Linux基本概念及常用命令实现汇总
1. 引言
Linux常用的发行版是Linux内核及各种应用软件的集成版本。各个版本的Linux发行版系统命令大同小异,这篇文章中,我们不讲区别,主要讲一些Linux的基本命令。
| 基于的包管理工具 | 商业发行版 | 社区发行版 |
|---|---|---|
| RPM | Red Hat | Fedora / CentOS |
| DPKG | Ubuntu | Debian |
首先我们必须要会的一个命令是ssh命令,当你需要连接的服务器不多时,进行一些简单的管理再也不需要XSHELL等工具了,macOS提供了terminal就可以实现简单的服务器管理功能,甚至我们还能进行上传、下载文件的操作。
ssh 账户名@ip/域名
按照要求输入密码后,我们就成功登陆了服务器:
2. 文件系统
分区与文件系统
对分区文件进行格式化是为了在分区上建立系统,一个分区通常只能格式化为一个文件系统,但是磁盘阵列等技术可以将一个分区格式化为多个文件系统,运维生产环境常用RAID级别为:RAID0,RAID1, RAID5 ,RAID10。
| RAID级别 | 最少磁盘要求 | 关键优点 | 关键缺点 | 实际应用场景 |
|---|---|---|---|---|
| RAID0 | 1块 | 读写速度快 | 没有任何冗余 | MySQL Slave(数据库的从库),集群的节点RS |
| RAID1 | 2块(只能) | 100%冗余,镜像 | 读写性能一般,成本高 | 单独的,数据很重要,且不能宕机的业务,监控,系统盘 |
| RAID5 | 3块 | 具有一定性能和冗余,可以坏一块盘 | 写入性能不高 | 一般的业务都可以用 |
| RAID10 | 4块 | 读写速度很快,100%冗余 | 成本高 | 性能和冗余要求很好的业务。数据库主库和存储的主节点 |
组成
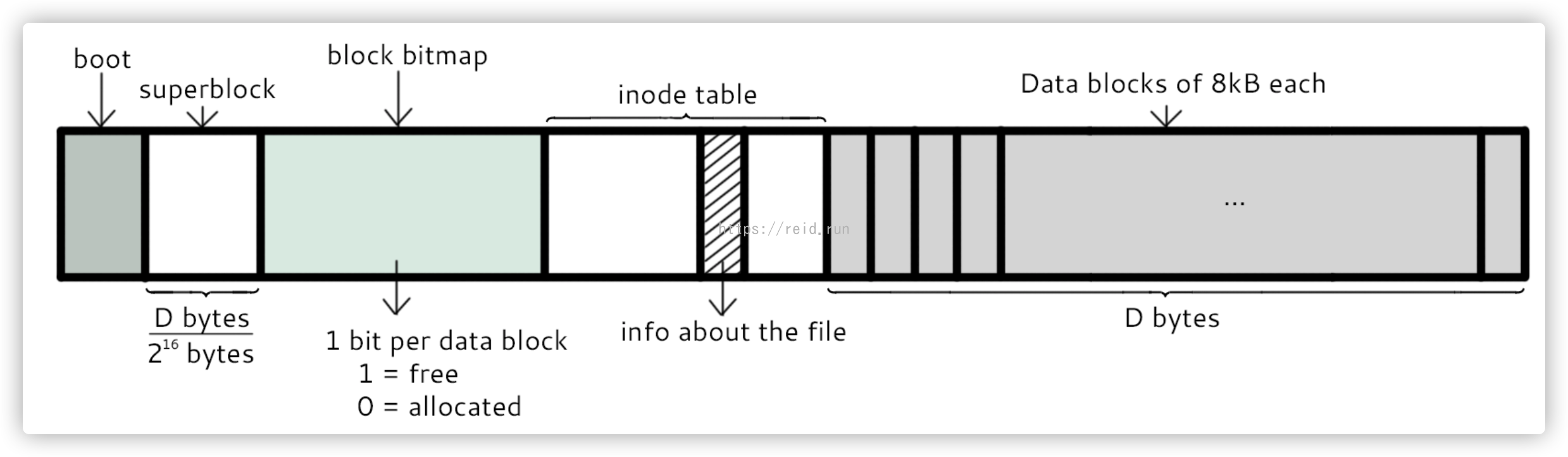
理解inode,要从文件储存说起。
文件存储在硬盘上,硬盘的最小存储单位叫做“扇区”(Sector)。每个扇区储存512字节(相当于0.5KB)。
操作系统读取硬盘的时候,不会一个个扇区的读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个“块”(block)。这种由多个扇区组成的“块”,是文件存取的最小单位。“块”的大小,最常见的是4KB,即连续八个sector组成一个block。
文件数据都储存在“块”中,那么很显然,我们还必须找到一个地方储存文件的“元信息”,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
最主要在组成部分如下:
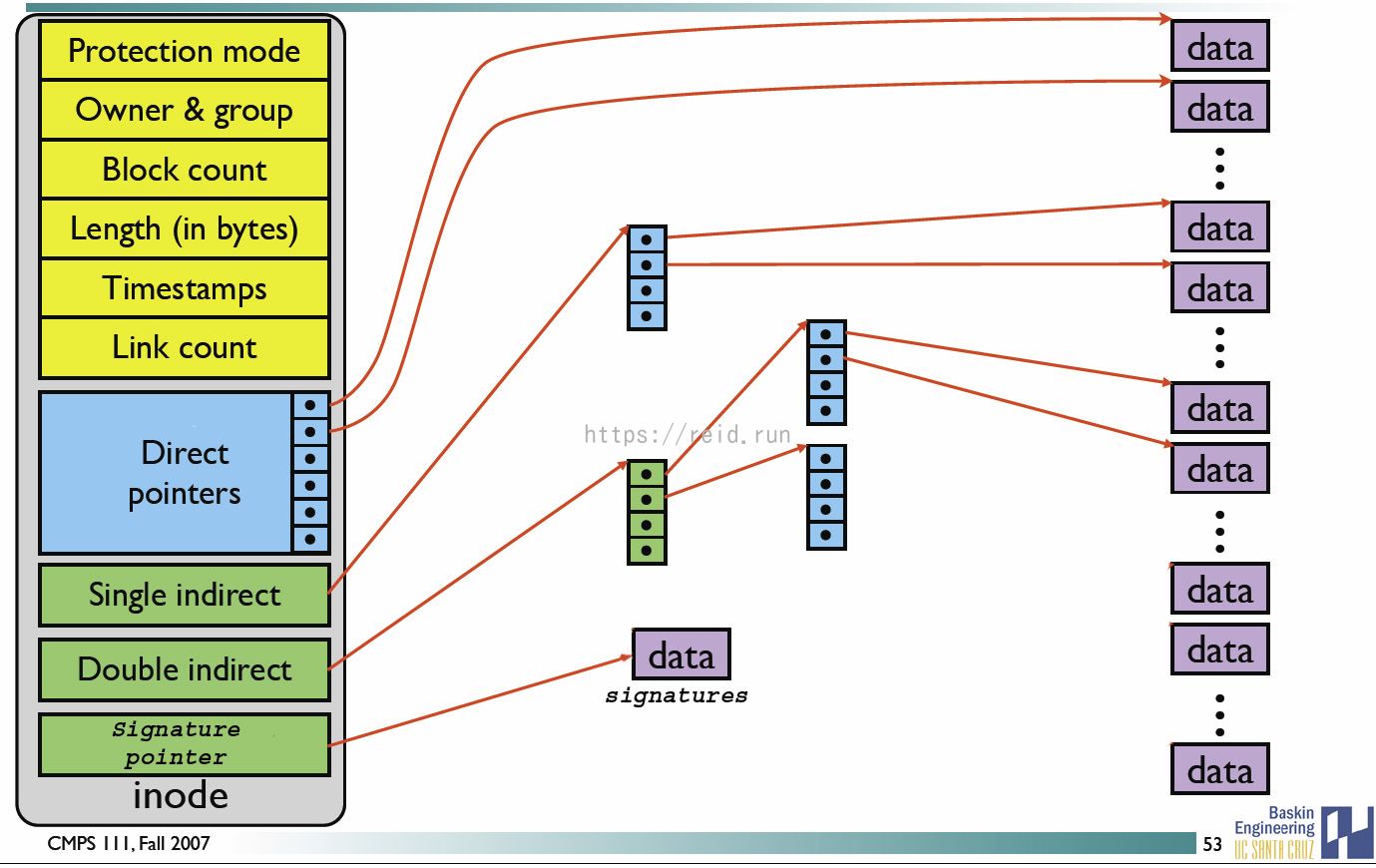
inode:一个文件占用一个inode,记录文件的属性,同时记录此文件的内容所在的block编号;
block:记录文件的内容,内容太大时,会占用多个block;
除此之外:
superblock:记录文件系统的整体信息,包括inode和block总量、使用量、剩余量,以及文件系统的格式与相关信息;
blcok bitmap:记录block是否被使用的位图;
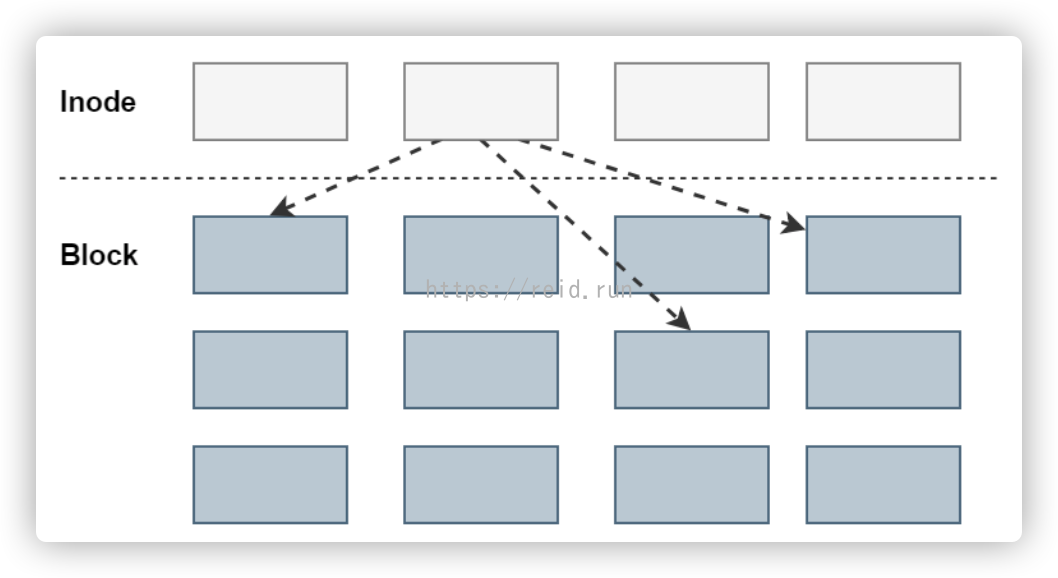
文件读取
