1、HiveSource-xxxx.xxxx’s parallelism (200) is higher than the max parallelism (128). Please lower the parallelism or increase the max parallelism.
(1)报错
这是sql-cli 连接hive,查一张表报的错
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.runtime.JobException: Vertex Source: HiveSource-xxxx.xxxx's parallelism (200) is higher than the max parallelism (128). Please lower the parallelism or increase the max parallelism.
(2)解决
只需要改动flink包下的/conf包里sql-client-defaults.yaml这个文件里的max-parallelism改为300即可
execution:
max-parallelism: 300
2、flink sql读取hive表时建议手动配置table.exec.hive.fallback-mapred-reader: true生效
(1)报错
不管用sql-cli,还是把sql放在代码里,执行以下sql都是下面的结果,同时报错都是报Caused by: java.lang.IllegalArgumentException。
而我用Spark Sql跑下面的Sql都是正常的。
(1)First:
SELECT vid From table_A WHERE datekey = '20210112' AND event = 'XXX' AND vid = 'aaaaaa'; (**OK**)
SELECT vid From table_A WHERE datekey = '20210112' AND vid = 'aaaaaa'; (**Error**)
(2)Second:
SELECT vid From table_B WHERE datekey = '20210112' AND event = 'YYY' AND vid = 'bbbbbb'; (**OK**)
SELECT vid From table_B WHERE datekey = '20210112' AND vid = 'bbbbbb'; (**Error**)
报错原文:
[ERROR] Could not execute SQL statement. Reason:
java.lang.RuntimeException: SplitFetcher thread 22 received unexpected exception while polling the records
java.lang.RuntimeException: One or more fetchers have encountered exception
at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcherManager.checkErrors(SplitFetcherManager.java:199)
at org.apache.flink.connector.base.source.reader.SourceReaderBase.getNextFetch(SourceReaderBase.java:154)
at org.apache.flink.connector.base.source.reader.SourceReaderBase.pollNext(SourceReaderBase.java:116)
at org.apache.flink.streaming.api.operators.SourceOperator.emitNext(SourceOperator.java:273)
at org.apache.flink.streaming.runtime.io.StreamTaskSourceInput.emitNext(StreamTaskSourceInput.java:67)
at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65)
at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:395)
at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:191)
at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:609)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:573)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:755)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:570)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.RuntimeException: SplitFetcher thread 22 received unexpected exception while polling the records
at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:146)
