摘要:
Java 中的 String类 是我们日常开发中使用最为频繁的一个类,但要想真正掌握的这个类却不是一件容易的事情。笔者为了还原String类的真实全貌,先分为上、下两篇博文来综述Java中的String类。笔者从Java内存模型展开,结合 JDK 中 String类的源码进行深入分析,特别就 String类与享元模式,String常量池,String不可变性,String对象的创建方式,String与正则表达式,String与克隆,String、StringBuffer 和 StringBuilder 的区别等几个方面对其进行详细阐述、总结,力求能够对String类的原理和使用作一个最全面和最准确的介绍。
原文链接:
https://blog.csdn.net/justloveyou_/article/details/60983034六. 字符串常量池
1、字符串池
字符串的分配,和其他的对象分配一样,耗费高昂的时间与空间代价。JVM为了提高性能和减少内存开销,在实例化字符串字面值的时候进行了一些优化。为了减少在JVM中创建的字符串的数量,字符串类维护了一个字符串常量池,每当以字面值形式创建一个字符串时,JVM会首先检查字符串常量池:如果字符串已经存在池中,就返回池中的实例引用;如果字符串不在池中,就会实例化一个字符串并放到池中。Java能够进行这样的优化是因为字符串是不可 变的,可以不用担心数据冲突进行共享。 例如:
public class Program
{
public static void main(String[] args)
{
String str1 = "Hello";
String str2 = "Hello";
System.out.print(str1 == str2); // true
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
一个初始为空的字符串池,它由类 String 私有地维护。当以字面值形式创建一个字符串时,总是先检查字符串池是否含存在该对象,若存在,则直接返回。此外,通过 new 操作符创建的字符串对象不指向字符串池中的任何对象。
2、手动入池
一个初始为空的字符串池,它由类 String 私有地维护。 当调用 intern 方法时,如果池已经包含一个等于此 String 对象的字符串(用 equals(Object) 方法确定),则返回池中的字符串。否则,将此 String 对象添加到池中,并返回此 String 对象的引用。特别地,手动入池遵循以下规则:
对于任意两个字符串 s 和 t ,当且仅当 s.equals(t) 为 true 时,s.intern() == t.intern() 才为 true 。
public class TestString{
public static void main(String args[]){
String str1 = "abc";
String str2 = new String("abc");
String str3 = s2.intern();
System.out.println( str1 == str2 ); //false
System.out.println( str1 == str3 ); //true
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
所以,对于 String str1 = “abc”,str1 引用的是 常量池(方法区) 的对象;而 String str2 = new String(“abc”),str2引用的是 堆 中的对象,所以内存地址不一样。但是由于内容一样,所以 str1 和 str3 指向同一对象。
3、实例
看下面几个场景来深入理解 String。
1) 情景一:字符串常量池
Java虚拟机(JVM)中存在着一个字符串常量池,其中保存着很多String对象,并且这些String对象可以被共享使用,因此提高了效率。之所以字符串具有字符串常量池,是因为String对象是不可变的,因此可以被共享。字符串常量池由String类维护,我们可以通过intern()方法使字符串池手动入池。
String s1 = "abc";
//↑ 在字符串池创建了一个对象
String s2 = "abc";
//↑ 字符串pool已经存在对象“abc”(共享),所以创建0个对象,累计创建一个对象
System.out.println("s1 == s2 : "+(s1==s2));
//↑ true 指向同一个对象,
System.out.println("s1.equals(s2) : " + (s1.equals(s2)));
//↑ true 值相等
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2) 情景二:关于new String(“…”)
String s3 = new String("abc");
//↑ 创建了两个对象,一个存放在字符串池中,一个存在与堆区中;
//↑ 还有一个对象引用s3存放在栈中
String s4 = new String("abc");
//↑ 字符串池中已经存在“abc”对象,所以只在堆中创建了一个对象
System.out.println("s3 == s4 : "+(s3==s4));
//↑false s3和s4栈区的地址不同,指向堆区的不同地址;
System.out.println("s3.equals(s4) : "+(s3.equals(s4)));
//↑true s3和s4的值相同
System.out.println("s1 == s3 : "+(s1==s3));
//↑false 存放的地区都不同,一个方法区,一个堆区
System.out.println("s1.equals(s3) : "+(s1.equals(s3)));
//↑true 值相同
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
通过上一篇博文我们知道,通过 new String(“…”) 来创建字符串时,在该构造函数的参数值为字符串字面值的前提下,若该字面值不在字符串常量池中,那么会创建两个对象:一个在字符串常量池中,一个在堆中;否则,只会在堆中创建一个对象。对于不在同一区域的两个对象,二者的内存地址必定不同。
3) 情景三:字符串连接符“+”
String str2 = "ab"; //1个对象
String str3 = "cd"; //1个对象
String str4 = str2+str3;
String str5 = "abcd";
System.out.println("str4 = str5 : " + (str4==str5)); // false
- 1
- 2
- 3
- 4
- 5
我们看这个例子,局部变量 str2,str3 指向字符串常量池中的两个对象。在运行时,第三行代码(str2+str3)实质上会被分解成五个步骤,分别是:
(1). 调用 String 类的静态方法 String.valueOf() 将 str2 转换为字符串表示;
(2). JVM 在堆中创建一个 StringBuilder对象,同时用str2指向转换后的字符串对象进行初始化;
(3). 调用StringBuilder对象的append方法完成与str3所指向的字符串对象的合并;
(4). 调用 StringBuilder 的 toString() 方法在堆中创建一个 String对象;
(5). 将刚刚生成的String对象的堆地址存赋给局部变量引用str4。
而引用str5指向的是字符串常量池中字面值”abcd”所对应的字符串对象。由上面的内容我们可以知道,引用str4和str5指向的对象的地址必定不一样。这时,内存中实际上会存在五个字符串对象: 三个在字符串常量池中的String对象、一个在堆中的String对象和一个在堆中的StringBuilder对象。
4) 情景四:字符串的编译期优化
String str1 = "ab" + "cd"; //1个对象
String str11 = "abcd";
System.out.println("str1 = str11 : "+ (str1 == str11)); // true
final String str8 = "cd";
String str9 = "ab" + str8;
String str89 = "abcd";
System.out.println("str9 = str89 : "+ (str9 == str89)); // true
//↑str8为常量变量,编译期会被优化
String str6 = "b";
String str7 = "a" + str6;
String str67 = "ab";
System.out.println("str7 = str67 : "+ (str7 == str67)); // false
//↑str6为变量,在运行期才会被解析。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
Java 编译器对于类似“常量+字面值”的组合,其值在编译的时候就能够被确定了。在这里,str1 和 str9 的值在编译时就可以被确定,因此它们分别等价于: String str1 = “abcd”; 和 String str9 = “abcd”;
Java 编译器对于含有 “String引用”的组合,则在运行期会产生新的对象 (通过调用StringBuilder类的toString()方法),因此这个对象存储在堆中。
4、小结
使用字面值形式创建的字符串与通过 new 创建的字符串一定是不同的,因为二者的存储位置不同:前者在方法区,后者在堆;
我们在使用诸如String str = “abc”;的格式创建字符串对象时,总是想当然地认为,我们创建了String类的对象str。但是事实上, 对象可能并没有被创建。唯一可以肯定的是,指向 String 对象 的引用被创建了。至于这个引用到底是否指向了一个新的对象,必须根据上下文来考虑;
字符串常量池的理念是 《享元模式》;
