一、概述
Redis持久化就是将内存数据保存到硬盘,Redis持久化存储分为AOF和RDB两种模式,默认开启RDB。
二、RDB持久化
RDB是在某个时间点将数据写入一个临时文件dump.rdb,持久化结束后,用这个临时文件替换上次持久化的文件,达到数据恢复,采用二进制文件形式进行存储。
2.1 特点
1)优点
- 使用单独子进程进行持久化,主进程不会进行任何IO操作,保证了redis的高性能。
2)缺点
- RDB是间隔一段时间进行持久化,如果持久化期间redis发生故障,会发生数据丢失。
通过上述两个特点的描述,我们可以知道RDB持久化方式适合在数据要求不严谨的情况下使用。
执行数据写入到临时文件的时间点是可以通过配置来确定的,通过配置redis在n秒内如果超过m个key被修改就执行一次RDB操作。这个操作类似于在这个时间点来保存一次redis的所有数据,一次快照数据。所以,该持久化方法也叫做snapshots。
2.2 开启方式
RDB默认开启,redis.conf中的配置参数如下:
#dbfilename:持久化数据存储在本地的文件
dbfilename dump.rdb
#dir:持久化数据存储在本地的路径,如果是在/redis/redis-3.0.6/src下启动的redis-cli,则数据会存储在当前src目录下
dir ./
##snapshot触发的时机,save
##如900秒后,至少有一个变更操作,才会snapshot
##对于此值的设置,需要谨慎,评估系统的变更操作密集程度
##可以通过"save """来关闭snapshot功能
#save时间,以下分别表示更改了1个key时间隔900s进行持久化存储;更改了10个key300s进行存储;更改10000个key60s进行存储。
save 900 1
save 300 10
save 60 10000
##当snapshot时出现错误无法继续时,是否阻塞客户端"变更操作","错误"可能因为磁盘已满/磁盘故障/OS级别异常等
stop-writes-on-bgsave-error yes
##是否启用rdb文件压缩,默认为"yes",压缩往往意味着"额外的cpu消耗",同时也意味这较小的文件尺寸以及较短的网络传输时间
rdbcompression yes
其中save 900 1的含义是:当时间到900秒时,如果redis数据发生了至少1次变化,则执行bgsave;save 300 10和save 60 10000同理。当三个save条件满足任意一个时,都会引起bgsave的调用。
2.3 save m n的实现原理
Redis的save m n,是通过serverCron函数、dirty计数器、和lastsave时间戳来实现的。
serverCron是Redis服务器的周期性操作函数,默认每隔100ms执行一次;该函数对服务器的状态进行维护,其中一项工作就是检查 save m n 配置的条件是否满足,如果满足就执行bgsave。
dirty计数器是Redis服务器维持的一个状态,记录了上一次执行bgsave/save命令后,服务器状态进行了多少次修改(包括增删改);而当save/bgsave执行完成后,会将dirty重新置为0。
例如,如果Redis执行了set mykey helloworld,则dirty值会+1;如果执行了sadd myset v1 v2 v3,则dirty值会+3;注意dirty记录的是服务器进行了多少次修改,而不是客户端执行了多少修改数据的命令。
lastsave时间戳也是Redis服务器维持的一个状态,记录的是上一次成功执行save/bgsave的时间。
save m n的原理如下:每隔100ms,执行serverCron函数;在serverCron函数中,遍历save m n配置的保存条件,只要有一个条件满足,就进行bgsave。对于每一个save m n条件,只有下面两条同时满足时才算满足:
(1)当前时间-lastsave > m
(2)dirty >= n
2.4 bgsave执行流程
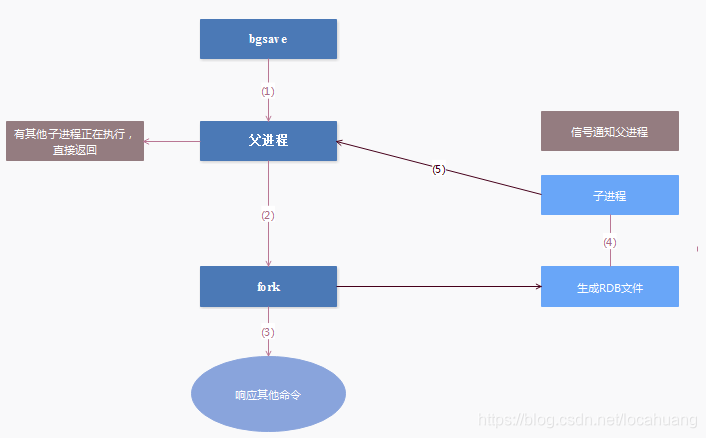
步骤解析
(1) Redis父进程首先判断:当前是否在执行save,或bgsave/bgrewriteaof的子进程,如果在执行则bgsave命令直接返回。bgsave/bgrewriteaof 的子进程不能同时执行,主要是基于性能方面的考虑:两个并发的子进程同时执行大量的磁盘写操作,可能引起严重的性能问题。
