0.摘要
上一节我们学习了生成器,它是一类特殊迭代器。这一节我们将学习类和迭代器。
1.类的定义
P y t h o n Python Python是完全面向对象的:你可以定义自己的类,从你自己或系统自带的类继承,并生成实例。
在 P y t h o n Python Python里定义一个类非常简单。就像函数一样, 没有分开的接口定义。 P y t h o n Python Python类以保留字 c l a s s class class 开始, 后面跟类名。 技术上来说,只需要这么多就够了,因为一个类不是必须继承其他类。
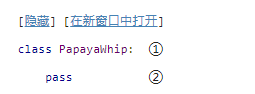
这个类的名字叫 P a p a y a W h i p PapayaWhip PapayaWhip,它没有任何方法和属性。 p a s s pass pass 就像 J a v a Java Java 或 C C C中的空大括号对 ({}) 。
1.1__init__() 方法
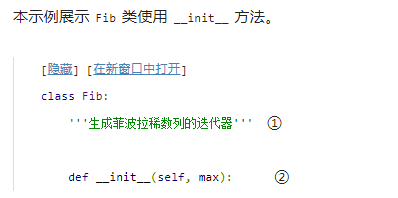
类同样可以 (而且应该) 具有 d o c s t r i n g docstring docstring, 与模块和方法一样。
类实例创建后, _ _ i n i t _ _ ( ) \_\_init\_\_() __init__()方法被立即调用。很容易将其——但技术上来说不正确——称为该类的构造函数”。 很容易,因为它看起来很像 C + + C++ C++ 的构造函数(按约定, _ _ i n i t _ _ ( ) \_\_init\_\_() __init__()是类中第一个被定义的方法),行为一致(是类的新实例中第一片被执行的代码),看起来完全一样。 错了,因为 _ _ i n i t _ _ ( ) \_\_init\_\_() __init__()方法调用时,对象已经创建了,你已经有了一个合法类对象的引用。
每个方法的第一个参数,包括 _ _ i n i t _ _ ( ) \_\_init\_\_() __init__() 方法,永远指向当前的类对象。 习惯上,该参数叫 s e l f self self。 该参数和 c + + c++ c++或 J a v a Java Java中 t h i s this this 角色一样, 但 s e l f self self 不是 P y t h o n Python Python的保留字, 仅仅是个命名习惯。 虽然如此,请不要取别的名字,只用 s e l f self self; 这是一个很强的命名习惯。
在 _ _ i n i t _ _ ( ) \_\_init\_\_() __init__()方法中, s e l f self self 指向新创建的对象; 在其他类对象中, 它指向方法所属的实例。尽管需在定义方法时显式指定 s e l f self self ,但是调用方法时不需要明确指定。 P y t h o n Python Python 会自动添加。
2.实例化类
P y t h o n Python Python 中实例化类很直接。实例化类时就像调用函数一样简单,将 _ _ i n i t _ _ ( ) \_\_init\_\_() __init__() 方法需要的参数传入,返回值就是新创建的对象。

P y t h o n Python Python里面, 和调用函数一样简单的调用一个类来创建该类的新实例。 与 c + + c++ c++ 或 J a v a Java Java不一样,没有显式的 n e w new new 操作符。
每个类实例具有一个内建属性, _ _ c l a s s _ _ \_\_class\_\_ __class__, 它是该对象的类。 J a v a Java Java 程序员可能熟悉 C l a s s Class Class 类, 包含方法如 g e t N a m e ( ) getName() getName() 和 g e t S u p e r c l a s s ( ) getSuperclass() getSuperclass() 获取对象相关元数据。 P y t h o n Python Python里面, 这类元数据由属性提供,但思想一致。
3.实例变量

s e l f . m a x self.max self.max是什么? 它就是实例变量。 与作为参数传入 _ _ i n i t _ _ ( ) \_\_init\_\_() __init__() 方法的 m a x max max完全是两回事。 s e l f . m a x self.max self.max 是实例内 “全局” 的。 这意味着可以在其他方法中访问它(感觉应该就是类的数据成员吧)。