对于Ext2文件系统,当要读取一个文件的内容时,先在inode中查找文件内容所在的所有block,然后把所有block的内容读出来。
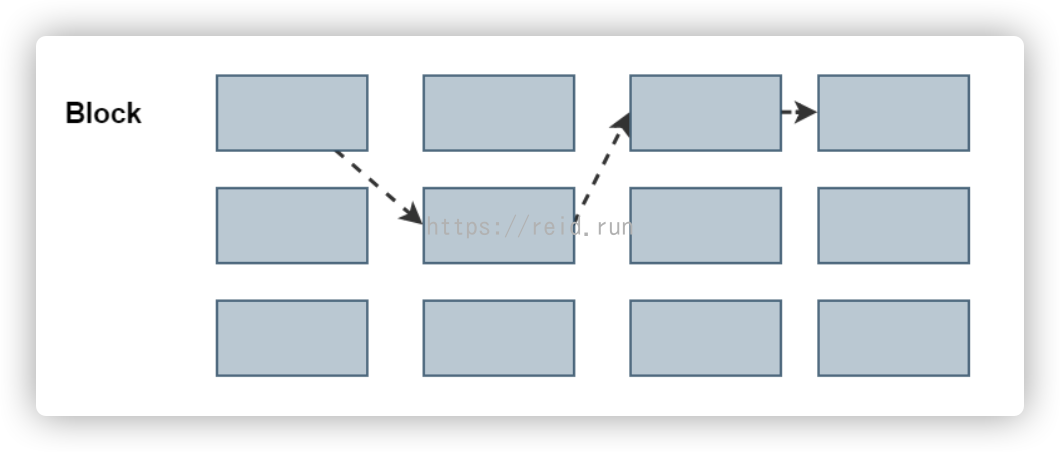
而对于FAT文件系统,它没有inode,每个block中存储着下一个block的编号。
磁盘碎片
当一个文件系统所在的block过于分散,导致磁头移动距离过大,从而降低了磁盘读写性能。
block
在Ext2文件系统中所支持的block大小有1K,2K,4K等,不同的大小限制了单个文件和文件系统的最大大小。
| 大小 | 1KB | 2KB | 4KB |
|---|---|---|---|
| 最大单一文件 | 16GB | 256GB | 2TB |
| 最大文件系统 | 2TB | 8TB | 16TB |
“4K对齐”这个概念因固态硬盘的出现而兴起,那么4K这个数值就肯定跟固态硬盘有关。固态硬盘的内部结构不同于机械硬盘,其读写的最小单位是“页”,相当于机械硬盘的物理扇区,并且常见尺寸为4KB。固态硬盘存颗粒不允许像机械硬盘一样覆盖写入,因此在有数据的地方要写入新数据,就需要先进行擦除操作,而擦除的最小单位是块(每个块都由很多个页组成)。因此,4K这个数值是顺应了硬盘设备的发展而得出的 。
以固态硬盘为例,固态硬盘的页大小为4KB,传统分区偏移尺寸为31.5KB。如果4K不对齐,那么用户的数据都会跨两个页,导致每次的写入操作都变成了读-擦-写操作,造成性能下降。写入一个4KB的数据,实际运行时会有两次写入操作,4K对齐就让是操作系统的最小分配单元和闪存的一个页对应起来,这样操作系统写入一个4KB的数据,一次就能完成。因此,“4K”对齐能够提升硬盘工作效率,延长硬盘寿命,提升文件操作的稳定性与安全性 。
这就是我们常说的4K对齐,我们可以通过sudo fdisk -lu查看,当start可以被8整除就说明已经4K对齐了。
inode
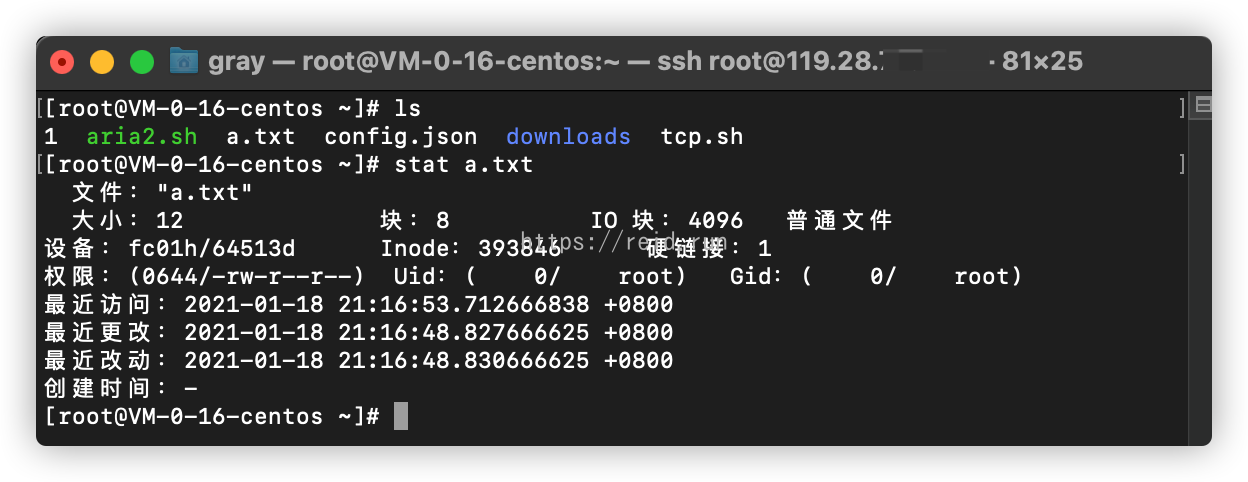
inode具体信息包含以下信息:
- Size 文件的字节数
- Uid 文件拥有者的User ID
- Gid 文件的Group ID
- Access 文件的读、写、执行权限
- 文件的时间戳,共有三个:
- Change 指inode上一次变动的时间
- Modify 指文件内容上一次变动的时间
- Access 指文件上一次打开的时间
- Links 链接数,即有多少文件名指向这个inode
- Inode 文件数据block的位置
- Blocks 块数
- IO Blocks 块大小
- Device 设备号码
我们可以通过stat 文件名查看某个文件的inode信息:
inode具有以下的特点:
- 每个inode大小均为128bytes(新的ext4和xfs可以设定到256bytes)
- 每个文件都会占用一个inode
inode中记录了文件内容所在的block编号,但是每个block非常小,一个大文件需要几十万个block,而一个inode大小有限,无法直接引用那么多block编号。因此引入了间接、双间接、三间接引用,间接引用让inode记录的引用block块记录引用信息。
目录
建立一个目录时,会分配一个inode与至少一个block。block记录的内容是目录下所有文件的inode编号以及文件名。
