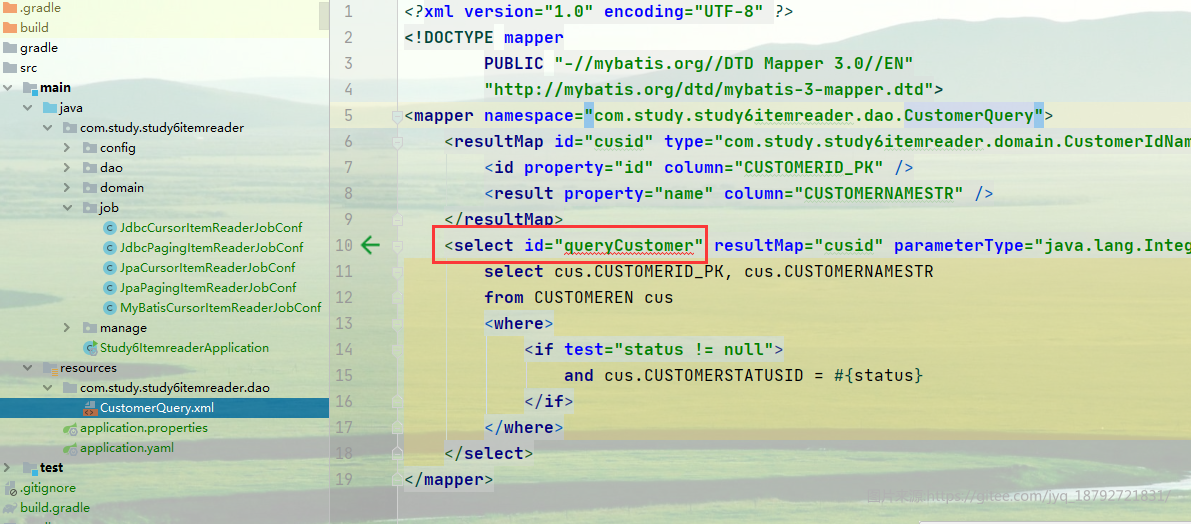
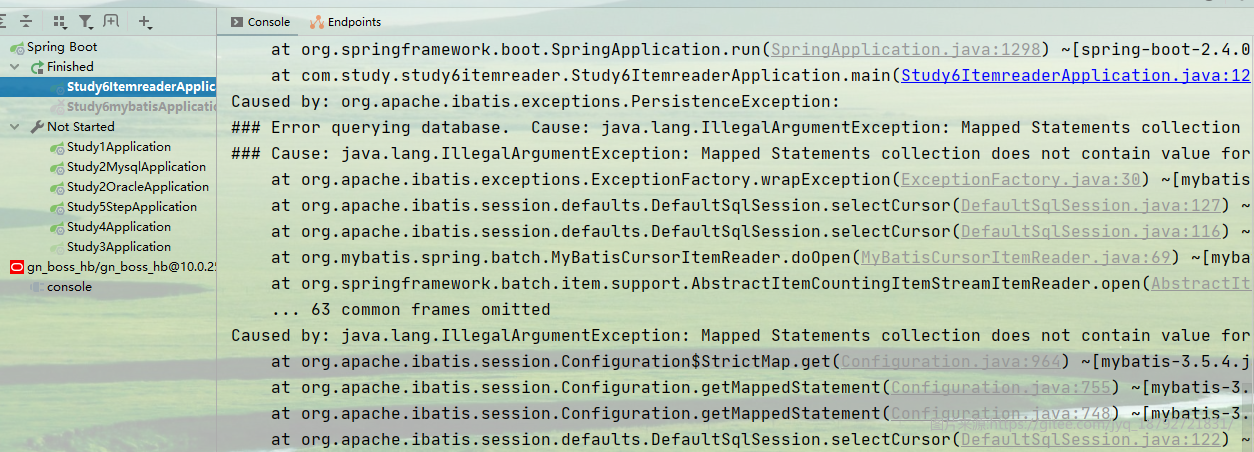
这里的id支持长名字,也支持短名字。
在使用的时候,需要特别注意:注解解析先于MyBatis的Mapper解析,因此,如果直接用,会出现找不到匹配的编译的SQL异常。
Mapped Statements collection does not contain value for
完整的代码:
@EnableBatchProcessing
@Configuration
public class MyBatisCursorItemReaderJobConf {
@Bean
public String runJob(JobLauncher jobLauncher, Job job,CustomerQuery customerQuery) throws JobParametersInvalidException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException {
jobLauncher.run(job, new JobParametersBuilder()
.addLong("status", 0L)
.addDate("date", new Date())
.toJobParameters());
return "";
}
@Bean
public Job job(JobBuilderFactory jobBuilderFactory, Step step) {
return jobBuilderFactory.get("mybatis-cursor-item-reader-job")
.start(step)
.build();
}
@Bean
public Step step(StepBuilderFactory stepBuilderFactory, MyBatisCursorItemReader<CustomerIdName> reader) {
return stepBuilderFactory.get("mybatis-curosr-item-reader")
.<CustomerIdName, CustomerIdName>chunk(6)
.reader(reader)
.processor((Function<CustomerIdName, CustomerIdName>) item -> {
System.out.println(item);
return item;
})
.writer(items -> System.out.println("writer : " + items.size()))
.build();
}
@Bean
@StepScope
public MyBatisCursorItemReader<CustomerIdName> reader(SqlSessionFactoryBean sqlSessionFactoryBean, @Value("#{jobParameters['status']}") Integer status) throws Exception {
return new MyBatisCursorItemReaderBuilder<CustomerIdName>()
.saveState(true)
.maxItemCount(100)
.sqlSessionFactory(sqlSessionFactoryBean.getObject())
.queryId("com.study.study6itemreader.dao.CustomerQuery.queryCustomer")
.parameterValues(Map.of("status", status))
.build();
}
@Bean
public SqlSessionFactoryBean sqlSessionFactoryBean(@Qualifier("bossDataSource") DataSource bossDataSource) {
SqlSessionFactoryBean factoryBean = new SqlSessionFactoryBean();
factoryBean.setDataSource(bossDataSource);
