决策树理解案例
我们在买苹果的时候可以通过苹果的颜色、硬度来判断它的好坏,再决定是否买这个苹果。那么我们也许可以基于之前买苹果的经验做出这样一个分析:

某人不太会挑苹果,所以纯粹是随机写的几条数据,假设上述几条就是我们挑苹果的真理。那么此时如果我们拿到了一个苹果,属性是(红色,硬,香),怎么判断呢?通常是一个一个属性顺序判断,先看颜色,有0、1、2三条经验符合,第二个硬,剩下0、1符合,再看香,第0条经验符合,这时候看第0条的结论是好苹果,那手里这个就是好苹果。通过对经验数据进行属性的比对来获取经验数据的结论,从而获取该判断为目前样本的判断。那么有人说,如果我手里的拿到的苹果很奇怪,经验里没有怎么办呢?比如说(绿色,软,香),在经验里并没有这条数据,那么我们还是从颜色判断,获取到了3、4、5三条经验,通过“软”筛选出来第5条,接着没有经验是香的了,那么就用最接近的也就是满足两个属性的第五条的结论来作为自己的结论,手里的这个苹果是坏苹果。
这就是决策树的模型,它通过对大量训练样本的学习去建立一个决策树,依次判断每个属性,从而判断该样本的标记。我们可以这样画个图。每次拿到一个苹果就从最顶上开始依次往下判断,最后
得出结论。可能有些同学发现我这个图好像有些地方判断完软硬度以后就不判断味道了,这是因为在经验中有几条数据只要硬度决定以后不管味道怎么样,苹果的好坏都已经确定了,也就不需要再判断了。这个图如果倒过来很像一颗大树,同时它在运行中是一个一个属性依次来决定该往哪个分支(树杈)走,所以叫做决策树。机器学习的模型通常来源于对人们生活中思维方式的模拟,在很早的时候就诞生了这种模型也就不足为怪了。

决策树数学原理

在《统计学习方法》书中对决策树的模型有一个规范的回答。最顶端的是根节点,对样本所有的预测都是从根节点开始依次判断。每个圆形的都是一个用于判断的节点,每一个节点只对属性的其中一个特征进行判断,比如说上文的苹果,圆形节点要么判断颜色,要么判断硬度等等,总之只判断其中的一个特征。在判断节点中只保存告诉你该往哪走的信息,在判断节点中并没有有关结论的信息。矩形节点就是标记节点,在判断中走到矩形就可以认为预测过程结束,将矩形中的标签作为预测结果返回。
那么在训练过程中构建这棵决策树的时候需要怎么做呢?就是一个一个特征属性依次比较过去然后建立分支吗?不是的,我们需要挑选最有代表性的特征。比如说苹果的形状,我们把形状作为一个特征,建立球形和立方体形两个分支,所有样本都会进入到球形这个分支里去,这样的判断并没有进行有效的划分,属于没有意义。除此之外很特别的特征,比如说某特征判断10个苹果,9个会进入A分支,1个进入B分支。另外有一个特征使得5个进入A分支,5个进入B分支。显然第二个特征选取得好,是一个很明显地将所有样本划分的一个特征。
在构建决策树的过程中,最重要的就是怎么选取合适的特征来构建它。如果选取不合理,可能会造成产生的决策树过于庞大,提升程序的复杂度,此外也会造成决策树的泛化性能降低。生成决策树的算法通常有ID3、C4.5、CART。
信息增益
我们想象这么一件事情,在买苹果的时候,我们是不是希望最好只需要通过一个特征就可以判断是不是好苹果。或者说,用最少的判断去得出结论。就好像下面这张图一样,如果苹果能用颜色来判断,红色就是好苹果,绿色就是坏苹果,那该多好啊。但是实际上是不可能的,谁都知道苹果只看颜色并不能分辨好坏。

这张图还可以接受,最多判断三次就可以知道苹果的好坏了。我们发现一个规律没有,就是我们每走一步,就是在确定这个苹果的好坏的过程。当我们在最顶端还没有进行判断的时候,我们对苹果的好坏是最不确定的。然后对颜色进行判断,如果是红色,我们就知道了好坏的概率可能各是1/2(因为还涉及到对软硬度的判断),我们从一点概念都没有到现在概率坍塌到1/2了,虽然还包含了对这1/2的不确定,但是我们有了一点点更清晰的判断是吗?如果苹果红色又硬呢?我们可以百分百确定这是个好苹果。从最初的没有信息,到最后的百分百确信,这是一个减少不确定性的过程。
什么是信息的不确定性?就是信息熵。我们给出信息熵的定义:


在熵H§越大时,表示信息的不确定性越大。
例如我们有10个苹果,1个好苹果,9个坏苹果,令好苹果为A,坏苹果为B,熵的计算如下:

log底数不是比如为2,信息熵的使用是从信息论中衍生过来,所以仍然保留了底数为2的习惯。事实上我们在意的是不同熵之间的大小,大小与底数的选择没有关系。可以看到10个苹果中9个事坏苹果时,信息熵为0.47。
同样,我们假设5个是好苹果,5个是坏苹果呢?
