Oracle数据库应用学习
表空间和用户权限管理
表空间:概述
Oracle数据库包含 逻辑结构 和 物理结构;
物理结构 是指数据库是物理存储数据的集合包括: 数据文件ORA或者DBF,控制文件,联机文件,日志文件,参数文件…
逻辑结构 是指描述数据组织方式的 一组逻辑概念及它们之间的关系;
表空间:
是数据库 逻辑结构中的一个重要组成部分, 表空间可以存放各种应用对象: 表 索引... 每一个表空间由一个或多个数据库文件组成...
表空间的分类:
| 类别 | 说明 |
|---|---|
| 永久性表空间 | 一般用来保存 视图 过程 索引 等数据 SYSTEM USERS 表空间是默认安装的; |
| 临时性表空间 | 只用于保存系统中短期活动的数据 如果排序数据… |
| 撤销表空间 | 用来帮助回退未提交的事务数据, 已提的数据在这里是不可以恢复的; |
一般不需要建临时 和 撤销表空间,除非把它们转移到其它磁盘中以提高性能;
表空间的目的:
1. 对不同用户|不同模式对象 分配不同的表空间, 方便对用户数据的操作 对模式对象的管理...
2. 可以将不同的数据文件 创建到不同的磁盘中,有利于管理磁盘空间 提高
// 一般在Oracle系统安装并创建Oracle实例后,Oracle系统会自动建立多个表空间;
创建表空间
通过 CREATE TABLESPACE 命令创建表空间
语法
-- 创建表空间
-- 语法:
CREATE TABLESPACE tablespacename
DATAFILE 'filename' [ SIZE integer [ K | M ] ]
[ AUTOEXTEND [ OFF | ON ] ] ;
}
/*
tablespacename: 创建表空间的名称;
DATAFILE: 指定组成表空间的 一个/多个文件,当有多个数据文件使用逗号分隔;
filename: 数据文件的 路径和名称(一个多个逗号分隔);
SIZE: 可选项,指定文件的大小 k(千字节) M(兆字节)
AUTOEXTEND: 用来启用 或 禁用数据文件的自动扩展; 默认应该是 off;
可选属性: NO OFF
NO: 设置为NO 空间使用完毕之后,自动扩展属性;
OFF: 设置为OFF 则很容易出现,表空间剩余容量为0的情况下,使数据不能在存储到数据库中;
*/
实例:
-- 创建表空间:wsm_540
create tablespace wsm_540
datafile 'tbs540.dbf'
size 60m
autoextend on;
-- 登录的用户是system用户
-- 查询系统表空间 系统表
select * from dba_data_files; -- 可以查看当前的表空间..
修改表空间:
通过 ALTER TABLESPACE (+对应表空间名) 命令修改表空间;
语法:
-- 更改数据文件大小 50m:
Alter database datafile '表空间的datafile文件路径~' Resize 50M;
-- 更改表数据文件自增;
Alter database datafile '表空间的datafile文件路径~' Autoextend on;
-- 表空间的datafile,可以查询表 dba_data_files 得到~
-- .....以此类推....
-- 移动数据文件(三种..);
-- 方式一
alter tablespace 表空间名;
rename datafile '原生位置'
to '移动位置';
-- 方式二
--物理硬盘上移动数据文件
-- 方式三
alter tablespace tablespace_name offline; --(后续了解...)
删除表空间:
通过 DROP TABLESPACE (+对应表空间名) 命令删除表空间;
切记, Oracle不要轻易删除表空间, 更别不用sql命令直接找到文件形式手动删除;
容易导致Oracle与内部的配置不匹配影响不可逆异常!
