x265的帧内预测模式的选择流程如下图所示:
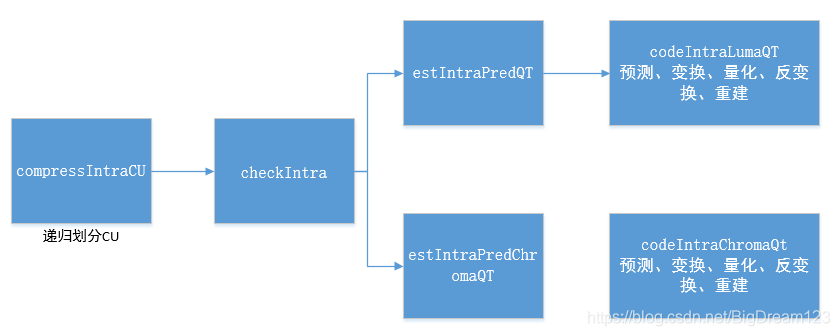
compressIntraCU函数进行递归划分CU的操作,对于每一个划分后的CU,调用CheckIntra函数进行帧内预测模式的RDO过程。
CheckIntra主要是调用estIntraPredQT和estIntraPredChromaQT分别选出当前CU的亮度最优预测模式和色度最优预测模式,然后计算编码当前CU所使用的的RD Cost。代码及注释如下:
void Search::checkIntra(Mode& intraMode, const CUGeom& cuGeom, PartSize partSize)
{
CUData& cu = intraMode.cu;
cu.setPartSizeSubParts(partSize);
cu.setPredModeSubParts(MODE_INTRA);
uint32_t tuDepthRange[2];
cu.getIntraTUQtDepthRange(tuDepthRange, 0);
intraMode.initCosts();
// 选出帧内的亮度最佳模式并保存SSE失真
intraMode.lumaDistortion += estIntraPredQT(intraMode, cuGeom, tuDepthRange);
if (m_csp != X265_CSP_I400)
{
intraMode.chromaDistortion += estIntraPredChromaQT(intraMode, cuGeom);//选出最佳的色度模式并返回失真
intraMode.distortion += intraMode.lumaDistortion + intraMode.chromaDistortion;//计算亮度和色度总失真
}
else
intraMode.distortion += intraMode.lumaDistortion;
cu.m_distortion[0] = intraMode.distortion;
m_entropyCoder.resetBits();
if (m_slice->m_pps->bTransquantBypassEnabled)
m_entropyCoder.codeCUTransquantBypassFlag(cu.m_tqBypass[0]);
int skipFlagBits = 0;
if (!m_slice->isIntra())
{
m_entropyCoder.codeSkipFlag(cu, 0);
skipFlagBits = m_entropyCoder.getNumberOfWrittenBits();
m_entropyCoder.codePredMode(cu.m_predMode[0]);
}
m_entropyCoder.codePartSize(cu, 0, cuGeom.depth);
m_entropyCoder.codePredInfo(cu, 0);//编码预测模式
intraMode.mvBits = m_entropyCoder.getNumberOfWrittenBits() - skipFlagBits;
bool bCodeDQP = m_slice->m_pps->bUseDQP;
m_entropyCoder.codeCoeff(cu, 0, bCodeDQP, tuDepthRange); //编码整个CU系数
m_entropyCoder.store(intraMode.contexts);
intraMode.totalBits = m_entropyCoder.getNumberOfWrittenBits();//计算出总的比特
intraMode.coeffBits = intraMode.totalBits - intraMode.mvBits - skipFlagBits;
const Yuv* fencYuv = intraMode.fencYuv;
if (m_rdCost.m_psyRd)
intraMode.psyEnergy = m_rdCost.psyCost(cuGeom.log2CUSize - 2, fencYuv->m_buf[0], fencYuv->m_size, intraMode.reconYuv.m_buf[0], intraMode.reconYuv.m_size);
else if(m_rdCost.m_ssimRd)
intraMode.ssimEnergy = m_quant.ssimDistortion(cu, fencYuv->m_buf[0], fencYuv->m_size, intraMode.reconYuv.m_buf[0], intraMode.reconYuv.m_size, cuGeom.log2CUSize, TEXT_LUMA, 0);
intraMode.resEnergy = primitives.cu[cuGeom.log2CUSize - 2].sse_pp(intraMode.fencYuv->m_buf[0], intraMode.fencYuv->m_size, intraMode.predYuv.m_buf[0], intraMode.predYuv.m_size);
updateModeCost(intraMode);//更新RD Cost
checkDQP(intraMode, cuGeom);
}estIntraPredQT函数主要是进行亮度预测模式的RDO选择,H.265的亮度预测模式包括DC、Planar和33种角度模式共35种预测模式
主要流程如下:
- 遍历所有子PU,对每个子PU选出最佳预测模式。选择过程分为以下步骤:
- (1)粗选,遍历35种预测模式,以预测像素和原始像素的差值的SAD作为失真D,编码预测模式比特作为R,计算SAD Cost,选出最佳的maxCandCount种模式;