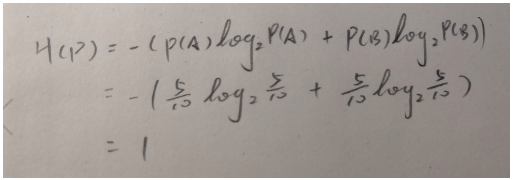
发现信息熵变成了1。在1个好苹果和9个坏苹果时,我们可以认为大部分都是坏苹果,在这10个苹果内部其实并不混乱,可以说确定性比较大(因为只有一个是好苹果)。当5比5时,里面就有点乱了,有一半是好苹果,有一半是坏苹果,你并不能太确定每个苹果是好的还是坏的,熵就大。
那么我们为什么要在决策树中提信息熵这件事呢?
上文中我们知道,当我们还没开始判断的时候,对于这个苹果的不了解程度是最高的,接下来我们对颜色进行了一次判断,是不是对苹果开始有了初步的了解了?虽然可能还不太确定它是好的还是坏的,随后我们再判断下一个特征,慢慢的慢慢的,我们走到了叶节点上,这时候我们完全确定了这个苹果的好坏。
在决策树根节点的最初,我们先假设信息熵为1,表示我们的一无所知。到叶节点时假设信息熵为0,表示非常确信。那么使用决策树决策的过程就是我们不断减少信息熵的过程,直到它降为0。那么还记得我们其中的一个愿望吗?我们多么希望能用尽可能少的判断次数就能确定苹果的好坏,放到信息熵的环境下,就是我们多希望信息熵能下降得快一点。这就涉及到决策树的构建了,我们该怎么构建才能使得这棵决策树的信息熵在判断分支中下降得最快呢?这就是信息增益。

上式是什么意思?不着急慢慢来。我们先看下面这张图。我们假设D和B是两个判断节点,它们在同一个分支中,D通过对样本特征A的值新型判断后进入了A分支。那么在D节点中我们的信息熵肯定是比较高的,令D节点中此时的信息熵是H(D)。然后经过D的一次判断,信息熵减少了,此时到了节点B,因为B节点的信息熵依靠于D对特征A的判断,所以节点B的信息熵设为H(D|A)。我们要让信息熵下降得最快,也就是他们之间的信息熵差值要最大,将这个信息熵差值设为g(D, A),汇总起来就是上图中的式子了。
决策树的生成
ID3算法
ID3算法很直观很简单。假设你有一片广茂的大农场,种了很多很多的大苹果。这个时候你就是根节点,所有的苹果都在你这。这时候你的大儿子和小儿子过来了,说“爸比,我要苹果”,那你当然得给啊。你问了问老天爷该怎么分配,自己一把老骨头了要苹果也没有用,打算全分下去。老天爷教你了一种方法叫信息增益,你按照信息增益的法子把苹果分成了D1堆和D2堆,D1给大儿子,D2给小儿子。他俩欢天喜地地把苹果拿回家了。
等大儿子回家以后,大儿子的大儿子和小儿子来了,说“爸比,我要苹果”,大儿子按照老天爷给的信息增益启示,把苹果分成E1和E2两堆,俩儿子各自给一堆。子子孙孙分下去,无穷无尽也。
好了,言归正传。在程序上来讲,首先从根节点开始,对每个特征进行遍历,假设对当前特征进行分配,计算分配后的子节点的信息熵,选择特征中信息增益最大的特征来划分数据并建立子节点。之后在子节点中递归调用该方法,子子孙孙无穷尽也。

算法实现
import time
import numpy as np
def loadData(fileName):
'''
加载文件
:param fileName:要加载的文件路径
:return: 数据集和标签集
'''
#存放数据及标记
dataArr = []; labelArr = []
#读取文件
fr = open(fileName)
#遍历文件中的每一行
for line in fr.readlines():
#获取当前行,并按“,”切割成字段放入列表中
#strip:去掉每行字符串首尾指定的字符(默认空格或换行符)
#split:按照指定的字符将字符串切割成每个字段,返回列表形式
curLine = line.strip().split(',')
#将每行中除标记外的数据放入数据集中(curLine[0]为标记信息)
#在放入的同时将原先字符串形式的数据转换为整型
#此外将数据进行了二值化处理,大于128的转换成1,小于的转换成0,方便后续计算
dataArr.append([int(int(num) > 128) for num in curLine[1:]])
#将标记信息放入标记集中
#放入的同时将标记转换为整型
labelArr.append(int(curLine[0]))
#返回数据集和标记
return dataArr, labelArr
def majorClass(labelArr):
'''
找到当前标签集中占数目最大的标签
:param labelArr: 标签集
:return: 最大的标签
'''
#建立字典,用于不同类别的标签技术
classDict = {
}
#遍历所有标签
for i in range(len(labelArr)):
#当第一次遇到A标签时,字典内还没有A标签,这时候直接幅值加1是错误的,
#所以需要判断字典中是否有该键,没有则创建,有就直接自增
if labelArr[i] in classDict.keys():
# 若在字典中存在该标签,则直接加1
classDict[labelArr[i]] += 1
else:
#若无该标签,设初值为1,表示出现了1次了
classDict[labelArr[i]] = 1
#对字典依据值进行降序排序
classSort = sorted(classDict.items(), key=lambda x: x[1], reverse=True)
#返回最大一项的标签,即占数目最多的标签
return classSort[0][0]
def calc_H_D(trainLabelArr):