(2) 父进程执行fork操作创建子进程,这个过程中父进程是阻塞的,Redis不能执行来自客户端的任何命令。
(3) 父进程fork后,bgsave命令返回”Background saving started”信息并不再阻塞父进程,并可以响应其他命令。
(4) 子进程创建RDB文件,根据父进程内存快照生成临时快照文件,完成后对原有文件进行原子替换。
(5) 子进程发送信号给父进程表示完成,父进程更新统计信息。
注意:使用RDB模式,以下两种关闭模式影响不同
1)如果直接shutdown redis-cli,那么在关闭后更新一次dump.rdb,因为内存中还存在redis进程,在关闭时会自动备份;
2)但如果直接杀死进程或直接关机,则redis不会更新dump.rdb,因为redis已从内存中消失。
三、AOF持久化
AOF(Append-only file),将"操作+数据"以格式化指令的方式追加到操作日志文件的尾部,在append操作返回后(已经写入到文件或者即将写入),才进行实际的数据变更,“日志文件”保存了历史所有的操作过程;当server需要数据恢复时,可以直接replay此日志文件,即可还原所有的操作过程。
AOF相对可靠,它和mysql中bin.log、apache.log、zookeeper中txn-log异曲同工。AOF文件内容是字符串,非常容易阅读和解析。
3.1 特点
1)优点
- 可以支持更高的数据完整性。如果设置追加file的时间是1s,如果redis发生故障,最多丢失1s钟的数据;且如果日志写入不完整,支持redis-check-aof来进行日志修复;aof文件没被rewrite之前(文件过大时会对命令进行合并重写),可以删除其中的某些命令(比如误操作的flushall)。
2)缺点
- AOF文件比RDB文件大,且恢复速度慢。
我们可以简单的认为:
- AOF文件就是日志文件,此文件只记录“变更操作”(如set、del等)
- 如果server中持续大量的变更操作,将会导致AOF文件非常大,意味着server失效后,数据恢复的过程会很长。
- 事实上,一条数据经过多次变更,将会产生多条AOF记录,其实只要保存当前的状态,历史的操作记录是可以抛弃的,因为AOF持久化还伴生了“AOF rewrite”。
AOF的特性决定了它相对比较安全,如果期望数据丢失更少,可以采用高AOF模式。如果AOF文件正在被写入时突然server失效,有可能导致文件的最后一次记录不完整,我们可以通过手工或程序的方式检测并修正不完整的记录,以便通过aof文件恢复能够正常;同事需要提醒,如果你的redis持久化手段中有AOF,那么在server故障失效后再次启动前,需要检测AOF文件的完整性。
3.2 开启方式
AOF默认关闭,可以通过修改redis.conf配置文件进行开启
##此选项为aof功能的开关,默认为"no",可以通过"yes"来开启aof功能
##只有在"yes"下,aof重写/文件同步等特性才会生效
appendonly yes
##指定aof文件名称
appendfilename appendonly.aof
##指定aof操作中文件同步策略,有三个合法值:always everysec no,默认为everysec
appendfsync everysec
##在aof-rewrite期间,appendfsync是否暂缓文件同步,"no"表示"不暂缓","yes"表示"暂缓",默认为"no"
no-appendfsync-on-rewrite no
##aof文件rewrite触发的最小文件尺寸(mb,gb),只有大于此aof文件大于此尺寸是才会触发rewrite,默认"64mb",建议"512mb"
auto-aof-rewrite-min-size 64mb
##相对于"上一次"rewrite,本次rewrite触发时aof文件应该增长的百分比。
##每一次rewrite之后,redis都会记录下此时"新aof"文件的大小(例如A),那么当aof文件增长到A*(1 + p)之后
##触发下一次rewrite,每一次aof记录的添加,都会检测当前aof文件的尺寸。
auto-aof-rewrite-percentage 100
