https://www.cnblogs.com/davidwang456/p/4966465.html
zookeeper简介
zookeeper是为分布式应用提供分布式协作服务的开源软件。它提供了一组简单的原子操作,分布式应用可以基于这些原子操作来实现更高层次的同步服务,配置维护,组管理和命名。zookeeper的设计使基于它的编程非常容易,若我们熟悉目录树结构的文件系统,也会很容易使用zookeeper的数据模型样式。它运行在java上,有java和c的客户端。
协作服务因难于获取正确而臭名远扬,他们特别易于出错如竞争条件和死锁。zookeeper的动机是减轻分布式应用中从零开始实现协作服务的压力。
zookeeper的特点
1.简单:zookeeper运行分布式进行通过一个共享的层次命名空间来进行协作,该命名空间的组织类似于标准的文件系统。命名空间包括数据注册器(称之为znode),在zookeeper看来,这类似于文件和目录。与典型的文件系统设计用来存储不同的是,zookeeper数据是存放在内存中,这意味着zookeeper可以实现很高的吞吐量和低延迟。
ZooKeeper 实现在高性能,高可用性,严格有序的访问方面有很大的优势。在性能方面的优势使它可以应用在大型的的分布式系统。在可靠性方面,避免单点故障。严格的顺序访问使它在客户端可以实现复杂的同步原语。
2. 可复制:类似于分布式进程的协作,zookeeper本身很容易在一组主机(称之为集合)中实现复制。zookeeper服务示意图:
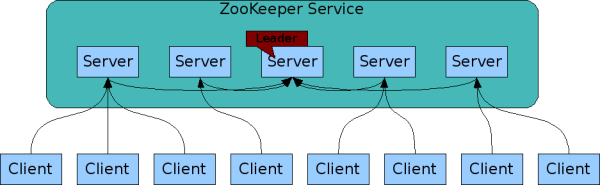
组成ZooKeeper服务的一组服务器都必须知道对方的。它们保存了内存映像的状态,以及在持久存储中的事务日志和快照。只要大部分的服务器可用,ZooKeeper服务将可用。
客户端连接到一台ZooKeeper服务器。客户端维护一个TCP连接,通过它发送请求,得到响应,得到监视事件,并发送心跳。如果TCP连接到服务器中断,客户端可以连接到不同的服务器。
3. 有序:ZooKeeper给每次更新使用数字打标记,它反映了所有zookeeper事务的顺序。随后的操作可以使用这些顺序来实现更高级别的抽象,如同步原语。
4.快速:它特别快,在“读为主”的工作中,ZooKeeper 应用程序运行在数千台机器,它在读远比写更多的时候(在10:1的比例)表现的最好。
数据模型与层次命名空间
ZooKeeper提供的名称空间更像是一个标准的文件系统。一个名字是一个由一个(或)分隔的路径元素的序列。zookeeper名称空间的每个节点由路径来标示。
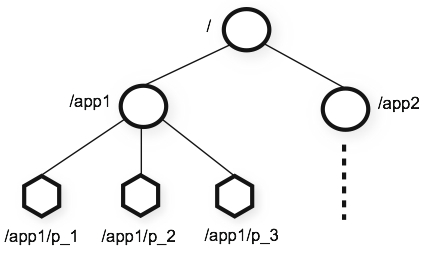
节点和临时节点
不像标准的文件系统,在ZooKeeper 命名空间中每个节点都有与它相关的数据以及子节点。它就像这样一个文件系统,它允许一个文件也可以是一个目录。(zookeeper是用来储存协作数据:状态信息,配置,位置信息等,因此,存储在每个节点的数据通常是很小的,在字节到千字节范围。)我们使用术语znode来表明我们谈论的是zookeeper数据节点。
znodes保存一个数据结构,该数据结构包括数据变化的版本号和时间戳,ACL的变化,这些信息允许缓存验证和协作更新。一个znode的数据的每次变化,版本号的增加。例如,每当客户检索数据时,它也接收到数据的版本。
在一个命名空间中的每个节点存储的数据的读写都是原子性的。读获取一个Znode所有的数据字节;写替换所有的数据。每个节点都有一个访问控制列表(ACL),限制谁可以做什么。
zookeeper也有临时节点的概念。这些znodes只要创建znode的会话是活跃的,它就存在的。当会话结束时,这些znode被删除。
条件更新与监控
ZooKeeper支持监控的概念。客户端可以在一个znode上设置一个监控。当znode发生变化时会触发或者移除监控。当监控触发时,客户端接收到一个报文,表明znode发生了变化。若客户端和一个zookeeper服务器的连接损坏时,客户端接收到一个本地通知。
保障
ZooKeeper非常快速和简单. 虽然它的目标是为建设更为复杂的服务,例如同步,它提供了一系列的保证。这些是:
顺序一致性----客户端的更新将被应用于它们被发送的命令中。
原子性-- - 更新要么成功要么失败,不存在部分成功或者部分失败.