'''
计算数据集D的经验熵,参考公式5.7 经验熵的计算
:param trainLabelArr:当前数据集的标签集
:return: 经验熵
'''
#初始化为0
H_D = 0
#将当前所有标签放入集合中,这样只要有的标签都会在集合中出现,且出现一次。
#遍历该集合就可以遍历所有出现过的标记并计算其Ck
#这么做有一个很重要的原因:首先假设一个背景,当前标签集中有一些标记已经没有了,比如说标签集中
#没有0(这是很正常的,说明当前分支不存在这个标签)。 式5.7中有一项Ck,那按照式中的针对不同标签k
#计算Cl和D并求和时,由于没有0,那么C0=0,此时C0/D0=0,log2(C0/D0) = log2(0),事实上0并不在log的
#定义区间内,出现了问题
#所以使用集合的方式先知道当前标签中都出现了那些标签,随后对每个标签进行计算,如果没出现的标签那一项就
#不在经验熵中出现(未参与,对经验熵无影响),保证log的计算能一直有定义
trainLabelSet = set([label for label in trainLabelArr])
#遍历每一个出现过的标签
for i in trainLabelSet:
#计算|Ck|/|D|
#trainLabelArr == i:当前标签集中为该标签的的位置
#例如a = [1, 0, 0, 1], c = (a == 1): c == [True, false, false, True]
#trainLabelArr[trainLabelArr == i]:获得为指定标签的样本
#trainLabelArr[trainLabelArr == i].size:获得为指定标签的样本的大小,即标签为i的样本
#数量,就是|Ck|
#trainLabelArr.size:整个标签集的数量(也就是样本集的数量),即|D|
p = trainLabelArr[trainLabelArr == i].size / trainLabelArr.size
#对经验熵的每一项累加求和
H_D += -1 * p * np.log2(p)
#返回经验熵
return H_D
def calcH_D_A(trainDataArr_DevFeature, trainLabelArr):
'''
计算经验条件熵
:param trainDataArr_DevFeature:切割后只有feature那列数据的数组
:param trainLabelArr: 标签集数组
:return: 经验条件熵
'''
#初始为0
H_D_A = 0
#在featue那列放入集合中,是为了根据集合中的数目知道该feature目前可取值数目是多少
trainDataSet = set([label for label in trainDataArr_DevFeature])
#对于每一个特征取值遍历计算条件经验熵的每一项
for i in trainDataSet:
#计算H(D|A)
#trainDataArr_DevFeature[trainDataArr_DevFeature == i].size / trainDataArr_DevFeature.size:|Di| / |D|
#calc_H_D(trainLabelArr[trainDataArr_DevFeature == i]):H(Di)
H_D_A += trainDataArr_DevFeature[trainDataArr_DevFeature == i].size / trainDataArr_DevFeature.size \
* calc_H_D(trainLabelArr[trainDataArr_DevFeature == i])
#返回得出的条件经验熵
return H_D_A
def calcBestFeature(trainDataList, trainLabelList):
'''
计算信息增益最大的特征
:param trainDataList: 当前数据集
:param trainLabelList: 当前标签集
:return: 信息增益最大的特征及最大信息增益值
'''
#将数据集和标签集转换为数组形式
#trainLabelArr转换后需要转置,这样在取数时方便
#例如a = np.array([1, 2, 3]); b = np.array([1, 2, 3]).T
#若不转置,a[0] = [1, 2, 3],转置后b[0] = 1, b[1] = 2
#对于标签集来说,能够很方便地取到每一位是很重要的
trainDataArr = np.array(trainDataList)
trainLabelArr = np.array(trainLabelList).T
#获取当前特征数目,也就是数据集的横轴大小
featureNum = trainDataArr.shape[1]
#初始化最大信息增益
maxG_D_A = -1
#初始化最大信息增益的特征
maxFeature = -1
#对每一个特征进行遍历计算
for feature in range(featureNum):
#“5.2.2 信息增益”中“算法5.1(信息增益的算法)”第一步:
#1.计算数据集D的经验熵H(D)
H_D = calc_H_D(trainLabelArr)
#2.计算条件经验熵H(D|A)
