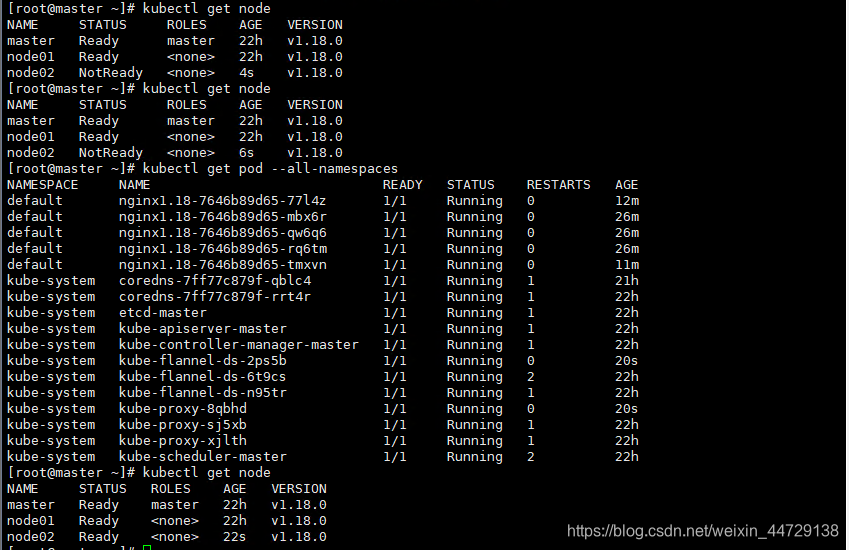
本篇是基于k8s-v1.18.0版本,参考https://cloud.tencent.com/developer/article/1552452。
一、环境说明
| 主机名 | ip | 系统版本 | docker版本 |
|---|---|---|---|
| master | 192.168.148.124 | CentOS 7.6.1810 | 19.03.9 |
| node01 | 192.168.148.125 | CentOS 7.6.1810 | 19.03.9 |
| node02 | 192.168.148.126 | CentOS 7.6.1810 | 19.03.9 |
二、背景
当node节点进行如打补丁、操作系统升级等操作时,需停机维护,这就涉及pod驱逐迁移,本文将详细介绍node节点维护的整个过程。
三、pdb简介
- pdb为poddisruptionbudgets缩写,意为主动驱逐保护;没有pdb,当进行节点维护时,如果某个服务的多个pod在该节点上,则节点的停机可能会造成服务中断或者服务降级。举个例子,某服务有5个pod,最低3个pod能保证服务质量,否则会造成响应慢等影响,此时该服务的4个pod在node01上,如果对node01进行停机维护,此时只有1个pod能正常对外服务,在node01的4个pod迁移过程中,就会影响该服务正常响应。
- pdb能保证应用在节点维护时不低于一定数量的pod运行,从而保持服务质量。
准备工作
1、新建pod
cd /root/pkg/eg/
kubectl create deployment nginx1.18 --image=nginx:1.18 --dry-run -o yaml > nginx.yml
