使用xlrd模块,xlrd是对于Excel进行读取,xlrd 操作的是xls/xlxs格式的excel
步骤:
1、导入xlrd莫款
2、打开Excel完成实例化
3、通过下标获取对应的表(可以通过表名获取)
4、通过列,行或者坐标获取表格的数据
文件格式:
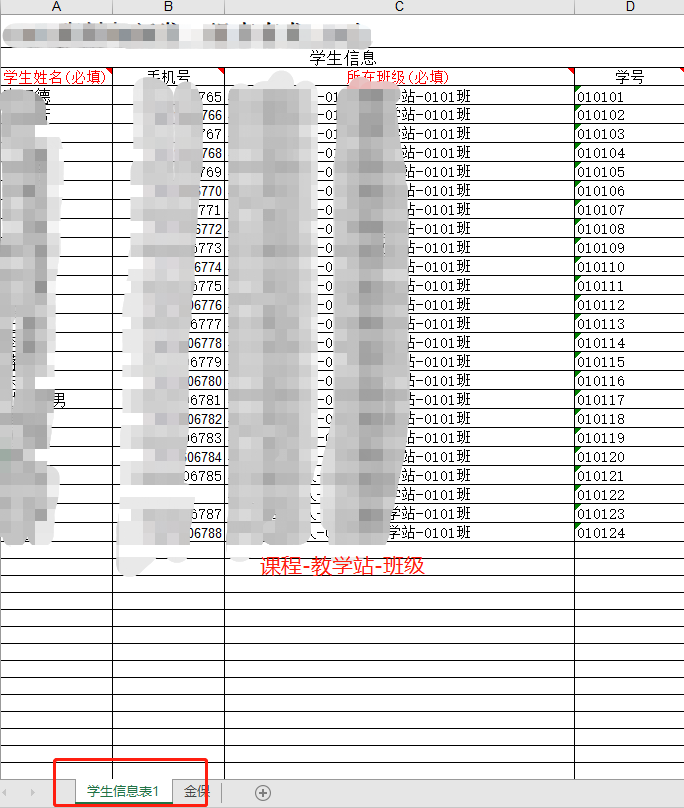

py文件:
import xlrd
class ExcelView(View):
"""
表格导入,分为学员导入或
该操作保存了: 班级信息,课程信息,学生信息
"""
def get(self, request):
return render(request, 'excelUpload.html')
def post(self, request):
'''
:param request:
:return: 上传文件excel表格 ,并进行解析
'''
f = request.FILES['my_file']
type_excel = f.name.split('.')[1]
if 'xlsx' == type_excel or 'xls' == type_excel:
# 开始解析上传的excel表格
wb = xlrd.open_workbook(filename=None, file_contents=f.read())
table = wb.sheet_by_name("学生信息表1")
nrows = table.nrows # 行数
# ncole = table.ncols # 列数
totalNum = nrows - 3 # 数据总数
sum = totalNum # 导入成功的数据总数
not_save_nrows = [] # 未被保存的行
class_check_row = table.row_values(3)
# 先检查该班级是否导入过
classname = class_check_row[2]
class_name = classname.split('-')[2]
class_info = ClassInfo.objects.filter(class_name=class_name).first()
# 如果已经导入过,则不导入该表
if class_info:
return JsonResponse({"state": 402, 'msg': '该班级学生信息已导入过了,请勿重复导入。'},
json_dumps_params={'ensure_ascii': False})
else:
# 保存班级信息
class_info = ClassInfo()
class_id = idCreater.classIdWorker.get_id()
class_info.class_id = class_id
class_info.class_name = classname.split('-')[2]
class_info.station_name = classname.split('-')[1]
class_info.class_status = 0
class_info.save()
# 课程信息
course_name = classname.split('-')[0]
course = CourseInfo.objects.filter(course_name=course_name).first()
# 如果该课程信息为空,则保存新的课程
if not course:
new_course = CourseInfo()
course_id = idCreater.courseIdWorker.get_id()
new_course.course_id = course_id
new_course.course_name = course_name
new_course.save()
try:
with transaction.atomic():
for i in range(3, nrows):
try:
rowValues = table.row_values(i) # 一行的数据
# logger.warn(rowValues)
# 当学生姓名或学生手机号码为空,则跳过
if rowValues[0] == "" or str(rowValues[1]).split('.')[0] == "":
sum -= 1 # 导入数减1
not_save_nrows.append(i + 1) # 改行没有被保存
continue
# 学生信息
student = Student()
student.student_id = idCreater.userIdWorker.get_id()
student.class_field = ClassInfo.objects.get(pk=class_id)
student.student_sno = rowValues[3]
student.name = rowValues[0]
student.phone_number = str(rowValues[1]).split('.')[0] # 不知道为什么,int类型上传后会变成float类型,导致变成12312341234.0,所以需要进行分割再第一个为手机号
student.create_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
student.stu_status = 0
student.save()
except:
# TODO 不知道为啥会出错,看程序逻辑没错,报错name太长mysql异常,我先跳过试试。
# TODO 文件存在根目录了 学员学习统计-测试1班
traceback.print_exc()
except IndexError:
return JsonResponse({"state": 402, 'msg': '上传excel表格式有误。'}, json_dumps_params={'ensure_ascii': False})
except Exception as e:
traceback.print_exc()
return JsonResponse({"state": 504, 'msg': '系统出现错误,请联系管理员。', 'errMsg': traceback.format_exc()},
json_dumps_params={'ensure_ascii': False})
return JsonResponse(
{"state": 200, "msg": "导入成功!", "totalNum": str(totalNum) + "条", "realNum": str(sum) + "条",
"not_save_nrows": "第" + str(not_save_nrows) + "行"}, json_dumps_params={'ensure_ascii': False})
return JsonResponse({"state": 402, 'msg': '上传文件格式不是xlsx'}, json_dumps_params={'ensure_ascii': False})html:
<form action="{% url 'excel' %}" method="post" enctype="multipart/form-data">
<input type="file" name="my_file">
<input type="submit">
</form>简单版:
# coding:utf-8
import xlrd
# excel路径
excle_path = r'E:\123.xlsx'
# 打开excel读取文件
data = xlrd.open_workbook(excle_path)
# 根据sheet下标选择读取内容
sheet = data.sheet_by_index(1)
# 获取到表的总行数
nrows = sheet.nrows
for i in range(nrows):
print(sheet.row_values(i))当一个excel文件中有多个sheet表时:
sheets = wb._sheet_names # 获取所有sheet表
for sheet in sheets:
table = wb.sheet_by_name(sheet)
nrows = table.nrows # 行数
# ncole = table.ncols # 列数
total_num += (nrows - 1)
class ExcelStudyView(View):
def get(self, request):
return render(request, 'excelStudyUpload.html')
def post(self, request):
'''
:param request:
:return: 解析一个学员学习统计共有两个产出存表
(1)产出每个学员当前的学习进度。student_learn_list
(2)产出一个班级列表。class_name_list
'''
# student_learn_list = []
# class_name_list = ClassInfo.objects.values("className")
total_num = 0 # 所有数据总数
total_num_actual = 0 # 实际总数
not_save_nrows = []
f = request.FILES['my_file']
type_excel = f.name.split('.')[1]
if 'xlsx' == type_excel or 'xls' == type_excel:
# 开始解析上传的excel表格
wb = xlrd.open_workbook(filename=None, file_contents=f.read())
# 利用本地文件测试
# wb = xlrd.open_workbook("C:\\Users\\Administrator\\PycharmProjects\\XXX.xlsx")
sheets = wb._sheet_names # 获取所有sheet表
for sheet in sheets:
table = wb.sheet_by_name(sheet)
nrows = table.nrows # 行数
# ncole = table.ncols # 列数
total_num += (nrows - 1)
try:
for i in range(1, nrows):
rowValues = table.row_values(i) # 一行的数据
# logger.error(rowValues)
# 更新学员学习状态
bumenList = rowValues[5].split(';') # 当前行的部门列数据
stu_name = rowValues[0] # 学生姓名
dingding = rowValues[1]
is_save = False # 是否有保存操作
for bumen in bumenList:
bumen_split = bumen.split('-')
# 判断部门格式是否正确并且该学员是学生
if len(bumen_split) == 5 and bumen_split[-1] == "学生":
# 通讯录-课程-教学楼-班级-学生 返回["课程","教学楼","班级","学生"] 给str(i)
# 再用"-"将他们连接起来形成 课程-教学楼-班级-学生
# studentNow.className = "-".join(str(i) for i in bumenList[0].split('-')[1:-1])
class_info = ClassInfo.objects.filter(class_name=bumen_split[-2]).first() # 通过班级名查找班级信息
course_info = CourseInfo.objects.filter(course_name=bumen_split[1]).first() # 通过课程名查询课程信息
