一、架构与核心类
基本介绍
Locust是开源、使用Python开发、基于事件、支持分布式并且提供Web UI进行测试执行和结果展示的性能测试工具。
Locust的主要特性有两个:
- 模拟用户操作:支持多协议,Locust可以用于压测任意协议类型的系统
- 并发机制:摒弃了进程和线程,采用协程(gevent)的机制,单台测试机可以产生数千并发压力
Locust使用了以下几个核心库:
1) gevent
gevent是一种基于协程的Python网络库,它用到Greenlet提供的,封装了libevent事件循环的高层同步API。
2) flask
Python编写的轻量级Web应用框架。
3) requests
Python Http库
4) msgpack-python
MessagePack是一种快速、紧凑的二进制序列化格式,适用于类似JSON的数据格式。msgpack-python主要提供MessagePack数据序列化及反序列化的方法。
5) pyzmq
pyzmq是zeromq(一种通信队列)的Python实现,主要用来实现Locust的分布式模式运行
系统架构及对比
我们知道,完整的压测系统应该包含以下组件:

相比于主流的压测系统LoadRunner和Jmeter,Locust是一个更为纯粹的开源压测系统,框架本身的结构并不复杂,甚至只提供了最基础的组件,但也正因为如此,Locust具有极高的可编程性和扩展性。对于测试开发同学来说,可以比较轻松地使用Locust实现对任意协议的压测。
工具简单对比
| LoadRunner | Jmeter | Locust | |
|---|---|---|---|
| 压力生成器 | √ | √ | √ |
| 负载控制器 | √ | √ | √ |
| 系统资源监控器 | √ | x | x |
| 结果采集器 | √ | √ | √ |
| 结果分析器 | √ | √ | √ |
上表简单展示了几个工具包含的压测组件,Locust的架构非常简单,部分组件的实现甚至都不完善,比如结果分析器,Locust本身并没有很详细的测试报告。但这并不妨碍它成为优秀的开源框架。
Locust的架构
Locust 最近发布了1.x 版本,代码进行了重构,重封装,对很多类进行了重命名,本文尽量使用新名词,但涉及的旧名词不影响理解。
- locust架构上使用master-slave模型,支持单机和分布式
- master和slave(即worker)使用 ZeroMQ 协议通讯
- 提供web页面管理master,从而控制slave,同时展示压测过程和汇总结果
- 可选no-web模式(一般用于调试)
- 基于Python本身已经支持跨平台

为了减少CPython的GIL限制,充分利用多核CPU,建议单机启动CPU核数的slave(多进程)。
核心类
上面展示的Locust架构,从代码层面来看究竟是如何实现的呢?下面我们就来窥视一

简单来说,Locust的代码分为以下模块:
- Runner-执行器,Locust的核心类,定义了整个框架的执行逻辑,实现了Master、Slave(worker)等执行器
- User-压测用例,提供了HttpUser压测http协议,用户可以定义事务,断言等,也可以实现特定协议的User
- Socket-通信器,提供了分布式模式下master和slave的交互方式
- RequestStats-采集、分析器,定义了结果分析和数据上报格式
- EventHook-事件钩子,通过预先定义的事件使得我们可以在这些事件发生时(比如slave上报)做一些额外的操作
- WebUI-提供web界面的操作台和压测过程展示
下面我们看看核心类的主要成员变量和方法

- 用户定义的User类作为Runner的user_classes传入
- master的client_listener监听施压端client消息
- slave的worker方法监听master消息
- slave的stats_reporter方法上报压测数据,默认3s上报一次
- slave的start启动协程,使用master分配的并发数开始压测
- slave默认1s上报一次心跳,如果master超过3s未收到某个slave的心跳则会将其标记为missing状态
- TaskSet和User持有client,可以在类中直接发起客户端请求,client可以自己实现,Locust只实现了HttpUser
二、Runner的状态与通信机制
接下来我们继续了解Locust分布式压测的核心:Runner的状态和通信机制。我们知道Locust等压测工具支持分布式压测,就是说理论上可以通过不断添加压力机(worker)提高并发数量,这个机制让使用者可以自由地增减机器资源,从而达到期望的施压能力。
Runner状态机
在分布式场景下,除了数据一致性,状态同步也是非常重要的。在Locust的master-slave架构下,需要管理master和slave的状态,不仅为了控制压测的开始或停止,也是为了掌握当前的压力机情况。那么都有哪些状态?