文件的inode本身不记录文件名,文件名记录在目录中,因此新增文件、删除文件、更改文件名这些操作与目录的读写权限无关。
日志
如果突然断电,那么文件系统会发生错误,例如断电前只修改了 block bitmap,而还没有将数据真正写入 block 中。
ext3/ext4 文件系统引入了日志功能,可以利用日志来修复文件系统。
挂载
linux挂载时:
- 首先要增加硬盘
- 然后格式化硬盘
- 在硬盘上创建分区
- 创建目录
- 然后才是挂载
- 1.提一句Windows下,mount挂载,就是给磁盘分区提供一个盘符(C,D,E,…)。比如插入U盘后系统自动分配给了它I:盘符其实就是挂载,退优盘的时候进行安全弹出,其实就是卸载unmount。
- 2.Linux下,不像Windows可以有C,D,E,多个目录,Linux只有一个根目录/。在装系统时,我们分配给linux的所有区都在/下的某个位置,比如/home等等。
- 3.提问者插入了新硬盘,分了新磁盘区sdb1。它现在还不属于/。
- 4.我们虽然可以在一些图形桌面系统里找到他的位置,浏览管理里面的文件,但在命令行却不知怎么访问它的目录,比如无法使用cd或者ls。也无法在编程时指定一个目录对它操作。
- 5.这时提问者使用了 mount /dev/sdb1 ~/Share/ ,把新硬盘的区sdb1挂载到工作目录的/Share/文件夹下,之后访问这个/Share/文件夹就相当于访问这个硬盘2的sdb1分区了。对/Share/的任何操作,都相当于对sdb1里文件的操作。
- 6.所以Linux下,mount挂载的作用,就是将一个设备(通常是存储设备)挂接到一个已存在的目录上。访问这个目录就是访问该存储设备。
- 7.linux操作系统将所有的设备都看作文件,它将整个计算机的资源都整合成一个大的文件目录。我们要访问存储设备中的文件,必须将文件所在的分区挂载到一个已存在的目录上,然后通过访问这个目录来访问存储设备。挂载就是把设备放在一个目录下,让系统知道怎么管理这个设备里的文件,了解这个存储设备的可读写特性之类的过程。
- 8.我们不是有/dev/sdb1 吗,直接对它操作不就行了?这不是它的目录吗?
- 9.这不是它的目录。虽然/dev是个目录,但/dev/sdb1不是目录。可以发现ls/dev/sdb1无法执行。/dev/sdb1,是一个类似指针的东西,指向这个分区的原始数据块。mount前,系统并不知道这个数据块哪部分数据代表文件,如何对它们操作。
- 10.插入CD,系统其实自动执行了 mount /dev/cdrom /media/cdrom。所以可以直接在/media/cdrom中对CD中的内容进行管理。
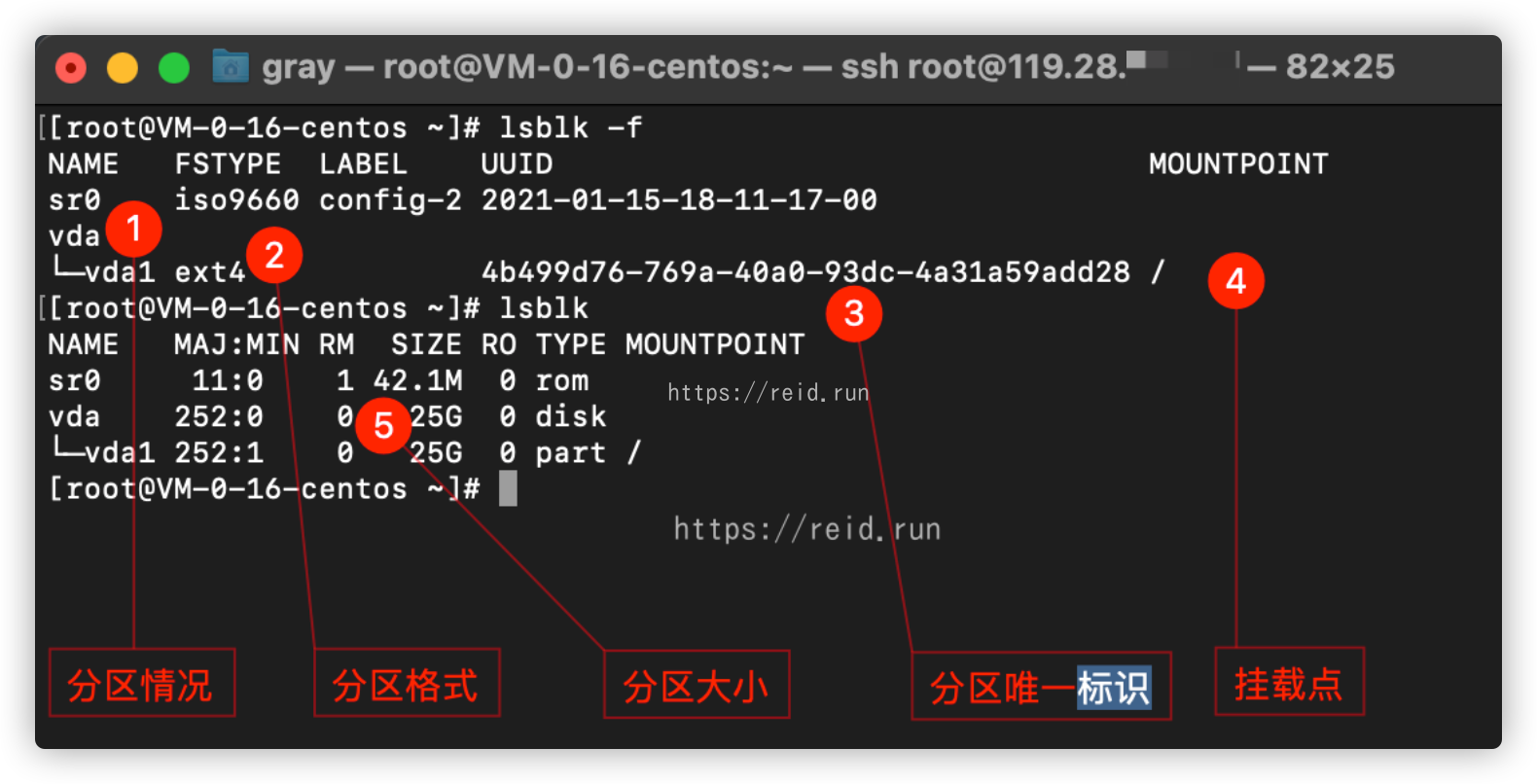
通过lsblk -f可以查看磁盘的挂载点、分区情况、分区格式、分区大小等。
目录结构
为了使不同 Linux 发行版本的目录结构保持一致性,Filesystem Hierarchy Standard (FHS) 规定了 Linux 的目录结构。最基础的三个目录如下:
- / (root, 根目录)
- /usr (unix software resource):所有系统默认软件都会安装到这个目录;
- /var (variable):存放系统或程序运行过程中的数据文件。
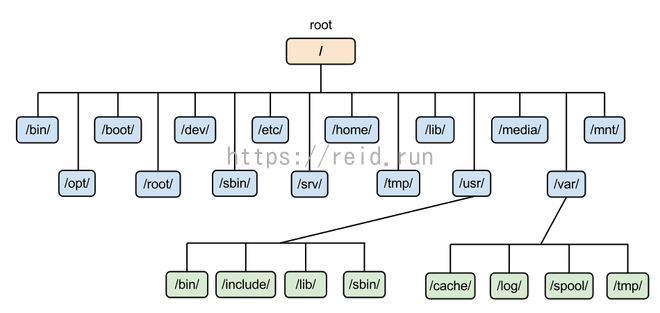
