Scala连接Mysql数据库和Sqlserver数据库
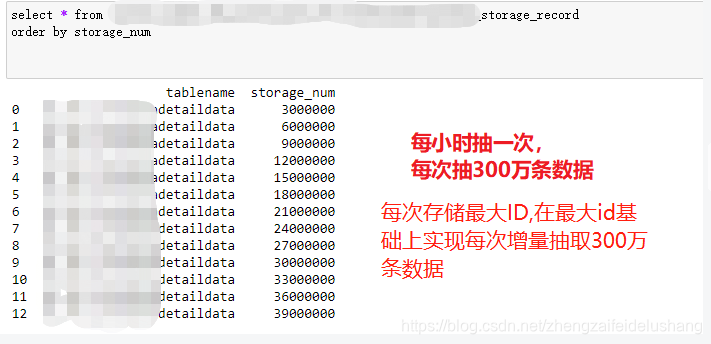
Mysql和Sqlserver源数据库单表数据量超过200G,现在需要把数据搬运到HDFS上存储,释放源数据库存储空间。这里采用Scala开发Spark程序,按照索引ID增量抽取数据插入到hive数据库中,计划每次增量抽取300万条数据,并且每次存储最大ID到一张记录表中。下次抽取的时候首先获取记录表中的最大ID作为数据抽取的起始ID,起始ID加300万与源数据库表中的最大ID进行比较,如果小于源数据库表中最大ID,则起始ID加300万的值作为数据抽取结束ID,如果大于源数据库表中最大ID,则取源数据库表中最大ID为数据抽取结束ID。
如下图所示:
每次抽取300万条数据,并且每次存储最大ID到一张记录表中,在最大ID基础上实现每次增量抽取300万条数据到Hive数据库表中。
下面详细记录了Scala连接Mysql数据库和Sqlserver数据库,增量抽取数据存储到Hive数据库的代码。连接Mysql数据库采取了单线程抽取数据,连接Sql