语法:
drop tablespace 对应表空间名 including contents and datafiles; --(删除内容和文件)
-- 删除表空间之前最好,对数据库进行备份;
自定义用户管理:
当创建一个新的数据库时候,Oracle将创建出一些默认数据库用户...SYS System Scott等;
SYS用户
Oracle的一个超级用户,主要用来维护系统信息和管理实例 ,只能以SYSDBA或SYSOPER角色登录
System用户
Oracle默认的系统管理员,拥有DBA权限, 通常用来管理Oracle数据库的用户、权限和存储等, 只能以Normal(正常默认)方式登录;
Scott用户
Oracle 系统提供的一个测试用户,,,, 默认未解锁;
Scott用户模式包含四个示范表(测试表),其中一个是Emp表。使用USERS表空间存储模式对象。
通常情况下,出于安全考虑,对于不同的数据表需要设置不同的访问权限。
此时,就需要创建不同的用户。Oracle 中的CREATE USER命令用于创建新用户。
每个用户都有一个默认表空间和一个临时表空间。如果没有指定,Oracle 就将USERS设为默认表空间,将TEMP设为临时表空间。
解锁用户/设置修改密码:
# 系统级用户下:
# 解锁Scott 用户;
alter user scott account unlock;
# 修改Scott 用户密码为:tiger
alter user scott identified by tiger;
alter user 用户名 account lock; # 加锁)
alter user 用户名 account unlock; # 解锁)
conn 用户名/密码; # 可以连接数据库语法~
创建用户:
语法:
--创建用户,语法;
CREATE USER user --设置用户名
IDENTIFIED BY password --添加密码 (必须指定用户名和密码)
[DEFAULT TABLESPACE tablespace] --添加默认表空间
[TEMPORARY TABLESPACE tablespace] --添加了临时表空间 (建议:为用户指定默认表空间或临时表空间
[QUOTA {
integer [K|M] | UNLIMITED}ON tablespace --QUOTA:设置用户表空间限额,表空间为 默认表空间或临时表空间;
[QUOTA {
integer [K|M] | UNLIMITED}ON tablespace ] ...] --size_clause的单位可以是K|M,默认是UNLIMITED不限制
[PASSWORD EXPIRE ] --第一次登录时需要初始化密码
--创建用户之后别忘了,分配权限角色哦~不然无法任何操作..
-- 实例语法
create user 用户名 --设置用户名
identified by 密码 --添加密码
default tablespace 默认表空间名 --添加默认表空间
temporary tablespace 临时表空间 --添加了临时表空间
quota unlimited on 默认名 --没有空间大小的限制
quota 100m on 临时名 --临时文件大小100m限制
password expire --第一次登录时需要初始化密码
修改/删除用户
--修改密码
ALTER USER 用户名
IDENTIFIED by 修改后密码;
--删除用户
DROP User 用户名;
DROP User 用户名 CASCADE; --当用户拥有模式对象,时无法删除用户可以在后面加 CASCADE删除用户和模式对象;
数据库权限管理
权限是用户对一项功能的 执行权力(用户必须赋予相应的权限), Oracle中根据系统管理方式不同分为:系统权限 和 对象权限;
系统权限
指被授权的用户, 可以对数据库进行的操作..
系统权限是在数据库中执行某种系统级别的操作 或 针对某一类对象执行某种操作权力;
eg: CREATE TABLE :创建表 CREATE VIEW : 创建视图....等系统权限;
对象权限
指用户在数据库中具体对象所拥有的权限;
针对某个特定的模式对象执行的权力,如:数据库中的某个表,视图,序列,存储过程等;
角色
角色是具有名称的一组权限的组合,使用角色可以更加方便 和 高效的对权限进行管理,所以数据库管理员通常使用角色对用户进行授予权限;
Oracle数据库用户有两种途径获得权限;
1.管理员直接向用户授予权限;
2.管理员将权限授予角色,然后在将 角色授予一个或多个用户.....
Oracle常用的系统提供的角色:
CONNECT : 临时用户,特指不需要建表的用户,通常只赋予他们connect role.
RESOURCE : 更可靠和正式的数据库用户可以授予resource,包括select/insert/update和delete等..创建表、视图、序列...
DBA : 拥有所有的系统权限,包括无限制的空间限额和给其他用户授予各种权限的能力。
授予权限语法:
-- 授予权限语法
-- 授予前,当前登录用户需要是一个高级的用户..