cat nginx.ym
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx1.18
name: nginx1.18
spec:
replicas: 5
selector:
matchLabels:
app: nginx1.18
strategy: {
}
template:
metadata:
labels:
app: nginx1.18
spec:
containers:
- image: nginx:1.18
name: nginx
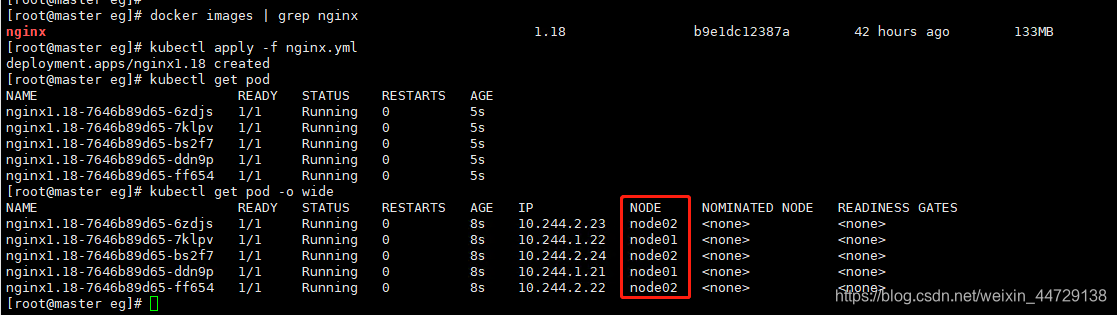
kubectl apply -f nginx.yml
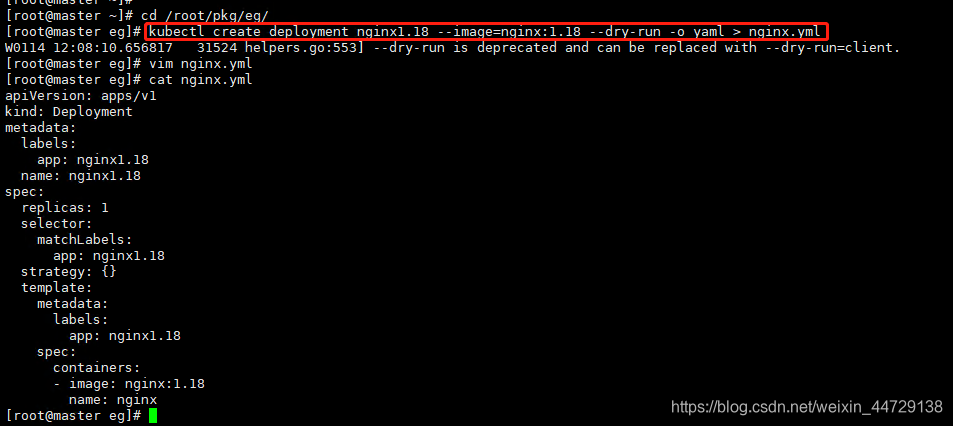
五个pod,分布于node01和node02上
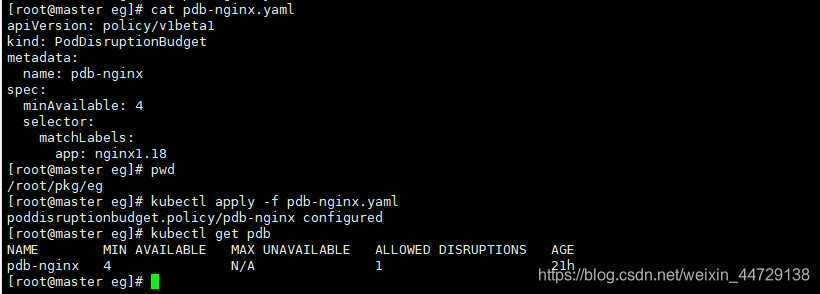
2、新建pdb
cd /root/pkg/eg
cat pdb-nginx.yaml
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: pdb-nginx
spec:
minAvailable: 4
selector:
matchLabels:
app: nginx1.18
新建pdb-nginx.yml,Label Selector和deployment一样都为app: nginx1.18,minAvailable: 4意为存活的nginx pod至少为4个。
四、节点维护
本文以节点node02维护为例介绍
1、设置节点不可调度
kubectl cordon node02

