broker是kafka集群服务的主要载体,主要是持久化消息以及将消息推送到消费端,其包含内容很多,如同步机制(水印机制)、备份机制、分区机制、存储机制、kafka控制器等;
一、broker消息设计
Java内存模型(JMM)中保存对象的开销很大,可能花费比消息本身2倍的大小来保存数据,字段重排也解决该类问题,因此kafka使用JavaNIO的ByteBuffer来保存信息,同时依赖文件系统提供的页缓存而非Java的堆缓存,ByteBuffer是紧凑的二进制结构而不需要padding操作,省去很多不必要的开销,同时kafka的0.11版本后重写了消息格式;
二、集群管理
新版本的producer和consumer不再需要zk,但kafka的broker节点的自动发现和成员管理依然是zookeeper实现,在通过zkCli.sh命令行进入zk的文件树后在/brokers/ids里面可以观察到kafka的broker节点状态,get/brokers/ids/0可以得到kafka节点的加入时间和状态信息;
/brokers 保存kafka节点信息
/controller 保存kafka集群的controller节点信息
/admin 保存管理脚本的输出结果
/isr_change_notification 保存ISR列表发生变化的分区列表
/config 保存每个broker的配置
/cluster 保存集群的ID信息和版本号
/controller_epoch 保存controller的版本号,使用版本号来隔离无效的controller请求;
三、副本与ISR机制
kafka利用多副本(replication)机制来保存数据,以单个分区(partition)为单位,保存冗余的分区备份来保证数据的安全性和系统的高可用性,replication被均匀地分布在多个broker载体上,这些replication有一个leader副本,其他都是follower副本(像leader请求数据,从而保证同leader的同步);当副本所在的broker宕机,其他几个follower副本争当leader副本,那些同步进度太落后的follower没有资格竞选leader,如何判断哪些follower副本是保持同步的,这就是ISR机制(IN-sync Replicas);
每个分区都有一个ISR列表,如果kafka运行日志频繁的扩大或减少这个列表,那就表明当前分区的数据量太大,其他follower同步或多或少的出现问题,需要扩大对ISR列表的判定条件(kafka1.0后config可以配置replica.lag.time.max.ms来决定follower最多可以落下多少数据,之前是replica.lag.max.messages)。可以参考之前的博文:kafka常见异常处理
在producer角度,只有分区的所有副本都接受到数据,数据才算是“已提交”状态,当然跟acks机制有关系(producer可以自己配置),follower发起fetch请求向leader请求数据,相关的专业术语:① 起始偏移量(base offset):记录当前副本第一个offset;② 最高水印(high watermark):HW保存了当前副本最新的消息偏移量,每个副本都有HW,只有leader副本才能决定clients能看到的消息,确定了consumer能够获取到的消息上线;③ 日志尾偏移量(log and offset):副本同样维护了LEO信息,只有ISR列表中所有副本都更新了对应的LEO,leader才会向右移动HW值表明写入成功;
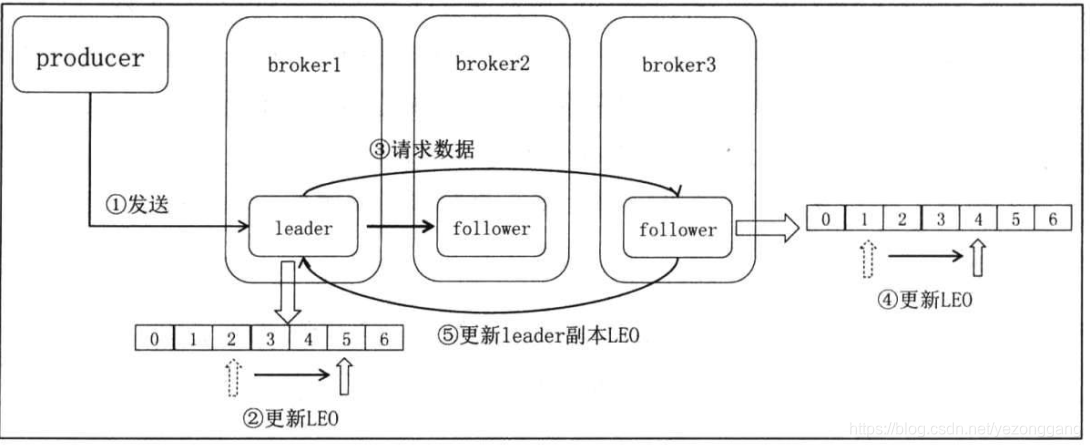
水印这个概念在spark和flink实时计算领域很熟悉,kafka的水印是数据的位置信息;高版本使用leader epoch来保持数据的不一致,源码中主要有:kafka.server.epoch.LeaderEpochCache.scala和kafka.server.checkpoints.LeaderEpochCheckpointFile类对其解释;
四、日志存储
日志即是数据,每个topic在数据目录有一个文件夹(名字是topic-分区号),也就是每个分区有自己的日志(partition log),producer可以指定要发送到的分区,每个日志由若干日志段文件+索引文件构成,.log是日志文件,.index和.timeindex是日志段对应的索引文件,而且3者的命名前缀相同,log.segment.bytes决定了log文件的大小(默认1G),log被写满一定大小就不能再追加,一个分区有一个激活日志段,其他都是写死的日志段;

index和.timeindex是日志段对应的偏移量索引和时间索引文件,索引文件由若干索引项组成,log.index.interval.bytes设置写入索引文件的大小间隔(默认4kb),所以它是稀疏的,kafka利用二分查找算法搜寻目标索引(时间复杂度是logN),索引可以极大减少查找时间和broker的CPU开销;当前索引日志是可变的,历史索引日志是只读的;
日志(包括log和索引文件)有定时清理机制,默认保存7天,broker有对应的超时时长和大小配置,日志清理线程跟数据处理线程独立,且kafka不清理当前活跃的日志段,cleaner组件负责日志的清理和压实;
五、请求通信协议
通信协议实现client-server和server-server之间数据传输的规范,kafka通信协议是基于TCP之上的二进制协议,供request和response请求的调用,clients使用类似于epoll方式在单个连接上轮询以传输数据,controller会像多个broker请求数据,clients会像多个broker请求数据;按照协议,所有的请求和响应都有固定的格式,size+request/response,请求体格式因请求类型不同而变化,请求头都是一样的,包括:api_key(请求编号),api_version(版本编号),correlation_id,client_id,响应头也是固定的包括correlation_id;

常见的请求类型有:PRODUCE请求、FETCH请求、METADATA请求;
PRODUCE请求是api_key=0的请求,实现数据的生产,clients向broker发送的生产数据请求,request包括包括事务ID + acks + timeout + topic数据,request包括[partition+error_code + base_offset + log_append_time + log_start_offset];
FETCH请求是api_key=1的请求,实现数据的消费,包括clients消费broker以及follower向leader请求数据,request格式为:replica_id +max_wait_time +min_bytes + max_bytes + isolation_level + topic,replica_id是副本的ID,如果是消费数据则是-1,min_bytes和max_bytes表示响应中包含数据的最小/大字节数,request包括topic、partition_header、真实数据集合;
METADATA是clients向broker获取topic元数据的请求,格式是topic+allow_auto_topic_creation
METADATA请求:
在clients端,
在broker端,
六、controller设计
七、broker通信机制