单系统映像 ---- 不管连接到哪台服务器,客户端看到相同的服务视图.
可靠性---- 一旦一个更新发生,直到下次一个客户端重新了更新,否则从更新的时间后都会保持。
及时性--- - 在一定时间范围内保证系统的客户视图是最新的.
简单api
zookeeper设计目标之一是提供一个简单的编程接口,因此,它只支持下面这些操作:
- create
-
在节点树上某个位置上创建一个新的节点。
- delete
-
删除一个节点
- exists
-
测试某位置的节点是否存在
- get data
-
从一个节点读取数据
- set data
-
向一个节点写入数据
- get children
-
检索一个节点的一组子节点
- sync
-
等待数据传播至一致。
实现
zookeeper组件显示了zookeeper服务的高级组件。除了request processor,组成zookeeper服务的每个服务器复制它的每个组件的copy。
zookeeper组件
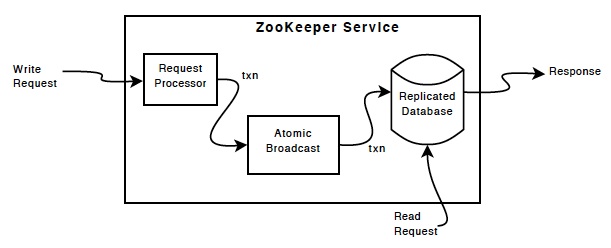
replicated database是一个包含整个数据数的内存数据库. 为了可复原,更新被写到磁盘上,写操作在应用到内存数据库之前,先序列化到磁盘。
每个zookeeper服务器给所有的客户端提供服务。客户端恰恰连接到一个服务器来提交请求。读请求由每个服务器数据库的本地复制提供服务。写请求改变了服务的状态,由request processor来处理。
作为通信协议的一部分,所有客户端的写请求由一个单独的服务器处理,这个服务器是zookeeper的leader服务器,其余的zookeeper服务器叫做follower,follower从leader接收消息并达成消息传输。消息层在失败后替换leader并同步到连接到leader所有的follower。
ZooKeeper使用自定义的原子消息协议. 因消息层是原子性的, ZooKeeper 可以保证本地复制不会冲突. 当leader接收到一个写请求,当写操作应用到系统时,leader计算出系统的状态,并转化成一个捕捉新状态的事务.
zookeeper启动
服务端启动
bin/zkServer.sh start
其中,启动命令如下:

start) echo -n "Starting zookeeper ... " if [ -f "$ZOOPIDFILE" ]; then if kill -0 `cat "$ZOOPIDFILE"` > /dev/null 2>&1; then echo $command already running as process `cat "$ZOOPIDFILE"`. exit 0 fi fi nohup "$JAVA" $ZOO_DATADIR_AUTOCREATE "-Dzookeeper.log.dir=${ZOO_LOG_DIR}" \ "-Dzookeeper.log.file=${ZOO_LOG_FILE}" "-Dzookeeper.root.logger=${ZOO_LOG4J_PROP}" \ -XX:+HeapDumpOnOutOfMemoryError -XX:OnOutOfMemoryError='kill -9 %p' \ -cp "$CLASSPATH" $JVMFLAGS $ZOOMAIN "$ZOOCFG" > "$_ZOO_DAEMON_OUT" 2>&1 < /dev/null & if [ $? -eq 0 ] then if /bin/echo -n $! > "$ZOOPIDFILE" then sleep 1 pid=$(cat "${ZOOPIDFILE}") if ps -p "${pid}" > /dev/null 2>&1; then echo STARTED else echo FAILED TO START exit 1 fi else echo FAILED TO WRITE PID exit 1 fi else echo SERVER DID NOT START exit 1 fi ;;
其中:
ZOOMAIN 是启动程序的入口,其类为:
org.apache.zookeeper.server.quorum.QuorumPeerMain
它的启动方法为:
/** * To start the replicated server specify the configuration file name on * the command line. * @param args path to the configfile */ public static void main(String[] args) { QuorumPeerMain main = new QuorumPeerMain(); try { main.initializeAndRun(args); } catch (IllegalArgumentException e) { LOG.error("Invalid arguments, exiting abnormally", e); LOG.info(USAGE); System.err.println(USAGE); System.exit(2); } catch (ConfigException e) { LOG.error("Invalid config, exiting abnormally", e); System.err.println("Invalid config, exiting abnormally"); System.exit(2); } catch (DatadirException e) { LOG.error("Unable to access datadir, exiting abnormally", e); System.err.println("Unable to access datadir, exiting abnormally"); System.exit(3); } catch (AdminServerException e) { LOG.error("Unable to start AdminServer, exiting abnormally", e); System.err.println("Unable to start AdminServer, exiting abnormally"); System.exit(4); } catch (Exception e) { LOG.error("Unexpected exception, exiting abnormally", e); System.exit(1); } LOG.info("Exiting normally"); System.exit(0); }
调用初始化方法及run方法:
protected void initializeAndRun(String[] args) throws ConfigException, IOException, AdminServerException { QuorumPeerConfig config = new QuorumPeerConfig(); if (args.length == 1) { config.parse(args[0]); } // Start and schedule the the purge task DatadirCleanupManager purgeMgr = new DatadirCleanupManager(config .getDataDir(), config.getDataLogDir(), config .getSnapRetainCount(), config.getPurgeInterval()); purgeMgr.start(); if (args.length == 1 && config.isDistributed()) { runFromConfig(config); } else { LOG.warn("Either no config or no quorum defined in config, running " + " in standalone mode"); // there is only server in the quorum -- run as standalone ZooKeeperServerMain.main(args); } }
上述代码主要分3部分:
1. 解析配置文件,默认的配置文件为上一级目录
config/zookeeper.properties或者config/zookeeper.cfg