factoryBean.setTypeAliasesPackage("com.study.study6itemreader.domain");
return factoryBean;
}
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.study.study6itemreader.dao.CustomerQuery">
<resultMap id="cusid" type="com.study.study6itemreader.domain.CustomerIdName">
<id property="id" column="CUSTOMERID_PK" />
<result property="name" column="CUSTOMERNAMESTR" />
</resultMap>
<select id="queryCustomer" resultMap="cusid" parameterType="java.lang.Integer">
select cus.CUSTOMERID_PK, cus.CUSTOMERNAMESTR
from CUSTOMEREN cus
<where>
<if test="status != null">
and cus.CUSTOMERSTATUSID = #{status}
</if>
</where>
</select>
</mapper>
public interface CustomerQuery {
List<CustomerIdName> queryCustomer(Integer status);
}
别忘记了MapperScan
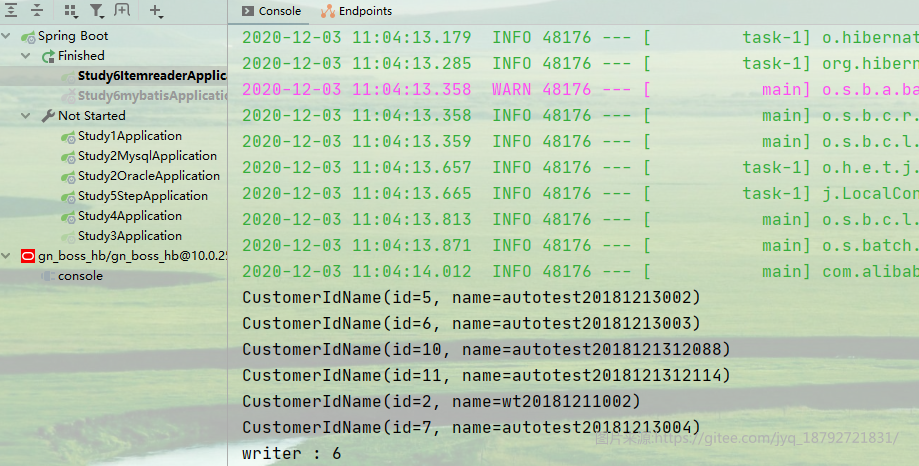
执行结果
MyBatisPagingItemReader
MyBatisPagingItemReader和MyBatisCursorItemReader非常类似,区别在spring batch如何从数据库取数。
在MyBatisCursorItemReader中,需要让oracle将全部的数据准备好,然后使用游标,依次取数,通过fetchSize控制一次取多少数据。
而MyBatisPagingItemReader,则是需要让oracle取出指定的数据即可,然后按页返回数据给spring batch。
理论上说,如果数据量非常大,那么使用分页可能更快。
如果数据量不是非常大,使用游标可能快。
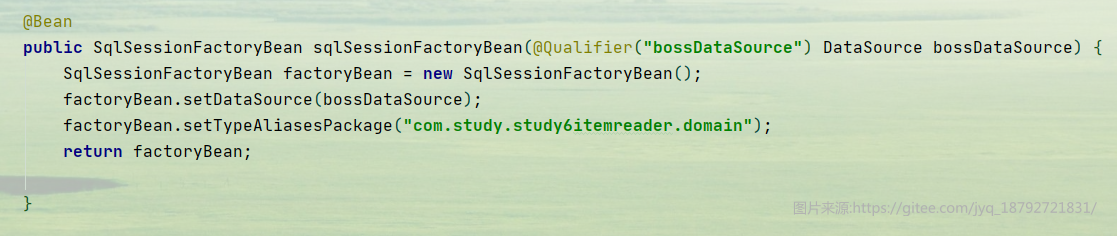
配置SqlSessionFactoryBean
指定查询SQL的queryId,这里使用短名字
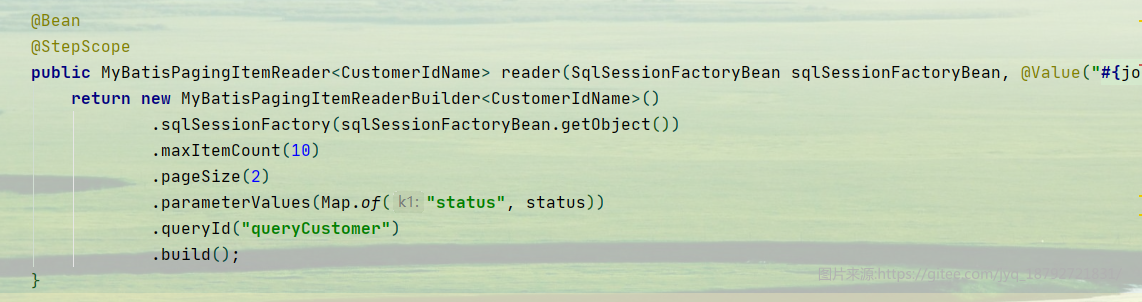
接着就是相同的配置Step和Job并启动,需要注意的是,启动之前需要保证Mapper已经被解析
完整的代码
@EnableBatchProcessing
@Configuration
public class MyBatisPagingItemReaderJobConf {
@Bean
public String runJob(JobLauncher jobLauncher, Job job, CustomerQuery customerQuery) throws JobParametersInvalidException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException {
jobLauncher.run(job, new JobParametersBuilder()
.addDate("date", new Date())
.addLong("status", 1L)
.toJobParameters());
return "";
}
@Bean
public Job job(JobBuilderFactory jobBuilderFactory, Step step) {
return jobBuilderFactory.get("mybatis-paging-item-reader-job")
.start(step)
.build();
}
@Bean
public Step step(StepBuilderFactory stepBuilderFactory, MyBatisPagingItemReader<CustomerIdName> reader) {