# 通过学生姓名和班级ID,在学生表查找该学生
# str.maketrans(a,b,c)第一个参数为被替换的字符,第二个参数为替换的字符,第三个参数为要删除的字符
# 因为存在不同班有学生重名的情况,而钉钉后台导出的学习情况表对于同名的处理方式是在名字后面加数字,所以这里将名字后面的数字去掉后再结合班级查找学生信息
student_info = Student.objects.filter(Q(name=stu_name.translate(str.maketrans('', '', digits))) & Q(class_field=class_info)).first()
if student_info:
# 通过学生ID,课程ID,钉钉ID,班级ID确认学员学习进度表里有该学生的学习信息
stu_learn_info = StudentLearningInfo.objects.filter(Q(student=student_info) & Q(course=course_info) & Q(dingding_id=dingding) & Q(class_field=class_info)).first()
# 该学生学习信息为空,则插入
if not stu_learn_info:
stu_learn_info = StudentLearningInfo()
stu_learn_info.stu_learning_id = idCreater.stu_learn_IdWorker.get_id()
stu_learn_info.student = student_info # 学生ID
stu_learn_info.course = course_info # 课程ID
stu_learn_info.dingding_id = dingding # 钉钉ID
stu_learn_info.class_field = class_info # 班级ID
stu_learn_info.training_count = int(rowValues[6]) if str(rowValues[6]).replace(".","").isdigit() else 0 # 培训学习数
stu_learn_info.training_completion_count = int(rowValues[7]) if str(rowValues[7]).replace(".", "").isdigit() else 0 # 培训学习完成数
stu_learn_info.compulsory_completion_count = int(rowValues[8]) if str(rowValues[8]).replace(".", "").isdigit() else 0 # 必修培训完成数
stu_learn_info.compulsory_on_time_count = int(rowValues[9]) if str(rowValues[9]).replace(".", "").isdigit() else 0 # 必修培训按时完成数
stu_learn_info.compulsory_overdue_count = int(rowValues[10]) if str(rowValues[10]).replace(".", "").isdigit() else 0 # 必修培训逾期完成数
stu_learn_info.video_num = int(rowValues[-5]) if str(rowValues[-5]).replace(".","").isdigit() else 0 # 视频学习数
stu_learn_info.total_study_time = rowValues[-2] # 学习总时长 (时分秒)
stu_learn_info.study_time = int(rowValues[-1]) if str(rowValues[-1]).replace(".","").isdigit() else 0 # 学习时长(秒)
stu_learn_info.save()
is_save = True
total_num_actual += 1
else:
continue
if not is_save:
not_save_nrows.append(i + 1)
except IndexError:
return JsonResponse({"state": 402, 'errMsg': '上传excel表格式有误'},
json_dumps_params={'ensure_ascii': False})
except Exception as e:
traceback.print_exc()
return JsonResponse({"state": 504, 'errMsg': '系统出现错误,请联系管理员'},
json_dumps_params={'ensure_ascii': False})
# TODO 将student_learn_list和class_name_list入库。你可以选择在这里入库,也可以在添加到列表的时刻直接入库
# logger.error(student_learn_list)
# logger.error(class_name_list)
return JsonResponse({"state": 200, "msg": "保存成功!", "totalNum": str(total_num) + "条",
"realNum": str(total_num_actual) + "条",
"notSaveNrows": "第" + str(not_save_nrows) + "行"},
json_dumps_params={'ensure_ascii': False})
return JsonResponse({"state": 402, 'errMsg': '上传文件格式不是xlsx'}, json_dumps_params={'ensure_ascii': False})