最近看了李宏毅ML课程,想起了之前写过的相关博客,在此做一个补充吧(下面的图片均来自于该课程PPT)
1、卷积神经网络结构
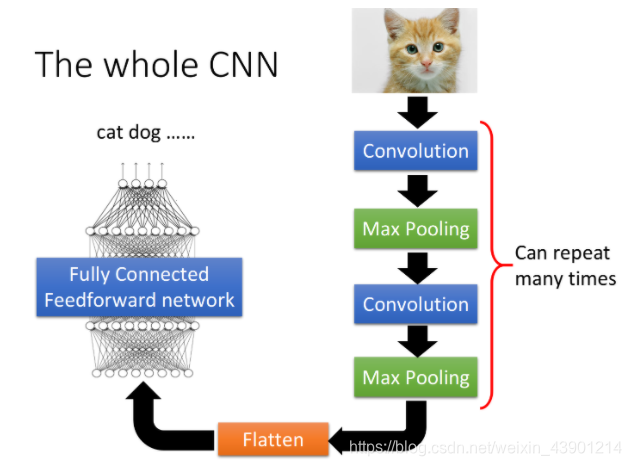
The whole CNN structure
2、Convolution V.s. Fully connected
你可能觉得说,卷积是一个很特别的操作,跟neural network没半毛钱关系,但它其实就是一个neural network。其实卷积核(filter)是特殊的”neuron“。
卷积其实就是全连接的层把一些weight拿掉而已,下图中绿色方框标识出的特征图的输出,其实就是隐藏层的神经的输出
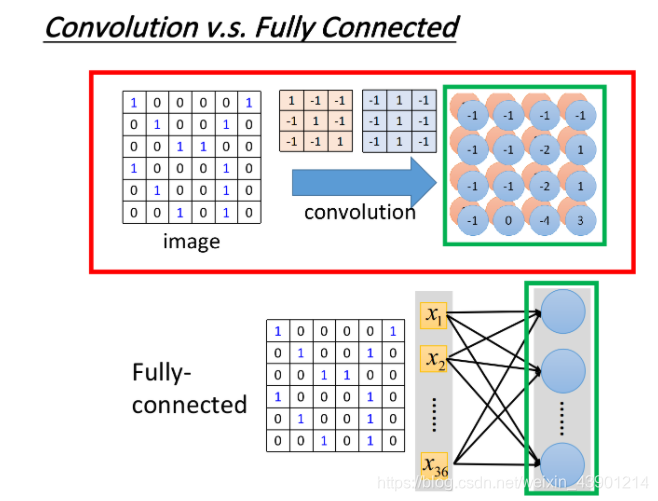
具体解释如下:
如下图所示,在做卷积的时候,把filter放在image的左上角,然后再去做内积,得到一个值3;这件事情等同于把这个image的6*6的matrix拉直变成右边这个用于输入的向量,然后,你有一个粉红色的神经元(就是下图中最右边的一个球),这些输入经过这个神经元之后,得到的输出是3。(先别管与神经元连接着的花里胡哨的线,下面会讲)
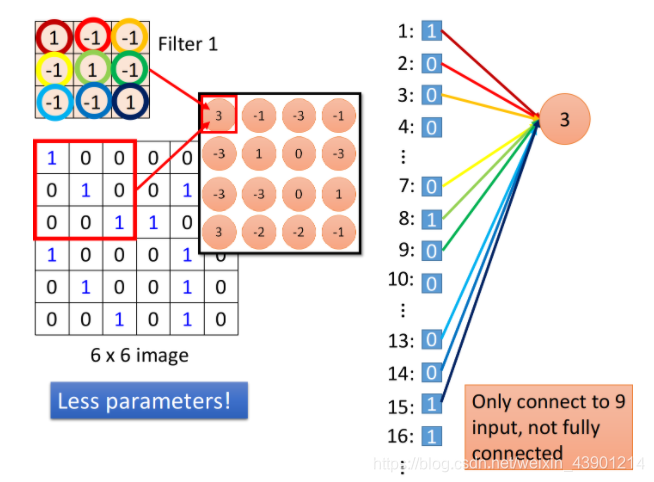
- 每个“neuron”只检测image的部分区域(这里的neural指卷积操作下的一种类似的神经元)。
当我们把filter放在image的左上角,此时filter考虑的就是和它重合的9个pixel,假设此时你把6*6的36个pixel拉直成向量作为输入,那么这9个pixel分别对应着上图右边中的1,2,3编号的pixel值、7,8,9编号的pixel值、13,14,15编号的pixel值(就是上图与彩色线相连的一些value)。
如果我们说这个filter和image matrix做内积以后得到的输出 3,就是输入向量经过某个神经元得到的输出 3的话,这就代表说存在这样一个神经元,这个神经元是带weight的连线,但是只连接到编号为1,2,3,7,8,9,13,14,15的这9个pixel而已,而这个神经元和这9个pixel连线上所标注的的weight就是filter matrix里面的这9个数值([[1,-1,-1],[-1,1,-1],[-1,-1,1]])
相比之下,全连接的neuron则必须连接到所有36个input上,但是,现在(进行的卷积操作)只用连接9个输入,因为我们知道要detect一个pattern,不需要看整张image,看9个input pixel就够了,所以当我们这么做的时候,就用了比较少的参数
- “neuron”之间共享参数
当我们把filter做stride = 1的移动的时,通过filter和image matrix的内积得到另外一个输出值-1,我们假设这个-1是另外一个neuron的输出,那这个neuron会连接到哪些输入呢?下图中这个框起来的地方正好就对应到pixel 2,3,4,pixel 8,9,10跟pixel 14,15,16。
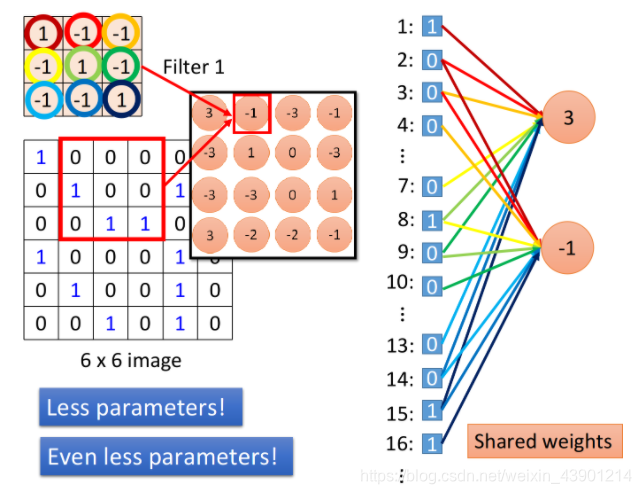
从上图中可以看出输出为3和-1的这两个neuron(粉红的球球),它们分别去检测在image的两个不同位置上是否存在某个pattern,因此在全连接里它们做的是两件不同的事情,每一个neuron应该有自己独立的weight。