Java 编译器对 “常量+字面值” 的组合 是当成常量表达式直接求值来优化的;对于含有“String引用”的组合,其在编译期不能被确定,会在运行期创建新对象。
七. 三大字符串类 : String、StringBuilder 和 StringBuffer
1. String 与 StringBuilder
简要的说, String 类型 和 StringBuilder 类型的主要性能区别在于 String 是不可变的对象。 事实上,在对 String 类型进行“改变”时,实质上等同于生成了一个新的 String 对象,然后将指针指向新的 String 对象。由于频繁的生成对象会对系统性能产生影响,特别是当内存中没有引用指向的对象多了以后,JVM 的垃圾回收器就会开始工作,继而会影响到程序的执行效率。所以,对于经常改变内容的字符串,最好不要声明为 String 类型。但如果我们使用的是 StringBuilder 类,那么情形就不一样了。因为,我们的每次修改都是针对 StringBuilder 对象本身的,而不会像对String操作那样去生成新的对象并重新给变量引用赋值。所以,在一般情况下,推荐使用 StringBuilder ,特别是字符串对象经常改变的情况下。
在某些特别情况下,String 对象的字符串拼接可以直接被JVM 在编译期确定下来,这时,StringBuilder 在速度上就不占任何优势了。
因此,在绝大部分情况下, 在效率方面:StringBuilder > String .
2.StringBuffer 与 StringBuilder
首先需要明确的是,StringBuffer 始于 JDK 1.0,而 StringBuilder 始于 JDK 5.0;此外,从 JDK 1.5 开始,对含有字符串变量 (非字符串字面值) 的连接操作(+),JVM 内部是采用 StringBuilder 来实现的,而在这之前,这个操作是采用 StringBuffer 实现的。
JDK的实现中 StringBuffer 与 StringBuilder 都继承自 AbstractStringBuilder。AbstractStringBuilder的实现原理为:AbstractStringBuilder中采用一个 char数组 来保存需要append的字符串,char数组有一个初始大小,当append的字符串长度超过当前char数组容量时,则对char数组进行动态扩展,即重新申请一段更大的内存空间,然后将当前char数组拷贝到新的位置,因为重新分配内存并拷贝的开销比较大,所以每次重新申请内存空间都是采用申请大于当前需要的内存空间的方式,这里是 2 倍。
StringBuffer 和 StringBuilder 都是可变的字符序列,但是二者最大的一个不同点是:StringBuffer 是线程安全的,而 StringBuilder 则不是。StringBuilder 提供的API与StringBuffer的API是完全兼容的,即,StringBuffer 与 StringBuilder 中的方法和功能完全是等价的,但是后者一般要比前者快。因此,可以这么说,StringBuilder 的提出就是为了在单线程环境下替换 StringBuffer 。
在单线程环境下,优先使用 StringBuilder。
3.实例
1). 编译时优化与字符串连接符的本质
我们先来看下面这个例子:
public class Test2 {
public static void main(String[] args) {
String s = "a" + "b" + "c";
String s1 = "a";
String s2 = "b";
String s3 = "c";
String s4 = s1 + s2 + s3;
System.out.println(s);
System.out.println(s4);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
由上面的叙述,我们可以知道,变量s的创建等价于 String s = “abc”; 而变量s4的创建相当于:
StringBuilder temp = new StringBuilder(s1);
temp.append(s2).append(s3);
String s4 = temp.toString();
- 1
- 2
- 3
但事实上,是不是这样子呢?我们将其反编译一下,来看看Java编译器究竟做了什么:
//将上述 Test2 的 class 文件反编译
public class Test2
{
public Test2(){}
public static void main(String args[])
{
String s = "abc"; // 编译期优化
String s1 = "a";
String s2 = "b";
String s3 = "c";
//底层使用 StringBuilder 进行字符串的拼接
String s4 = (new StringBuilder(String.valueOf(s1))).append(s2).append(s3).toString();
System.out.println(s);
System.out.println(s4);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
根据上面的反编译结果,很好的印证了我们在第六节中提出的字符串连接符的本质。
2). 另一个例子:字符串连接符的本质
由上面的分析结果,我们不难推断出 String 采用连接运算符(+)效率低下原因分析,形如这样的代码:
public class Test {
public static void main(String args[]) {
String s = null;
for(int i = 0; i < 100; i++) {
s += "a";
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
会被编译器编译为:
public class Test
{
public Test(){}
public static void main(String args[])
{
String s = null;
for (int i = 0; i < 100; i++)
s = (new StringBuilder(String.valueOf(s))).append("a").toString();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
也就是说,每做一次 字符串连接操作 “+” 就产生一个 StringBuilder 对象,然后 append 后就扔掉。下次循环再到达时,再重新 new 一个 StringBuilder 对象,然后 append 字符串,如此循环直至结束。事实上,如果我们直接采用 StringBuilder 对象进行 append 的话,我们可以节省 N - 1 次创建和销毁对象的时间。所以,对于在循环中要进行字符串连接的应用,一般都是用StringBulider对象来进行append操作。
八. 字符串与正则表达式:匹配、替换和验证
- 正则表达式
- 用一个字符串来描述一个特征,然后去验证另一个字符串是否符合这个特征。使用正则表达式,我们能够以编程的方式,构造复杂的文本模式,并对输入的字符串进行搜索。 Java 内置了对正则表达式的支持,其相关的类库在 java.util.regex 包下,感兴趣的读者可以去查看相应的 API 和 JDK 源码。在使用过程中,有两点需要注意以下:
1、Java转义与正则表达式转义
要想匹配某些特殊字符,比如 “\”,需要进行两次转义,即Java转义与正则表达式转义。对于下面的例子,需要注意的是,split()函数的参数必须是“正则表达式”字符串。
public class Test {
public static void main(String[] args) {
String a = "a\\b";
System.out.println(a.split("\\\\")[0]);
System.out.println(a.split("\\\\")[1]);
}
}/* Output:
a
b
*///:~
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2、使用 Pattern 与 Matcher 构造功能强大的正则表达式对象
Pattern 与 Matcher的组合就是Java对正则表达式的主要内置支持,如下:
public class Test {
public static void main(String[] args) {
Pattern pattern = Pattern.compile(".\\\\.");
Matcher matcher = pattern.matcher("a\\b");
System.out.println(matcher.matches());
System.out.println(matcher.group());
}
}/* Output:
true
a\b
*///:~
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
九. String 与 (深)克隆
1、克隆的定义与意义
顾名思义,克隆就是制造一个对象的副本。一般地,根据所要克隆的对象的成员变量中是否含有引用类型,可以将克隆分为两种:浅克隆(Shallow Clone) 和 深克隆(Deep Clone),默认情况下使用Object中的clone方法进行克隆就是浅克隆,即完成对象域对域的拷贝。
(1). Object 中的 clone() 方法

在使用clone()方法时,若该类未实现 Cloneable 接口,则抛出 java.lang.CloneNotSupportedException 异常。下面我们以Employee这个例子进行说明:
public class Employee {
private String name;
private double salary;
private Date hireDay;
...