return stepBuilderFactory.get("mybatis-paging-item-reader-step")
.<CustomerIdName, CustomerIdName>chunk(3)
.reader(reader)
.processor((Function<CustomerIdName, CustomerIdName>) item -> {
System.out.println(item);
return item;
})
.writer(items -> System.out.println("writer : " + items.size()))
.build();
}
@Bean
@StepScope
public MyBatisPagingItemReader<CustomerIdName> reader(SqlSessionFactoryBean sqlSessionFactoryBean, @Value("#{jobParameters['status']}") Integer status) throws Exception {
return new MyBatisPagingItemReaderBuilder<CustomerIdName>()
.sqlSessionFactory(sqlSessionFactoryBean.getObject())
.maxItemCount(10)
.pageSize(2)
.parameterValues(Map.of("status", status))
.queryId("queryCustomer")
.build();
}
@Bean
public SqlSessionFactoryBean sqlSessionFactoryBean(@Qualifier("bossDataSource") DataSource bossDataSource) {
SqlSessionFactoryBean factoryBean = new SqlSessionFactoryBean();
factoryBean.setDataSource(bossDataSource);
factoryBean.setTypeAliasesPackage("com.study.study6itemreader.domain");
return factoryBean;
}
}
执行结果
ItemReader类图

服务复用
复用现有的企业资产和服务是提高企业应用开发的快捷手段,spring batch框架的读组件提供了复用现有服务的能力,利用spring batch的框架提供的ItemReaderAdapter可以方便的复用业务服务、spring bean、ejb或者其他远程服务。
ItemReaderAdapter结构
ItemReaderApapter持有服务对象,并调用指定的操作来完成ItemReader中定义的read功能。需要注意的是:ItemReader的read操作需要每次返回一条对象,当没有数据可以读取时,需要返回null。但是现有的服务通常返回一个对象的数组或者List列表;因此现有的服务通常不能直接被ItemReaderApapter直接使用,需要在ItemReaderAdapter和现有的服务之间在增加一个ServiceAdapter来完成适配工作。
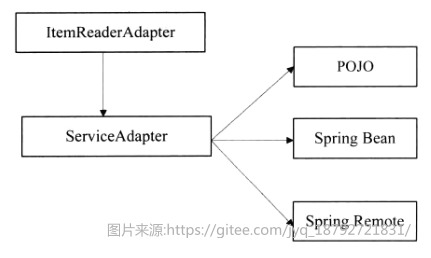
在配置ItemReaderApapter时,只需要指定三个属性即可:targetObject,targetMethod和Arguments。其中Arguments可选,其他必选。
首先我们创建一个service,用于模拟我们现有的服务
@Service
@Configuration
public class CustomerService {
@Autowired
private CustomerQuery customerQuery;
public List<CustomerIdName> getAll() {
List<CustomerIdName> result = customerQuery.queryCustomer(0);
result.addAll(customerQuery.queryCustomer(1));
return result;
}
@Bean