- (2)使用从上一步选出的maxCandCount种预测模式,调用codeIntraLumaQT进行变换、量化、反变换以及熵编码,计算出RD Cost,根据RD Cost选出最佳模式(simple RDO,进行变换时禁止TU划分)
- (3)使用上一步选出的最佳模式,进行变换、量化、反变换等计算出最终的RD Cost(此时允许TU划分),并保存亮度失真
- (4)计算所有PU的失真之和
- 返回总的失真
注意:粗选时候选出的模式数目maxCandCount和RDO level以及当前的划分深度有关:
int maxCandCount = 2 + m_param->rdLevel + ((depth + initTuDepth) >> 1);其中rdLevel是介于1和6(包括1和6)之间的值,用于确定在模式和深度决策期间要执行的率失真优化级别,RDO越多,压缩效率就越高,但要付出很大的性能代价,默认值为3。该参数可以通过命令行参数–rd <1…6>控制;depth指代的是当前CU的划分深度;initTuDepth表示当前PU类型是SIZE_2Nx2N还是SIZE_NxN
代码及注释如下:
sse_t Search::estIntraPredQT(Mode &intraMode, const CUGeom& cuGeom, const uint32_t depthRange[2])
{
CUData& cu = intraMode.cu;
Yuv* reconYuv = &intraMode.reconYuv;
Yuv* predYuv = &intraMode.predYuv;
const Yuv* fencYuv = intraMode.fencYuv;
uint32_t depth = cuGeom.depth;
//如果当前m_partSize是2Nx2N,表示PU没有进一步划分;如果当前m_partSize是NxN,表示PU进一步划分为4个小PU
uint32_t initTuDepth = cu.m_partSize[0] != SIZE_2Nx2N;
uint32_t numPU = 1 << (2 * initTuDepth);
uint32_t log2TrSize = cuGeom.log2CUSize - initTuDepth;
uint32_t tuSize = 1 << log2TrSize;
uint32_t qNumParts = cuGeom.numPartitions >> 2;
uint32_t sizeIdx = log2TrSize - 2;
uint32_t absPartIdx = 0;
sse_t totalDistortion = 0;
int checkTransformSkip = m_slice->m_pps->bTransformSkipEnabled && !cu.m_tqBypass[0] && cu.m_partSize[0] != SIZE_2Nx2N;
// loop over partitions 循环分区
for (uint32_t puIdx = 0; puIdx < numPU; puIdx++, absPartIdx += qNumParts)
{
uint32_t bmode = 0;
// 选出最佳预测模式
if (intraMode.cu.m_lumaIntraDir[puIdx] != (uint8_t)ALL_IDX)
bmode = intraMode.cu.m_lumaIntraDir[puIdx];
else
{
uint64_t candCostList[MAX_RD_INTRA_MODES];
uint32_t rdModeList[MAX_RD_INTRA_MODES];
uint64_t bcost;
int maxCandCount = 2 + m_param->rdLevel + ((depth + initTuDepth) >> 1);
{
ProfileCUScope(intraMode.cu, intraAnalysisElapsedTime, countIntraAnalysis);
// Reference sample smoothing 参考像素滤波
IntraNeighbors intraNeighbors;
initIntraNeighbors(cu, absPartIdx, initTuDepth, true, &intraNeighbors);
initAdiPattern(cu, cuGeom, absPartIdx, intraNeighbors, ALL_IDX);
// determine set of modes to be tested (using prediction signal only)
// 确定要测试的模式集(仅使用预测信号)
const pixel* fenc = fencYuv->getLumaAddr(absPartIdx);//原始信号
uint32_t stride = predYuv->m_size;
int scaleTuSize = tuSize;
int scaleStride = stride;
int costShift = 0;
m_entropyCoder.loadIntraDirModeLuma(m_rqt[depth].cur);
/* there are three cost tiers for intra modes:帧内模式有三个成本等级:
* pred[0] - mode probable, least cost
* pred[1], pred[2] - less probable, slightly more cost
* non-mpm modes - all cost the same (rbits) */
uint64_t mpms;
uint32_t mpmModes[3];
// 返回发出非最可能模式信号所需的位数。返回时,mpms包含最可能模式的位图
uint32_t rbits = getIntraRemModeBits(cu, absPartIdx, mpmModes, mpms);
pixelcmp_t sa8d = primitives.cu[sizeIdx].sa8d;