public static void main(String[] args) throws CloneNotSupportedException {
Employee employee = new Employee();
employee.clone();
System.out.println("克隆完成...");
}
}/* Output:
~Exception in thread "main" java.lang.CloneNotSupportedException: P1_1.Employee
*///:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
(2). Cloneable 接口
Cloneable 接口是一个标识性接口,即该接口不包含任何方法(甚至没有clone()方法),但是如果一个类想合法的进行克隆,那么就必须实现这个接口。下面我们看JDK对它的描述:
A class implements the Cloneable interface to indicate to the java.lang.Object.clone() method that it is legal for that method to make a field-for-field copy of instances of that class.
Invoking Object’s clone method on an instance that does not implement the Cloneable interface results in the exception CloneNotSupportedException being thrown.
By convention, classes that implement this interface should override Object.clone (which is protected) with a public method.
Note that this interface does not contain the clone() method. Therefore, it is not possible to clone an object merely by virtue of the fact that it implements this interface. Even if the clone method is invoked reflectively, there is no guarantee that it will succeed.
/**
* @author unascribed
* @see java.lang.CloneNotSupportedException
* @see java.lang.Object#clone()
* @since JDK1.0
*/
public interface Cloneable {
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2、Clone & Copy
假设现在有一个Employee对象,Employee tobby = new Employee(“CMTobby”,5000),通常, 我们会有这样的赋值Employee tom=tobby,这个时候只是简单了copy了一下reference,tom 和 tobby 都指向内存中同一个object,这样tom或者tobby对对象的修改都会影响到对方。打个比方,如果我们通过tom.raiseSalary()方法改变了salary域的值,那么tobby通过getSalary()方法得到的就是修改之后的salary域的值,显然这不是我们愿意看到的。如果我们希望得到tobby所指向的对象的一个精确拷贝,同时两者互不影响,那么我们就可以使用Clone来满足我们的需求。Employee cindy=tobby.clone(),这时会生成一个新的Employee对象,并且和tobby具有相同的属性值和方法。
3、Shallow Clone & Deep Clone
Clone是如何完成的呢?Object中的clone()方法在对某个对象实施克隆时对其是一无所知的,它仅仅是简单地执行域对域的copy,这就是Shallow Clone。这样,问题就来了,以Employee为例,它里面有一个域hireDay不是基本类型的变量,而是一个reference变量,经过Clone之后克隆类只会产生一个新的Date类型的引用,它和原始引用都指向同一个 Date 对象,这样克隆类就和原始类共享了一部分信息,显然这种情况不是我们愿意看到的,过程下图所示:
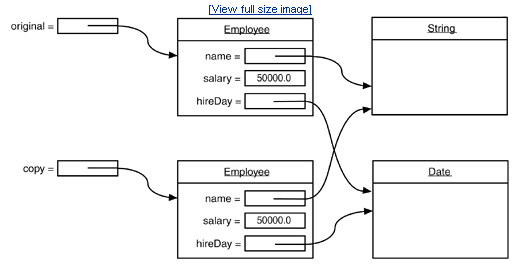
这个时候,我们就需要进行 Deep Clone 了,以便对那些引用类型的域进行特殊的处理,例如本例中的hireDay。我们可以重新定义 clone方法,对hireDay做特殊处理,如下代码所示:
class Employee implements Cloneable
{
private String name;
private int id;
private Date hireDay;
...