| 状态 | 说明 |
|---|---|
| ready | 准备就绪,master和slave启动后默认状态 |
| hatching | 正在孵化压力机,对master来说正在告诉slave们开始干活,对slave来说是过渡状态,因为它们马上要running |
| running | 正在压测 |
| cleanup | 当发生GreenletExit时的状态,一般不会出现 |
| stopping | 表示正在通知slave们停止,只有master有这个状态 |
| stopped | 压测已经停止 |
| missing | 状态丢失,只有slave有的状态,默认3秒如果master没有收到slave的心跳就会认为它missing了,一般是进程没有正常退出导致 |
Runner的状态不多,但是在压测过程中起到非常重要的作用,状态之间是按约定的方式进行扭转的,我们使用Locust的web界面管理master的状态,master根据我们的操作通过通信机制推进slave的状态。

通信机制
Master与Slave之间是通过Zeromq建立的TCP连接进行通信的(一对多)。
ZeroMQ(简称ZMQ)是一个基于消息队列的多线程网络库,其对套接字类型、连接处理、帧、甚至路由的底层细节进行抽象,提供跨越多种传输协议的套接字。
ZMQ是网络通信中新的一层,介于应用层和传输层之间(按照TCP/IP划分),其是一个可伸缩层,可并行运行,分散在分布式系统间。
master与各个slave各维持一个TCP连接,在每个连接中,master下发的命令,slave上报的信息等自由地的传输着。
消息格式
class Message(object):
def __init__(self, message_type, data, node_id):
self.type = message_type
self.data = data
self.node_id = node_id
def serialize(self):
return msgpack.dumps((self.type, self.data, self.node_id))
@classmethod
def unserialize(cls, data):
msg = cls(*msgpack.loads(data, raw=False))
return msg
其中message_type指明消息类型,data是实际的消息内容,node_id指明机器ID。Locust使用msgpack做序列化与反序列化处理。
消息类型和结构
master和slave之间的消息类型不过10种,其中大部分消息由slave上报给master,下方表格可以清楚的看到,实现一套分布式系统并没有那么复杂。