系统启动必须:
-
**/boot:**存放的启动Linux 时使用的内核文件,包括连接文件以及镜像文件。
-
/etc:存放所有的系统需要的配置文件和**子目录列表,**更改目录下的文件可能会导致系统不能启动。
-
/lib:存放基本代码库(比如c++库),其作用类似于Windows里的DLL文件。几乎所有的应用程序都需要用到这些共享库。
-
/sys: 这是linux2.6内核的一个很大的变化。该目录下安装了2.6内核中新出现的一个文件系统 sysfs 。sysfs文件系统集成了下面3种文件系统的信息:针对进程信息的proc文件系统、针对设备的devfs文件系统以及针对伪终端的devpts文件系统。该文件系统是内核设备树的一个直观反映。当一个内核对象被创建的时候,对应的文件和目录也在内核对象子系统中
指令集合:
-
**/bin:**存放着最常用的程序和指令
-
**/sbin:**只有系统管理员能使用的程序和指令。
外部文件管理:
-
**/dev :**Device(设备)的缩写, 存放的是Linux的外部设备。**注意:**在Linux中访问设备和访问文件的方式是相同的。
-
/media:类windows的**其他设备,**例如U盘、光驱等等,识别后linux会把设备放到这个目录下。
-
/mnt:临时挂载别的文件系统的,我们可以将光驱挂载在/mnt/上,然后进入该目录就可以查看光驱里的内容了。
临时文件:
-
/run:是一个临时文件系统,存储系统启动以来的信息。当系统重启时,这个目录下的文件应该被删掉或清除。如果你的系统上有 /var/run 目录,应该让它指向 run。
-
/lost+found:一般情况下为空的,系统非法关机后,这里就存放一些文件。
-
/tmp:这个目录是用来存放一些临时文件的。
账户:
-
/root:系统管理员的用户主目录。
-
/home:用户的主目录,以用户的账号命名的。
-
/usr:用户的很多应用程序和文件都放在这个目录下,类似于windows下的program files目录。
-
**/usr/bin:**系统用户使用的应用程序与指令。
-
**/usr/sbin:**超级用户使用的比较高级的管理程序和系统守护程序。
-
**/usr/src:**内核源代码默认的放置目录。
运行过程中要用:
-
/var:存放经常修改的数据,比如程序运行的日志文件(/var/log 目录下)。
-
/proc:管理**内存空间!**虚拟的目录,是系统内存的映射,我们可以直接访问这个目录来,获取系统信息。这个目录的内容不在硬盘上而是在内存里,我们也可以直接修改里面的某些文件来做修改。
扩展用的:
-
/opt:默认是空的,我们安装额外软件可以放在这个里面。
-
/srv:存放服务启动后需要提取的数据**(不用服务器就是空)**
3. 文件命令
文件与目录的基本操作
1. ls
列出文件或者目录的信息,目录的信息就是其中包含的文件。
## ls [-aAdfFhilnrRSt] file|dir
-a :列出全部的文件
-d :仅列出目录本身
-l :以长数据串行列出,包含文件的属性与权限等等数据
2. cd
更换当前目录。
cd [相对路径或绝对路径]
3. mkdir
创建目录。
## mkdir [-mp] 目录名称
-m :配置目录权限
-p :递归创建目录
4. rmdir
删除目录,目录必须为空。
