探索环境
让我们从选择一个环境和理解Gym界面开始。您可能已经熟悉了前面章节中用于创建Gym环境的基本函数调用,在前面的章节中,我们使用这些函数调用来测试我们的安装。在这里,我们将正式地进行一遍。
现在我们可以使用gym.make方法从可用的环境列表中创建一个环境。您可能会问如何找到系统上可用的Gym环境列表。我们将创建一个小的实用程序脚本来生成环境列表,以便您以后需要时可以引用它。让我们在~/rl_gym_book/ch4目录下创建一个名为list_gym_envs.py的脚本,包含以下内容:
from gym import envs
env_names = [spec.id for spec in envs.registry.all()]
for name in sorted(env_names):
print(name)
这个脚本将按照字母顺序打印Gym安装中可用的所有环境的名称。您可以使用以下命令运行这个脚本,查看系统中已安装和可用环境的名称。
您将得到这样的输出。注意,其中只显示了前几个环境名。

命名法
在环境名称中出现ram一词意味着环境返回的观察结果是Atari主机的随机访问内存(RAM,Random Access Memory)的内容,游戏就是在这个主机上运行的。
环境名称中出现“确定性”一词意味着代理发送给环境的动作在确定的/固定的四帧时间内重复执行,然后返回结果状态。
单词NoFrameskip的存在意味着代理发送给环境的操作只执行一次,并立即返回结果状态,其间不跳过任何帧。
默认情况下,如果环境名中不包含确定性和NoFrameskip,发送到环境的动作将重复执行n帧,其中n从{2,3,4}中统一采样。
环境名称中的字母v后跟一个数字表示该环境的版本。这是为了确保对环境实现的任何更改都反映在其名称中,以便环境中一个算法/代理获得的结果可以与另一个算法/代理获得的结果相比较,而不会有任何差异。
- Alien-ram-v0:观察是雅达利机器的RAM内容,总大小为128字节,发送给环境的动作重复执行n帧,其中n从{2,3,4}中均匀采样。
- Alien-ram-v4:观察是雅达利机器的RAM内容的总大小为128字节和动作发送到重复执行Alien-ram-v4环境,持续n帧,其中n从{2,3,4}中均匀采样。与v0相比,环境中有一些修改。
- Alien- ramDeterministic-v0:观察是雅达利机器的RAM内容,总大小为128字节,发送给环境的动作在四帧的持续时间内重复执行。
- Alien- ramNoFrameskip-v0:观察是雅达利机器的RAM内容,总大小为128字节,发送给环境的动作被应用,结果状态立即返回,不会跳过任何帧。
本文的概述应该有助于您理解环境的命名法,它一般适用于所有环境。RAM可能是特定于雅达利环境的,但是现在您已经知道当您看到几个相关的环境名时会发生什么。
探索Gym环境
为了便于我们可视化环境的样子或它的任务是什么,我们将使用一个简单的脚本,它可以启动任何环境,并使用一些随机采样的操作逐步执行该环境。你可以从本书的代码库ch4下下载这个脚本,或者在~/rl_gym_book/ch4下创建一个名为run_gym_env.py的文件,包含以下内容:
import gym
import sys
def run_gym_env(argv):
env = gym.make(argv[1]) # Name of the environment supplied as 1st argument
env.reset()
for _ in range(int(argv[2])): # Number of steps to be run supplied as 2nd argument
env.render()
env.step(env.action_space.sample())
env.close()
if __name__ == "__main__":
run_gym_env(sys.argv)
该脚本将使用提供的环境名称作为第一个命令行参数和要运行的步骤数。例如,我们可以这样运行脚本:
:~/rl_gym_book/ch4$python run_gym_env.py Alien-ram-v0 2000
该命令将启动Alien-ram-v0环境,并使用从环境的操作空间中采样的随机操作对其执行2000次步进操作。
你会看到一个弹出的带有Alien-ram-v0环境的窗口,像这样:
理解Gym接口
让我们通过理解Gym环境和我们将要开发的因素之间的界面来继续我们的Gym探索。为了帮助我们,让我们再看一遍我们在第二章《强化学习和深度强化学习》中看到的图片,当时我们在讨论强化学习的基础知识:
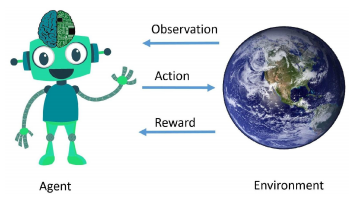
这张图片是否让你了解了代理和环境之间的界面?我们将通过浏览接口的描述来确保您的理解。
import gym之后,我们使用下面的代码创建一个环境:
env = gym.make("ENVIRONMENT_NAME")
