Spark环境搭建
编译
编译的时候只创建一个机器即可,启动app-11,在编译的时候会占用大量的资源。
1、以hadoop用户登录。
命令:su – hadoop

2、切换到tmp根目录下。
命令:cd /tmp/

3、创建编译spark目录。
命令:mkdir spark

4、创建Maven仓库。
命令:mkdir -p /home/hadoop/.m2/repository/org/spark-project

5、进入spark目录下。
命令:cd spark/

6、下载编译安装包。
命令:wget https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0.tgz

7、解压。
命令:tar -xf spark-2.4.0.tgz

8、进入spark-2.4.0目录。
命令:cd spark-2.4.0

9、删除pom.xml文件。
命令:rm -rf pom.xml

10、切换到Spark的编译目录下。
命令:cd /tmp/Spark-stack/Spark/compile/

11、将pom_hive3.xml拷贝到spark解压之后的目录下。
命令:cp pom_hive3.xml /tmp/spark/spark-2.4.0
12、将spark-project.zip解压到Maven库中。
命令:unzip /tmp/Spark-stack/Spark/compile/spark-project.zip -d /home/hadoop/.m2/repository/org/spark-project/

13、进入到spark安装目录下。
命令:cd /tmp/spark/spark-2.4.0

14、将pom_hive3.xml改名为pom.xml。
命令:mv pom_hive3.xml pom.xml

15、设置Maven的OPTS使用内存的设置。
命令:export MAVEN_OPTS="-Xmx3g -XX:ReservedCodeCacheSize=512m"

16、开始编译。
命令:./dev/make-distribution.sh --name hadoop3.1.2 --tgz -Phadoop-3.1 -Dhadoop.version=3.1.2 -Phive -Dhive.version=1.21.2.3.1.2.0-4 -Dhive.version.short=1.21.2.3.1.2.0-4 -Phive-thriftserver -Pyarn
注:时间会很长。

安装Spark
再创建另外两台机器,确保三台机器正常运行。
下载安装包
1、在app-11上进行三台机器的认证。
命令:sudo /bin/bash、cd /hadoop、 ./initHosts.sh

2、启动集群。
命令:su – hadoop、cd /hadoop/、./startAll.sh
3、检查启动集群。
命令:jps

4、创建安装Spark的目录。
命令:mkdir Spark

5、进入到编译之后的目录下。
命令:cd /tmp/spark/spark-2.4.0

6、将spark的安装包拷贝到Spark的安装目录下。
命令:cp spark-2.4.0-bin-hadoop3.1.2.tgz /hadoop/Spark/

7、进入到Spark安装目录下。
命令:cd /hadoop/Spark/

8、解压安装包。
命令:tar -xf spark-2.4.0-bin-hadoop3.1.2.tgz

9、进入Spark目录,下载配置文件。
命令:cd /tmp/Spark-stack/Spark/

10、拷贝基本配置文件。
命令:cp Bconf/* /hadoop/Spark/

11、返回Spark的安装目录下。
命令:cd /hadoop/Spark/

修改配置文件
12、进入解压之后的目录下。
命令:cd spark-2.4.0-bin-hadoop3.1.2

13、进入配置文件下。
命令:cd conf/

14、将下载下来的slaves文件拷贝到该目录下。
命令:cp /hadoop/Spark/slaves ./

15、将下载下来的spark-env.sh文件拷贝到该目录下。
命令:cp /hadoop/Spark/spark-env.sh ./

安装Scala
16、切到Spark的安装目录下。
命令:cd /hadoop/Spark/

17、下载Scala安装包。
命令:wget https://downloads.lightbend.com/scala/2.11.12/scala-2.11.12.tgz

18、返回hadoop目录。
命令:cd /hadoop/

19、创建安装Scala目录。
命令:mkdir Scala

20、将下载的Scala安装包拷贝到Scala目录下。
命令:tar -xf Spark/scala-2.11.12.tgz -C Scala/

21、给Scala赋予执行权限。
命令:chmod -R a+x /hadoop/Scala/scala-2.11.12/

修改环境变量
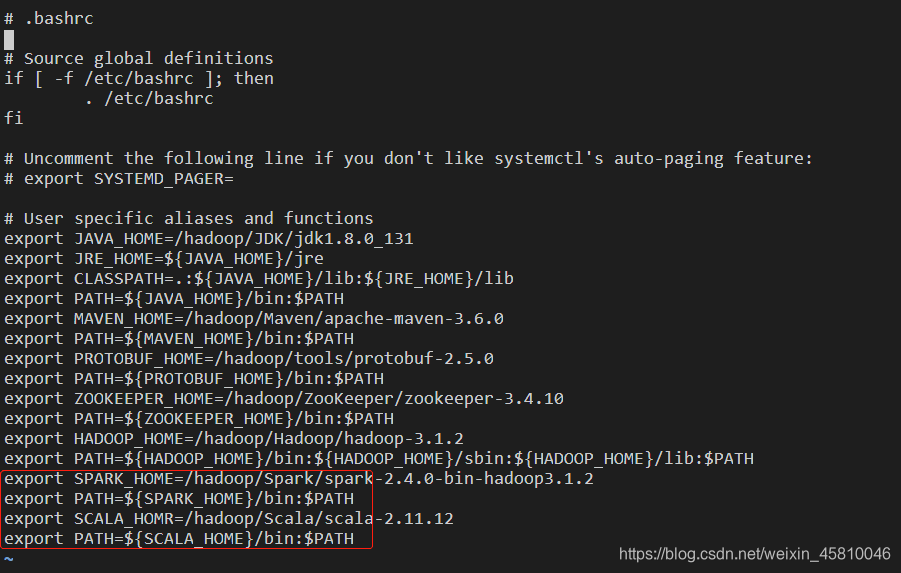
22、修改环境变量。
命令:vi ~/.bashrc
export SPARK_HOME=/hadoop/Spark/spark-2.4.0-bin-hadoop3.1.2
export PATH=${SPARK_HOME}/bin:$PATH
export SCALA_HOME=/hadoop/Scala/scala-2.11.12
export PATH=${SCALA_HOME}/bin:$PATH
23、环境变量生效。
命令:source ~/.bashrc

24、检查环境变量生效。
命令:echo $PATH

清理工作
25、进入Spark安装目录下。
命令:cd Spark/

26、删除没用的文件。
命令:rm -rf scala-2.11.12.tgz slaves spark-2.4.0-bin-hadoop3.1.2.tgz spark-env.sh

27、将config.conf拷贝到hadoop的根目录下。
命令:mv config.conf /hadoop/

拷贝到集群的其他机器上
28、切换到hadoop的根目录下。
命令:cd /hadoop/

29、将环境变量拷贝到其他机器上。
命令:scp ~/.bashrc hadoop@app-12:/hadoop/
scp ~/.bashrc hadoop@app-13:/hadoop/

30、将Spark静默拷贝到其他机器上。
命令:for name in app-12 app-13; do scp -r -q Spark $name:/hadoop/; done

31、将Scala拷贝到其他机器上。
命令:for name in app-12 app-13; do scp -r -q Scala $name:/hadoop/; done

启动集群
32、进入Spark的安装目录下。
命令:cd /hadoop/Spark/spark-2.4.0-bin-hadoop3.1.2/

33、启动集群。
命令:sbin/start-all.sh

34、检查集群。
命令:jps
注:Worker集群已经启动了。

详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