| 序号 | message_type | 发送者 | data格式 | 发送时机 |
|---|---|---|---|---|
| 1 | client_ready | slave | 空 | slave启动后或压测停止完成 |
| 2 | hatching | slave | 空 | 接受到master的hatch先发送一个确认 |
| 3 | hatch_complete | slave | {"count":n} | 所有并发用户已经孵化完成 |
| 4 | client_stopped | slave | 空 | 停止所有并发用户后 |
| 5 | heatbeat | slave | {"state": x,"current_cpu_usage":x} | 默认每3秒上报一次心跳 |
| 6 | stats | slave | {"stats":[], "stats_total":{}, "errors":{},"user_count":x} | 每3秒上报一次压测信息 |
| 7 | exception | slave | {"msg":x, "traceback":x} | TaskSet.run出现异常 |
| 8 | hatch | master | {"hatch_rate":x, "num_users":x, "host":x, "stop_timeout":x} | 开始swarm |
| 9 | stop | master | 空 | 点击stop |
| 10 | quit | master,slave | 空 | 手动或其他方式退出的时候 |
可以看到上面有一种非常重要的消息类型——stats,压测的结果采集都封装在这个消息里。
三、结果采集器
统计对象
从上面我们知道有一个非常重要的消息类型——stats,这个是slave给master发送的消息,默认每3秒钟上报一次。stats消息的结构如下所示:
{
"stats": [],
"stats_total": {},
"errors": {},
"user_count": 10
}
实际上,slave也是持有着类似如上json格式的三个对象:
- RequestStats
- StatsEntry
- StatsError
其中每一个locust进程会维护一个全局RequestStats单例global_stats,这个实例包含一个StatsEntry实例total(对应json的stats_total),以及两个字典entries(对应json的stats)和errors(对应json的errors),其中entries字典key为(name,method),对应值为一个StatsEntry实例,另一个errors字典的key为(name,method,error),对应值为一个StatsError实例。