1. 一条更新Sql语句的执行流程
更新语句的基本流程和查询语句一致的,也就是说,它也要经过解析器、优化器的处理,最后交给执行器。区别就在于拿到符合条件的数据之后的操作。
1.1 缓冲池 Buffer Pool
首先,对于InnoDB存储引擎来说,数据都是放在磁盘上的,存储引擎要操作数据, 必须先把磁盘里面的数据加载到内存里面才可以操作。
这里就有个问题,是不是我们需要的数据多大,我们就一次从磁盘加载多少数据到内存呢?比如我要读6个字节。
磁盘I/O的读写相对于内存的操作来说是很慢的。如果我们需要的数据分散在磁盘的不同的地方,那就意味着会产生很多次的I/O操作。
所以,无论是操作系统也好,还是存储引擎也好,都有一个预读取的概念。也就是说,当磁盘上的一块数据被读取的时候,很有可能它附近的位置也会马上被读取到,这个就叫做局部性原理。那么这样,我们干脆每次多读取一点,而不是用多少读多少。
InnoDB设定了一个存储弓I擎从磁盘读取数据到内存的最小的单位,叫做页。操作系统也有页的概念。操作系统的页大小一般是4K,而在InnoDB里面,这个最小的单位默认是16KB大小。如果要修改这个值的大小,需要清空数据重新初始化服务。
这里有一个问题,操作数据的时候,每次都要从磁盘读取到内存(再返回给Server),
有没有什么办法可以提高效率?还是缓存的思想。把读取过的数据页缓存起来。
InnoDB设计了一个内存的缓冲区。读取数据的时候,先判断是不是在这个内存区域里面,如果是,就直接读取,然后操作,不用再次从磁盘加载。如果不是,读取后就写到这个内存的缓冲区。这个内存区域有个专属的名字,叫Buffer Pool
修改数据的时候,也是先写入到buffer pool,而不是直接写到磁盘。内存的数据页和磁盘数据不一致的时候,我们把它叫做脏页。那脏页什么时候才同步到磁盘呢?
InnoDB里面有专门的后台线程把Buffer Pool的数据写入到磁盘,每隔一段时间就一次性地把多个修改写入磁盘,这个动作就叫做刷脏。
总结一下:Buffer Pool的作用是为了提高读写的效率。
1.2 Redo log 重做日志 (实现持久性)
思考一个问题:因为刷脏不是实时的,如果Buffer Pool里面的脏页还没有刷入磁盘时,数据库宕机或者重启,这些数据就会丢失。
那怎么办呢?所以内存的数据必须要有一个持久化的措施。
为了避免这个问题,InnoDB把所有对页面的修改操作专门写入一个日志文件。
如果有未同步到磁盘的数据,数据库在启动的时候,会从这个日志文件进行恢复操作(实现crash-safe)。我们说的事务的ACID里面D (持久性),就是用它来实现的。

这个日志文件就是磁盘的redo log (叫做重做日志)
有没有同学有这样的问题:同样是写磁盘,为什么不直接写到dbfile里面去?为什么先写日志再写磁盘?