@Override
public Object clone() throws CloneNotSupportedException {
Employee cloned = (Employee) super.clone();
// Date 支持克隆且重写了clone()方法,Date 的定义是:
// public class Date implements java.io.Serializable, Cloneable, Comparable<Date>
cloned.hireDay = (Date) hireDay.clone() ;
return cloned;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
因此,Object 在对某个对象实施 Clone 时,对其是一无所知的,它仅仅是简单执行域对域的Copy。 其中,对八种基本类型的克隆是没有问题的,但当对一个引用类型进行克隆时,只是克隆了它的引用。因此,克隆对象和原始对象共享了同一个对象成员变量,故而提出了深克隆 : 在对整个对象浅克隆后,还需对其引用变量进行克隆,并将其更新到浅克隆对象中去。
4、一个克隆的示例
在这里,我们通过一个简单的例子来说明克隆在Java中的使用,如下所示:
// 父类 Employee
public class Employee implements Cloneable{
private String name;
private double salary;
private Date hireDay;
public Employee(String name, double salary, Date hireDay) {
this.name = name;
this.salary = salary;
this.hireDay = hireDay;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getSalary() {
return salary;
}
public void setSalary(double salary) {
this.salary = salary;
}
public Date getHireDay() {
return hireDay;
}
public void setHireDay(Date hireDay) {
this.hireDay = hireDay;
}
@Override
public Object clone() throws CloneNotSupportedException {
Employee cloned = (Employee) super.clone();
cloned.hireDay = (Date) hireDay.clone();
return cloned;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((hireDay == null) ? 0 : hireDay.hashCode());
result = prime * result + ((name == null) ? 0 : name.hashCode());
long temp;
temp = Double.doubleToLongBits(salary);
result = prime * result + (int) (temp ^ (temp >>> 32));
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Employee other = (Employee) obj;
if (hireDay == null) {
if (other.hireDay != null)
return false;
} else if (!hireDay.equals(other.hireDay))
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
if (Double.doubleToLongBits(salary) != Double
.doubleToLongBits(other.salary))
return false;
return true;
}
@Override
public String toString() {
return name + " : " + String.valueOf(salary) + " : " + hireDay.toString();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
// 子类 Manger
public class Manger extends Employee implements Cloneable {
private String edu;
public Manger(String name, double salary, Date hireDay, String edu) {
super(name, salary, hireDay);
this.edu = edu;
}
public String getEdu() {
return edu;
}
public void setEdu(String edu) {
this.edu = edu;
}
@Override
public String toString() {
return this.getName() + " : " + this.getSalary() + " : "
+ this.getHireDay() + " : " + this.getEdu();
}
@Override
public int hashCode() {
final int prime = 31;
int result = super.hashCode();
result = prime * result + ((edu == null) ? 0 : edu.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (!super.equals(obj))
return false;
if (getClass() != obj.getClass())
return false;
Manger other = (Manger) obj;
if (edu == null) {
if (other.edu != null)
return false;
} else if (!edu.equals(other.edu))
return false;
return true;
}
public static void main(String[] args) throws CloneNotSupportedException {
Manger manger = new Manger("Rico", 20000.0, new Date(), "NEU");
// 输出manger
System.out.println("Manger对象 = " + manger.toString());
Manger clonedManger = (Manger) manger.clone();
// 输出克隆的manger
System.out.println("Manger对象的克隆对象 = " + clonedManger.toString());
System.out.println("Manger对象和其克隆对象是否相等: "
+ manger.equals(clonedManger) + "\r\n");
// 修改、输出manger
manger.setEdu("TJU");
System.out.println("修改后的Manger对象 = " + manger.toString());
// 再次输出manger
System.out.println("原克隆对象= " + clonedManger.toString());
System.out.println("修改后的Manger对象和原克隆对象是否相等: "
+ manger.equals(clonedManger));
}
}
/* Output:
Manger对象 = Rico : 20000.0 : Mon Mar 13 15:36:03 CST 2017 : NEU
Manger对象的克隆对象 = Rico : 20000.0 : Mon Mar 13 15:36:03 CST 2017 : NEU
Manger对象和其克隆对象是否相等: true
修改后的Manger对象 = Rico : 20000.0 : Mon Mar 13 15:36:03 CST 2017 : TJU
原克隆对象= Rico : 20000.0 : Mon Mar 13 15:36:03 CST 2017 : NEU
修改后的Manger对象和原克隆对象是否相等: false
*///:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
5、Clone()方法的保护机制
在Object中clone()是被申明为 protected 的,这样做是有一定的道理的。以 Employee 类为例,如果我们在Employee中重写了protected Object clone()方法, ,就大大限制了可以“克隆”Employee对象的范围,即可以保证只有在和Employee类在同一包中类及Employee类的子类里面才能“克隆”Employee对象。进一步地,如果我们没有在Employee类重写clone()方法,则只有Employee类及其子类才能够“克隆”Employee对象。
这里面涉及到一个大家可能都会忽略的一个知识点,那就是关于protected的用法。实际上,很多的有关介绍Java语言的书籍,都对protected介绍的比较的简单,就是:被protected修饰的成员或方法对于本包和其子类可见。这种说法有点太过含糊,常常会对大家造成误解。以此为契机,笔者专门在一篇独立博文《Java 访问权限控制:你真的了解 protected 关键字吗?》中介绍了Java中的访问权限控制,特别就 protected 关键字的使用和内涵做了清晰到位的说明。
6、注意事项
Clone()方法的使用比较简单,注意如下几点即可:
什么时候使用shallow Clone,什么时候使用deep Clone?
这个主要看具体对象的域是什么性质的,基本类型还是引用类型。
- 调用Clone()方法的对象所属的类(Class)必须实现 Clonable 接口,否则在调用Clone方法的时候会抛出CloneNotSupportedException;
- 所有数组对象都实现了 Clonable 接口,默认支持克隆;
- 如果我们实现了 Clonable 接口,但没有重写Object类的clone方法,那么执行域对域的拷贝;
明白 String 在克隆中的特殊性
String 在克隆时只是克隆了它的引用。
奇怪的是,在修改克隆后的 String 对象时,其原来的对象并未改变。原因是:String是在内存中不可以被改变的对象。虽然在克隆时,源对象和克隆对象都指向了同一个String对象,但当其中一个对象修改这个String对象的时候,会新分配一块内存用来保存修改后的String对象并将其引用指向新的String对象,而原来的String对象因为还存在指向它的引用,所以不会被回收。这样,对于String而言,虽然是复制的引用,但是当修改值的时候,并不会改变被复制对象的值。所以在使用克隆时,我们可以将 String类型 视为与基本类型,只需浅克隆即可。
十. String 总结
(1). 使用字面值形式创建字符串时,不一定会创建对象,但其引用一定指向位于字符串常量池的某个对象;
(2). 使用 new String(“…”)方式创建字符串时,一定会创建对象,甚至可能会同时创建两个对象(一个位于字符串常量池中,一个位于堆中);
(3). String 对象是不可变的,对String 对象的任何改变都会导致一个新的 String 对象的产生,而不会影响到原String 对象;
(4). StringBuilder 与 StringBuffer 具有共同的父类,具有相同的API,分别适用于单线程和多线程环境下。特别地,在单线程环境下,StringBuilder 是 StringBuffer 的替代品,前者效率相对较高;
(5). 字符串比较时用的什么方法,内部实现如何?