但是,当我们做卷积的时,首先把每一个neuron前面连接的weight减少了,然后我们强迫某些neuron(比如上图中output为3和-1的两个neuron),它们一定要共享一组weight,虽然这两个neuron连接到的pixel对象各不相同(即输入是不同的),但它们用的weight都必须是一样的,等于filter里面的元素值,这件事情就叫做weight share,当我们做这件事情的时候,用的参数,又会比原来更少。
- 总结
当filter在image matrix上移动做卷积操作的时候,每次移动做的事情实际上是去检测这个地方有没有某一种pattern,对于全连接层来说,它是对整张image做检测,因此每次去检测image上不同地方有没有pattern其实是不同的事情,所以这些神经元都必须连接到整张image的所有pixel上,并且不同神经元的连线上的weight都是相互独立的。
那对于卷积层来说,首先它是对image的一部分做检测,因此它的神经元只需要连接到image的部分pixel上,对应连线所需要的weight参数就会减少;其次由于是用同一个filter去检测不同位置的pattern,所以这对卷积层来说,其实是同一件事情,因此不同的神经元,虽然连接到的pixel对象各不相同,但是在“做同一件事情”的前提下,也就是用同一个filter的前提下,这些神经元所使用的weight参数都是相同的,通过这样一张weight share的方式,再次减少网络所需要用到的weight参数。CNN的本质,就是减少参数的过程。
3、1*1卷积 V.s. 全连接
1*1的filter最后得到的特征图与原图大小是一样的,只是可以根据filter的channel来改变原image的channel,可以起到降维的作用。
根据第2节中的内容,我们知道比如3x3的filter形成的”neuron“与被拉直后的原image中的每个pixel值是部分连接的,而1x1的filter所形成的”neuron“则是与原image matrix被拉直后的所有pixel的值相连,且所有的weight都是filter中的value。所以此时等价于全连接网络。
4、想在某个任务上使用CNN的条件
使用CNN的条件基础:
(1)三个property
-
Some patterns are much smaller than the whole image ——property 1
例如一张鸟的image,其中鸟的嘴是一个特征,它在整幅图的局部一个小范围就可以找到。即每一个neuron其实只要连接到一个小块的区域就好,它不需要连接到整张完整的图,因此也对应着更少的参数
-
The same patterns appear in different regions ——property 2
同样的pattern,可能会出现在image的不同部分,但是它们有同样的形状、代表的是同样的含义,因此它们也可以用同样的neuron、同样的参数,被同一个detector检测出来。例如两张image,一个鸟嘴处于左上角,一个鸟嘴处于中央,但你并不需要训练两个不同的detector去专门侦测左上角有没有鸟嘴和中央有没有鸟嘴这两件事情,所以我们可以要求这些功能几乎一致的neuron共用一组参数,它们share同一组参数就可以帮助减少总参数的量
-
Subsampling the pixels will not change the object ——property 3
例如对一个image做subsampling,你拿掉奇数行、偶数列的pixel,把image变成原来的1/4的大小也不会影响你看这张图的样子,基于这个观察才有了Max pooling这个layer
(2)两个架构
convolution架构:针对property 1和property 2
max pooling架构:针对property 3