rmdir [-p] 目录名称
-p :递归删除目录
5. touch
更新文件时间或者建立新文件。
## touch [-acdmt] filename
-a : 更新 atime
-c : 更新 ctime,若该文件不存在则不建立新文件
-m : 更新 mtime
-d : 后面可以接更新日期而不使用当前日期,也可以使用 --date="日期或时间"
-t : 后面可以接更新时间而不使用当前时间,格式为[YYYYMMDDhhmm]
6. cp
复制文件。如果源文件有两个以上,则目的文件一定要是目录才行。
cp [-adfilprsu] source destination
-a :相当于 -dr --preserve=all
-d :若来源文件为链接文件,则复制链接文件属性而非文件本身
-i :若目标文件已经存在时,在覆盖前会先询问
-p :连同文件的属性一起复制过去
-r :递归复制
-u :destination 比 source 旧才更新 destination,或 destination 不存在的情况下才复制
--preserve=all :除了 -p 的权限相关参数外,还加入 SELinux 的属性, links, xattr 等也复制了
7. rm
删除文件。
## rm [-fir] 文件或目录
-r :递归删除
8. mv
移动文件。
## mv [-fiu] source destination
## mv [options] source1 source2 source3 .... directory
-f : force 强制的意思,如果目标文件已经存在,不会询问而直接覆盖
修改权限
可以将一组权限用数字来表示,此时一组权限的 3 个位当做二进制数字的位,从左到右每个位的权值为 4、2、1,即每个权限对应的数字权值为 r : 4、w : 2、x : 1。
## chmod [-R] xyz dirname/filename
示例:将 .bashrc 文件的权限修改为 -rwxr-xr–。
## chmod 754 .bashrc
也可以使用符号来设定权限。
## chmod [ugoa] [+-=] [rwx] dirname/filename
- u:拥有者
- g:所属群组
- o:其他人
- a:所有人
- +:添加权限
- -:移除权限
- =:设定权限
示例:为 .bashrc 文件的所有用户添加写权限。
## chmod a+w .bashrc
默认权限
- 文件默认权限:文件默认没有可执行权限,因此为 666,也就是 -rw-rw-rw- 。
- 目录默认权限:目录必须要能够进入,也就是必须拥有可执行权限,因此为 777 ,也就是 drwxrwxrwx。
可以通过 umask 设置或者查看默认权限,通常以掩码的形式来表示,例如 002 表示其它用户的权限去除了一个 2 的权限,也就是写权限,因此建立新文件时默认的权限为 -rw-rw-r–。
软链接和硬链接
硬链接(hard link):
A是B的硬链接(A和B都是文件名),则A的目录项中的inode节点号与B的目录项中的inode节点号相同,即一个inode节点对应两个不同的文件名,两个文件名指向同一个文件,A和B对文件系统来说是完全平等的。如果删除了其中一个,对另外一个没有影响。每增加一个文件名,inode节点上的链接数增加一,每删除一个对应的文件名,inode节点上的链接数减一,直到为0,inode节点和对应的数据块被回收。注:文件和文件名是不同的东西,rm A删除的只是A这个文件名,而A对应的数据块(文件)只有在inode节点链接数减少为0的时候才会被系统回收。
