来自大拿老师的Python笔记
结构化文件存储
- xml, json,
- 为了解决不同设备之间的信息交换
xml
-
XML文件
-
参考资料
- https://docs.python.org/3/library/xml.etree.elementtree.html
- https://www.runoob.com/python/python-xml.html
- https://blog.csdn.net/seetheworld518/article/details/49535285
-
XML : 可扩展标记语言
-
标记语言 : 语言中使用尖括号括起来的文本字符串标记
-
可扩展 : 用户可以自己定义需要的标记
-
例如:
自定义标记Teacher
在两个标记之间任何内容都应该跟Teacher相关
-
是w3c组织制定的一个标准
-
XML描述的是数据本身, 即数据的结构和语义
-
HTML侧重于如何显示web页面的数据
-
-
XML文档的构成
-
处理指令(可以认为一个文件内只有一个处理指令) ,最多只有一行,且必须在第一行,内容是xml本身处理相关的一些声明或者指令,以xml关键字开头,一般用于声明xml的版本和采用的编码,version属性是必须的,encoding属性用来指出xml解释器使用的编码,如果没有就使用默认的
-
根元素
- 看成一个树形结构
- 一个文件内只有一个根元素
-
子元素
-
属性
-
内容
- 表明标签存储的信息
-
注释
- 起说明作用的信息
- 注释不能嵌套在标签里面
- 只有在注释的开始和结尾使用双短横线
- 注释里面可以有一个短横线
- 三短横线只能出现在注释的开头而不能出现在结尾
-
保留字符的处理
- XML中使用的符号可能跟实际符号相冲突,典型的就是左右前括号
- 使用实体引用(转义)来表示保留字符
- 比如用score & gt ; 80代替score>80
- 把含有保留字符的部分放在CDATA块内部,CDATA块把内部信息视为不需要转义
- <![CDATA[ select name, age(sql语言) from Student where score>80 ]]>
-
常见需要转义的保留字符和对应实体引用
- & :& ;
- > : > ;
- < : < ;
- ’ : &apos
- " : "
- 一共五个,每个实体引用都以&开头并且以 ; 结尾
-
XML文件的命名规则
- pacal命名法
- 用单词表示,第一个字母大写
- 大小写严格区分
- 配对的标签必须一致
-
<?xml version="1.0" ?> <!--这是处理指令-->
<Student type="online" loc="beijing"> <!--最高级的只能有一个,内部可以写入属性-->
<name sex="lalala">haha</name>
<age>18</age>
</Student>
- 命名空间
- 为了防止命名冲突
- 为了避免冲突,需要给可能冲突的元素加命名空间
- xmlns :xml name space的缩写
<!--这是就添加了命名空间stuent和room,不然Name的命名会冲突-->
<Schooler xmlns:student="http://my_student" xmlns:room="hettp://my_room">
<student:Name>LiuYing</student:Name>
<Age>23</age>
<room:Name>2014</room:Name>
<Location>1-23-1</Location>
<Schooler>
- XML访问
- 读取
- XML读取分两个主要技术,SAX, DOM
- SAX(Simple API for XML):
- 基于事件驱动的API
- 利用SAX解析文档设计到解析器和时间处理两部分
- 特点
- 快
- 流式读取
- DOM
- 是W3C规定的XML变成接口
- 一个XML文件在缓存中以树形结构保存,读取
- 定位浏览XML任何一个节点信息
- 添加删除相应内容和
- minidom
- minidom.parse(filename):加载读取的xml文件,filename也可以是xml代码
- doc.documentElement:获取xml文档对象,一个xml文件只有一个对应的文档对象
- node.getAttribute(attr_name):获取xml节点的属性值
- node.getElementByTagName(tage_name):得到一个节点对象集合
- node.childNodes:得到所有孩子节点
- node.childNodes[index].nodeValue:获取单个节点值
- node.firstNode:得到第一个节点,等价于node.childNodes[0]
- node.attributes[tage_name]
- etree
- 以树形结构来表示xml
- root.getiterator : 得到相应的可迭代的node集合
- root.iter :同上
- find(node_name) : 查找指定node_name的节点,返回一个node
- root.findall(node_name) : 返回多个node_name的节点
- node.tag : node对应的tagename
- node.text : node的文本值
- node.attrib : 是node的属性的字典类型的内容
- 读取
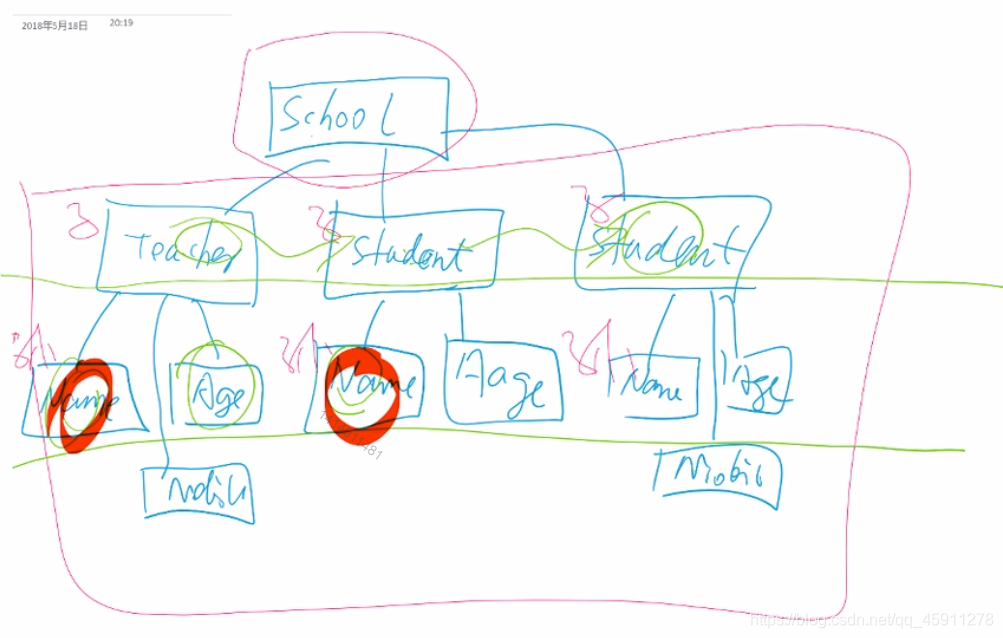
树形结构如下
<?xml version="1.0" encoding="utf-8"?>
<School>
<Teacher>
<Name>LiuDana</Name>
<age detail="Age for year 2010">18</Age>
<Mobile>13260446055<Mobile>
</Teacher>
<Student>
<Name Other="他是班长">ZhangSan</Name>
<Age Detail="The youngest boy in class">14</Age>
<Student>
<Student>
<Name>LiSi</Name>
<Age>19</Age>
<Mobile>15578875040</Mobile>
</Student>
</School>
minidom的案例
import xml.dom.minidom
#负责解析xml文件
from xml.dom.minidom import parse
#使用minidom打开xml文件
DOMTree = xml.dom.minidom.parse("student.xml")
#得到文档对象
doc = DOMTree.documentElement
#显示子元素
for ele in doc.childNodes:
if ele.nodeName == "Teacher":
print("----Node:{}----".format(ele.nodeName))