实例变量特定于某个类的实例。例如,如果你创建 F i b Fib Fib 的两个具有不同最大值的实例,每个实例会记住自己的值。

4.斐波那契迭代器


当调用 i t e r ( f i b ) iter(fib) iter(fib)的时候, _ _ i t e r _ _ ( ) \_\_iter\_\_() __iter__()就会被调用(正如你等下会看到的, f o r for for 循环会自动调用它, 你也可以自己手动调用)。在完成迭代器初始化后,(在本例中, 重置我们两个计数器 s e l f . a self.a self.a 和 s e l f . b self.b self.b), _ _ i t e r _ _ ( ) \_\_iter\_\_() __iter__() 方法能返回任何实现了 _ _ n e x t _ _ ( ) \_\_next\_\_() __next__() 方法的对象。 在本例(甚至大多数例子)中, _ _ i t e r _ _ ( ) \_\_iter\_\_() __iter__() 仅简单返回 s e l f self self, 因为该类实现了自己的 _ _ n e x t _ _ ( ) \_\_next\_\_() __next__() 方法。
在迭代器的实例中调用 n e x t ( ) next() next()方法时, _ _ n e x t _ _ ( ) \_\_next\_\_() __next__() 会自动调用。
当 _ _ n e x t _ _ ( ) \_\_next\_\_() __next__() 方法抛出 S t o p I t e r a t i o n StopIteration StopIteration 异常, 这是给调用者表示迭代完成了的信号。 和大多数异常不同,这不是错误;它是正常情况,仅表示迭代器没有值可产生了。 如果调用者是 f o r for for 循环, 它会注意到该 S t o p I t e r a t i o n StopIteration StopIteration 异常并优雅的退出(换句话说,它会捕获该异常)。这就是 f o r for for 循环的关键。
为了分离出下一个值,迭代器的 _ _ n e x t _ _ ( ) \_\_next\_\_() __next__() 方法简单 r e t u r n return return该值。不要使用 y i e l d yield yield;该语法上的小甜头(语法糖)仅用于你使用生成器的时候。现在我们在创建迭代器,请使用 r e t u r n return return。
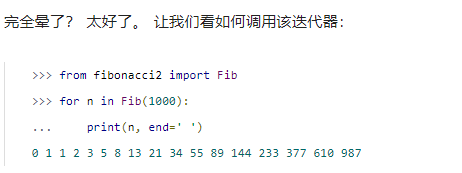
下面我们来分析, f o r for for究竟干了什么:
首先, f o r for for 循环调用 F i b ( 1000 ) Fib(1000) Fib(1000)。这返回 F i b Fib Fib 类的实例。叫它 f i b _ i n s t fib\_inst fib_inst。
然后 f o r for for 循环调用 i t e r ( f i b _ i n s t ) iter(fib\_inst) iter(fib_inst),它返回迭代器。叫它 f i b _ i t e r fib\_iter fib_iter。本例中, f i b _ i t e r = = f i b _ i n s t fib\_iter == fib\_inst fib_iter==fib_inst,因为 _ _ i t e r _ _ ( ) \_\_iter\_\_() __iter__() 方法返回 s e l f self self,但 f o r for for 循环不知道(也不关心)那些。
接下来 f o r for for 循环调用 n e x t ( f i b _ i t e r ) next(fib\_iter) next(fib_iter),所以该对象的 _ _ n e x t _ _ ( ) \_\_next\_\_() __next__() 方法被调用,它计算斐波那契数列并返回, f o r for for 拿到该值并将其赋给 n n n,然后执行循环体并进入下一次循环。
当 n e x t ( f i b _ i t e r ) next(fib\_iter) next(fib_iter) 抛出 S t o p I t e r a t i o n StopIteration StopIteration 异常时, f o r for for循环捕获该异常并退出循环。
5.复数规则迭代器
还记得我们上一章写过的复数规则转换吗?我们将会用一种更好的方式实现它。