uint64_t modeCosts[35];
// DC 计算DC模式的预测值,并根据原始像素和预测像素计算SAD,根据SAD计算RD Cost
primitives.cu[sizeIdx].intra_pred[DC_IDX](m_intraPred, scaleStride, intraNeighbourBuf[0], 0, (scaleTuSize <= 16));
uint32_t bits = (mpms & ((uint64_t)1 << DC_IDX)) ? m_entropyCoder.bitsIntraModeMPM(mpmModes, DC_IDX) : rbits;
uint32_t sad = sa8d(fenc, scaleStride, m_intraPred, scaleStride) << costShift;
modeCosts[DC_IDX] = bcost = m_rdCost.calcRdSADCost(sad, bits);
// PLANAR
pixel* planar = intraNeighbourBuf[0];
if (tuSize >= 8 && tuSize <= 32)
planar = intraNeighbourBuf[1];
primitives.cu[sizeIdx].intra_pred[PLANAR_IDX](m_intraPred, scaleStride, planar, 0, 0);
bits = (mpms & ((uint64_t)1 << PLANAR_IDX)) ? m_entropyCoder.bitsIntraModeMPM(mpmModes, PLANAR_IDX) : rbits;
sad = sa8d(fenc, scaleStride, m_intraPred, scaleStride) << costShift;
modeCosts[PLANAR_IDX] = m_rdCost.calcRdSADCost(sad, bits);
COPY1_IF_LT(bcost, modeCosts[PLANAR_IDX]);
// angular predictions 角度预测模式
if (primitives.cu[sizeIdx].intra_pred_allangs)
{ //遍历全部33种角度模式
primitives.cu[sizeIdx].transpose(m_fencTransposed, fenc, scaleStride);
primitives.cu[sizeIdx].intra_pred_allangs(m_intraPredAngs, intraNeighbourBuf[0], intraNeighbourBuf[1], (scaleTuSize <= 16));
for (int mode = 2; mode < 35; mode++)
{
bits = (mpms & ((uint64_t)1 << mode)) ? m_entropyCoder.bitsIntraModeMPM(mpmModes, mode) : rbits;
if (mode < 18)
sad = sa8d(m_fencTransposed, scaleTuSize, &m_intraPredAngs[(mode - 2) * (scaleTuSize * scaleTuSize)], scaleTuSize) << costShift;
else
sad = sa8d(fenc, scaleStride, &m_intraPredAngs[(mode - 2) * (scaleTuSize * scaleTuSize)], scaleTuSize) << costShift;
modeCosts[mode] = m_rdCost.calcRdSADCost(sad, bits);
COPY1_IF_LT(bcost, modeCosts[mode]);
}
}
else
{
for (int mode = 2; mode < 35; mode++)
{
bits = (mpms & ((uint64_t)1 << mode)) ? m_entropyCoder.bitsIntraModeMPM(mpmModes, mode) : rbits;
int filter = !!(g_intraFilterFlags[mode] & scaleTuSize);
primitives.cu[sizeIdx].intra_pred[mode](m_intraPred, scaleTuSize, intraNeighbourBuf[filter], mode, scaleTuSize <= 16);
sad = sa8d(fenc, scaleStride, m_intraPred, scaleTuSize) << costShift;
modeCosts[mode] = m_rdCost.calcRdSADCost(sad, bits);
COPY1_IF_LT(bcost, modeCosts[mode]);
}
}
/* Find the top maxCandCount candidate modes with cost within 25% of best
* or among the most probable modes. maxCandCount is derived from the
* rdLevel and depth. In general we want to try more modes at slower RD
* levels and at higher depths */
// 找到成本在最佳模式或最可能模式25%以内的最大候选模式。
// maxCandCount是从rdLevel和depth派生的。
// 一般来说,我们想尝试更多的模式在较慢的RD水平和更高的深度
for (int i = 0; i < maxCandCount; i++)
candCostList[i] = MAX_INT64;
uint64_t paddedBcost = bcost + (bcost >> 2); // 1.25%