写日志文件和写到数据文件有什么区别?
我们先说一下磁盘寻址的过程。这个是磁盘的构造。磁盘的盘片不停地旋转,磁头会在磁盘表面画出一个圆形轨迹,这个就叫磁道。从内到外半径不同有很多磁道。然后又用半径线,把磁道分割成了扇区(两根射线之内的扇区组成扇面)。如果要读写数据, 必须找到数据对应的扇区,这个过程就叫寻址。
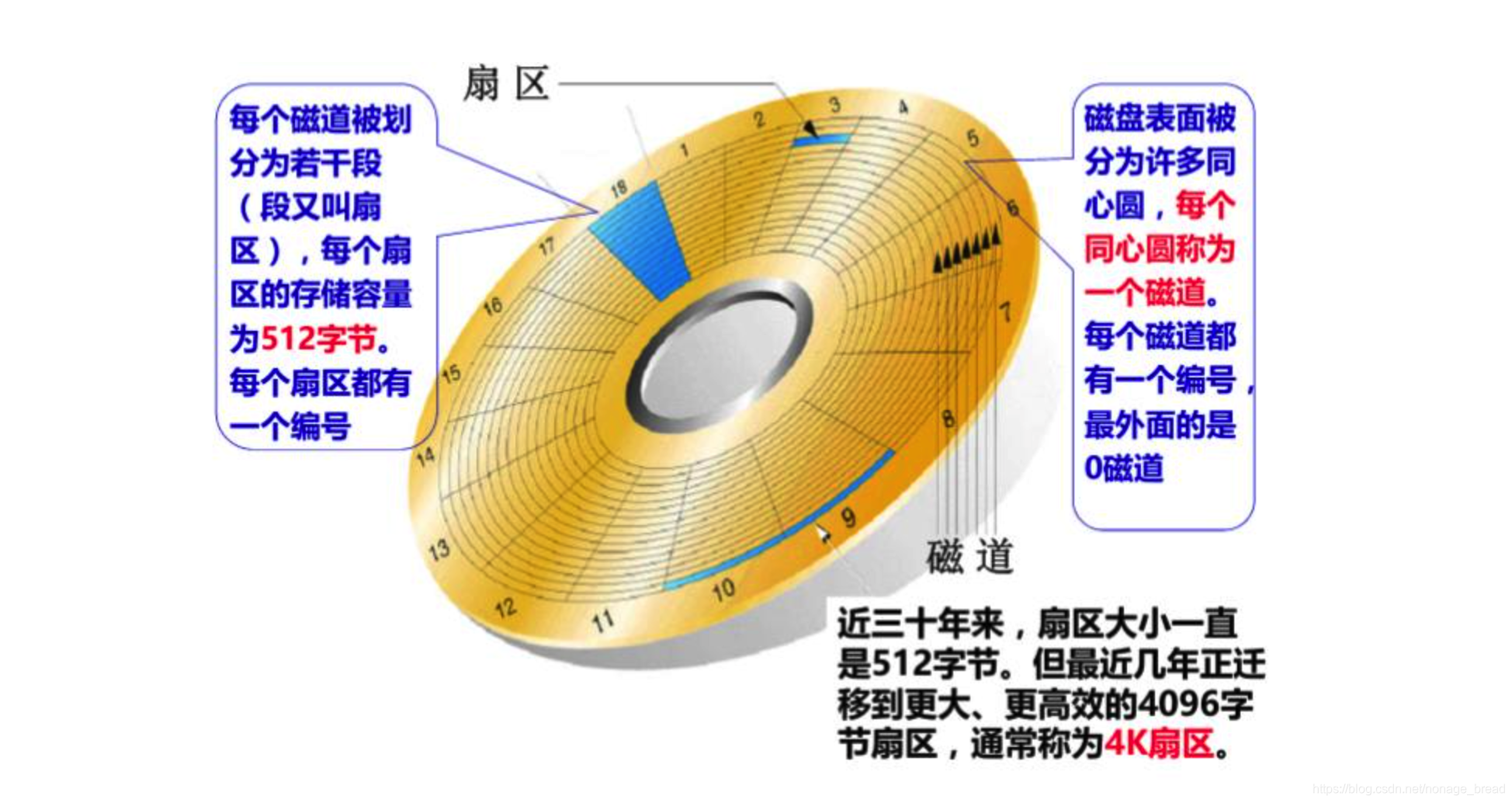
- 随机IO:
如果我们所需要的数据是随机分散在磁盘上不同页的不同扇区中,那么找到相应的数据需要等到磁臂旋转到指定的页,然后盘片寻找到对应的扇区,才能找到我们所需要的一块数据,一次进行此过程直到找完所有数据,这个就是随机IO,读取数据速度较慢。 - 顺序IO:
假设我们已经找到了第一块数据,并且其他所需的数据就在这一块数据后边,那么就不需要重新寻址,可以依次拿到我们所需的数据,这个就叫顺序IO。
刷盘是随机I/O,而记录日志是顺序I/O (连续写的),顺序I/O效率更高,本质上是数据集中存储和分散存储的区别。因此先把修改写入日志文件,在保证了内存数据的安全性的情况下,可以延迟刷盘时机,进而提升系统吞吐。
redo log 位于/var/lib/mysql/目录下的 ib_logfile0 和 ib_logfile1, 默认 2 个文件,每个48M。
show variables like 'innodb_log%';
| 参数 | 含义 |
|---|---|
| innodb_log_file_size | 指定每个文件的大小,默认48M |
| innodb_log_files_in_group | 指定文件的数量,默认为2 |
| innodb_log_group_home_dir | 指定文件所在路径,相对或绝对。如果不指定,则为 datadir 路径 |
redo log 的特点
- redo log是InnoDB存储引擎实现的,并不是所有存储引擎都有。支持崩溃恢复是InnoDB的一个特性。
- redo log不是记录数据页更新之后的状态,而是记录的是"在某个数据页上做了什么修改”。属于物理日志。
- redo log的大小是固定的,前面的内容会被覆盖,一旦写满,就会触发buffer pool 到磁盘的同步,以便腾出空间记录后面的修改。
除了 redo log之外,还有一个跟修改有关的日志,叫做undo logo。redo log和undo log与事务密切相关,统称为事务日志。
1.3. Undo log 撤销日志或回滚日志
undo log 记录了事务发生之前的数据状态,分为insert undo log和update undo log。如果修改数据时出现异常,可以用undo log来实现回滚操作 (保持原子性)。