GRANT 权限|角色 TO 用户名;
-- 给用户名 WSM授予CONNECT 和 RESOURCE 角色权限;
grant connect,RESOURCE to WSM; -- 逗号分隔可以同时赋值两个;
-- 撤销用户角色|权限;
REVOKE 权限|角色 FROM 用户;
序列
序列是用于生成唯一、连续序号的数据库对象; 通常用来生成主键或唯一键的值;
序列可以是升序的,也可以是降序的...
使用 CREATE SEQUENCE 语句创建序列
创建序列语法:
CREATE SEQUENCE 序列名
[START WITH n] --都是可选项;
[INCREMENT BY n]
[{MAXVALUE/ MINVALUE n| NOMAXVALUE}]
[{
CYCLE|NOCYCLE}]
[{CACHE n| NOCACHE}];
START WITH 定义序列的初始值(即产生的第一个值),默认为1。
INCREMENT BY 用于定义序列的步长(间隔) 默认为1,如果出现负值,则代表序列是按照 降序排序的;
MAXVALUE 定义序列生成器能产生的最大值。
NOMAXVALUE 是默认选项,代表没有最大值定义,这时对于递增Oracle序列,系统能够产生的最大值是10的27次方;对于递减序列,最大值是-1。
MINVALUE定义序列生成器能产生的最小值。
NOMAXVALUE 是默认选项,代表没有最小值定义,这时对于递减序列,系统能够产生的最小值是?10的26次方;对于递增序列,最小值是1。
CYCLE和NOCYCLE 表示当序列生成器的值达到限制值后是否循环。
CYCLE代表循环,NOCYCLE代表不循环。
如果循环,则当递增序列达到最大值时,循环到最小值;对于递减序列达到最小值时,循环到最大值。
如果不循环,达到限制值后,继续产生新值就会发生错误。
CACHE(缓冲)定义存放序列的内存块的大小,默认为20。
NOCACHE表示不对序列进行内存缓冲。对序列进行内存缓冲,可以改善序列的性能。
访问序列
创建序列之后, 可以通过 NEXTVAL 和 CURRVAL 序列伪列,来访问该序列的值 (实现新增..等操作) ;
NEXTVAL 返回序列中下一个有效的值,任何用户(表)都可以引用。
CURRVAL 中存放序列的当前值, NEXTVAL应在 CURRVAL之前指定二者应同时有效。
使用序列
空理论说序列没有什么用, 纸上谈兵永远比不上现场实战!!
--切换scott用户
select * from dept; --系统提供表 dept
--创建一个序列 dept_insert
--起始位置40
create sequence dept_insert
start with 40 --起始位置 41
increment by 1 --每次增长的个数 1
minvalue 1 --最小值 1
nomaxvalue --没有最大值
cache 10 --数据库事先缓存10个备用~
--利用序列,新增dept
insert into dept values(dept_insert.NEXTVAL,'asda','dasdsa'); --41
insert into dept values(dept_insert.NEXTVAL,'asda','dasdsa'); --42
insert into dept values(dept_insert.NEXTVAL,'asda','dasdsa'); --43
--在单独查询
select dept_insert.NEXTVAL from dual; --44
select dept_insert.NEXTVAL from dual; --45
--CURRVAL不会获取下一个,而是当前值
select dept_insert.CURRVAL from dual; --45
使用序列可以设置Oracle 中的主键…确保某个值在表在唯一;
对于主键 Oracle还可以使用 SYS_GUID函数生成32位的唯一编码作为主键;
SYS_GUID() :源自对数据库进行访问的时间戳 和 机器标识符; 不同时间产生不同的结果,可以作为主键使用确保了唯一性;
可以多运行几次来比较结果~ SELECT SYS_GUID() From dual;