/** * Parse a ZooKeeper configuration file * @param path the patch of the configuration file * @throws ConfigException error processing configuration */ public void parse(String path) throws ConfigException { LOG.info("Reading configuration from: " + path); try { File configFile = (new VerifyingFileFactory.Builder(LOG) .warnForRelativePath() .failForNonExistingPath() .build()).create(path); Properties cfg = new Properties(); FileInputStream in = new FileInputStream(configFile); try { cfg.load(in); configFileStr = path; } finally { in.close(); } parseProperties(cfg); } catch (IOException e) { throw new ConfigException("Error processing " + path, e); } catch (IllegalArgumentException e) { throw new ConfigException("Error processing " + path, e); } if (dynamicConfigFileStr!=null) { try { Properties dynamicCfg = new Properties(); FileInputStream inConfig = new FileInputStream(dynamicConfigFileStr); try { dynamicCfg.load(inConfig); if (dynamicCfg.getProperty("version") != null) { throw new ConfigException("dynamic file shouldn't have version inside"); } String version = getVersionFromFilename(dynamicConfigFileStr); // If there isn't any version associated with the filename, // the default version is 0. if (version != null) { dynamicCfg.setProperty("version", version); } } finally { inConfig.close(); } setupQuorumPeerConfig(dynamicCfg, false); } catch (IOException e) { throw new ConfigException("Error processing " + dynamicConfigFileStr, e); } catch (IllegalArgumentException e) { throw new ConfigException("Error processing " + dynamicConfigFileStr, e); } File nextDynamicConfigFile = new File(configFileStr + nextDynamicConfigFileSuffix); if (nextDynamicConfigFile.exists()) { try { Properties dynamicConfigNextCfg = new Properties(); FileInputStream inConfigNext = new FileInputStream(nextDynamicConfigFile); try { dynamicConfigNextCfg.load(inConfigNext); } finally { inConfigNext.close(); } boolean isHierarchical = false; for (Entry<Object, Object> entry : dynamicConfigNextCfg.entrySet()) { String key = entry.getKey().toString().trim(); if (key.startsWith("group") || key.startsWith("weight")) { isHierarchical = true; break; } } lastSeenQuorumVerifier = createQuorumVerifier(dynamicConfigNextCfg, isHierarchical); } catch (IOException e) { LOG.warn("NextQuorumVerifier is initiated to null"); } } } }
2. 启动安排清除任务
// Start and schedule the the purge task DatadirCleanupManager purgeMgr = new DatadirCleanupManager(config .getDataDir(), config.getDataLogDir(), config .getSnapRetainCount(), config.getPurgeInterval()); purgeMgr.start();
调用start方法:
/** * Validates the purge configuration and schedules the purge task. Purge * task keeps the most recent <code>snapRetainCount</code> number of * snapshots and deletes the remaining for every <code>purgeInterval</code> * hour(s). * <p> * <code>purgeInterval</code> of <code>0</code> or * <code>negative integer</code> will not schedule the purge task. * </p> * * @see PurgeTxnLog#purge(File, File, int) */ public void start() { if (PurgeTaskStatus.STARTED == purgeTaskStatus) { LOG.warn("Purge task is already running."); return; } // Don't schedule the purge task with zero or negative purge interval. if (purgeInterval <= 0) { LOG.info("Purge task is not scheduled."); return; } timer = new Timer("PurgeTask", true); TimerTask task = new PurgeTask(dataLogDir, snapDir, snapRetainCount); timer.scheduleAtFixedRate(task, 0, TimeUnit.HOURS.toMillis(purgeInterval)); purgeTaskStatus = PurgeTaskStatus.STARTED; }
从上面代码可以看到,清除工作启动了一个定时器timer,PurgeTask继承实现了TimeTask(一个可以被定时器安排执行一次或者多次的task),PurgeTask的实现如下:
static class PurgeTask extends TimerTask { private File logsDir; private File snapsDir; private int snapRetainCount; public PurgeTask(File dataDir, File snapDir, int count) { logsDir = dataDir; snapsDir = snapDir; snapRetainCount = count; } @Override public void run() { LOG.info("Purge task started."); try { PurgeTxnLog.purge(logsDir, snapsDir, snapRetainCount); } catch (Exception e) { LOG.error("Error occured while purging.", e); } LOG.info("Purge task completed."); } }
调用purge方法:
/** * Purges the snapshot and logs keeping the last num snapshots and the * corresponding logs. If logs are rolling or a new snapshot is created * during this process, these newest N snapshots or any data logs will be * excluded from current purging cycle. * * @param dataDir the dir that has the logs * @param snapDir the dir that has the snapshots * @param num the number of snapshots to keep * @throws IOException */ public static void purge(File dataDir, File snapDir, int num) throws IOException { if (num < 3) { throw new IllegalArgumentException(COUNT_ERR_MSG); } FileTxnSnapLog txnLog = new FileTxnSnapLog(dataDir, snapDir); List<File> snaps = txnLog.findNRecentSnapshots(num); retainNRecentSnapshots(txnLog, snaps); }
先获取日志文件和快照,然后调用retainNRecentSnapshots方法处理:
static void retainNRecentSnapshots(FileTxnSnapLog txnLog, List<File> snaps) { // found any valid recent snapshots? if (snaps.size() == 0) return; File snapShot = snaps.get(snaps.size() -1); final long leastZxidToBeRetain = Util.getZxidFromName( snapShot.getName(), PREFIX_SNAPSHOT); class MyFileFilter implements FileFilter{ private final String prefix; MyFileFilter(String prefix){ this.prefix=prefix; } public boolean accept(File f){ if(!f.getName().startsWith(prefix + ".")) return false; long fZxid = Util.getZxidFromName(f.getName(), prefix); if (fZxid >= leastZxidToBeRetain) { return false; } return true; } } // add all non-excluded log files List<File> files = new ArrayList<File>(Arrays.asList(txnLog .getDataDir().listFiles(new MyFileFilter(PREFIX_LOG)))); // add all non-excluded snapshot files to the deletion list files.addAll(Arrays.asList(txnLog.getSnapDir().listFiles( new MyFileFilter(PREFIX_SNAPSHOT)))); // remove the old files for(File f: files) { System.out.println("Removing file: "+ DateFormat.getDateTimeInstance().format(f.lastModified())+ "\t"+f.getPath()); if(!f.delete()){ System.err.println("Failed to remove "+f.getPath()); } } }
3. 启动zookeeper 服务器
3.1 启动单机
/* * Start up the ZooKeeper server. * * @param args the configfile or the port datadir [ticktime] */ public static void main(String[] args) { ZooKeeperServerMain main = new ZooKeeperServerMain(); try { main.initializeAndRun(args); } catch (IllegalArgumentException e) { LOG.error("Invalid arguments, exiting abnormally", e); LOG.info(USAGE); System.err.println(USAGE); System.exit(2); } catch (ConfigException e) { LOG.error("Invalid config, exiting abnormally", e); System.err.println("Invalid config, exiting abnormally"); System.exit(2); } catch (DatadirException e) { LOG.error("Unable to access datadir, exiting abnormally", e); System.err.println("Unable to access datadir, exiting abnormally"); System.exit(3); } catch (AdminServerException e) { LOG.error("Unable to start AdminServer, exiting abnormally", e); System.err.println("Unable to start AdminServer, exiting abnormally"); System.exit(4); } catch (Exception e) { LOG.error("Unexpected exception, exiting abnormally", e); System.exit(1); } LOG.info("Exiting normally"); System.exit(0); }
调用方法:
protected void initializeAndRun(String[] args) throws ConfigException, IOException, AdminServerException { try { ManagedUtil.registerLog4jMBeans(); } catch (JMException e) { LOG.warn("Unable to register log4j JMX control", e); } ServerConfig config = new ServerConfig(); if (args.length == 1) { config.parse(args[0]); } else { config.parse(args); } runFromConfig(config); }
启动过程:
/** * Run from a ServerConfig. * @param config ServerConfig to use. * @throws IOException * @throws AdminServerException */ public void runFromConfig(ServerConfig config) throws IOException, AdminServerException { LOG.info("Starting server"); FileTxnSnapLog txnLog = null; try { // Note that this thread isn't going to be doing anything else, // so rather than spawning another thread, we will just call // run() in this thread. // create a file logger url from the command line args txnLog = new FileTxnSnapLog(config.dataLogDir, config.dataDir); ZooKeeperServer zkServer = new ZooKeeperServer( txnLog, config.tickTime, config.minSessionTimeout, config.maxSessionTimeout, null); // Start