public SqlSessionFactory sqlSessionFactoryBean(@Qualifier("bossDataSource") DataSource bossDataSource) throws Exception {
SqlSessionFactoryBean factoryBean = new SqlSessionFactoryBean();
factoryBean.setDataSource(bossDataSource);
factoryBean.setTypeAliasesPackage("com.study.study6itemreader.domain");
return factoryBean.getObject();
}
}
因为用到了MyBatis的查询,所以需要向spring容器中注入SqlSessionFactory。
并且暴露了一个查询全部数据的服务。
接着创建Adapter
@Component
public class CustomerQueryAdapter {
private List<CustomerIdName> data = new LinkedList<>();
@Autowired
private CustomerService customerService;
@PostConstruct
public void init() {
data.addAll(customerService.getAll());
}
public CustomerIdName getCustomer() {
CustomerIdName result = null;
if (!data.isEmpty()) {
result = data.remove(0);
}
System.out.print("reader : " + result);
return result;
}
}
我们创建的Adapter中持有全部的数据,在bean被创建后,初始化进去全部的数据。
而且提供了一个方法,用于从全部数据中取出1条数据。
如果数据被取完了,那么返回空。
接着就是创建reader了
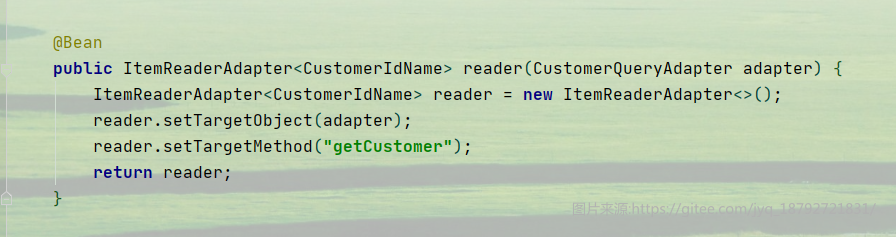
因为我们的Adapter方法中没有参数,所以,就不设置参数,只需要设置目标对象和目标方法就行了。
完整的代码如下
@EnableBatchProcessing
@Configuration
public class ItemReaderAdapterJobConf {
@Bean
public String runJob(JobLauncher jobLauncher, Job job) throws JobParametersInvalidException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException {
jobLauncher.run(job, new JobParametersBuilder()
.addDate("date", new Date())
.toJobParameters());
return "";
}
@Bean
public Job job(JobBuilderFactory jobBuilderFactory, Step step) {
return jobBuilderFactory.get("item-reader-adapter-job")
.start(step)
.build();
}
@Bean
public Step step(StepBuilderFactory stepBuilderFactory, ItemReaderAdapter<CustomerIdName> reader) {
return stepBuilderFactory.get("item-reader-adapter-step")
.<CustomerIdName, CustomerIdName>chunk(4)
.reader(reader)
.processor((Function<CustomerIdName, CustomerIdName>) item -> {
System.out.println(item);
return item;
})
.writer(items -> System.out.println("writer : " + items.size()))
.build();
}
@Bean