更改序列
使用 ALTER SEQUENCE 语句修改序列,不能更改序列的 START WITH参数;
语法:
/*
使用序列会产生裂缝:
回滚 系统异常 多个表同时使用同一序列....序列使用顺序紊乱;
*/
--语法
ALTER SEQUENCE 序列名
[INCREMENT BY n]
[{MAXVALUE/ MINVALUE n| NOMAXVALUE}]
[{
CYCLE|NOCYCLE}]
[{CACHE n| NOCACHE}];
--修改序列的注意事项:
--必须是序列的拥有者或对序列有 ALTER 权限
--只有将来的序列值会被改变
--改变序列的初始值只能通过删除序列之后重建序列的方法实现;
删除序列
使用DROP SEQUENCE语句删除序列
语法:
-- 上面说到序列不可以修改起始值;
-- 但是删除可以做到类似的操作( 把A序列删除,在创建一个A序列更改其属性...实现相同的效果 )
DROP SEQUENCE 序列名; --删除序列
同义词
同义词概念
Oracle的同义词(synonyms)从字面上理解就是别名的意思,和视图的功能类似,就是一种映射关系。
同义词是数据库对象的一个别名,经常用于简化对象访问和提高对象访问的安全性。
对象访问:A用户模式下 查 B模型下表 SELECT * FROM B.表名; 简化代码提高安全(轻松知道对于模式位置);
在使用同义词时,Oracle数据库将它翻译成对应方案对象的名字。
与视图类似,同义词并不占用实际存储空间,只有在数据字典中保存了同义词的定义。
用途:
同义词是现有对象的一个别名:
简化SQL语句 隐藏对象的名称和所有者 提供对对象的公共访问
分类:
同义词共有两种类型:
分别是Oracle公用同义词与Oracle私有同义词。普通用户创建的同义词一般都是私有同义词;
公有同义词一般由DBA创建,普通用户如果希望创建同义词,则需要CREATE PUBLIC SYNONYM这个系统权限。
私有同义词
只能被当前模式的用户访问, 且私有同义词名称 不可以与当前模式对象名相同(表名);
语法:
-- 私有同义词
CREATE OR REPLACE SYNONYM 同义词名 FOR 模式对象.原表名;
-- OR REPLACE:可选,指如果已存在该同义词替换同义词;
公有同义词
公有同义词可被所有的数据库用户访问
语法:
-- 共有同义词
CREATE OR REPLACE PUBLIC SYNONYM 同义词名 FOR 模式对象.原表名;
当前私有同义词 和 共有同义词同名时候优先选择 私有同义词作为目标...
删除同义词:
-- 删除私有
DROP SYNONYM 名;
-- 删除共有
DROP PUBLIC SYNONYM 名;
--只是删除同义词哦,跟对象表没有任何影响!!
索引
个人在学习mysql 对索引有一点点的了解.. 主键索引 唯一索引 空间啥的...
刚才回头看了看感觉有点low就不cope重新整理一个...
索引作用:提高了数据库 检索查询速度,改善数据库性能;
索引简介
索引是数据库对象之一,用于加快数据的检索,类似于书籍的索引(目录)。
在数据库中索引可以减少数据库程序查询结果时需要读取的数据量 (类似于在书籍中我们利用索引可以不用翻阅整本书即可找到想要的信息。)
oracle会自动管理索引,索引删除,不会对表产生影响;
索引对用户是透明的,无论表上是否有索引,sql语句的用法不变, oracle创建主键时会自动在该列上创建主键索引;
索引分类
| 物理分类 | 逻辑分类 |
|---|---|
| 分区或非分区索引 | 单列或组合索引 |
| B树索引 | 唯一或非唯一索引 |
| 正常或反向键索引 | 基于函数索引 |
| 位图索引 | |
| 。。。。 | 。。。。 |
索引原理
1.若没有索引 搜索某个记录时(例如查找name='wish')需要搜索所有的记录,因为不能保证只有一个wish,必须全部搜索一遍
2.若在name上建立索引,oracle会对全表进行一次搜索,将每条记录的name值排列,然后构建索引条目(name和rowid),存储到索引段中,查询name为wish时即可直接查找对应地方, 而快速的找到这些记录...