Admin server adminServer = AdminServerFactory.createAdminServer(); adminServer.setZooKeeperServer(zkServer); adminServer.start(); boolean needStartZKServer = true; if (config.getClientPortAddress() != null) { cnxnFactory = ServerCnxnFactory.createFactory(); cnxnFactory.configure(config.getClientPortAddress(), config.getMaxClientCnxns(), false); cnxnFactory.startup(zkServer); // zkServer has been started. So we don't need to start it again in secureCnxnFactory. needStartZKServer = false; } if (config.getSecureClientPortAddress() != null) { secureCnxnFactory = ServerCnxnFactory.createFactory(); secureCnxnFactory.configure(config.getSecureClientPortAddress(), config.getMaxClientCnxns(), true); secureCnxnFactory.startup(zkServer, needStartZKServer); } containerManager = new ContainerManager(zkServer.getZKDatabase(), zkServer.firstProcessor, Integer.getInteger("znode.container.checkIntervalMs", (int) TimeUnit.MINUTES.toMillis(1)), Integer.getInteger("znode.container.maxPerMinute", 10000) ); containerManager.start(); if (cnxnFactory != null) { cnxnFactory.join(); } if (secureCnxnFactory != null) { secureCnxnFactory.join(); } if (zkServer.isRunning()) { zkServer.shutdown(); } } catch (InterruptedException e) { // warn, but generally this is ok LOG.warn("Server interrupted", e); } finally { if (txnLog != null) { txnLog.close(); } } }
cnxnFactory.startup(zkServer);[NettyServerCnxnFactory]
@Override public void startup(ZooKeeperServer zks, boolean startServer) throws IOException, InterruptedException { start(); setZooKeeperServer(zks); if (startServer) { zks.startdata(); zks.startup(); } }
public synchronized void startup() { if (sessionTracker == null) { createSessionTracker(); } startSessionTracker(); setupRequestProcessors(); registerJMX(); state = State.RUNNING; notifyAll(); } protected void setupRequestProcessors() { RequestProcessor finalProcessor = new FinalRequestProcessor(this); RequestProcessor syncProcessor = new SyncRequestProcessor(this, finalProcessor); ((SyncRequestProcessor)syncProcessor).start(); firstProcessor = new PrepRequestProcessor(this, syncProcessor); ((PrepRequestProcessor)firstProcessor).start(); }
3.2 集群启动
public void runFromConfig(QuorumPeerConfig config) throws IOException, AdminServerException { try { ManagedUtil.registerLog4jMBeans(); } catch (JMException e) { LOG.warn("Unable to register log4j JMX control", e); } LOG.info("Starting quorum peer"); try { ServerCnxnFactory cnxnFactory = null; ServerCnxnFactory secureCnxnFactory = null; if (config.getClientPortAddress() != null) { cnxnFactory = ServerCnxnFactory.createFactory(); cnxnFactory.configure(config.getClientPortAddress(), config.getMaxClientCnxns(), false); } if (config.getSecureClientPortAddress() != null) { secureCnxnFactory = ServerCnxnFactory.createFactory(); secureCnxnFactory.configure(config.getSecureClientPortAddress(), config.getMaxClientCnxns(), true); } quorumPeer = new QuorumPeer(); quorumPeer.setTxnFactory(new FileTxnSnapLog( config.getDataLogDir(), config.getDataDir())); quorumPeer.enableLocalSessions(config.areLocalSessionsEnabled()); quorumPeer.enableLocalSessionsUpgrading( config.isLocalSessionsUpgradingEnabled()); //quorumPeer.setQuorumPeers(config.getAllMembers()); quorumPeer.setElectionType(config.getElectionAlg()); quorumPeer.setMyid(config.getServerId()); quorumPeer.setTickTime(config.getTickTime()); quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout()); quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout()); quorumPeer.setInitLimit(config.getInitLimit()); quorumPeer.setSyncLimit(config.getSyncLimit()); quorumPeer.setConfigFileName(config.getConfigFilename()); quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory())); quorumPeer.setQuorumVerifier(config.getQuorumVerifier(), false); if (config.getLastSeenQuorumVerifier()!=null) { quorumPeer.setLastSeenQuorumVerifier(config.getLastSeenQuorumVerifier(), false); } quorumPeer.initConfigInZKDatabase(); quorumPeer.setCnxnFactory(cnxnFactory); quorumPeer.setSecureCnxnFactory(secureCnxnFactory); quorumPeer.setLearnerType(config.getPeerType()); quorumPeer.setSyncEnabled(config.getSyncEnabled()); quorumPeer.setQuorumListenOnAllIPs(config.getQuorumListenOnAllIPs()); quorumPeer.start(); quorumPeer.join(); } catch (InterruptedException e) { // warn, but generally this is ok LOG.warn("Quorum Peer interrupted", e); } }