public ItemReaderAdapter<CustomerIdName> reader(CustomerQueryAdapter adapter) {
ItemReaderAdapter<CustomerIdName> reader = new ItemReaderAdapter<>();
reader.setTargetObject(adapter);
reader.setTargetMethod("getCustomer");
return reader;
}
}
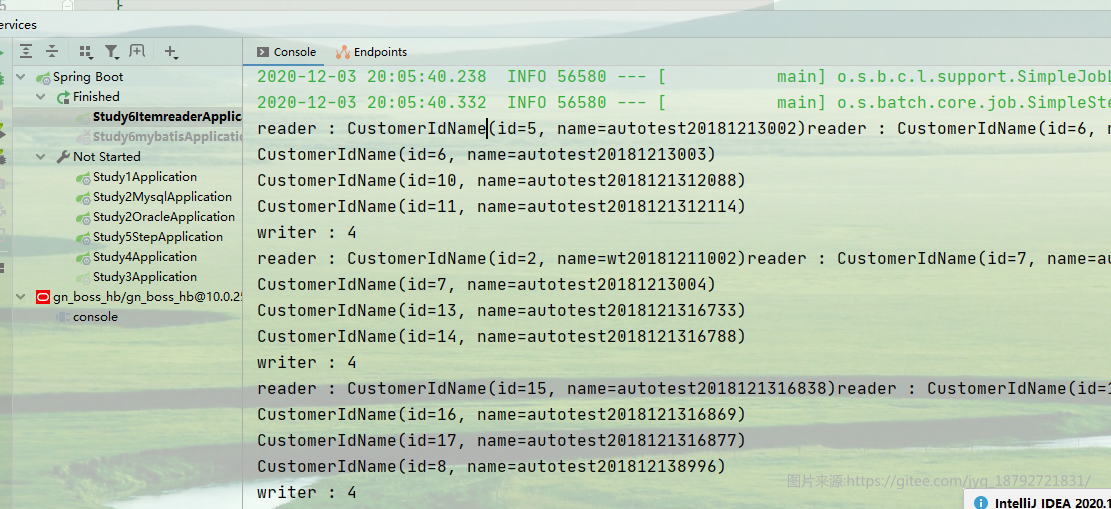
执行结果
自定义ItemReader
spring batch框架提供丰富的ItemReader组件,当这些默认的系统组件不能满足需求时,我们可以自己实现ItemReader接口,完成需要的业务操作。自定义实现ItemReader非常容易,只需要实现接口ItemReader。只实现ItemReader接口的读不支持重启,实现了ItemStream支持重启。
不可重启ItemReader
直接实现ItemReader接口即可
@Component
public class MyItemReader implements ItemReader<Integer> {
private Integer number = 0;
@Override
public Integer read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException {
number++;
if (number <= 20) {
System.out.println("reader : " + number);
return number;
}
throw new Exception(" more than 20 ");
}
}
在reader中,如果number大于20,那么抛出异常。抛出异常就是为了重启。验证我们的ItemReader是不可重启的。
接着使用这个自定义的不可重启的reader
@EnableBatchProcessing
@Configuration
public class MyItemReaderJobConf {
@Bean
public String runJob(JobLauncher jobLauncher, Job job) throws JobParametersInvalidException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException {
jobLauncher.run(job, new JobParametersBuilder()
.toJobParameters());
return "";
}
@Bean
public Job job(JobBuilderFactory jobBuilderFactory, Step step) {
return jobBuilderFactory.get("my-item-reader-job")
.start(step)
.build();
}
@Bean
public Step step(StepBuilderFactory stepBuilderFactory, MyItemReader myItemReader) {
return stepBuilderFactory.get("my-item-reader-step")
.<Integer, Integer>chunk(3)
.reader(myItemReader)
.processor((Function<Integer, Integer>) item -> {
System.out.println("process : " + item);
return item;
})
.writer(items -> System.out.println("writer : " + items.size()))
.build();
}
}
执行就会出现异常
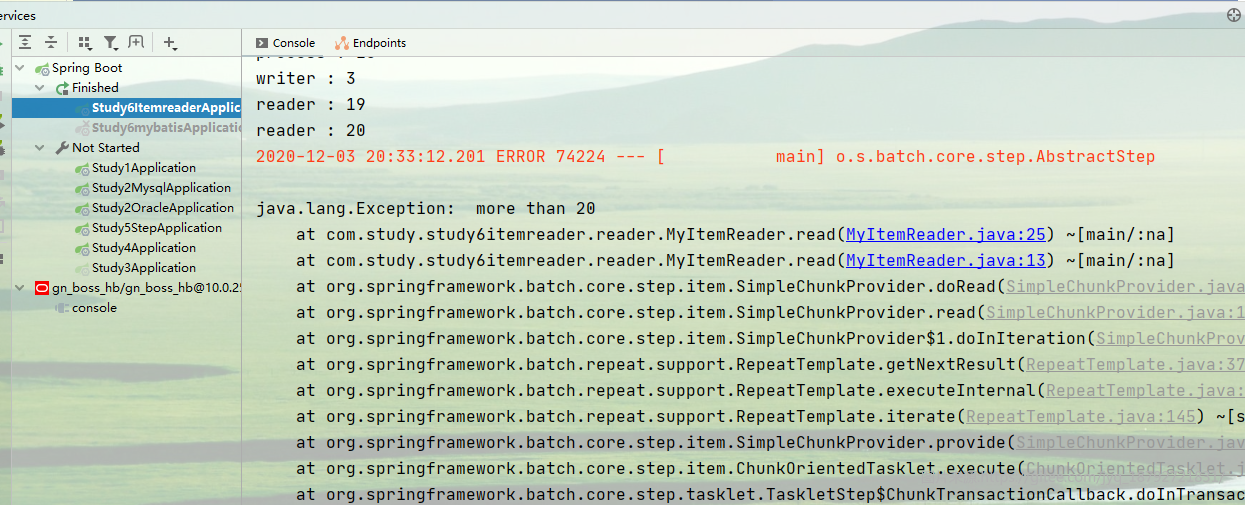
接着重启
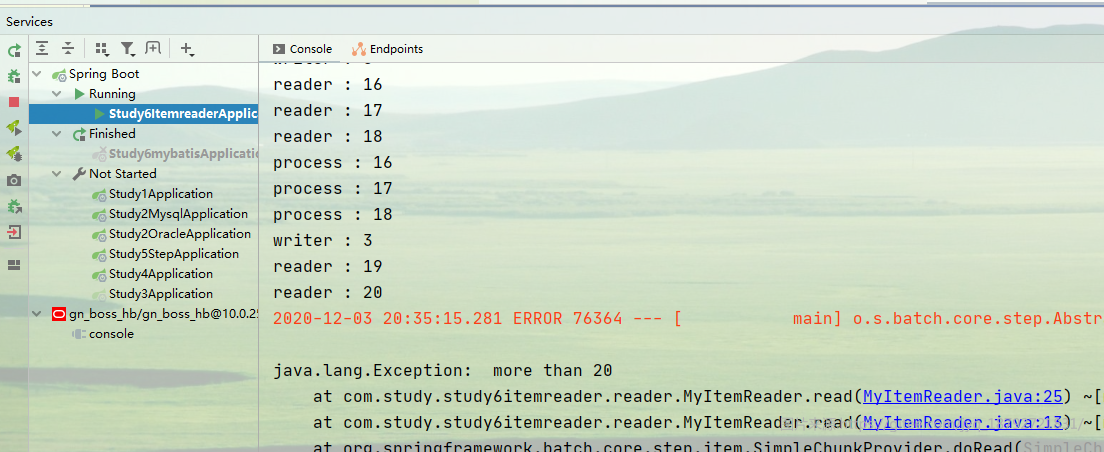
发现还是从1开始的,并不像spring btach提供的组件一样,失败了,重新启动,会从失败的地方继续执行。