at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.run(SplitFetcher.java:101)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
... 1 more
Caused by: java.lang.IllegalArgumentException
at java.nio.Buffer.position(Buffer.java:244)
at java.nio.HeapByteBuffer.get(HeapByteBuffer.java:153)
at java.nio.ByteBuffer.get(ByteBuffer.java:715)
at org.apache.flink.hive.shaded.parquet.io.api.Binary$ByteBufferBackedBinary.getBytes(Binary.java:422)
at org.apache.flink.hive.shaded.formats.parquet.vector.reader.BytesColumnReader.readBatchFromDictionaryIds(BytesColumnReader.java:79)
at org.apache.flink.hive.shaded.formats.parquet.vector.reader.BytesColumnReader.readBatchFromDictionaryIds(BytesColumnReader.java:33)
at org.apache.flink.hive.shaded.formats.parquet.vector.reader.AbstractColumnReader.readToVector(AbstractColumnReader.java:199)
at org.apache.flink.hive.shaded.formats.parquet.ParquetVectorizedInputFormat$ParquetReader.nextBatch(ParquetVectorizedInputFormat.java:359)
at org.apache.flink.hive.shaded.formats.parquet.ParquetVectorizedInputFormat$ParquetReader.readBatch(ParquetVectorizedInputFormat.java:328)
at org.apache.flink.connector.file.src.impl.FileSourceSplitReader.fetch(FileSourceSplitReader.java:67)
at org.apache.flink.connector.base.source.reader.fetcher.FetchTask.run(FetchTask.java:56)
at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:138)
... 6 more
(2)解决
昨天提交了一个issue:https://issues.apache.org/jira/browse/FLINK-20951,云邪大佬帮忙叫Rui Li大佬帮忙看了一下,需要配置table.exec.hive.fallback-mapred-reader: true。
我昨天翻遍了官网也看到了这个配置,官方文档说是默认开启的,所以还是建议手动将这个配置配置上。官网的解释是启动这个配置是启用hive表的向量化读取,当Format是ORC 或者 Parquet类型,同时没有hive的复杂类型。
官网链接:https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/hive/hive_read_write.html#vectorized-optimization-upon-read
a、用sql-cli可以配置在flink包下的/conf包里sql-client-defaults.yaml这个文件里
configuration:
table.exec.hive.fallback-mapred-reader: true
b、如果是在代码里提交flink sql,像下面这样配置Configuration就好:
Configuration configuration = tableEnv.getConfig().getConfiguration();
configuration.setString("table.exec.hive.fallback-mapred-reader", "true");
3、如果你的hive表的分区非常多,flink的默认配置会帮你开启很多的Taskmanager
(1)报错
可以看到一下子给你分配1000,当时看到时候被吓到了
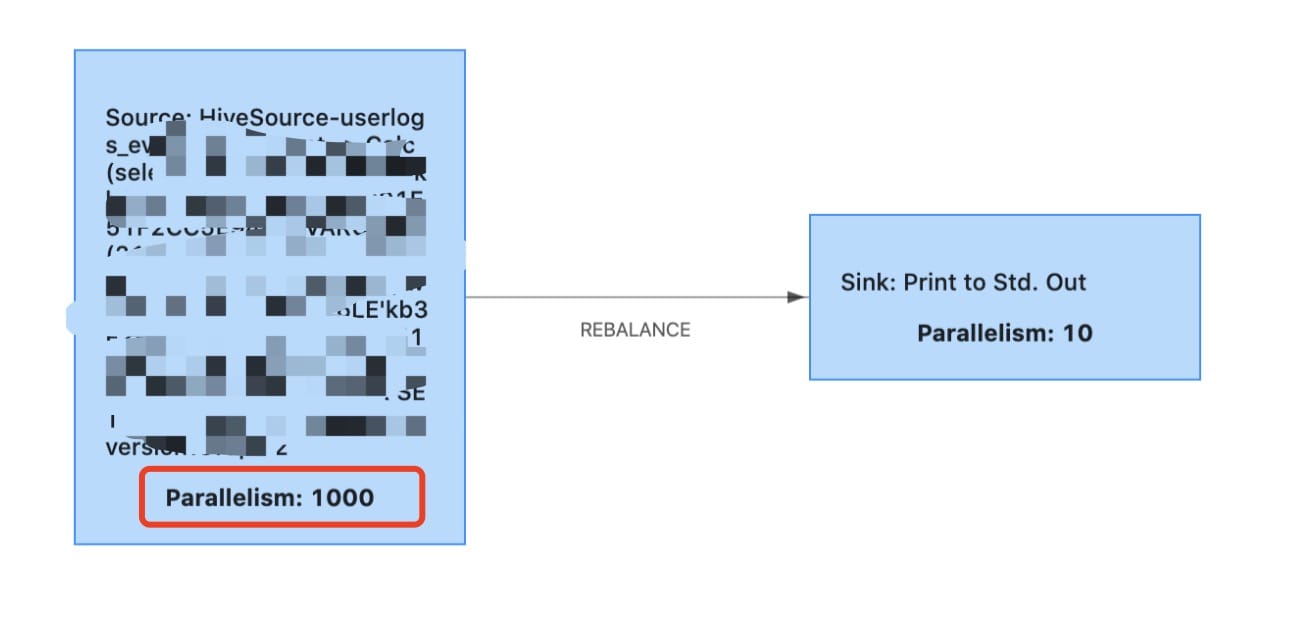
(2)解决
翻了一下官网,原来是Flink将根据文件数和每个文件中的块数为其Hive读取器推断最佳并行度,不过目前看起来并不是很良好。
可以关闭这个配置然后根据自己任务进行配置(这个参数会影响所有的hive作业,我建议自己启任务前启动一个合适的并行度设置在代码里,或者sql-cli可以在sql-client-defaults.yaml配置)
configuration.setString("table.exec.hive.infer-source-parallelism.max", "100");
configuration.setString("table.exec.hive.fallback-mapred-reader", "true");