一些属性说明
AOF是文件操作,对于变更操作比较密集的server,将会造成磁盘IO的负荷加重。此外linux对文件操作采取了“延迟写入”手段,并非每次write操作都会触发实际硬盘操作,而是进入了buffer中,当buffer数据达到阀值时触发实际写入(也有其他时机),这是linux对文件系统的优化,但同时也带了隐患,如果buffer没有刷新到磁盘,物理机失效(如断电),有可能导致最后一条或多条aof记录丢失。
通过上面配置文件,我们得知redis提供了3种aof记录同步选项:
- always:每一条aof记录都立即同步到文件,这是最安全的方式,同时也需要更多的磁盘操作和阻塞延迟,IO开销较大。
- everysec:每秒同步一次,性能和安全都比较中庸的方式,也是redis推荐的方式。如果遇到物理故障,有可能导致最近一秒内aof记录丢失(可能为部分丢失)。
- no:redis并不直接调用文件同步,而是交给操作系统来处理。操作系统可以根据buffer 填充情况 / 通道空闲时间等择机触发同步;这是一种普通的文件操作方式。性能较好,在物理服务器故障时,数据丢失量会因 OS 配置有关。
AOF 文件会不断增大,它的大小直接影响“故障恢复”的时间, 而且 AOF 文件中历史操作是可以丢弃的。
AOF rewrite 操作就是“压缩”AOF 文件的过程,当然 redis 并没有采用“基于原 aof 文件”来重写的方式,而是采取了类似 snapshot 的方式:基于 copy-on-write,全量遍历内存中数据,然后逐个序列到 aof 文件中。
因此 AOF rewrite 能够正确反应当前内存数据的状态,这正是我们所需要的。
rewrite 过程中,对于新的变更操作将仍然被写入到原 AOF 文件中,同时这些新的变更操作也会被 redis 收集起来(buffer,copy-on-write 方式下,最极端的可能是所有的 key 都在此期间被修改,将会耗费 2 倍内存),当内存数据被全部写入到新的 aof 文件之后,收集的新的变更操作也将会一并追加到新的 aof 文件中,此后将会重命名新的 aof 文件为 appendonly.aof, 此后所有的操作都将被写入新的 aof 文件。如果在 rewrite 过程中,出现故障,将不会影响原 AOF 文件的正常工作,只有当 rewrite 完成之后才会切换文件,因为 rewrite 过程是比较可靠的。
触发 rewrite 的时机可以通过配置文件来声明,同时 redis 中可以通过 bgrewriteaof 指令人工干预。
redis-cli -h ip -p port bgrewriteaof
因为 rewrite 操作 /aof 记录同步 /snapshot 都消耗磁盘 IO,redis 采取了“schedule”策略:无论是“人工干预”还是系统触发,snapshot 和 rewrite 需要逐个被执行。
AOF rewrite 过程并不阻塞客户端请求。系统会开启一个子进程来完成。
四、RDB与AOF的区别
1)AOF更加安全,可以将数据更加及时的同步到文件中,但是AOF需要较多的磁盘IO开支,AOF文件尺寸较大,文件内容恢复数据相对较慢。
2)RDB安全性较差,它是正常时期数据备份以及master-slave数据同步最佳手段,文件尺寸较小,恢复数据较快。
选择策略
1)在架构良好的环境中,master通常使用AOF,slave使用RDB,原因是master主要首先确保数据完整性,它作为数据备份第一选择;slave提供只读服务,主要目的就是快速响应客户端read请求。
2)如果网络稳定性比较差/物理环境糟糕情况下,建议master和slave均采用AOF,在master和slave切换角色时,可以减少人工数据备份/人工引导数据恢复的时间成本。
3)如果你的环境一切非常好,且服务需要接收密集性的write操作,那么建议master采取RDB,slave采用AOF。
问:redis宕机后,redis的值会消失吗?
不会。redis默认开启RDB存储。
使用RDB持久化,只有在特定时间达到特定的修改数量,redis的值才会被持久化到dump.rdb中,但断开连接后,会自动更新【无则生成】dump.rdb,实现自动备份。需要注意的是,如果直接杀死进程或者直接关机/重启服务,数据有可能会丢失,这种情况下不会自动备份dump.rdb。