软链接(soft link):
A是B的软链接(A和B都是文件名),A的目录项中的inode节点号与B的目录项中的inode节点号不相同,A和B指向的是两个不同的inode,继而指向两块不同的数据块。但是A的数据块中存放的只是B的路径名(可以根据这个找到B的目录项)。A和B之间是“主从”关系,如果B被删除了,A仍然存在(因为两个是不同的文件),但指向的是一个无效的链接。
主要区别、限制:
硬链接:
a.不能对目录创建硬链接,原因有几种,最重要的是:文件系统不能存在链接环(目录创建时的"…"除外,这个系统可以识别出来),存在环的后果会导致例如文件遍历等操作的混乱(du,pwd等命令的运作原理就是基于文件硬链接,顺便一提,ls -l结果的第二列也是文件的硬链接数,即inode节点的链接数)
b:不能对不同的文件系统创建硬链接,即两个文件名要在相同的文件系统下。
c:不能对不存在的文件创建硬链接,由原理即可知原因。
软链接:
a.可以对目录创建软链接,遍历操作会忽略目录的软链接。
b:可以跨文件系统
c:可以对不存在的文件创建软链接,因为放的只是一个字符串,至于这个字符串是不是对于一个实际的文件,就是另外一回事了
ln 语法格式
硬链接:ln 源文件 链接名
软链接:ln -s 源文件 链接名
注意: 链接的源文件路径要写绝对路径
获取文件内容
1. cat
取得文件内容。
## cat [-AbEnTv] filename
-n :打印出行号,连同空白行也会有行号,-b 不会
2. tac
是 cat 的反向操作,从最后一行开始打印。
3. more
和 cat 不同的是它可以一页一页查看文件内容,比较适合大文件的查看。
4. less
和 more 类似,但是多了一个向前翻页的功能。
5. head
取得文件前几行。
## head [-n number] filename
-n :后面接数字,代表显示几行的意思
6. tail
是 head 的反向操作,只是取得是后几行。
7. od
以字符或者十六进制的形式显示二进制文件。
指令与文件搜索
1. which
指令搜索。
## which [-a] command
-a :将所有指令列出,而不是只列第一个
2. whereis
文件搜索。速度比较快,因为它只搜索几个特定的目录。
## whereis [-bmsu] dirname/filename
3. locate
文件搜索。可以用关键字或者正则表达式进行搜索。
locate 使用 /var/lib/mlocate/ 这个数据库来进行搜索,它存储在内存中,并且每天更新一次,所以无法用 locate 搜索新建的文件。可以使用 updatedb 来立即更新数据库。
## locate [-ir] keyword
-r:正则表达式
4. find
文件搜索。可以使用文件的属性和权限进行搜索。
## find [basedir] [option]
example: find . -name "shadow*"
① 与时间有关的选项
-mtime n :列出在 n 天前的那一天修改过内容的文件
-mtime +n :列出在 n 天之前 (不含 n 天本身) 修改过内容的文件