3.创建了索引并不一定就会使用,oracle自动统计表的信息后,决定是否使用索引,表中数据很少时使用全表扫描速度已经很快,没有必要使用索引
索引使用(创建、修改、删除、查看)
1.创建索引语法
--创建索引: Oracle中会有专门的文件用来存储创建的索引,删除不会对原表造成影响(注意命名不能重复..);
CREATE [UNIQUE]|[BITMAP] INDEX 创建索引名
ON 指定创建索引的表名([column1 [ASC|DESC],column2 [ASC|DESC],…])
[TABLESPACE 为索引指定表空间]
[.....可选,还有很多属性]
/*
[UNIQUE]|[BITMAP]可选属性:
UNIQUE唯一索引 或 BITMAP视图索引,不指定索引默认B-tree索引.
指定创建索引的表名:
(列1,列2) 可以基于多个列创建索引,列之间逗号分隔.
TABLESPACE可选属性:
为索引指定表空间.
*/
索引建立原则
表中导入数据后再创建索引,否则每次表中插入数据时都必须更新索引
在适当的表和字段上创建索引
小表(数据少的表)不要建立索引, 索引虽然可以提高效率, 前提是对于高量的数据;对于低数据,数据的性能已经够强大了..还非要用索引来多此一举...反而影响效率;
对于不经常作为条件的列,不适合作为索引..经常排序分组的列可以作为索引;
限制表中索引的数目
索引越多,在修改表时对索引做出修改的工作量越大
2.修改索引
重命名索引
alter index 旧名字 rename to 新索引名;
合并索引
表使用一段时间后在索引中会产生碎片,此时索引效率会降低。
可以选择重建索引或者合并索引,合并索引方式更好些,无需额外存储空间,代价较低
alter index 索引名 coalesce;
重建索引
方式一 删除原来的索引,重新建立索引
方式二
语法: alter index 索引名 rebuild [内部过程和注意点] ;
举例: alter index 索引名 rebuild TABLESPACE 表空间; 修改索引表空间...
何时重建索引:
用户表被移动到新的表空间后, 表上的索引并不会自动转移, 此时需要手动移动...
索引中包含很多已删除的项, 对表进行频繁的删除...造成索引浪费可以重建索引;
3.删除索引
语法: drop index 索引名;
SqlServer中创建索引必须指定对应的表名, 而Oracle 索引名在用户账户这是唯一的,删除时不需要指定表名;
4.查看索引
索引是透明的, 不会影响正常的SQL语句, 使用时就正常的查询即可...
假设给 A表 A列设置索引;
SELECT * FORM A表 WHERE A列 = '...'; -- 即可,Oracle会默认使用索引...
使用工具的话可以选中查询 F5查看SQL执行顺序. (尝试一次有索引一次没索引的顺序)
常见索引
唯一索引: 定义索引中的列,在表中唯一存在的数据;
非唯一索引: 指列的数据表中可以重复... 无任何声明默认就是非唯一索引;
创建一个唯一索引 AA
CREATE UNIQUE INDEX aa ON a表(列1,列2) --A表中的 列1+列2的数据在表中是唯一的...
-- a表(列1,列2) 这也是一种复合索引..
--组合索引
--创建一个非唯一组合索引
create index ENAME_JOB on EMP(ENAME,JOB)
--使用了索引
SELECT * FROM EMP WHERE ENAME = 'SMITH' AND JOB = 'CLERK';
--而,并不是使用了组合索引,组合索引内部,根据两个列拼接进行查询..