设置node02不可调度,查看各节点状态,发现node02为SchedulingDisabled,此时master不会将新的pod调度到该节点上,但是node02上pod还是正常运行。
2、驱逐节点上的pod
kubectl drain node02 --delete-local-data --ignore-daemonsets --force
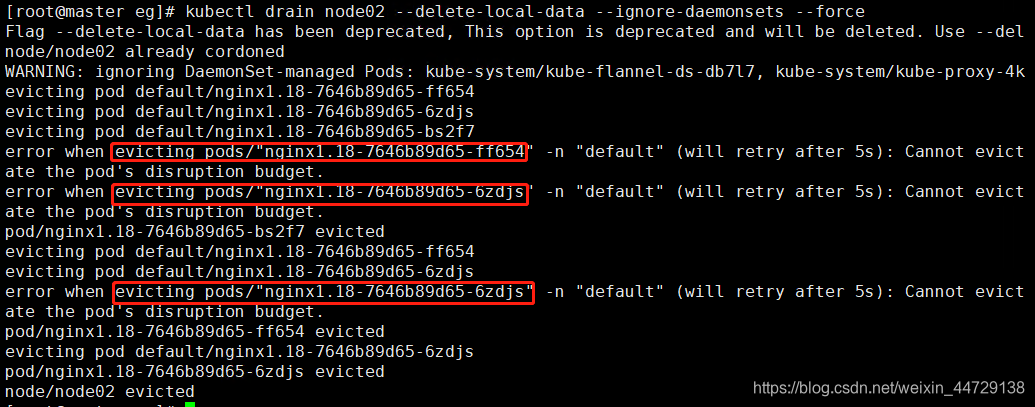

参数说明:
- –delete-local-data :即使pod使用了emptyDir也删除;
- –ignore-daemonsets :忽略deamonset控制器的pod,如果不忽略,deamonset控制器控制的pod被删除后可能马上又在此节点上启动起来,会成为死循环;
- –force :不加force参数只会删除该NODE上由ReplicationController, ReplicaSet,DaemonSet,StatefulSet or Job创建的Pod,加了后还会删除’裸奔的pod’(没有绑定到任何replication controller)
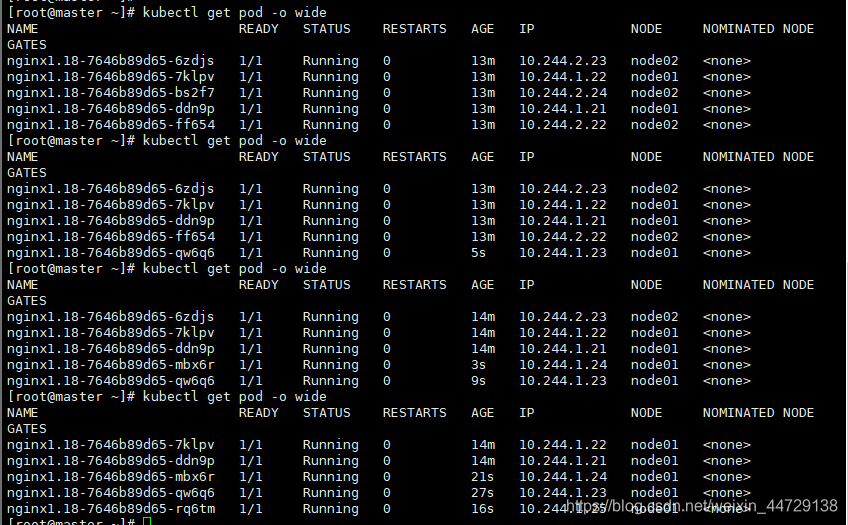
可以看到同一时刻只有一个pod进行迁移,对外提供服务的pod始终有4个,这个也再次验证了同一时刻只有一个pod迁移,nginx服务始终有4个pod对外提供服务。
3、维护结束
kubectl uncordon node02
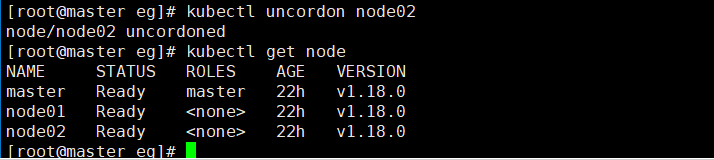
维护结束,重新将node02节点置为可调度状态。
五、pod回迁
pod回迁貌似还没什么好的办法,这里采用delete然后重建的方式回迁。
kubectl get po -o wide