for (int mode = 0; mode < 35; mode++)
if ((modeCosts[mode] < paddedBcost) || ((uint32_t)mode == mpmModes[0]))
/* choose for R-D analysis only if this mode passes cost threshold or matches MPM[0] */
// 仅当此模式通过成本阈值或与MPM[0]匹配时,才选择进行R-D分析
updateCandList(mode, modeCosts[mode], maxCandCount, rdModeList, candCostList);
}
/* measure best candidates using simple RDO (no TU splits) */
// 使用简单RDO测量最佳候选对象(无TU拆分)
bcost = MAX_INT64;
for (int i = 0; i < maxCandCount; i++)
{
if (candCostList[i] == MAX_INT64)
break;
ProfileCUScope(intraMode.cu, intraRDOElapsedTime[cuGeom.depth], countIntraRDO[cuGeom.depth]);
m_entropyCoder.load(m_rqt[depth].cur);
cu.setLumaIntraDirSubParts(rdModeList[i], absPartIdx, depth + initTuDepth);
Cost icosts;
if (checkTransformSkip)
codeIntraLumaTSkip(intraMode, cuGeom, initTuDepth, absPartIdx, icosts);
else
codeIntraLumaQT(intraMode, cuGeom, initTuDepth, absPartIdx, false, icosts, depthRange);
// 进行变换量化细选
COPY2_IF_LT(bcost, icosts.rdcost, bmode, rdModeList[i]);//更新最佳模式和最佳Cost
}
}
ProfileCUScope(intraMode.cu, intraRDOElapsedTime[cuGeom.depth], countIntraRDO[cuGeom.depth]);
/* remeasure best mode, allowing TU splits */
// 重新测量最佳模式,允许TU划分
cu.setLumaIntraDirSubParts(bmode, absPartIdx, depth + initTuDepth);
m_entropyCoder.load(m_rqt[depth].cur);
Cost icosts;
if (checkTransformSkip)
codeIntraLumaTSkip(intraMode, cuGeom, initTuDepth, absPartIdx, icosts);
else
codeIntraLumaQT(intraMode, cuGeom, initTuDepth, absPartIdx, true, icosts, depthRange);
// 计算所选预测模式的最终失真
totalDistortion += icosts.distortion;
extractIntraResultQT(cu, *reconYuv, initTuDepth, absPartIdx);
// set reconstruction for next intra prediction blocks 为下一预测块准备重建值
if (puIdx != numPU - 1)
{
/* This has important implications for parallelism and RDO. It is writing intermediate results into the
* output recon picture, so it cannot proceed in parallel with anything else when doing INTRA_NXN. Also
* it is not updating m_rdContexts[depth].cur for the later PUs which I suspect is slightly wrong. I think
* that the contexts should be tracked through each PU */
PicYuv* reconPic = m_frame->m_reconPic;
pixel* dst = reconPic->getLumaAddr(cu.m_cuAddr, cuGeom.absPartIdx + absPartIdx);
uint32_t dststride = reconPic->m_stride;
const pixel* src = reconYuv->getLumaAddr(absPartIdx);
uint32_t srcstride = reconYuv->m_size;
primitives.cu[log2TrSize - 2].copy_pp(dst, dststride, src, srcstride);
}
}// for(PU)
if (numPU > 1)
{
uint32_t combCbfY = 0;
for (uint32_t qIdx = 0, qPartIdx = 0; qIdx < 4; ++qIdx, qPartIdx += qNumParts)
combCbfY |= cu.getCbf(qPartIdx, TEXT_LUMA, 1);
cu.m_cbf[0][0] |= combCbfY;
}
// TODO: remove this
m_entropyCoder.load(m_rqt[depth].cur);