SELECT * FROM EMP WHERE JOB = 'CLERK' AND ENAME = 'SMITH';
DROP Index ENAME_JOB; --删除索引;

B数索引
oracle中最常用的索引;B树索引就是一颗二叉树;
叶子节点(双向链表)包含索引列和指向表中每个匹配行的ROWID值
所有叶子节点具有相同的深度,因而不管查询条件怎样,查询速度基本相同,能够适应精确查询、模糊查询和比较查询
创建例子
craete index 索引名 on 表(列);
适合使用场景:
列基数(列不重复值的个数)大时适合使用B数索引
举例
sd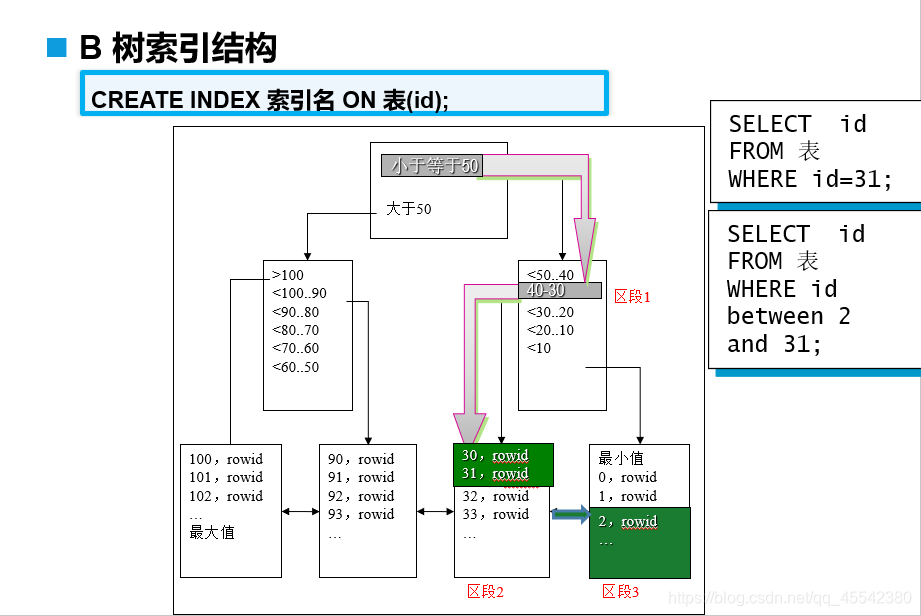
索引的遍历如下:
先找到id 小于等于50 的分支块,再找40~30 之间的分支块,再找到id 为31 对应的叶子节点。
根据rowid 的值找到数据块中相应的记录并显示出来。如果查找between 2 and 31 之间的数据。
那么这时,Oracle已经找到了31这个值,之后可以通过叶节点双向连接.
平行的查找包含2的索引块,完成对于id的查询。
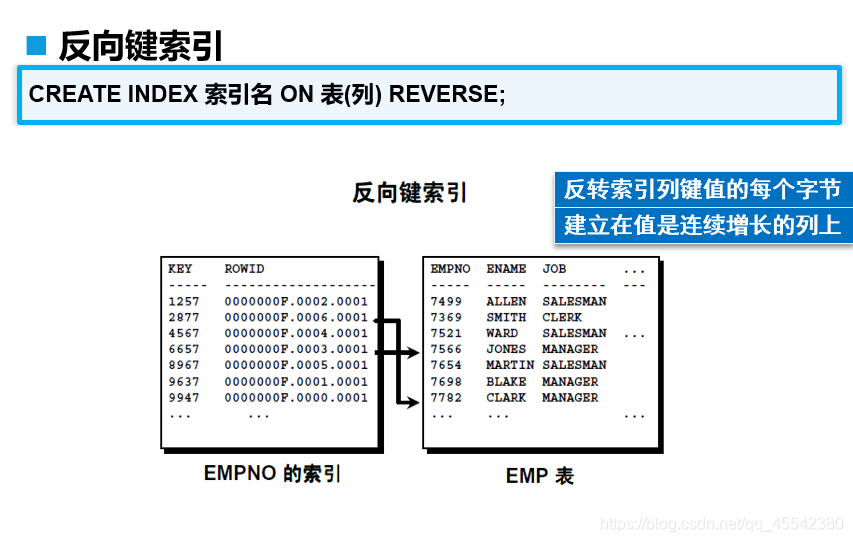
反向键索引
反向键索引:在抱持列顺序的同时,反转索引列的字节
即:123 发转 321
好处:
对于像身份证这种数据, 前一段都是 320xxxx的而关键是后面的不同...对这种数据列设置 **反向键索引**
查询时:根据输入的值, 反着进行查找效率极高...