使用equals方法 : 先比较引用是否相同(是否是同一对象),再检查是否为同一类型(str instanceof String), 最后比较内容是否一致(String 的各个成员变量的值或内容是否相同)。这也同样适用于诸如 Integer 等的八种包装器类。
十一. 说明
在综述String的过程中,我们涉及到了很多知识点,其中有一些我们已经在其他博文中专门提到过,因此没有作更多详细的阐述,这里给出对应的链接:
更多关于Java 访问权限控制的介绍,特别是 protected 的内涵,请移步我的博文《Java 访问权限控制:你真的了解 protected 关键字吗?》;
更多关于字面量的介绍请移步我的博文《Java 原生类型与包装器类型深度剖析》;
更多关于享元模式的介绍请移步我的博文《深入理解享元模式》。
摘要:
Java 中的 String类 是我们日常开发中使用最为频繁的一个类,但要想真正掌握的这个类却不是一件容易的事情。笔者为了还原String类的真实全貌,先分为上、下两篇博文来综述Java中的String类。笔者从Java内存模型展开,结合 JDK 中 String类的源码进行深入分析,特别就 String类与享元模式,String常量池,String不可变性,String对象的创建方式,String与正则表达式,String与克隆,String、StringBuffer 和 StringBuilder 的区别等几个方面对其进行详细阐述、总结,力求能够对String类的原理和使用作一个最全面和最准确的介绍。
原文链接:
https://blog.csdn.net/justloveyou_/article/details/60983034六. 字符串常量池
1、字符串池
字符串的分配,和其他的对象分配一样,耗费高昂的时间与空间代价。JVM为了提高性能和减少内存开销,在实例化字符串字面值的时候进行了一些优化。为了减少在JVM中创建的字符串的数量,字符串类维护了一个字符串常量池,每当以字面值形式创建一个字符串时,JVM会首先检查字符串常量池:如果字符串已经存在池中,就返回池中的实例引用;如果字符串不在池中,就会实例化一个字符串并放到池中。Java能够进行这样的优化是因为字符串是不可 变的,可以不用担心数据冲突进行共享。 例如:
public class Program
{
public static void main(String[] args)
{
String str1 = "Hello";
String str2 = "Hello";
System.out.print(str1 == str2); // true
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
一个初始为空的字符串池,它由类 String 私有地维护。当以字面值形式创建一个字符串时,总是先检查字符串池是否含存在该对象,若存在,则直接返回。此外,通过 new 操作符创建的字符串对象不指向字符串池中的任何对象。
2、手动入池
一个初始为空的字符串池,它由类 String 私有地维护。 当调用 intern 方法时,如果池已经包含一个等于此 String 对象的字符串(用 equals(Object) 方法确定),则返回池中的字符串。否则,将此 String 对象添加到池中,并返回此 String 对象的引用。特别地,手动入池遵循以下规则:
对于任意两个字符串 s 和 t ,当且仅当 s.equals(t) 为 true 时,s.intern() == t.intern() 才为 true 。
public class TestString{
public static void main(String args[]){
String str1 = "abc";
String str2 = new String("abc");
String str3 = s2.intern();
System.out.println( str1 == str2 ); //false
System.out.println( str1 == str3 ); //true
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
所以,对于 String str1 = “abc”,str1 引用的是 常量池(方法区) 的对象;而 String str2 = new String(“abc”),str2引用的是 堆 中的对象,所以内存地址不一样。但是由于内容一样,所以 str1 和 str3 指向同一对象。
3、实例
看下面几个场景来深入理解 String。
1) 情景一:字符串常量池
Java虚拟机(JVM)中存在着一个字符串常量池,其中保存着很多String对象,并且这些String对象可以被共享使用,因此提高了效率。之所以字符串具有字符串常量池,是因为String对象是不可变的,因此可以被共享。字符串常量池由String类维护,我们可以通过intern()方法使字符串池手动入池。
String s1 = "abc";
//↑ 在字符串池创建了一个对象
String s2 = "abc";
//↑ 字符串pool已经存在对象“abc”(共享),所以创建0个对象,累计创建一个对象
System.out.println("s1 == s2 : "+(s1==s2));
//↑ true 指向同一个对象,
System.out.println("s1.equals(s2) : " + (s1.equals(s2)));
//↑ true 值相等
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2) 情景二:关于new String(“…”)
String s3 = new String("abc");
//↑ 创建了两个对象,一个存放在字符串池中,一个存在与堆区中;
//↑ 还有一个对象引用s3存放在栈中
String s4 = new String("abc");
//↑ 字符串池中已经存在“abc”对象,所以只在堆中创建了一个对象
System.out.println("s3 == s4 : "+(s3==s4));
//↑false s3和s4栈区的地址不同,指向堆区的不同地址;
System.out.println("s3.equals(s4) : "+(s3.equals(s4)));
//↑true s3和s4的值相同
System.out.println("s1 == s3 : "+(s1==s3));
//↑false 存放的地区都不同,一个方法区,一个堆区
System.out.println("s1.equals(s3) : "+(s1.equals(s3)));
//↑true 值相同
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
通过上一篇博文我们知道,通过 new String(“…”) 来创建字符串时,在该构造函数的参数值为字符串字面值的前提下,若该字面值不在字符串常量池中,那么会创建两个对象:一个在字符串常量池中,一个在堆中;否则,只会在堆中创建一个对象。对于不在同一区域的两个对象,二者的内存地址必定不同。
3) 情景三:字符串连接符“+”
String str2 = "ab"; //1个对象
String str3 = "cd"; //1个对象
String str4 = str2+str3;
String str5 = "abcd";
System.out.println("str4 = str5 : " + (str4==str5)); // false
- 1
- 2
- 3
- 4
- 5
我们看这个例子,局部变量 str2,str3 指向字符串常量池中的两个对象。在运行时,第三行代码(str2+str3)实质上会被分解成五个步骤,分别是:
(1). 调用 String 类的静态方法 String.valueOf() 将 str2 转换为字符串表示;
(2). JVM 在堆中创建一个 StringBuilder对象,同时用str2指向转换后的字符串对象进行初始化;
(3). 调用StringBuilder对象的append方法完成与str3所指向的字符串对象的合并;
(4). 调用 StringBuilder 的 toString() 方法在堆中创建一个 String对象;
(5). 将刚刚生成的String对象的堆地址存赋给局部变量引用str4。
而引用str5指向的是字符串常量池中字面值”abcd”所对应的字符串对象。由上面的内容我们可以知道,引用str4和str5指向的对象的地址必定不一样。这时,内存中实际上会存在五个字符串对象: 三个在字符串常量池中的String对象、一个在堆中的String对象和一个在堆中的StringBuilder对象。
4) 情景四:字符串的编译期优化
String str1 = "ab" + "cd"; //1个对象
String str11 = "abcd";
System.out.println("str1 = str11 : "+ (str1 == str11)); // true
final String str8 = "cd";
String str9 = "ab" + str8;
String str89 = "abcd";
System.out.println("str9 = str89 : "+ (str9 == str89)); // true
//↑str8为常量变量,编译期会被优化
String str6 = "b";
String str7 = "a" + str6;
String str67 = "ab";
System.out.println("str7 = str67 : "+ (str7 == str67)); // false
//↑str6为变量,在运行期才会被解析。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
Java 编译器对于类似“常量+字面值”的组合,其值在编译的时候就能够被确定了。在这里,str1 和 str9 的值在编译时就可以被确定,因此它们分别等价于: String str1 = “abcd”; 和 String str9 = “abcd”;
Java 编译器对于含有 “String引用”的组合,则在运行期会产生新的对象 (通过调用StringBuilder类的toString()方法),因此这个对象存储在堆中。
4、小结
使用字面值形式创建的字符串与通过 new 创建的字符串一定是不同的,因为二者的存储位置不同:前者在方法区,后者在堆;