#由于条件经验熵的计算过程中只涉及到标签以及当前特征,为了提高运算速度(全部样本
#做成的矩阵运算速度太慢,需要剔除不需要的部分),将数据集矩阵进行切割
#数据集在初始时刻是一个Arr = 60000*784的矩阵,针对当前要计算的feature,在训练集中切割下
#Arr[:, feature]这么一条来,因为后续计算中数据集中只用到这个(没明白的跟着算一遍例5.2)
#trainDataArr[:, feature]:在数据集中切割下这么一条
#trainDataArr[:, feature].flat:将这么一条转换成竖着的列表
#np.array(trainDataArr[:, feature].flat):再转换成一条竖着的矩阵,大小为60000*1(只是初始是
#这么大,运行过程中是依据当前数据集大小动态变的)
trainDataArr_DevideByFeature = np.array(trainDataArr[:, feature].flat)
#3.计算信息增益G(D|A) G(D|A) = H(D) - H(D | A)
G_D_A = H_D - calcH_D_A(trainDataArr_DevideByFeature, trainLabelArr)
#不断更新最大的信息增益以及对应的feature
if G_D_A > maxG_D_A:
maxG_D_A = G_D_A
maxFeature = feature
return maxFeature, maxG_D_A
def getSubDataArr(trainDataArr, trainLabelArr, A, a):
'''
更新数据集和标签集
:param trainDataArr:要更新的数据集
:param trainLabelArr: 要更新的标签集
:param A: 要去除的特征索引
:param a: 当data[A]== a时,说明该行样本时要保留的
:return: 新的数据集和标签集
'''
#返回的数据集
retDataArr = []
#返回的标签集
retLabelArr = []
#对当前数据的每一个样本进行遍历
for i in range(len(trainDataArr)):
#如果当前样本的特征为指定特征值a
if trainDataArr[i][A] == a:
#那么将该样本的第A个特征切割掉,放入返回的数据集中
retDataArr.append(trainDataArr[i][0:A] + trainDataArr[i][A+1:])
#将该样本的标签放入返回标签集中
retLabelArr.append(trainLabelArr[i])
#返回新的数据集和标签集
return retDataArr, retLabelArr
def createTree(*dataSet):
'''
递归创建决策树
:param dataSet:(trainDataList, trainLabelList) <<-- 元祖形式
:return:新的子节点或该叶子节点的值
'''
#设置Epsilon,“5.3.1 ID3算法”第4步提到需要将信息增益与阈值Epsilon比较,若小于则
#直接处理后返回T
#该值的大小在设置上并未考虑太多,观察到信息增益前期在运行中为0.3左右,所以设置了0.1
Epsilon = 0.1
#从参数中获取trainDataList和trainLabelList
#之所以使用元祖作为参数,是由于后续递归调用时直数据集需要对某个特征进行切割,在函数递归
#调用上直接将切割函数的返回值放入递归调用中,而函数的返回值形式是元祖的,等看到这个函数
#的底部就会明白了,这样子的用处就是写程序的时候简洁一点,方便一点
trainDataList = dataSet[0][0]
trainLabelList = dataSet[0][1]
#打印信息:开始一个子节点创建,打印当前特征向量数目及当前剩余样本数目
print('start a node', len(trainDataList[0]), len(trainLabelList))
#将标签放入一个字典中,当前样本有多少类,在字典中就会有多少项
#也相当于去重,多次出现的标签就留一次。举个例子,假如处理结束后字典的长度为1,那说明所有的样本
#都是同一个标签,那就可以直接返回该标签了,不需要再生成子节点了。
classDict = {
i for i in trainLabelList}
#如果D中所有实例属于同一类Ck,则置T为单节点数,并将Ck作为该节点的类,返回T
#即若所有样本的标签一致,也就不需要再分化,返回标记作为该节点的值,返回后这就是一个叶子节点
if len(classDict) == 1:
#因为所有样本都是一致的,在标签集中随便拿一个标签返回都行,这里用的第0个(因为你并不知道
#当前标签集的长度是多少,但运行中所有标签只要有长度都会有第0位。
return trainLabelList[0]
#如果A为空集,则置T为单节点数,并将D中实例数最大的类Ck作为该节点的类,返回T
#即如果已经没有特征可以用来再分化了,就返回占大多数的类别
if len(trainDataList[0]) == 0:
#返回当前标签集中占数目最大的标签
return majorClass(trainLabelList)