换句话说,只实现了ItemReader接口,是不会将当前的数据记录到数据库,如果Job存在异常,导致失败,下次重新执行会从上次失败的记录继续执行。
可重启ItemReader
spring batch框架对job提供了可重启的能力,所有spring batch框架中提供的ItemReader组件均支持可重启的能力。为了支持ItemReader的可重启能力,框架定义了接口ItemStream,所有实现接口ItemStream的组件均支持可重启的能力。
首先我们实现ItemReader和ItemStream接口,创建自己的可重启的ItemReader
@Component
public class MyRestartItemReader implements ItemReader<Integer>, ItemStream {
private static final String CURRENT = "current";
private Integer current = 0;
@Override
public Integer read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException {
System.out.println("reader : " + current);
if (current > 20) {
throw new Exception("more than 20 ");
}
return current++;
}
@Override
public void open(ExecutionContext executionContext) throws ItemStreamException {
if (executionContext.containsKey(CURRENT)) {
current = executionContext.getInt(CURRENT, 0);
}
}
@Override
public void update(ExecutionContext executionContext) throws ItemStreamException {
executionContext.putInt(CURRENT, current);
}
@Override
public void close() throws ItemStreamException {
}
}
我们在ExecutionContext中保存当前的状态或者是记录号,等下一次重启时,调用open方法,从Context中读取上次的记录号,或者是状态,然后,将上次的状态恢复到本次执行的变量current中。
在spring batch调用reader读取数据时,接着从上次读取的记录继续执行。
我们在真正的一个job中使用这个自定义的可重启的ItemReader
@EnableBatchProcessing
@Configuration
public class MyRestartItemReaderJobConf {
@Bean
public String runJob(JobLauncher jobLauncher, Job job) throws JobParametersInvalidException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException {
jobLauncher.run(job, new JobParametersBuilder().addLong("id", 0L).toJobParameters());
return "";
}
@Bean
public Job job(JobBuilderFactory jobBuilderFactory,Step step) {
return jobBuilderFactory.get("my-restart-item-reader-job")
.start(step)
.build();
}
@Bean
public Step step(StepBuilderFactory stepBuilderFactory, MyRestartItemReader reader) {
return stepBuilderFactory.get("my-restart-item-reader-step")
.<Integer,Integer>chunk(3)
.reader(reader)