childs = ele.childNodes
for child in childs:
if child.nodeName == "Name":
#data是文本节点的一个属性,表示他的值
print("Name:{}".format(child.childNodes[0].data))
if child.nodeName == "Mobile":
#data是文本节点的一个属性,表示他的值
print("Mobile:{}".format(childNodes[0].data))
#data是文本节点的一个属性,表示他的值
if child.nodeName == "Age"
print("Age-detail:{}".format(child.getAttribute("detail"))
etree案例
import xml.etree.ElemenTree
root = xml.etree.ElemenTree.parse("student.xml")
print("利用getiterator访问:")
nodes = root.getiterator()
for node in nodes:
print("{}---{}".format(node.tag,node.text))
print("利用find和findall方法")
ele_teacher = root.find("Teacher")
print("{}---{}".format(ele_teacher.tag,ele_teacher.text))
ele_stus = root.findall("Student")
for ele in ele_stus:
print("{}---{}".format(ele.tag,ele.text))
for sub in ele.getiterator()
if sub.tag == "Name":
if "Other" in sub.attrib.keys():
print(sub.attrib['Other']
- xml文件写入
- 更改
- ele.set : 修改属性
- ele.append : 追加元素
- ele.remove : 删除元素
- 生成创建
- 更改
xml文件进行修改案例
import xml.etree.ElemenTree as et
tree = et.parse(r'to_edit.xml')
root = tree.getroot()
for e in root.iter("Name")
print(e.text)
for stu in root.iter("Student"):
name = stu.find('Name') # 去找这个节点
if name != None :
name.set('text',name.text*2) # 将text文本重复两次
stu = root.find("Student")
#生成一个新的元素
e = et.Element('ADDer')
e.attrib = {
'a':'b'}
e.text = "我加的"
sut.append(e)
#一定要把修改后的内容写回文件 , 否则修改无效
tree.write('to_edit.xml')
- xml文件生成/创建
- SubElement
来看xml文件生成案例
import xml.etree.ElemenTree as et
stu = et.Element("Student")
name = et.SubElement(stu,"Name") #生成一个儿子,属于stu,名字叫Name
name.attrib = {
"lang" , "en"} #属性
name.text = "emmmm" #文本
age = et.SubElement(stu,'Age')
age.text = 18
et.dump()
etree写入案例
import xml.etree.ElemenTree as et
# 在内存中创建一个空的文档
etree = et.ElementTree()
e = et.Element("Student")
etree._setroot(e) # 将这个设置为根
e_name = et.SubElement(e,'Name')
e_name.text = "hahaa"
etree.write('v06.xml')
JSON
-
参考资料
- https://www.sojson.com/
- https://www.w3school.com.cn/json/
- http://www.runoob.com/json/json-tutorial.html
-
JSON(JavaScriptObjectNotation)
-
轻量级的数据交换格式,基于ECMAScript
-
json格式是一个键值对形式的数据集
- key : 字符串
- value : 字符串,数字,列表,json
- json使用大括号包裹
- 键值对直接用括号隔开
student={
"name" : "wangdapeng",
"age" : 18,
"mobile" : "13260446055"
}
-
json和python格式的对应
- 字符串 : 字符串
- 数字 : 数字
- 队列 : list
- 对象 : dict
- 布尔值 : 布尔值(大小写不一样)
-
python for json
- json包
- json和python对象的转换
- json.dumps() : 对数据编码 , 把python格式表示成json格式
- json.loads() : 对数据解码 ,把json格式转换成python格式
- python读取json文件
- json.dump() : 把内容写入文件
- json.load() : 把json文件内容读入python
json的案例
improt json
# 此时student是一个dict格式内容,不是json
student={
"name" : "liudana",
"age" : 18,
"mobile" : "15512321"
}
print(type(student))
stu_json = json.dumps(student) # 转换成json格式
print(type(stu_json))
print("JSON对象:{}".format(stu_json))
stu_dict = json.loads(stu_json) # 转换成python格式
print(type(stu_dict))
print(stu_dict)
import json
data = {
'name':'hahaha','age':12}
with open('t.json','w') as f:
json.dump(data,f) # 把内容写入文件
with open('t.json','r') as f:
d = json.load(f) # 把json文件内容写入python
print(d)