可以理解为undo log记录的是反向的操作,比如insert会记录delete, update 会记录update原来的值,跟redolog记录在哪个物理页面做了什么操作不同,所以叫做逻辑格式的日志。
show global variables like '%undo%';
| 参数 | 含义 |
|---|---|
| innodb_undo_directory | undo文件的路径 |
| innodb_undo_log_truncate | 设置为1,即开启在线回收(收缩)undo log 志文件 |
| innodb_max_undo_log_size | 如果innodb_undo_log_truncate设置为1,超过这个大小的时候会触发 truncate回收(收缩)动作,如果page大小是16KB, truncate后空间缩小到10M 默认1073741824字节=1G。 |
| innodb_undo_logs | 回滚段的数量,默认128,这个参数已经过时。 |
| innodb_undo_tablespaces | 设置undo独立表空间个数,范围为0-95,默认为0,表示表示不开启独立undo表空间,且undo日志存储在ibdata文件中。这个参数已经过时, |
1.4 更新过程
有了这些日志之后,我们来总结一下一个更新操作的流程,这是一个简化的过程。 name 原值是 xhc
update user set name = '中华第一帅' where id=1;
- 事务开始,从内存(buffer pool)或磁盘(data file)取到包含这条数据的数据页,返回给Server的执行器;
- Server的执行器修改数据页的这一行数据的值为 ‘中华第一帅’;
- 记录 name=xhc 至 undo log;
- 记录 name=中华第一帅 至 redo log;
- 记录bin log;
- 调用存储引擎接口,记录数据页到Buffer Pool (修改name=中华第一帅);
- 事务提交。
1.5 bin log
什么是binlog?
binlog记录了数据库表结构和表数据变更,比如update/delete/insert/truncate/create。它不会记录select,因为这个没有对表进行变更。
binlog以事件的形式记录了所有的DDL和DML语句(因为它记录的是操作而不是数据值,属于逻辑日志),可以用来做主从复制和数据恢复。跟redo log不一样,它的文件内容是可以追加的,没有固定大小限制。
在开启了 binlog功能的情况下,我们可以把binlog导出成SQL语句,把所有的操作重放一遍,来实现数据的恢复。
binlog到底是什么样的?binlog我们可以理解位存储着每条变更的SQL语句。