return totalDistortion;
}codeIntraLumaQT函数主要是使用上层传进来的预测模式进行预测,然后进行变换、量化、反变换、反量化、重建,计算RD Cost
主要分为以下步骤:
- 如果当前CU可以进一步划分,则递归执行该函数进行划分,直到不能再划分为止
- 如果当前CU不能进一步划分,则调用predIntraLumaAng函数进行预测,调用transformNxN函数进行变换量化,之后再调用invtransformNxN函数进行反量化、反变换,和预测值相加获得重建像素,计算原始像素和重建像素的SSE作为失真,计算编码模式和系数所需的比特,从而计算RD Cost
代码及注释如下:
void Search::codeIntraLumaQT(Mode& mode, const CUGeom& cuGeom, uint32_t tuDepth, uint32_t absPartIdx, bool bAllowSplit, Cost& outCost, const uint32_t depthRange[2])
{
CUData& cu = mode.cu;
uint32_t fullDepth = cuGeom.depth + tuDepth;
uint32_t log2TrSize = cuGeom.log2CUSize - tuDepth;
uint32_t qtLayer = log2TrSize - 2;
uint32_t sizeIdx = log2TrSize - 2;
bool mightNotSplit = log2TrSize <= depthRange[1]; //可能不会划分
// 如果当前变换块尺寸大于最小的变换块尺寸且允许划分,则可能会划分
bool mightSplit = (log2TrSize > depthRange[0]) && (bAllowSplit || !mightNotSplit);
bool bEnableRDOQ = !!m_param->rdoqLevel;
/* If maximum RD penalty, force spits at TU size 32x32 if SPS allows TUs of 16x16 */
// 如果最大RD惩罚,如果SPS允许TUs为16x16,则尺寸为32x32的TU进行划分
if (m_param->rdPenalty == 2 && m_slice->m_sliceType != I_SLICE && log2TrSize == 5 && depthRange[0] <= 4)
{
mightNotSplit = false;
mightSplit = true;
}
Cost fullCost;
uint32_t bCBF = 0;
pixel* reconQt = m_rqt[qtLayer].reconQtYuv.getLumaAddr(absPartIdx);
uint32_t reconQtStride = m_rqt[qtLayer].reconQtYuv.m_size;
if (mightNotSplit)
{
if (mightSplit)
m_entropyCoder.store(m_rqt[fullDepth].rqtRoot);
const pixel* fenc = mode.fencYuv->getLumaAddr(absPartIdx);//原始YUV
pixel* pred = mode.predYuv.getLumaAddr(absPartIdx);//预测YUV
int16_t* residual = m_rqt[cuGeom.depth].tmpResiYuv.getLumaAddr(absPartIdx);//残差
uint32_t stride = mode.fencYuv->m_size;
// init availability pattern
uint32_t lumaPredMode = cu.m_lumaIntraDir[absPartIdx];//初始化帧内模式
IntraNeighbors intraNeighbors;
initIntraNeighbors(cu, absPartIdx, tuDepth, true, &intraNeighbors);
initAdiPattern(cu, cuGeom, absPartIdx, intraNeighbors, lumaPredMode);
// get prediction signal
predIntraLumaAng(lumaPredMode, pred, stride, log2TrSize);//预测,获得预测像素
cu.setTransformSkipSubParts(0, TEXT_LUMA, absPartIdx, fullDepth);
cu.setTUDepthSubParts(tuDepth, absPartIdx, fullDepth);
uint32_t coeffOffsetY = absPartIdx << (LOG2_UNIT_SIZE * 2);
coeff_t* coeffY = m_rqt[qtLayer].coeffRQT[0] + coeffOffsetY;
// store original entropy coding status
if (bEnableRDOQ)
m_entropyCoder.estBit(m_entropyCoder.m_estBitsSbac, log2TrSize, true);
// 计算残差
primitives.cu[sizeIdx].calcresidual[stride % 64 == 0](fenc, pred, residual, stride);
//变换量化
uint32_t numSig = m_quant.transformNxN(cu, fenc, stride, residual, stride, coeffY, log2TrSize, TEXT_LUMA, absPartIdx, false);
if (numSig)
{ //如果存在残差,则进行反变换