我们在使用诸如String str = “abc”;的格式创建字符串对象时,总是想当然地认为,我们创建了String类的对象str。但是事实上, 对象可能并没有被创建。唯一可以肯定的是,指向 String 对象 的引用被创建了。至于这个引用到底是否指向了一个新的对象,必须根据上下文来考虑;
字符串常量池的理念是 《享元模式》;
Java 编译器对 “常量+字面值” 的组合 是当成常量表达式直接求值来优化的;对于含有“String引用”的组合,其在编译期不能被确定,会在运行期创建新对象。
七. 三大字符串类 : String、StringBuilder 和 StringBuffer
1. String 与 StringBuilder
简要的说, String 类型 和 StringBuilder 类型的主要性能区别在于 String 是不可变的对象。 事实上,在对 String 类型进行“改变”时,实质上等同于生成了一个新的 String 对象,然后将指针指向新的 String 对象。由于频繁的生成对象会对系统性能产生影响,特别是当内存中没有引用指向的对象多了以后,JVM 的垃圾回收器就会开始工作,继而会影响到程序的执行效率。所以,对于经常改变内容的字符串,最好不要声明为 String 类型。但如果我们使用的是 StringBuilder 类,那么情形就不一样了。因为,我们的每次修改都是针对 StringBuilder 对象本身的,而不会像对String操作那样去生成新的对象并重新给变量引用赋值。所以,在一般情况下,推荐使用 StringBuilder ,特别是字符串对象经常改变的情况下。
在某些特别情况下,String 对象的字符串拼接可以直接被JVM 在编译期确定下来,这时,StringBuilder 在速度上就不占任何优势了。
因此,在绝大部分情况下, 在效率方面:StringBuilder > String .
2.StringBuffer 与 StringBuilder
首先需要明确的是,StringBuffer 始于 JDK 1.0,而 StringBuilder 始于 JDK 5.0;此外,从 JDK 1.5 开始,对含有字符串变量 (非字符串字面值) 的连接操作(+),JVM 内部是采用 StringBuilder 来实现的,而在这之前,这个操作是采用 StringBuffer 实现的。
JDK的实现中 StringBuffer 与 StringBuilder 都继承自 AbstractStringBuilder。AbstractStringBuilder的实现原理为:AbstractStringBuilder中采用一个 char数组 来保存需要append的字符串,char数组有一个初始大小,当append的字符串长度超过当前char数组容量时,则对char数组进行动态扩展,即重新申请一段更大的内存空间,然后将当前char数组拷贝到新的位置,因为重新分配内存并拷贝的开销比较大,所以每次重新申请内存空间都是采用申请大于当前需要的内存空间的方式,这里是 2 倍。
StringBuffer 和 StringBuilder 都是可变的字符序列,但是二者最大的一个不同点是:StringBuffer 是线程安全的,而 StringBuilder 则不是。StringBuilder 提供的API与StringBuffer的API是完全兼容的,即,StringBuffer 与 StringBuilder 中的方法和功能完全是等价的,但是后者一般要比前者快。因此,可以这么说,StringBuilder 的提出就是为了在单线程环境下替换 StringBuffer 。
在单线程环境下,优先使用 StringBuilder。
3.实例
1). 编译时优化与字符串连接符的本质
我们先来看下面这个例子:
public class Test2 {
public static void main(String[] args) {
String s = "a" + "b" + "c";
String s1 = "a";
String s2 = "b";
String s3 = "c";
String s4 = s1 + s2 + s3;
System.out.println(s);
System.out.println(s4);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
由上面的叙述,我们可以知道,变量s的创建等价于 String s = “abc”; 而变量s4的创建相当于:
StringBuilder temp = new StringBuilder(s1);
temp.append(s2).append(s3);
String s4 = temp.toString();
- 1
- 2
- 3
但事实上,是不是这样子呢?我们将其反编译一下,来看看Java编译器究竟做了什么:
//将上述 Test2 的 class 文件反编译
public class Test2
{
public Test2(){}
public static void main(String args[])
{
String s = "abc"; // 编译期优化
String s1 = "a";
String s2 = "b";
String s3 = "c";
//底层使用 StringBuilder 进行字符串的拼接
String s4 = (new StringBuilder(String.valueOf(s1))).append(s2).append(s3).toString();
System.out.println(s);
System.out.println(s4);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
根据上面的反编译结果,很好的印证了我们在第六节中提出的字符串连接符的本质。
2). 另一个例子:字符串连接符的本质
由上面的分析结果,我们不难推断出 String 采用连接运算符(+)效率低下原因分析,形如这样的代码:
public class Test {
public static void main(String args[]) {
String s = null;
for(int i = 0; i < 100; i++) {
s += "a";
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
会被编译器编译为:
public class Test
{
public Test(){}
public static void main(String args[])
{
String s = null;
for (int i = 0; i < 100; i++)
s = (new StringBuilder(String.valueOf(s))).append("a").toString();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
也就是说,每做一次 字符串连接操作 “+” 就产生一个 StringBuilder 对象,然后 append 后就扔掉。下次循环再到达时,再重新 new 一个 StringBuilder 对象,然后 append 字符串,如此循环直至结束。事实上,如果我们直接采用 StringBuilder 对象进行 append 的话,我们可以节省 N - 1 次创建和销毁对象的时间。所以,对于在循环中要进行字符串连接的应用,一般都是用StringBulider对象来进行append操作。
八. 字符串与正则表达式:匹配、替换和验证
- 正则表达式
- 用一个字符串来描述一个特征,然后去验证另一个字符串是否符合这个特征。使用正则表达式,我们能够以编程的方式,构造复杂的文本模式,并对输入的字符串进行搜索。 Java 内置了对正则表达式的支持,其相关的类库在 java.util.regex 包下,感兴趣的读者可以去查看相应的 API 和 JDK 源码。在使用过程中,有两点需要注意以下:
1、Java转义与正则表达式转义
要想匹配某些特殊字符,比如 “\”,需要进行两次转义,即Java转义与正则表达式转义。对于下面的例子,需要注意的是,split()函数的参数必须是“正则表达式”字符串。
public class Test {
public static void main(String[] args) {
String a = "a\\b";
System.out.println(a.split("\\\\")[0]);
System.out.println(a.split("\\\\")[1]);
}
}/* Output:
a
b
*///:~
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2、使用 Pattern 与 Matcher 构造功能强大的正则表达式对象
Pattern 与 Matcher的组合就是Java对正则表达式的主要内置支持,如下:
public class Test {
public static void main(String[] args) {
Pattern pattern = Pattern.compile(".\\\\.");
Matcher matcher = pattern.matcher("a\\b");
System.out.println(matcher.matches());
System.out.println(matcher.group());
}
}/* Output:
true
a\b
*///:~
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
九. String 与 (深)克隆
1、克隆的定义与意义
顾名思义,克隆就是制造一个对象的副本。一般地,根据所要克隆的对象的成员变量中是否含有引用类型,可以将克隆分为两种:浅克隆(Shallow Clone) 和 深克隆(Deep Clone),默认情况下使用Object中的clone方法进行克隆就是浅克隆,即完成对象域对域的拷贝。
(1). Object 中的 clone() 方法
在使用clone()方法时,若该类未实现 Cloneable 接口,则抛出 java.lang.CloneNotSupportedException 异常。下面我们以Employee这个例子进行说明:
public class Employee {
private String name;
private double salary;
private Date hireDay;
...