kubectl delete pod nginx1.18-7646b89d65-7klpv nginx1.18-7646b89d65-ddn9p

可以在业务低峰nginx1.18-7646b89d65-7klpv和nginx1.18-7646b89d65-ddn9p,由于node02上的pod之前都被驱逐,此时资源使用率最低,所以pod重建时会调度值该节点,完成pod回迁。
六、节点删除
1、删除节点
实际运维过程中可能会删除某个node节点,本文还是以node02为例,介绍如果删除节点。
kubectl cordon node02
kubectl drain node02 --delete-local-data --ignore-daemonsets --force
kubectl delete node node02
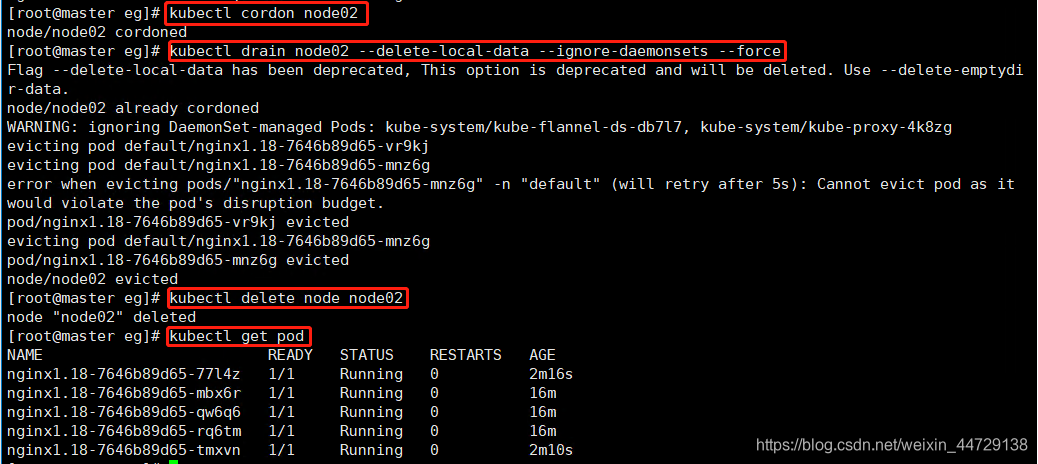

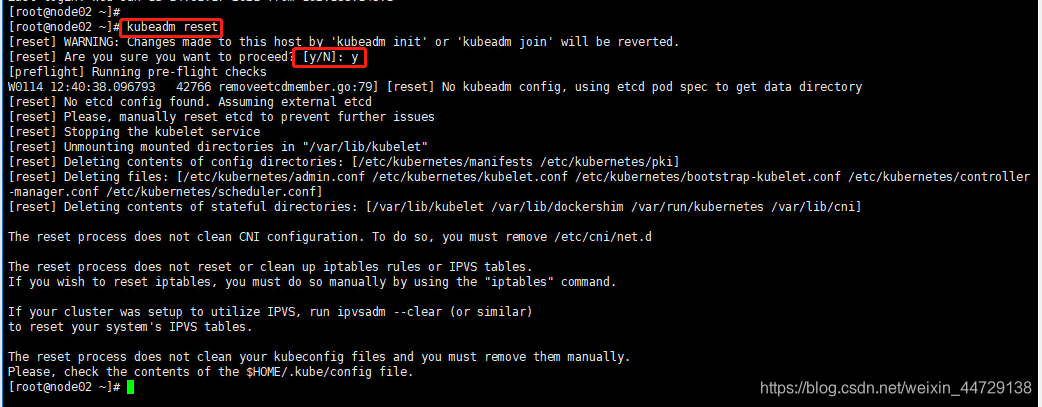
kubeadm reset
2、节点重新加入
master节点上运行
kubeadm token create --print-join-command

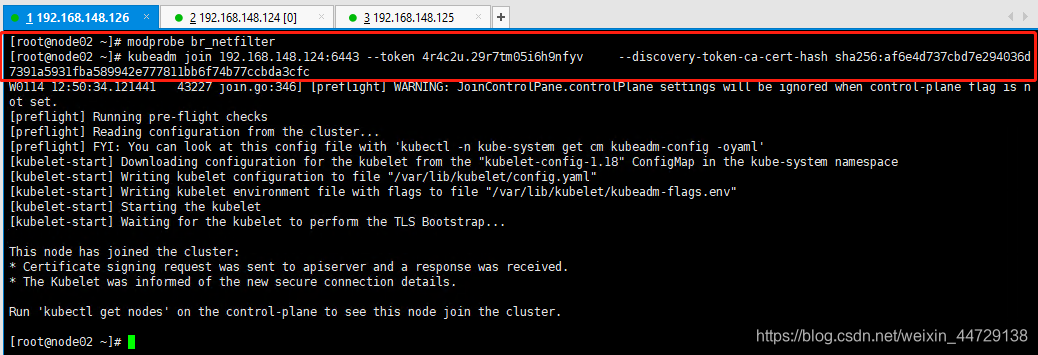
node02上运行
modprobe br_netfilter
kubeadm join 192.168.148.124:6443 --token 4r4c2u.29r7tm05i6h9nfyv --discovery-token-ca-cert-hash sha256:af6e4d737cbd7e294036d7391a5931fba589942e777811bb6f74b77ccbda3cfc #node02上运行
查看node
kubectl get node