binlog一般用来干什么?
主要的两个作用:复制和恢复数据
-
MySQL在公司使用的时候往往都是一主多从结构的,从服务器需要与主服务器的数据保持一致,这就是通过binlog来是实现的(数据库的主从复制),它的原理就是从服务器读取主服务器 的binlog,然后执行一遍。
-
数据库的数据被干掉了,我们可以通过binlog来对数据进行恢复。因为binlog记录了数据库表的变更,所以我们可以用binlog进行复制和恢复数据
在开启了bin log之后,我们来看一下一条更新语句是怎么执行的(redo 不能一次写入了)
两阶段提交:
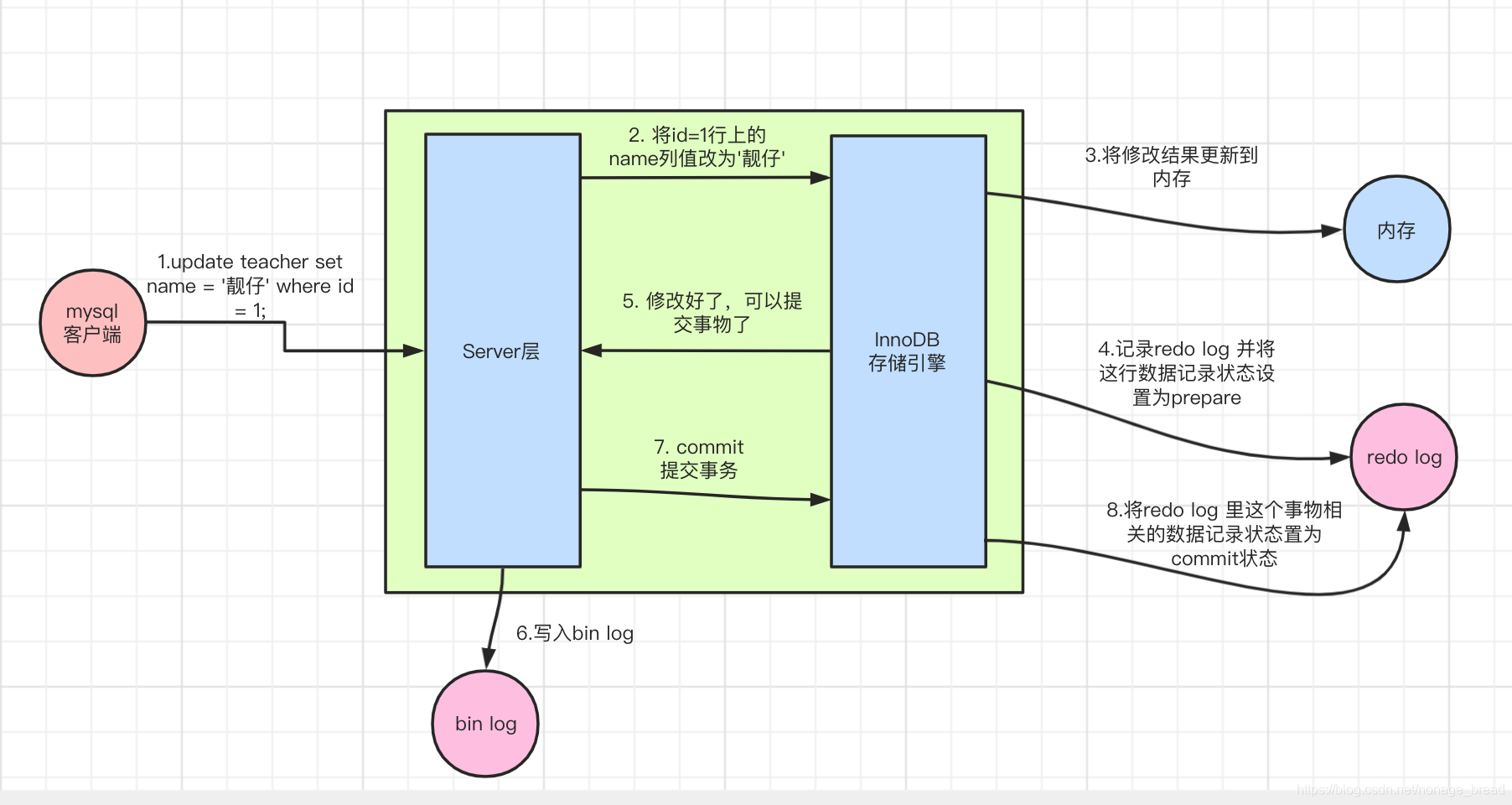
例如一条语句:
update teacher set name='靓仔' where id=1;
- 先查询到这条数据,如果有缓存,也会用到缓存。
- 把name改成 ‘靓仔’,然后调用引擎的API接口,写入这一行数据到内存, 同时记录redo log,这时redo log进入prepare状态,然后告诉执行器,执行完成了,可以随时提交。
- 执行器收到通知后记录binlog,然后调用存储引擎接口,设置redo log为 commit 状态。
- 更新完成。
这张图片的重点:
- 先记录到内存,再写日志文件。
- 记录redo log分为两个阶段。
- 存储引擎和Server记录不同的日志。
- 先记录redo,再记录bin log
为什么需要两阶段提交?
举例:
如果我们执行的是把name改成’靓仔’,如果写完redo log,还没有写binlog的时候,MySQL重启了。
因为redo log可以在重启的时候用于恢复数据,所以写入磁盘的是’靓仔’。但是 binlog里面没有记录这个逻辑日志,所以这时候用binlog去恢复数据或者同步到从库, 就会出现数据不一致的情况。
所以在写两个日志的情况下,binlog就充当了一个事务的协调者。通知InnoDB来执行 prepare 或者 commit 或者 rollback
如果第⑥步写入binlog失败,就不会提交。
简单地来说,这里有两个写日志的操作,类似于分布式事务,不用两阶段提交,就不能保证都成功或者都失败。
在崩溃恢复时,判断事务是否需要提交:
- binlog无记录,redolog无记录:在redolog写之前crash,恢复操作:回滚事务
- binlog无记录, redolog状态prepare:在binlog写完之前的crash,恢复操作:回滚事务
- binlog有记录,redolog状态prepare:在binlog写完提交事务之前的crash, 恢复操作:提交事务
- binlog有记录,redolog状态commit:正常完成的事务,不需要恢复