public static void main(String[] args) throws CloneNotSupportedException {
Employee employee = new Employee();
employee.clone();
System.out.println("克隆完成...");
}
}/* Output:
~Exception in thread "main" java.lang.CloneNotSupportedException: P1_1.Employee
*///:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
(2). Cloneable 接口
Cloneable 接口是一个标识性接口,即该接口不包含任何方法(甚至没有clone()方法),但是如果一个类想合法的进行克隆,那么就必须实现这个接口。下面我们看JDK对它的描述:
A class implements the Cloneable interface to indicate to the java.lang.Object.clone() method that it is legal for that method to make a field-for-field copy of instances of that class.
Invoking Object’s clone method on an instance that does not implement the Cloneable interface results in the exception CloneNotSupportedException being thrown.
By convention, classes that implement this interface should override Object.clone (which is protected) with a public method.
Note that this interface does not contain the clone() method. Therefore, it is not possible to clone an object merely by virtue of the fact that it implements this interface. Even if the clone method is invoked reflectively, there is no guarantee that it will succeed.
/**
* @author unascribed
* @see java.lang.CloneNotSupportedException
* @see java.lang.Object#clone()
* @since JDK1.0
*/
public interface Cloneable {
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2、Clone & Copy
假设现在有一个Employee对象,Employee tobby = new Employee(“CMTobby”,5000),通常, 我们会有这样的赋值Employee tom=tobby,这个时候只是简单了copy了一下reference,tom 和 tobby 都指向内存中同一个object,这样tom或者tobby对对象的修改都会影响到对方。打个比方,如果我们通过tom.raiseSalary()方法改变了salary域的值,那么tobby通过getSalary()方法得到的就是修改之后的salary域的值,显然这不是我们愿意看到的。如果我们希望得到tobby所指向的对象的一个精确拷贝,同时两者互不影响,那么我们就可以使用Clone来满足我们的需求。Employee cindy=tobby.clone(),这时会生成一个新的Employee对象,并且和tobby具有相同的属性值和方法。
3、Shallow Clone & Deep Clone
Clone是如何完成的呢?Object中的clone()方法在对某个对象实施克隆时对其是一无所知的,它仅仅是简单地执行域对域的copy,这就是Shallow Clone。这样,问题就来了,以Employee为例,它里面有一个域hireDay不是基本类型的变量,而是一个reference变量,经过Clone之后克隆类只会产生一个新的Date类型的引用,它和原始引用都指向同一个 Date 对象,这样克隆类就和原始类共享了一部分信息,显然这种情况不是我们愿意看到的,过程下图所示:
这个时候,我们就需要进行 Deep Clone 了,以便对那些引用类型的域进行特殊的处理,例如本例中的hireDay。我们可以重新定义 clone方法,对hireDay做特殊处理,如下代码所示:
class Employee implements Cloneable
{
private String name;
private int id;
private Date hireDay;
...