m_quant.invtransformNxN(cu, residual, stride, coeffY, log2TrSize, TEXT_LUMA, true, false, numSig);
bool reconQtYuvAlign = m_rqt[qtLayer].reconQtYuv.getAddrOffset(absPartIdx, mode.predYuv.m_size) % 64 == 0;
bool predAlign = mode.predYuv.getAddrOffset(absPartIdx, mode.predYuv.m_size) % 64 == 0;
bool residualAlign = m_rqt[cuGeom.depth].tmpResiYuv.getAddrOffset(absPartIdx, mode.predYuv.m_size) % 64 == 0;
bool bufferAlignCheck = (reconQtStride % 64 == 0) && (stride % 64 == 0) && reconQtYuvAlign && predAlign && residualAlign;
// 获得重建像素
primitives.cu[sizeIdx].add_ps[bufferAlignCheck](reconQt, reconQtStride, pred, residual, stride, stride);
}
else
// no coded residual, recon = pred 没有残差,重建像素等于预测像素
primitives.cu[sizeIdx].copy_pp(reconQt, reconQtStride, pred, stride);
bCBF = !!numSig << tuDepth;
cu.setCbfSubParts(bCBF, TEXT_LUMA, absPartIdx, fullDepth);
// 计算重建像素和原始像素的SSE平方误差和
fullCost.distortion = primitives.cu[sizeIdx].sse_pp(reconQt, reconQtStride, fenc, stride);
m_entropyCoder.resetBits();
// 编码模式
if (!absPartIdx)
{
if (!cu.m_slice->isIntra())
{
if (cu.m_slice->m_pps->bTransquantBypassEnabled)
m_entropyCoder.codeCUTransquantBypassFlag(cu.m_tqBypass[0]);
m_entropyCoder.codeSkipFlag(cu, 0);
m_entropyCoder.codePredMode(cu.m_predMode[0]);
}
m_entropyCoder.codePartSize(cu, 0, cuGeom.depth);
}
if (cu.m_partSize[0] == SIZE_2Nx2N)
{
if (!absPartIdx)
m_entropyCoder.codeIntraDirLumaAng(cu, 0, false);
}
else
{
uint32_t qNumParts = cuGeom.numPartitions >> 2;
if (!tuDepth)
{
for (uint32_t qIdx = 0; qIdx < 4; ++qIdx)
m_entropyCoder.codeIntraDirLumaAng(cu, qIdx * qNumParts, false);
}
else if (!(absPartIdx & (qNumParts - 1)))
m_entropyCoder.codeIntraDirLumaAng(cu, absPartIdx, false);
}
if (log2TrSize != depthRange[0])
m_entropyCoder.codeTransformSubdivFlag(0, 5 - log2TrSize);
m_entropyCoder.codeQtCbfLuma(!!numSig, tuDepth);
//编码系数
if (cu.getCbf(absPartIdx, TEXT_LUMA, tuDepth))
m_entropyCoder.codeCoeffNxN(cu, coeffY, absPartIdx, log2TrSize, TEXT_LUMA);
fullCost.bits = m_entropyCoder.getNumberOfWrittenBits();
if (m_param->rdPenalty && log2TrSize == 5 && m_slice->m_sliceType != I_SLICE)
fullCost.bits *= 4;
//计算 RD Cost
if (m_rdCost.m_psyRd)
{
fullCost.energy = m_rdCost.psyCost(sizeIdx, fenc, mode.fencYuv->m_size, reconQt, reconQtStride);
fullCost.rdcost = m_rdCost.calcPsyRdCost(fullCost.distortion, fullCost.bits, fullCost.energy);
}
else if(m_rdCost.m_ssimRd)
{
fullCost.energy = m_quant.ssimDistortion(cu, fenc, stride, reconQt, reconQtStride, log2TrSize, TEXT_LUMA, absPartIdx);
fullCost.rdcost = m_rdCost.calcSsimRdCost(fullCost.distortion, fullCost.bits, fullCost.energy);
}
else
fullCost.rdcost = m_rdCost.calcRdCost(fullCost.distortion, fullCost.bits);