.processor((Function<Integer, Integer>)item->{
System.out.println("process : " + item);
return item;
})
.writer(items -> System.out.println("writer : " + items.size()))
.build();
}
}
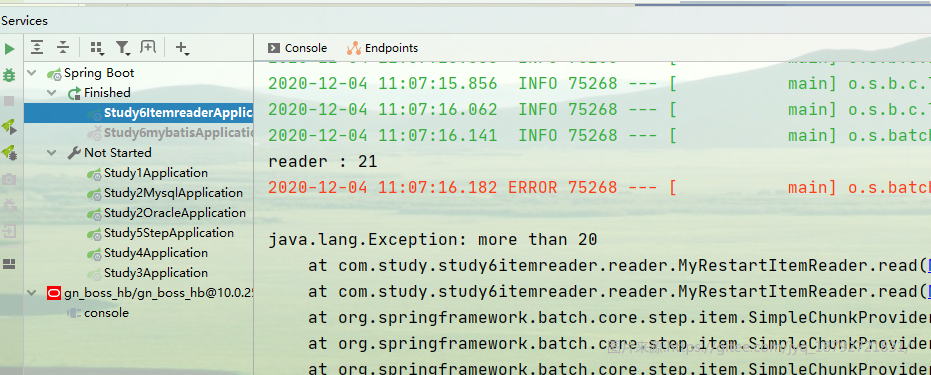
第一次启动,当读取到21的时候,reader会抛出异常,此时整个Job失败。
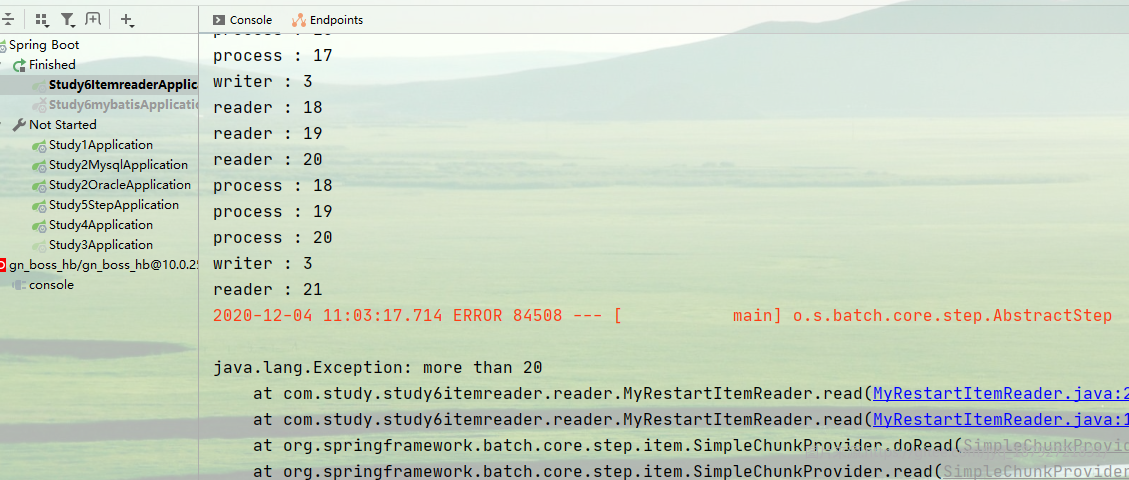
在不修改任何参数的情况下,重启。此时reader从Context中读取到上次已经读取到20了,重启后,会继续从21开始。
拦截器
spring batch框架在ItemReader执行阶段提供了烂机器,使得在ItemReader执行前后能够加入自定义的业务逻辑。ItemReader执行阶段拦截接口:ItemReaderListener
接口

实现接口即可
@Component
public class MyReaderListener implements ItemReadListener {
private static final String name = "MyReaderListener";
@Override
public void beforeRead() {
System.out.println(name + " before read ");
}
@Override
public void afterRead(Object item) {
System.out.println(name + " after read : " + item);
}
@Override
public void onReadError(Exception ex) {
System.out.println(name + " exception read : " + ex.getMessage());
}
}
然后使用
@EnableBatchProcessing
@Configuration
public class MyReaderListenerJobConf {
@Bean
public String runJob(JobLauncher jobLauncher, Job job) throws JobParametersInvalidException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException {
jobLauncher.run(job, new JobParametersBuilder()
.addDate("date", new Date())
.toJobParameters());
return "";
}
@Bean
public Job job(JobBuilderFactory jobBuilderFactory, Step step) {
return jobBuilderFactory.get("my-reader-listener-job")
.start(step)
.build();
}
@Bean
public Step step(StepBuilderFactory stepBuilderFactory) {
AtomicInteger atomicInteger = new AtomicInteger();
return stepBuilderFactory.get("my-reader-listener-step")
.<Integer, Integer>chunk(3)
.reader(() -> atomicInteger.get() > 20 ? null : atomicInteger.getAndIncrement())
.processor((Function<Integer, Integer>) item -> {
System.out.println("process : " + item);
return item;
})
.writer(items -> System.out.println("writer : " + items.size()))
.listener(new MyReaderListener())
.build();
}