从上述代码可以看出,QuorumPeer的start()方法和join()方法是主流程。
QuorumPeer继承了ZooKeeperThread,ZooKeeperThread继承自Thread,故QuorumPeer间接继承了Thread。
@Override public synchronized void start() { if (!getView().containsKey(myid)) { throw new RuntimeException("My id " + myid + " not in the peer list"); } loadDataBase(); startServerCnxnFactory(); try { adminServer.start(); } catch (AdminServerException e) { LOG.warn("Problem starting AdminServer", e); System.out.println(e); } startLeaderElection(); super.start(); }
3.2.1. 启动时先从内存数据库中恢复数据
private void loadDataBase() { try { zkDb.loadDataBase(); // load the epochs long lastProcessedZxid = zkDb.getDataTree().lastProcessedZxid; long epochOfZxid = ZxidUtils.getEpochFromZxid(lastProcessedZxid); try { currentEpoch = readLongFromFile(CURRENT_EPOCH_FILENAME); } catch(FileNotFoundException e) { // pick a reasonable epoch number // this should only happen once when moving to a // new code version currentEpoch = epochOfZxid; LOG.info(CURRENT_EPOCH_FILENAME + " not found! Creating with a reasonable default of {}. This should only happen when you are upgrading your installation", currentEpoch); writeLongToFile(CURRENT_EPOCH_FILENAME, currentEpoch); } if (epochOfZxid > currentEpoch) { throw new IOException("The current epoch, " + ZxidUtils.zxidToString(currentEpoch) + ", is older than the last zxid, " + lastProcessedZxid); } try { acceptedEpoch = readLongFromFile(ACCEPTED_EPOCH_FILENAME); } catch(FileNotFoundException e) { // pick a reasonable epoch number // this should only happen once when moving to a // new code version acceptedEpoch = epochOfZxid; LOG.info(ACCEPTED_EPOCH_FILENAME + " not found! Creating with a reasonable default of {}. This should only happen when you are upgrading your installation", acceptedEpoch); writeLongToFile(ACCEPTED_EPOCH_FILENAME, acceptedEpoch); } if (acceptedEpoch < currentEpoch) { throw new IOException("The accepted epoch, " + ZxidUtils.zxidToString(acceptedEpoch) + " is less than the current epoch, " + ZxidUtils.zxidToString(currentEpoch)); } } catch(IOException ie) { LOG.error("Unable to load database on disk", ie); throw new RuntimeException("Unable to run quorum server ", ie); } }
调用
/** * load the database from the disk onto memory and also add * the transactions to the committedlog in memory. * @return the last valid zxid on disk * @throws IOException */ public long loadDataBase() throws IOException { PlayBackListener listener=new PlayBackListener(){ public void onTxnLoaded(TxnHeader hdr,Record txn){ Request r = new Request(0, hdr.getCxid(),hdr.getType(), hdr, txn, hdr.getZxid()); addCommittedProposal(r); } }; long zxid = snapLog.restore(dataTree,sessionsWithTimeouts,listener); initialized = true; return zxid; } /** * maintains a list of last <i>committedLog</i> * or so committed requests. This is used for * fast follower synchronization. * @param request committed request */ public void addCommittedProposal(Request request) { WriteLock wl = logLock.writeLock(); try { wl.lock(); if (committedLog.size() > commitLogCount) { committedLog.removeFirst(); minCommittedLog = committedLog.getFirst().packet.getZxid(); } if (committedLog.isEmpty()) { minCommittedLog = request.zxid; maxCommittedLog = request.zxid; } ByteArrayOutputStream baos = new ByteArrayOutputStream(); BinaryOutputArchive boa = BinaryOutputArchive.getArchive(baos); try { request.getHdr().serialize(boa, "hdr"); if (request.getTxn() != null) { request.getTxn().serialize(boa, "txn"); } baos.close(); } catch (IOException e) { LOG.error("This really should be impossible", e); } QuorumPacket pp = new QuorumPacket(Leader.PROPOSAL, request.zxid, baos.toByteArray(), null); Proposal p = new Proposal(); p.packet = pp; p.request = request; committedLog.add(p); maxCommittedLog = p.packet.getZxid(); } finally { wl.unlock(); } }