}
else
fullCost.rdcost = MAX_INT64;
if (mightSplit)
{
if (mightNotSplit)
{
m_entropyCoder.store(m_rqt[fullDepth].rqtTest); // save state after full TU encode
m_entropyCoder.load(m_rqt[fullDepth].rqtRoot); // prep state of split encode
}
/* code split block */
uint32_t qNumParts = 1 << (log2TrSize - 1 - LOG2_UNIT_SIZE) * 2;
int checkTransformSkip = m_slice->m_pps->bTransformSkipEnabled && (log2TrSize - 1) <= MAX_LOG2_TS_SIZE && !cu.m_tqBypass[0];
if (m_param->bEnableTSkipFast)
checkTransformSkip &= cu.m_partSize[0] != SIZE_2Nx2N;
Cost splitCost;
uint32_t cbf = 0;
for (uint32_t qIdx = 0, qPartIdx = absPartIdx; qIdx < 4; ++qIdx, qPartIdx += qNumParts)
{
if (checkTransformSkip)
codeIntraLumaTSkip(mode, cuGeom, tuDepth + 1, qPartIdx, splitCost);
else
codeIntraLumaQT(mode, cuGeom, tuDepth + 1, qPartIdx, bAllowSplit, splitCost, depthRange);
cbf |= cu.getCbf(qPartIdx, TEXT_LUMA, tuDepth + 1);
}
cu.m_cbf[0][absPartIdx] |= (cbf << tuDepth);
if (mightNotSplit && log2TrSize != depthRange[0])
{
/* If we could have coded this TU depth, include cost of subdiv flag */
m_entropyCoder.resetBits();
m_entropyCoder.codeTransformSubdivFlag(1, 5 - log2TrSize);
splitCost.bits += m_entropyCoder.getNumberOfWrittenBits();
if (m_rdCost.m_psyRd)
splitCost.rdcost = m_rdCost.calcPsyRdCost(splitCost.distortion, splitCost.bits, splitCost.energy);
else if(m_rdCost.m_ssimRd)
splitCost.rdcost = m_rdCost.calcSsimRdCost(splitCost.distortion, splitCost.bits, splitCost.energy);
else
splitCost.rdcost = m_rdCost.calcRdCost(splitCost.distortion, splitCost.bits);
}
// 比较划分TU使用的RD Cost和不划分TU使用的RD Cost
if (splitCost.rdcost < fullCost.rdcost)
{
outCost.rdcost += splitCost.rdcost;
outCost.distortion += splitCost.distortion;
outCost.bits += splitCost.bits;
outCost.energy += splitCost.energy;
return;
}
else
{
// recover entropy state of full-size TU encode
m_entropyCoder.load(m_rqt[fullDepth].rqtTest);
// recover transform index and Cbf values
cu.setTUDepthSubParts(tuDepth, absPartIdx, fullDepth);
cu.setCbfSubParts(bCBF, TEXT_LUMA, absPartIdx, fullDepth);
cu.setTransformSkipSubParts(0, TEXT_LUMA, absPartIdx, fullDepth);
}
}
// set reconstruction for next intra prediction blocks if full TU prediction won
// 如果full TU预测获胜,则为下一帧内预测块设置重建
PicYuv* reconPic = m_frame->m_reconPic;
pixel* picReconY = reconPic->getLumaAddr(cu.m_cuAddr, cuGeom.absPartIdx + absPartIdx);
intptr_t picStride = reconPic->m_stride;
primitives.cu[sizeIdx].copy_pp(picReconY, picStride, reconQt, reconQtStride);
outCost.rdcost += fullCost.rdcost;
outCost.distortion += fullCost.distortion;
outCost.bits += fullCost.bits;
outCost.energy += fullCost.energy;
}