在这里,ENVIRONMENT_NAME是我们想要的环境的名称,从系统上安装的环境列表中选择。从前面的图中,我们可以看到第一个箭头来自环境到代理,它被命名为观察。第二章,强化学习和深度强化学习,我们了解了部分可观察环境和完全可观察环境之间的区别,以及每种情况下状态和观察之间的区别。我们通过调用env.reset()从环境中获得第一个观察结果。让我们使用以下代码将观察结果存储在一个名为obs的变量中:
obs = env.reset()
现在,代理已经收到了观察结果(第一个箭头的结尾)。现在该让代理采取一个操作并将该操作发送到环境以查看发生了什么。本质上,这就是我们为代理开发的算法应该解决的问题!在接下来的章节中,我们将开发各种最先进的算法来开发代理。让我们继续理解Gym界面的旅程。
一旦决定了要采取的行动,我们就使用env.step()方法将它发送到环境(图中的第二个箭头),该方法将按照以下顺序返回4个值:next_state、reward、done和info:
- next_state是在前一个状态下执行操作后环境的结果状态
- reward(图中的第三个箭头)由环境返回。
- done变量是一个布尔值(true或false),如果情节已经结束/结束(因此,是时候重置环境了),则该变量的值为true,否则为false。这将有助于代理知道某个事件何时结束,或者环境何时将被重置为某种初始状态。
- 返回的info变量是一个可选变量,一些环境可能会返回一些附加信息。通常,代理不会使用它来决定采取哪个操作。
让我们把所有的部分放在一起,在一个地方看看:
import gym env = gym.make("ENVIRONMENT_NAME")
obs = env.reset() # The first arrow in the picture
# Inner loop (roll out)
action = agent.choose_action(obs) # The second arrow in the picture
next_state, reward, done, info = env.step(action) # The third arrow (and more)
obs = next_state
# Repeat Inner loop (roll out)
我希望你们对环境和agent之间相互作用的一个循环有了很好的理解。这个过程将不断重复,直到我们决定在经过一定数量的集或步骤后终止循环。现在让我们看一个完整的例子,在一个Qbert-v0环境中,内部循环运行MAX_STEPS_PER_EPISODE,外部循环运行MAX_NUM_EPISODES:
import gym
env = gym.make("Qbert-v0")
MAX_NUM_EPISODES = 10
MAX_STEPS_PER_EPISODE = 500
for episode in range(MAX_NUM_EPISODES):
obs = env.reset()
for step in range(MAX_STEPS_PER_EPISODE):
env.render()
action = env.action_space.sample()# Sample random action. This will be replaced by our agent's action when we start developing the agent algorithms
next_state, reward, done, info = env.step(action) # Send the action to the environment and receive the next_state, reward and whether done or not
obs = next_state
if done is True:
print("\n Episode #{} ended in {} steps.".format(episode, step+1))
break
当你运行这个脚本时,你会注意到一个Qbert屏幕弹出,Qbert采取随机行动并获得分数,如下所示:

您还将在控制台上看到如下打印语句,这取决于事件结束的时间。注意,你得到的步骤数可能不同,因为动作是随机的:

总结
在本章中,我们探索了在前一章中安装的系统上可用的Gym环境列表,然后理解了这些环境的命名惯例或命名法。然后,我们重新访问了代理-环境交互关系(RL循环)图,并理解了Gym环境如何提供与我们在图中看到的每个箭头对应的接口。然后,我们以易于理解的表格形式查看了Gym环境的step()方法返回的四个值的汇总摘要,以加强您对它们含义的理解!我们还详细探讨了用于体育馆观察和行动空间的各种类型的空间,并使用脚本打印出环境使用的空间,以更好地了解体育馆环境界面。在我们的下一章,我们将巩固到目前为止所有的学习,开发我们的第一个人工智能代理!兴奋呢? !现在翻到下一章。