3.2.2 启动NettyServerCnxnFactory绑定服务
@Override public void start() { LOG.info("binding to port " + localAddress); parentChannel = bootstrap.bind(localAddress); }
3.2.3 选举算法
synchronized public void startLeaderElection() { try { if (getPeerState() == ServerState.LOOKING) { currentVote = new Vote(myid, getLastLoggedZxid(), getCurrentEpoch()); } } catch(IOException e) { RuntimeException re = new RuntimeException(e.getMessage()); re.setStackTrace(e.getStackTrace()); throw re; } // if (!getView().containsKey(myid)) { // throw new RuntimeException("My id " + myid + " not in the peer list"); //} if (electionType == 0) { try { udpSocket = new DatagramSocket(myQuorumAddr.getPort()); responder = new ResponderThread(); responder.start(); } catch (SocketException e) { throw new RuntimeException(e); } } this.electionAlg = createElectionAlgorithm(electionType); }
调用
@SuppressWarnings("deprecation")
protected Election createElectionAlgorithm(int electionAlgorithm){
Election le=null;
//TODO: use a factory rather than a switch
switch (electionAlgorithm) {
case 0:
le = new LeaderElection(this);
break;
case 1:
le = new AuthFastLeaderElection(this);
break;
case 2:
le = new AuthFastLeaderElection(this, true);
break;
case 3:
qcm = new QuorumCnxManager(this);
QuorumCnxManager.Listener listener = qcm.listener;
if(listener != null){
listener.start();
FastLeaderElection fle = new FastLeaderElection(this, qcm);
fle.start();
le = fle;
} else {
LOG.error("Null listener when initializing cnx manager");
}
break;
default:
assert false;
}
return le;
}
调用选举方法:
/** * Starts a new round of leader election. Whenever our QuorumPeer * changes its state to LOOKING, this method is invoked, and it * sends notifications to all other peers. */ public Vote lookForLeader() throws InterruptedException { try { self.jmxLeaderElectionBean = new LeaderElectionBean(); MBeanRegistry.getInstance().register( self.jmxLeaderElectionBean, self.jmxLocalPeerBean); } catch (Exception e) { LOG.warn("Failed to register with JMX", e); self.jmxLeaderElectionBean = null; } if (self.start_fle == 0) { self.start_fle = Time.currentElapsedTime(); } try { HashMap<Long, Vote> recvset = new HashMap<Long, Vote>(); HashMap<Long, Vote> outofelection = new HashMap<Long, Vote>(); int notTimeout = finalizeWait; synchronized(this){ logicalclock.incrementAndGet(); updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch()); } LOG.info("New election. My id = " + self.getId() + ", proposed zxid=0x" + Long.toHexString(proposedZxid)); sendNotifications(); /* * Loop in which we exchange notifications until we find a leader */ while ((self.getPeerState() == ServerState.LOOKING) && (!stop)){ /* * Remove next notification from queue, times out after 2 times * the termination time */ Notification n = recvqueue.poll(notTimeout, TimeUnit.MILLISECONDS); /* * Sends more notifications if haven't received enough. * Otherwise processes new notification. */ if(n == null){ if(manager.haveDelivered()){ sendNotifications(); } else { manager.connectAll(); } /* * Exponential backoff */ int tmpTimeOut = notTimeout*2; notTimeout = (tmpTimeOut < maxNotificationInterval? tmpTimeOut : maxNotificationInterval); LOG.info("Notification time out: " + notTimeout); } else if (self.getCurrentAndNextConfigVoters().contains(n.sid)) { /* * Only proceed if the vote comes from a replica in the current or next * voting view. */ switch (n.state) { case LOOKING: // If notification > current, replace and send messages out if (n.electionEpoch > logicalclock.get()) { logicalclock.set(n.electionEpoch); recvset.clear(); if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) { updateProposal(n.leader, n.zxid, n.peerEpoch); } else { updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch()); } sendNotifications(); } else if (n.electionEpoch < logicalclock.get()) { if(LOG.isDebugEnabled()){ LOG.debug("Notification election epoch is smaller than logicalclock. n.electionEpoch = 0x" + Long.toHexString(n.electionEpoch) + ", logicalclock=0x" + Long.toHexString(logicalclock.get())); } break; } else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) { updateProposal(n.leader, n.zxid, n.peerEpoch); sendNotifications(); } if(LOG.isDebugEnabled()){ LOG.debug("Adding vote: from=" + n.sid + ", proposed leader=" + n.leader + ", proposed zxid=0x" + Long.toHexString(n.zxid) + ", proposed election epoch=0x" + Long.toHexString(n.electionEpoch)); } recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch)); if (termPredicate(recvset, new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch))) { // Verify if there is any change in the proposed leader while((n = recvqueue.poll(finalizeWait, TimeUnit.MILLISECONDS)) != null){ if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)){ recvqueue.put(n); break; } } /* * This predicate is true once we don't read any new * relevant message from the reception queue */ if (n == null) { self.setPeerState((proposedLeader == self.getId()) ? ServerState.LEADING: learningState()); Vote endVote = new Vote(proposedLeader, proposedZxid, proposedEpoch); leaveInstance(endVote); return endVote; } } break; case OBSERVING: LOG.debug("Notification from observer: " + n.sid); break; case FOLLOWING: case LEADING: /* * Consider all notifications from the same epoch * together. */ if(n.electionEpoch == logicalclock.get()){ recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch)); if(termPredicate(recvset, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state)) && checkLeader(outofelection, n.leader, n.electionEpoch)) { self.setPeerState((n.leader == self.getId()) ? ServerState.LEADING: learningState()); Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch); leaveInstance(endVote); return endVote; } } /* * Before joining an established ensemble, verify that * a majority are following the same leader. * Only peer epoch is used to check that the votes come * from the same ensemble. This is because there is at * least one corner case in which the ensemble can be * created with inconsistent zxid and election epoch * info. However, given that only one ensemble can be * running at a single point in time and that each * epoch is used only once, using only the epoch to * compare the votes is sufficient. * * @see https://issues.apache.org/jira/browse/ZOOKEEPER-1732 */ outofelection.put(n.sid, new Vote(n.leader, IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state)); if (termPredicate(outofelection, new Vote(n.leader, IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state)) && checkLeader(outofelection, n.leader, IGNOREVALUE)) { synchronized(this){ logicalclock.set(n.electionEpoch); self.setPeerState((n.leader == self.getId()) ? ServerState.LEADING: learningState()); } Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch); leaveInstance(endVote); return endVote; } break; default: LOG.warn("Notification state unrecoginized: " + n.state + " (n.state), " + n.sid + " (n.sid)"); break; } } else { LOG.warn("Ignoring notification from non-cluster member " + n.sid); } } return null; } finally { try { if(self.jmxLeaderElectionBean != null){ MBeanRegistry.getInstance().unregister( self.jmxLeaderElectionBean); } } catch (Exception e) { LOG.warn("Failed to unregister with JMX", e); } self.jmxLeaderElectionBean = null; } }
4. 小结
本文先介绍了zookeeper开源分布式协作系统及其特点、应用场景,然后根据zookeeper的启动方式,找到zookeeper的入口。在入口方法中,单机启动使用ZooKeeperServerMain,最终调用ZookeeperServer的startup()方法来RequestProcessor;集群启动时调用QuorumPeer的start方法,接着也是调用ZookeeperServer的startup()方法来RequestProcessor,最后调用选举算法选出leader。
参考文献:
【1】http://zookeeper.apache.org/doc/r3.4.6/zookeeperOver.html
【2】http://zookeeper.apache.org/doc/r3.4.6/zookeeperStarted.html