@Override
public Object clone() throws CloneNotSupportedException {
Employee cloned = (Employee) super.clone();
// Date 支持克隆且重写了clone()方法,Date 的定义是:
// public class Date implements java.io.Serializable, Cloneable, Comparable<Date>
cloned.hireDay = (Date) hireDay.clone() ;
return cloned;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
因此,Object 在对某个对象实施 Clone 时,对其是一无所知的,它仅仅是简单执行域对域的Copy。 其中,对八种基本类型的克隆是没有问题的,但当对一个引用类型进行克隆时,只是克隆了它的引用。因此,克隆对象和原始对象共享了同一个对象成员变量,故而提出了深克隆 : 在对整个对象浅克隆后,还需对其引用变量进行克隆,并将其更新到浅克隆对象中去。
4、一个克隆的示例
在这里,我们通过一个简单的例子来说明克隆在Java中的使用,如下所示:
// 父类 Employee
public class Employee implements Cloneable{
private String name;
private double salary;
private Date hireDay;
public Employee(String name, double salary, Date hireDay) {
this.name = name;
this.salary = salary;
this.hireDay = hireDay;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getSalary() {
return salary;
}
public void setSalary(double salary) {
this.salary = salary;
}
public Date getHireDay() {
return hireDay;
}
public void setHireDay(Date hireDay) {
this.hireDay = hireDay;
}
@Override
public Object clone() throws CloneNotSupportedException {
Employee cloned = (Employee) super.clone();
cloned.hireDay = (Date) hireDay.clone();
return cloned;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((hireDay == null) ? 0 : hireDay.hashCode());
result = prime * result + ((name == null) ? 0 : name.hashCode());
long temp;
temp = Double.doubleToLongBits(salary);
result = prime * result + (int) (temp ^ (temp >>> 32));
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Employee other = (Employee) obj;
if (hireDay == null) {
if (other.hireDay != null)
return false;
} else if (!hireDay.equals(other.hireDay))
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
if (Double.doubleToLongBits(salary) != Double
.doubleToLongBits(other.salary))
return false;
return true;
}
@Override
public String toString() {
return name + " : " + String.valueOf(salary) + " : " + hireDay.toString();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
// 子类 Manger
public class Manger extends Employee implements Cloneable {
private String edu;
public Manger(String name, double salary, Date hireDay, String edu) {
super(name, salary, hireDay);
this.edu = edu;
}
public String getEdu() {
return edu;
}
public void setEdu(String edu) {
this.edu = edu;
}
@Override
public String toString() {
return this.getName() + " : " + this.getSalary() + " : "
+ this.getHireDay() + " : " + this.getEdu();
}
@Override
public int hashCode() {
final int prime = 31;
int result = super.hashCode();
result = prime * result + ((edu == null) ? 0 : edu.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (!super.equals(obj))
return false;
if (getClass() != obj.getClass())
return false;
Manger other = (Manger) obj;
if (edu == null) {
if (other.edu != null)
return false;
} else if (!edu.equals(other.edu))
return false;
return true;
}
public static void main(String[] args) throws CloneNotSupportedException {
Manger manger = new Manger("Rico", 20000.0, new Date(), "NEU");
// 输出manger
System.out.println("Manger对象 = " + manger.toString());
Manger clonedManger = (Manger) manger.clone();
// 输出克隆的manger
System.out.println("Manger对象的克隆对象 = " + clonedManger.toString());
System.out.println("Manger对象和其克隆对象是否相等: "
+ manger.equals(clonedManger) + "\r\n");
// 修改、输出manger
manger.setEdu("TJU");
System.out.println("修改后的Manger对象 = " + manger.toString());
// 再次输出manger
System.out.println("原克隆对象= " + clonedManger.toString());
System.out.println("修改后的Manger对象和原克隆对象是否相等: "
+ manger.equals(clonedManger));
}
}
/* Output:
Manger对象 = Rico : 20000.0 : Mon Mar 13 15:36:03 CST 2017 : NEU
Manger对象的克隆对象 = Rico : 20000.0 : Mon Mar 13 15:36:03 CST 2017 : NEU
Manger对象和其克隆对象是否相等: true
修改后的Manger对象 = Rico : 20000.0 : Mon Mar 13 15:36:03 CST 2017 : TJU
原克隆对象= Rico : 20000.0 : Mon Mar 13 15:36:03 CST 2017 : NEU
修改后的Manger对象和原克隆对象是否相等: false
*///:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
5、Clone()方法的保护机制
在Object中clone()是被申明为 protected 的,这样做是有一定的道理的。以 Employee 类为例,如果我们在Employee中重写了protected Object clone()方法, ,就大大限制了可以“克隆”Employee对象的范围,即可以保证只有在和Employee类在同一包中类及Employee类的子类里面才能“克隆”Employee对象。进一步地,如果我们没有在Employee类重写clone()方法,则只有Employee类及其子类才能够“克隆”Employee对象。
这里面涉及到一个大家可能都会忽略的一个知识点,那就是关于protected的用法。实际上,很多的有关介绍Java语言的书籍,都对protected介绍的比较的简单,就是:被protected修饰的成员或方法对于本包和其子类可见。这种说法有点太过含糊,常常会对大家造成误解。以此为契机,笔者专门在一篇独立博文《Java 访问权限控制:你真的了解 protected 关键字吗?》中介绍了Java中的访问权限控制,特别就 protected 关键字的使用和内涵做了清晰到位的说明。
6、注意事项
Clone()方法的使用比较简单,注意如下几点即可:
什么时候使用shallow Clone,什么时候使用deep Clone?
这个主要看具体对象的域是什么性质的,基本类型还是引用类型。
- 调用Clone()方法的对象所属的类(Class)必须实现 Clonable 接口,否则在调用Clone方法的时候会抛出CloneNotSupportedException;
- 所有数组对象都实现了 Clonable 接口,默认支持克隆;
- 如果我们实现了 Clonable 接口,但没有重写Object类的clone方法,那么执行域对域的拷贝;
明白 String 在克隆中的特殊性
String 在克隆时只是克隆了它的引用。
奇怪的是,在修改克隆后的 String 对象时,其原来的对象并未改变。原因是:String是在内存中不可以被改变的对象。虽然在克隆时,源对象和克隆对象都指向了同一个String对象,但当其中一个对象修改这个String对象的时候,会新分配一块内存用来保存修改后的String对象并将其引用指向新的String对象,而原来的String对象因为还存在指向它的引用,所以不会被回收。这样,对于String而言,虽然是复制的引用,但是当修改值的时候,并不会改变被复制对象的值。所以在使用克隆时,我们可以将 String类型 视为与基本类型,只需浅克隆即可。
十. String 总结
(1). 使用字面值形式创建字符串时,不一定会创建对象,但其引用一定指向位于字符串常量池的某个对象;
(2). 使用 new String(“…”)方式创建字符串时,一定会创建对象,甚至可能会同时创建两个对象(一个位于字符串常量池中,一个位于堆中);
(3). String 对象是不可变的,对String 对象的任何改变都会导致一个新的 String 对象的产生,而不会影响到原String 对象;
(4). StringBuilder 与 StringBuffer 具有共同的父类,具有相同的API,分别适用于单线程和多线程环境下。特别地,在单线程环境下,StringBuilder 是 StringBuffer 的替代品,前者效率相对较高;
(5). 字符串比较时用的什么方法,内部实现如何?
使用equals方法 : 先比较引用是否相同(是否是同一对象),再检查是否为同一类型(str instanceof String), 最后比较内容是否一致(String 的各个成员变量的值或内容是否相同)。这也同样适用于诸如 Integer 等的八种包装器类。
十一. 说明
在综述String的过程中,我们涉及到了很多知识点,其中有一些我们已经在其他博文中专门提到过,因此没有作更多详细的阐述,这里给出对应的链接:
更多关于Java 访问权限控制的介绍,特别是 protected 的内涵,请移步我的博文《Java 访问权限控制:你真的了解 protected 关键字吗?》;
更多关于字面量的介绍请移步我的博文《Java 原生类型与包装器类型深度剖析》;
更多关于享元模式的介绍请移步我的博文《深入理解享元模式》。