}
执行结果
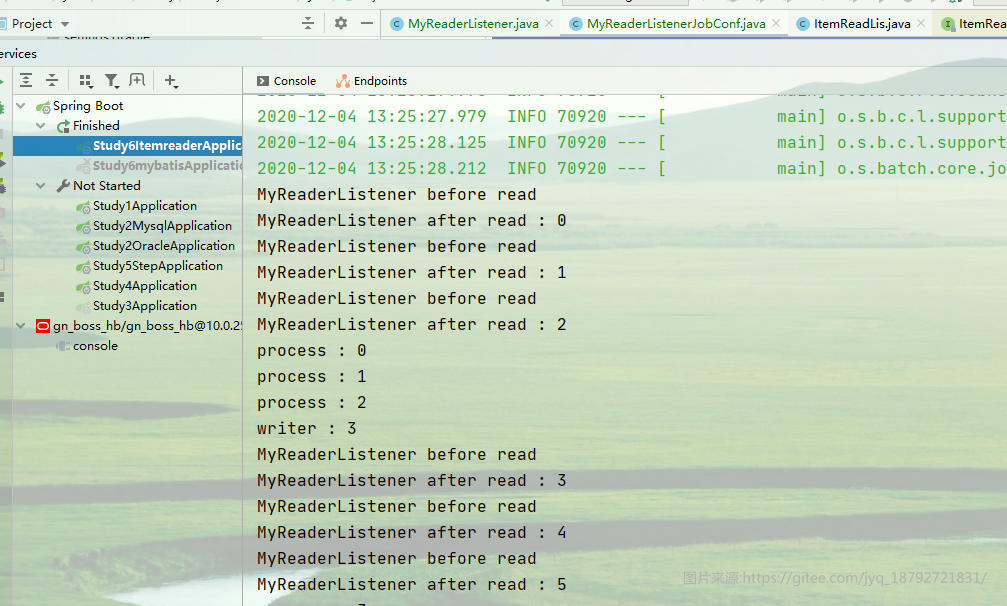
异常
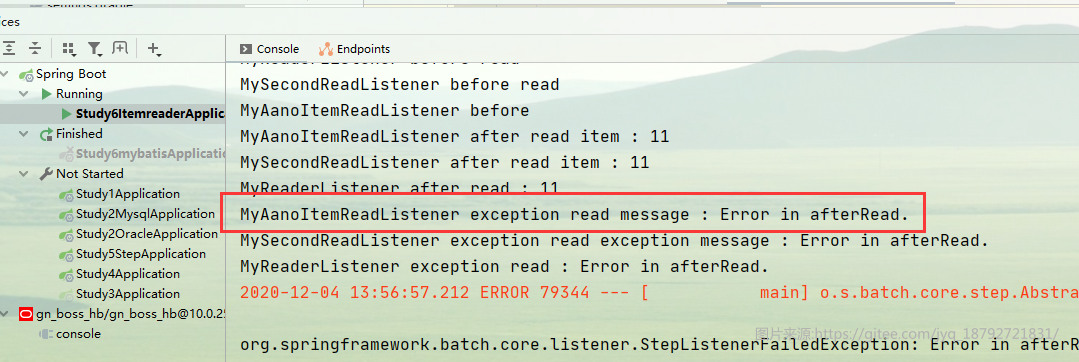
拦截器方法如果抛出异常,会影响Job的执行,所以在执行自定义的拦截器的时候,需要考虑对拦截器发生的异常做处理,避免因拦截器异常从而导致整个Job异常。
比如在上面的例子中,我们将id为11的记录抛出异常。
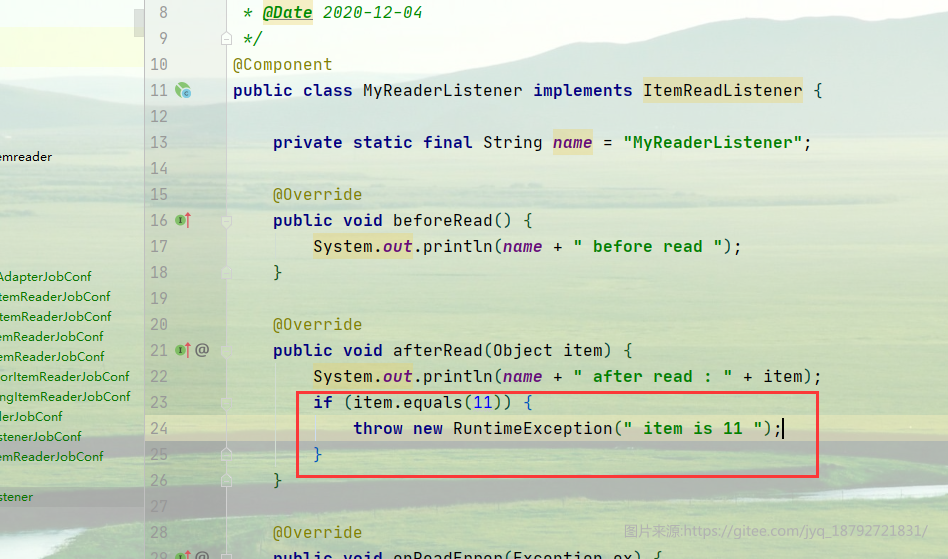
然后启动
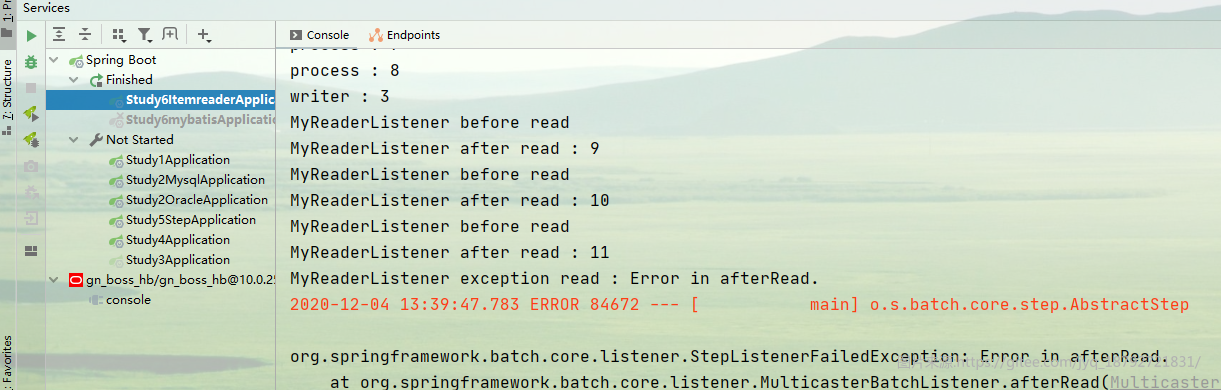
异常是我们主动抛出的
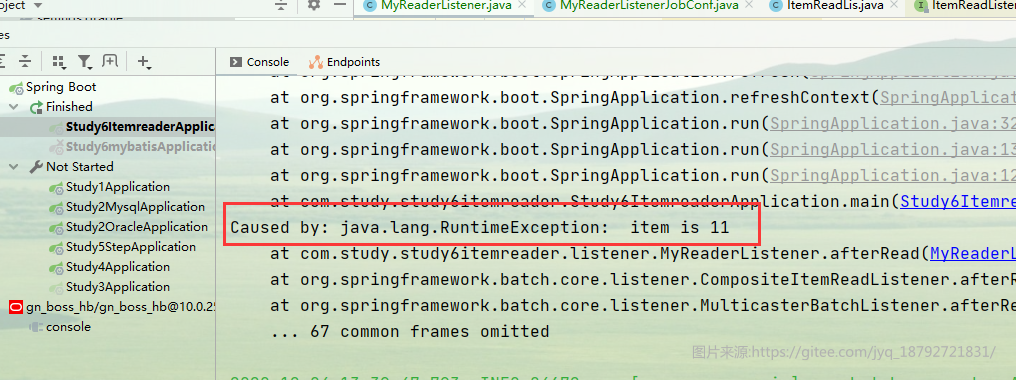
整个Job是FAILED的了
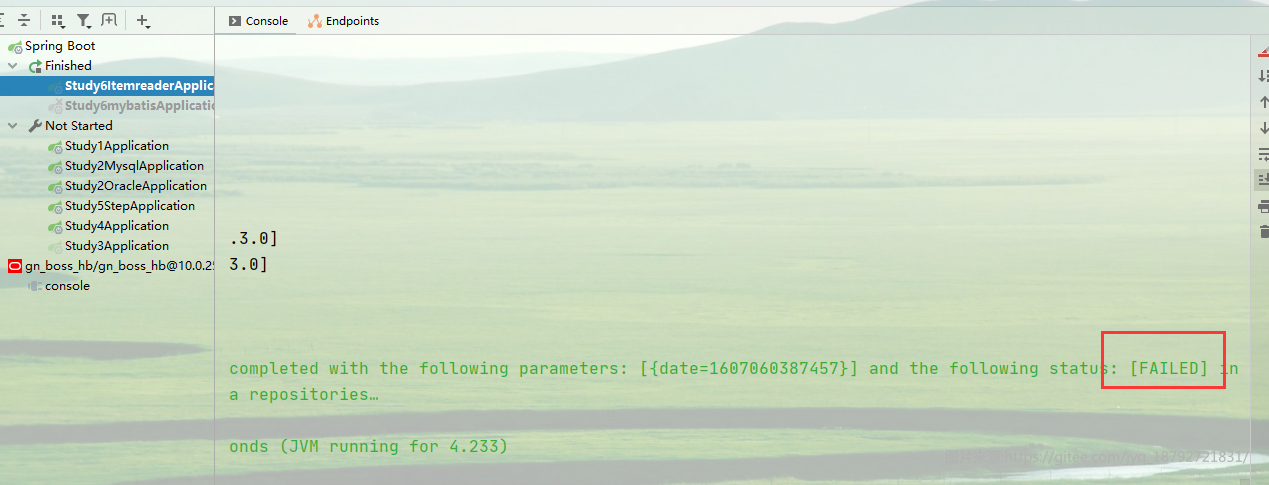
执行顺序
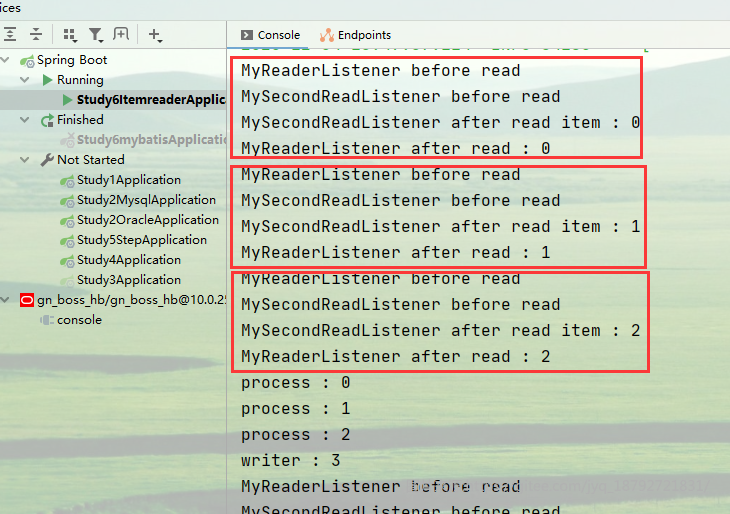
在配置的时候,可以配置多个ItemReadListener,执行的顺序与配置的顺序相同。
before是配置的顺序,after是配置的倒序。
在上面的例子的基础上,增加另一个ItemReadListener
@Component
public class MySecondReadListener implements ItemReadListener<Integer> {
private static final String name = "MySecondReadListener";
@Override
public void beforeRead() {
System.out.println(name + " before read ");
}
@Override
public void afterRead(Integer item) {
System.out.println(name + " after read item : " + item);
}
@Override
public void onReadError(Exception ex) {
System.out.println(name + " exception read exception message : " + ex.getMessage());
}
}
在step中增加Listener
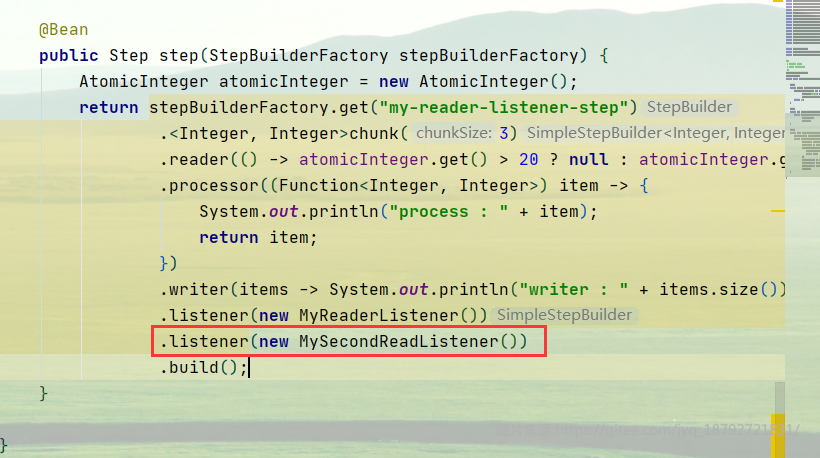
执行
Annotation
除了实现接口,spring batch框架提供了注解机制,可以在不实现接口的情况下,直接通过注解,定义拦截器。
ItemReadListener提供的注解有:
- @BeforeRead
- @AfterRead
- OnReadError
创建使用注解的拦截器
public class MyAanoItemReadListener {
private static final String name = "MyAanoItemReadListener";
@BeforeRead
public void before(){
System.out.println(name + " before ");
}
@AfterRead
public void after(Object item){
System.out.println(name + " after read item : " + item);
}
@OnReadError
public void onError(Exception e) {
System.out.println(name + " exception read message : " + e.getMessage());
}
}
然后使用
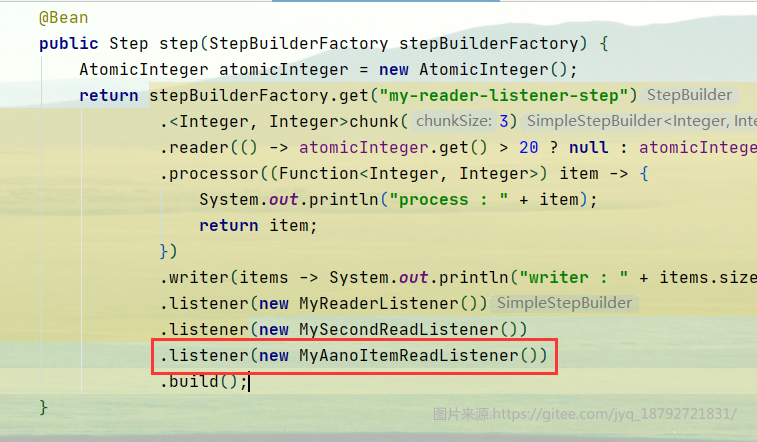
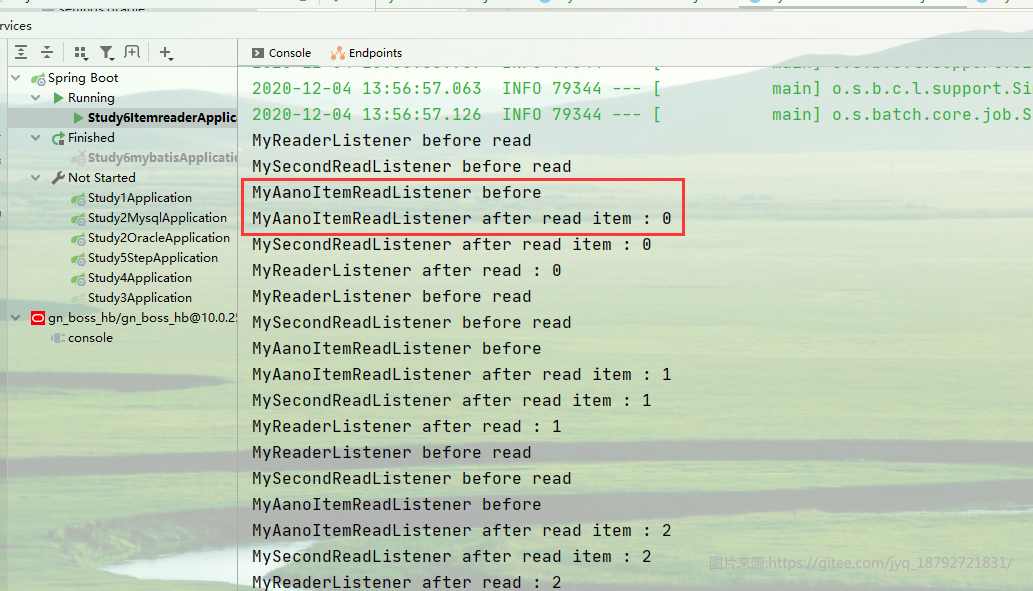
启动
异常也有
属性Merge
spring batch框架提供了多处配置拦截器执行,可以在chunk配置,也可以在tasklet配置。而且基于step的抽象和继承,可以在子step中控制是否执行父step。
通过在子step中使用super调用父step的监听,就可以实现将父、子step的拦截器全部注册。
如果在子step中没有调用父step中注册拦截器的方法,那么父step中的拦截器就不会注册,也就不会执行。