位图索引
位图索引的优点在于,它适用于低基数列 (即该列的值是有限的,理论上不会是无穷大的)
eg: 员工表的工种, 即使员工表 员工有几万条而职位工种也就是那几种;
优点:
1.对于大批即时查询的数据,可以减少响应时间
2.相比其它索引,占用空间明显减少
3.即使在很低的终端配置上,也能获得显著的性能;
注意:位图索引,不应该频繁的 insert update delete ...需要重新锁定!
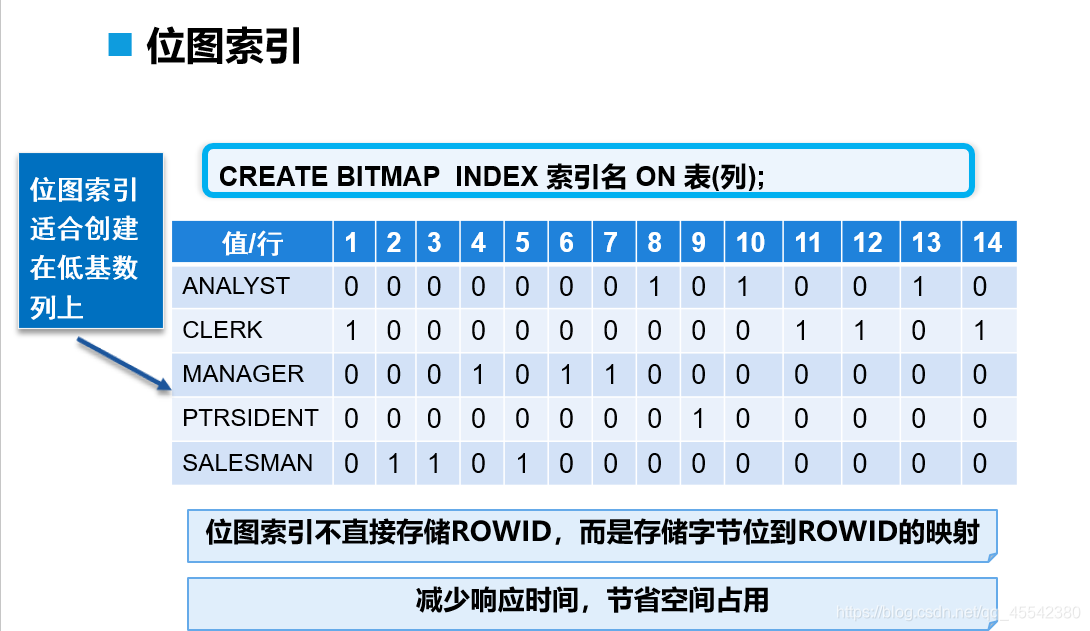
给员工表的 job 列创建位图索引;
对于 job 这种低基数列; 值不是很多的列…
位图索引会以一种:1/0 形式存储, 1存在 0不存在表示;
底层以 记录下标 及列的各值进行管理…
索引注意事项:
- 通配符在搜索词首出现时,oracle不能使用索引,eg:
--我们在name上创建索引;
create index index_name on student('name');
--下面的方式oracle不适用name索引
select * from student where name like '%wish%';
--如果通配符出现在字符串的其他位置时,优化器能够利用索引;如下:
select * from student where name like 'wish%';
- 不要在索引列上使用not,可以采用其他方式代替如下:(oracle碰到not会停止使用索引,而采用全表扫描)
select * from student where not (score=100);
select * from student where score <> 100;
--替换为
select * from student where score>100 or score <100
- 索引上使用空值比较将停止使用索引, eg:
select * from student where score is not null;