因此这是一个实现了 _ _ i t e r _ _ ( ) \_\_iter\_\_() __iter__() 和 _ _ n e x t _ _ ( ) \_\_next\_\_() __next__()的类。所以它可以被用作迭代器。然后,你实例化它并将其赋给 r u l e s rules rules 。这只发生一次,在 i m p o r t import import的时候。

在继续之前,让我们近观 r u l e s _ f i l e n a m e rules\_filename rules_filename。它没在 _ _ i t e r _ _ ( ) \_\_iter\_\_() __iter__() 方法中定义。事实上,它没在任何方法中定义。它定义于类级别。它是类变量, 尽管访问时和实例变量一样 ( s e l f . r u l e s _ f i l e n a m e self.rules\_filename self.rules_filename), L a z y R u l e s LazyRules LazyRules 类的所有实例共享该变量。很像类的静态成员,也可以直接通过类名访问。

类的每个实例继承了 r u l e s f i l e n a m e rules_filename rulesfilename 属性及它在类中定义的值。
修改一个实例属性的值不影响其他实例……
……也不会修改类的属性。可以使用特殊的 _ _ c l a s s _ _ \_\_class\_\_ __class__ 属性来访问类属性(与此相对的是单独实例的属性)。
如果修改类属性,所有仍然继承该实例的值的实例(如这里的 r 1 r1 r1 )会受影响。
已经覆盖( o v e r r i d d e n overridden overridden)了该属性(如这里的 r 2 r2 r2 )的所有实例将不受影响。

每个 _ _ i t e r _ _ ( ) \_\_iter\_\_() __iter__() 方法都需要做的就是必须返回一个迭代器。在本例中,返回 s e l f self self,意味着该类定义了 _ _ n e x t _ _ ( ) \_\_next\_\_() __next__() 方法,由它来关注整个迭代过程中的返回值。


r e a d l i n e ( ) readline() readline() 方法(注意:是单数,不是复数 r e a d l i n e s ( ) readlines() readlines())从一个打开的文件中精确读取一行,即下一行(文件对象同样也是迭代器! 它自始至终是迭代器……)。
如果有一行 r e a d l i n e ( ) readline() readline() 可以读, l i n e line line 就不会是空字符串。 甚至文件包含一个空行, l i n e line line 将会是一个字符的字符串 ‘\n’ (回车换行符)。 如果 l i n e line line 是真的空字符串,就意味着文件已经没有行可读了。
那说明我们到了文件的结尾。所以应该关闭文件并抛出 S t o p I t e r a t i o n StopIteration StopIteration 异常,标志着迭代器结束。

这一步其实就是判断所需要的规则是否已经缓存过了,如果是那么就直接返回结果,这样就不需要重复读文件了。即使 _ _ i t e r ( ) _ _ \_\_iter()\_\_ __iter()__被多次调用,它也只会重置 i n d e x index index的值,并不会修改规则的缓存 c a c h e cache cache。
现在的实现已经很棒了:
- 最小化初始代价。在 i m p o r t import import 时发生的唯一的事就是实例化一个单一的类并打开一个文件(但并不读取)。
- 最大化性能。前述示例会在每次你想让一个单词变复数时,读遍文件并动态创建功能。本版本将在创建的同时缓存功能,在最坏情况下,仅需要读完一遍文件,无论你要让多少单词变复数。
- 将代码和数据分离。所有模式被存在一个分开的文件。代码是代码,数据是数据,二者永远不会交织。
但是它可能有一些潜在的问题:模式文件一直处于打开状态,只有当 P y t h o n Python Python退出或最后一个 L a z y R u l e s LazyRules LazyRules 类的实例销毁时,这个文件才会被关闭。你可以选择其它的实现方式,比如在初始化过程中直接读完整个文件,然后关闭它;或者每次读取结束时利用 t e l l ( ) tell() tell()方法保存读取的位置,再次打开时通过 s e e k ( ) seek() seek()方法定位。