-mtime -n :列出在 n 天之内 (含 n 天本身) 修改过内容的文件
-newer file : 列出比 file 更新的文件
+4、4 和 -4 的指示的时间范围如下:

② 与文件拥有者和所属群组有关的选项
-uid n
-gid n
-user name
-group name
-nouser :搜索拥有者不存在 /etc/passwd 的文件
-nogroup:搜索所属群组不存在于 /etc/group 的文件
③ 与文件权限和名称有关的选项
-name filename
-size [+-]SIZE:搜寻比 SIZE 还要大 (+) 或小 (-) 的文件。这个 SIZE 的规格有:c: 代表 byte,k: 代表 1024bytes。所以,要找比 50KB 还要大的文件,就是 -size +50k
-type TYPE
-perm mode :搜索权限等于 mode 的文件
-perm -mode :搜索权限包含 mode 的文件
-perm /mode :搜索权限包含任一 mode 的文件
六、压缩与打包
压缩文件名
Linux 底下有很多压缩文件名,常见的如下:
| 扩展名 | 压缩程序 |
|---|---|
| *.Z | compress |
| *.zip | zip |
| *.gz | gzip |
| *.bz2 | bzip2 |
| *.xz | xz |
| *.tar | tar 程序打包的数据,没有经过压缩 |
| *.tar.gz | tar 程序打包的文件,经过 gzip 的压缩 |
| *.tar.bz2 | tar 程序打包的文件,经过 bzip2 的压缩 |
| *.tar.xz | tar 程序打包的文件,经过 xz 的压缩 |
压缩指令
1. gzip
gzip 是 Linux 使用最广的压缩指令,可以解开 compress、zip 与 gzip 所压缩的文件。
经过 gzip 压缩过,源文件就不存在了。
有 9 个不同的压缩等级可以使用。
可以使用 zcat、zmore、zless 来读取压缩文件的内容。
$ gzip [-cdtv#] filename
-c :将压缩的数据输出到屏幕上
-d :解压缩
-t :检验压缩文件是否出错
-v :显示压缩比等信息
-# : # 为数字的意思,代表压缩等级,数字越大压缩比越高,默认为 6
2. bzip2
提供比 gzip 更高的压缩比。
查看命令:bzcat、bzmore、bzless、bzgrep。
$ bzip2 [-cdkzv#] filename
-k :保留源文件
3. xz
提供比 bzip2 更佳的压缩比。
可以看到,gzip、bzip2、xz 的压缩比不断优化。不过要注意的是,压缩比越高,压缩的时间也越长。
查看命令:xzcat、xzmore、xzless、xzgrep。
$ xz [-dtlkc#] filename
打包
压缩指令只能对一个文件进行压缩,而打包能够将多个文件打包成一个大文件。tar 不仅可以用于打包,也可以使用 gzip、bzip2、xz 将打包文件进行压缩。
$ tar [-z|-j|-J] [cv] [-f 新建的 tar 文件] filename... ==打包压缩
$ tar [-z|-j|-J] [tv] [-f 已有的 tar 文件] ==查看