#否则,按式5.10计算A中个特征值的信息增益,选择信息增益最大的特征Ag
Ag, EpsilonGet = calcBestFeature(trainDataList, trainLabelList)
#如果Ag的信息增益比小于阈值Epsilon,则置T为单节点树,并将D中实例数最大的类Ck
#作为该节点的类,返回T
if EpsilonGet < Epsilon:
return majorClass(trainLabelList)
#否则,对Ag的每一可能值ai,依Ag=ai将D分割为若干非空子集Di,将Di中实例数最大的
# 类作为标记,构建子节点,由节点及其子节点构成树T,返回T
treeDict = {
Ag:{
}}
#特征值为0时,进入0分支
#getSubDataArr(trainDataList, trainLabelList, Ag, 0):在当前数据集中切割当前feature,返回新的数据集和标签集
treeDict[Ag][0] = createTree(getSubDataArr(trainDataList, trainLabelList, Ag, 0))
treeDict[Ag][1] = createTree(getSubDataArr(trainDataList, trainLabelList, Ag, 1))
return treeDict
def predict(testDataList, tree):
'''
预测标签
:param testDataList:样本
:param tree: 决策树
:return: 预测结果
'''
# treeDict = copy.deepcopy(tree)
#死循环,直到找到一个有效地分类
while True:
#因为有时候当前字典只有一个节点
#例如{73: {0: {74:6}}}看起来节点很多,但是对于字典的最顶层来说,只有73一个key,其余都是value
#若还是采用for来读取的话不太合适,所以使用下行这种方式读取key和value
(key, value), = tree.items()
#如果当前的value是字典,说明还需要遍历下去
if type(tree[key]).__name__ == 'dict':
#获取目前所在节点的feature值,需要在样本中删除该feature
#因为在创建树的过程中,feature的索引值永远是对于当时剩余的feature来设置的
#所以需要不断地删除已经用掉的特征,保证索引相对位置的一致性
dataVal = testDataList[key]
del testDataList[key]
#将tree更新为其子节点的字典
tree = value[dataVal]
#如果当前节点的子节点的值是int,就直接返回该int值
#例如{403: {0: 7, 1: {297:7}},dataVal=0
#此时上一行tree = value[dataVal],将tree定位到了7,而7不再是一个字典了,
#这里就可以直接返回7了,如果tree = value[1],那就是一个新的子节点,需要继续遍历下去
if type(tree).__name__ == 'int':
#返回该节点值,也就是分类值
return tree
else:
#如果当前value不是字典,那就返回分类值
return value
def test(testDataList, testLabelList, tree):
'''
测试准确率
:param testDataList:待测试数据集
:param testLabelList: 待测试标签集
:param tree: 训练集生成的树
:return: 准确率
'''
#错误次数计数
errorCnt = 0
#遍历测试集中每一个测试样本
for i in range(len(testDataList)):
#判断预测与标签中结果是否一致
if testLabelList[i] != predict(testDataList[i], tree):
errorCnt += 1
#返回准确率
return 1 - errorCnt / len(testDataList)
if __name__ == '__main__':
#开始时间
start = time.time()
# 获取训练集
trainDataList, trainLabelList = loadData('../Mnist/mnist_train.csv')
# 获取测试集
testDataList, testLabelList = loadData('../Mnist/mnist_test.csv')
#创建决策树
print('start create tree')
tree = createTree((trainDataList, trainLabelList))
print('tree is:', tree)
#测试准确率
print('start test')
accur = test(testDataList, testLabelList, tree)
print('the accur is:', accur)
#结束时间
end = time.time()
print('time span:', end - start)
最后
学长亲自接毕业设计,有需要的同同学:
(q扣)
746876041