$ tar [-z|-j|-J] [xv] [-f 已有的 tar 文件] [-C 目录] ==解压缩
-z :使用 zip;
-j :使用 bzip2;
-J :使用 xz;
-c :新建打包文件;
-t :查看打包文件里面有哪些文件;
-x :解打包或解压缩的功能;
-v :在压缩/解压缩的过程中,显示正在处理的文件名;
-f : filename:要处理的文件;
-C 目录 : 在特定目录解压缩。
| 使用方式 | 命令 |
|---|---|
| 打包压缩 | tar -jcv -f filename.tar.bz2 要被压缩的文件或目录名称 |
| 查 看 | tar -jtv -f filename.tar.bz2 |
| 解压缩 | tar -jxv -f filename.tar.bz2 -C 要解压缩的目录 |
4. 进程管理
1.ps
ps -l # 查看自己的进程
ps aux # 查看系统所有进程
ps aux | grep aria2 # 查看特定进程aria2
pstree -A # 查看进程树
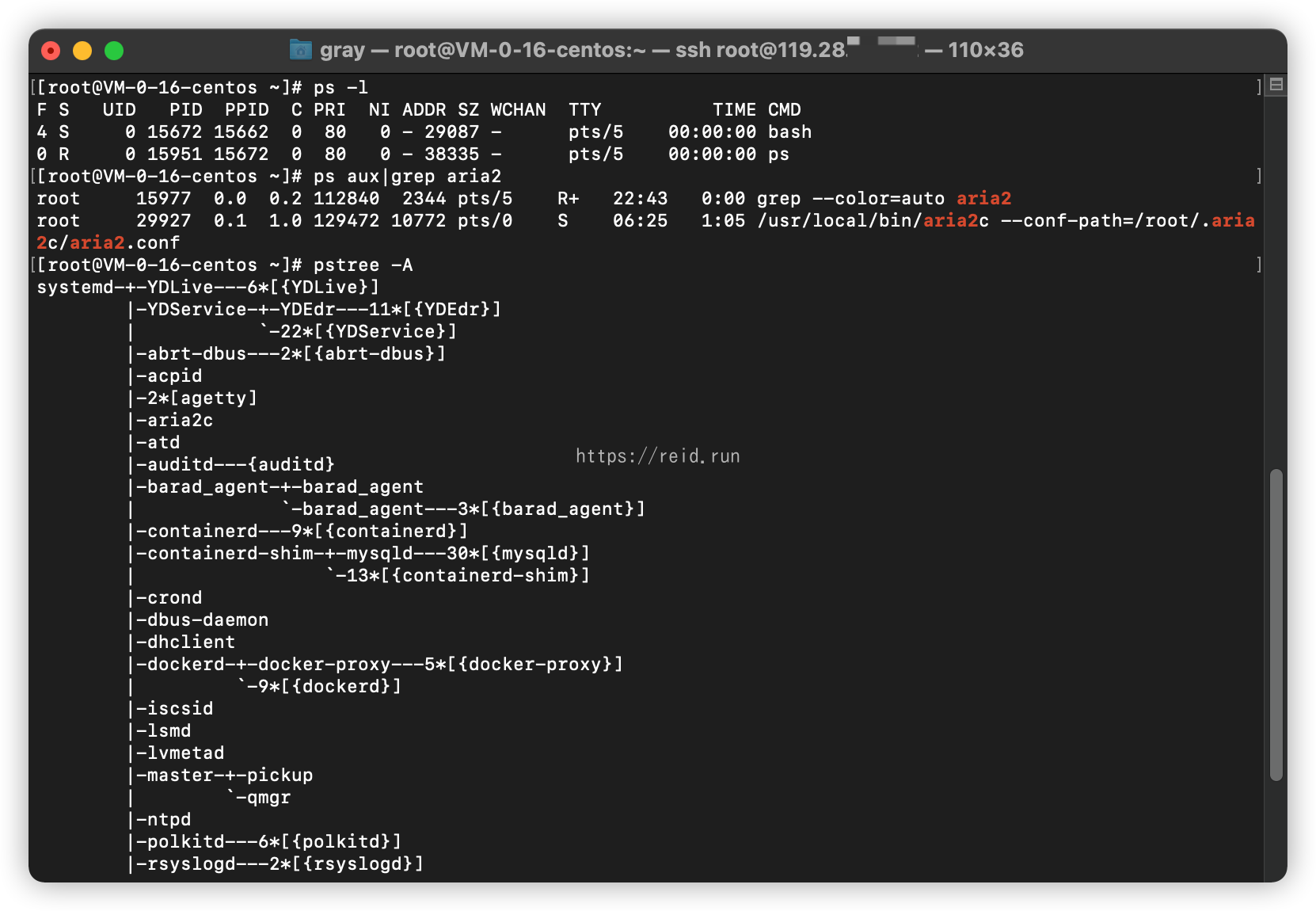
2.top
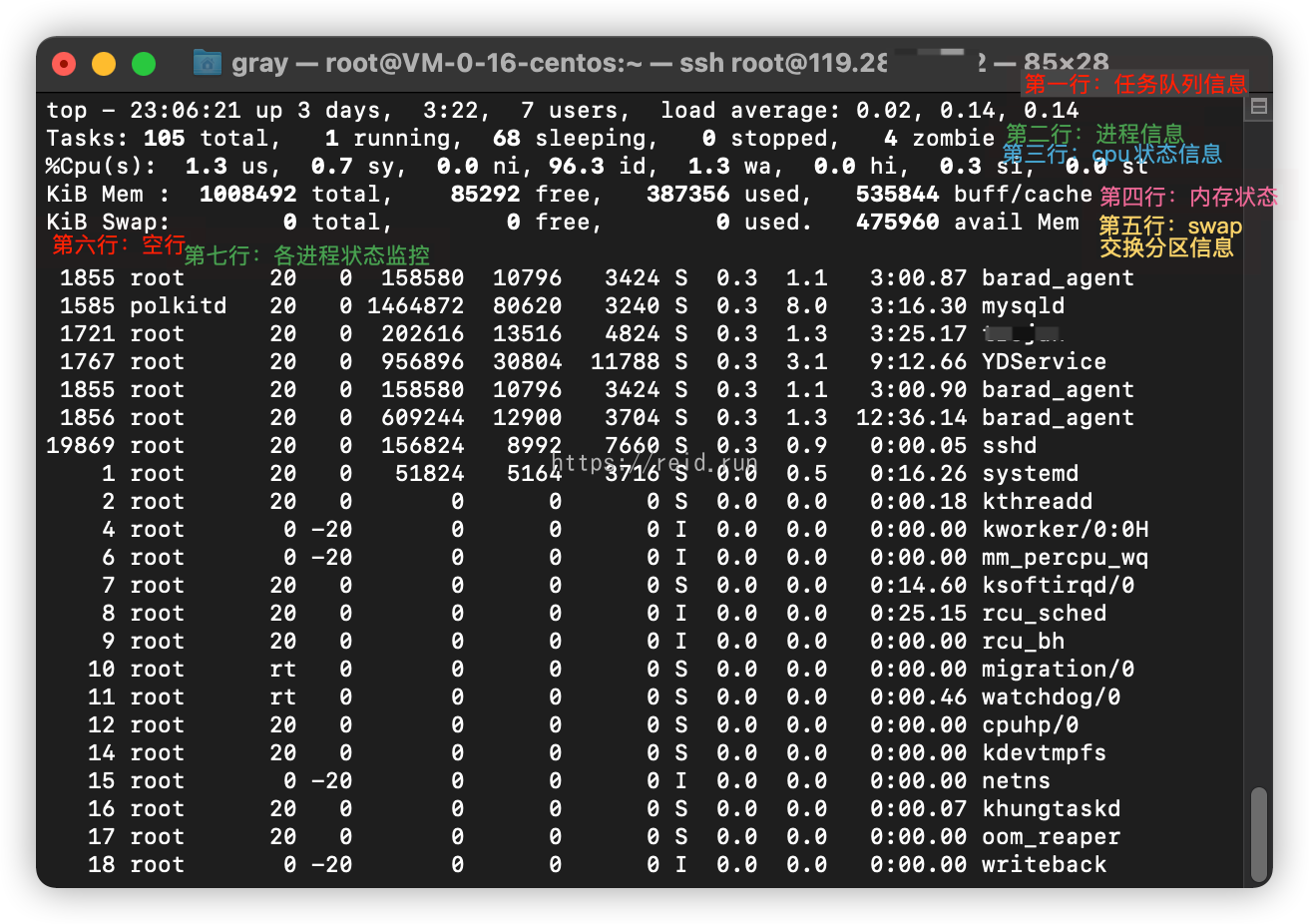
第一行,任务队列信息,同 uptime 命令的执行结果
系统时间:23:06:21
运行时间:up 3days,3:22 min,
当前登录用户: 7 users
负载均衡(uptime) load average: 0.02, 0.14, 0.14
average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了
第二行,Tasks — 任务(进程)
总进程:150 total, 运行:1 running, 休眠:68 sleeping, 停止: 0 stopped, 僵尸进程: 4 zombie
第三行,cpu状态信息
0.0%us【user space】— 用户空间占用CPU的百分比。
0.3%sy【sysctl】— 内核空间占用CPU的百分比。
0.0%ni【】— 改变过优先级的进程占用CPU的百分比
99.7%id【idolt】— 空闲CPU百分比
0.0%wa【wait】— IO等待占用CPU的百分比
0.0%hi【Hardware IRQ】— 硬中断占用CPU的百分比
0.0%si【Software Interrupts】— 软中断占用CPU的百分比
第四行,内存状态
1008492 total, 387356 used, 85292 free, 535844 buffers【缓存的内存量】
第五行,swap交换分区信息
0 total, 0 used, 0 free, 475960 cached【缓冲的交换区总量】
备注:
可用内存=free + buffer + cached
对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,
第四行中空闲内存总量(free)是内核还未纳入其管控范围的数量。
纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少,但不用为此担心。
3.netstat
查看占用端口进程,可以用netstat -anp | grep port查看指定端口进程。
博文的后续更新,请关注我的个人博客:星尘博客