可见,global_stats包含了单个slave汇总的信息,以及各个请求url或name的统计信息。在分布式的场景下,每个slave都会维护一个global_stats, 在一个上报周期达到后将信息发送到master,发送完成后就会重置所有数据,进入下一个周期的统计。
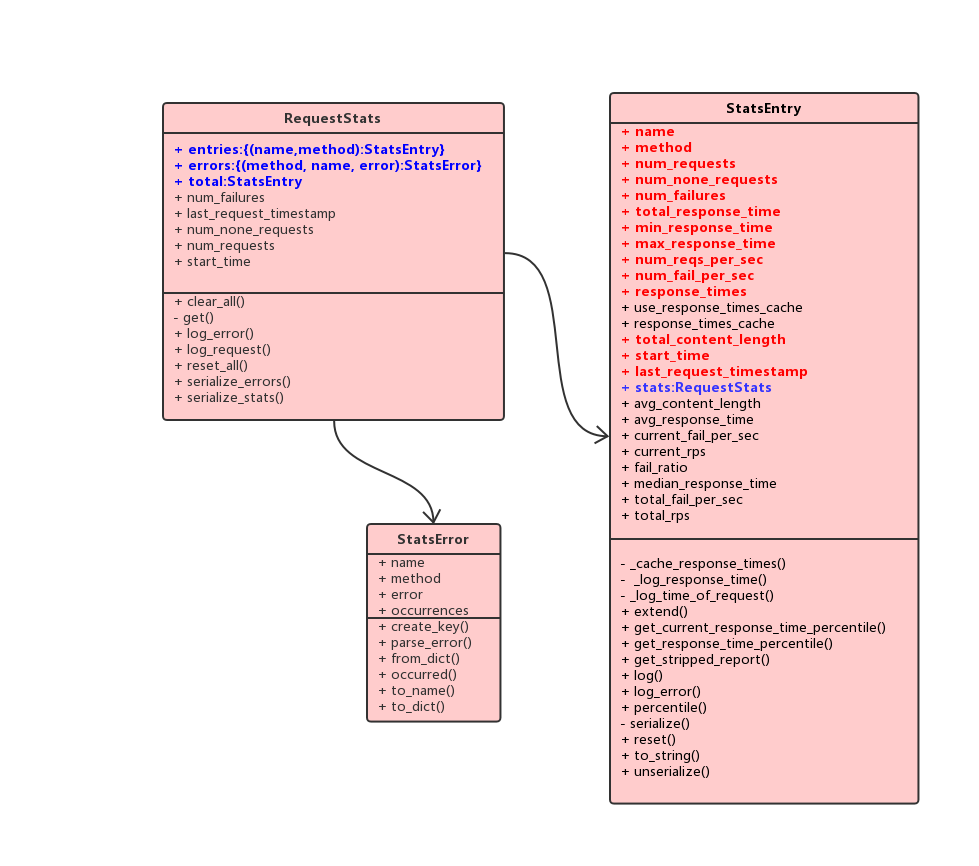
上图中红色的字段是slave真正上报给master的数据。
统计过程
那么slave是如何统计消息,又究竟需要上报什么内容给master?master又是如何汇总的呢?下面我们来看看整个统计过程:
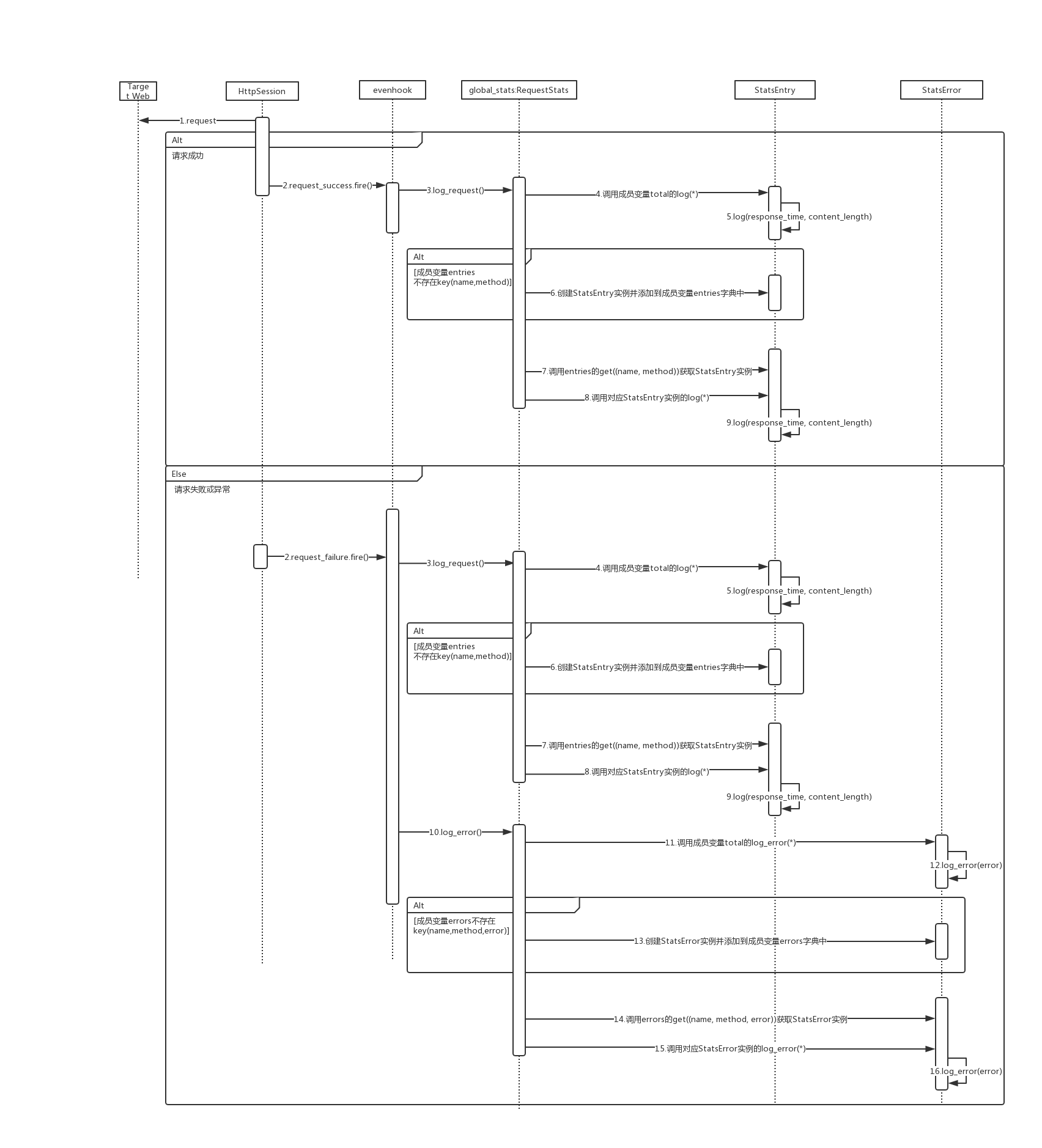
在每一次请求后,无论是成功还是失败,都会触发对应的request_success或者request_failure事件,stats.py文件中的数据统计模块订阅了对应的事件,会调用global_stats对数据进行统计。
在slave的一个上报周期达到后,触发on_report_to_master事件,此时global_stats就会依次调用以下方法对数据进行序列化:
- serialize_stats
- total.get_stripped_report
- serialize_errors
其实也就是对上面提到的total和两个字典中的内容进行序列化,其实就是转为json字符串。
def on_report_to_master(client_id, data):
data["stats"] = global_stats.serialize_stats()
data["stats_total"] = global_stats.total.get_stripped_report()
data["errors"] = global_stats.serialize_errors()
global_stats.errors = {}
下图是断点过程看到的stats消息内容(在msgpack序列化之前):

每秒请求数和响应时间及其对应请求个数
StatsEntry有两个比较重要的对象,分别是num_reqs_per_sec和response_times,它们都是字典类型,其中num_reqs_per_sec的key是秒时间戳,显示当前秒完成了多少个请求,统计的时间是完成请求的时刻,比如如果一个请求从第0秒开始,第3秒完成,那么这个请求统计在第3秒的时间戳上,这个对象可以很方便的计算出rps。response_times的key是响应时间,单位是豪秒,为了防止key过多,做了取整,比如147 取 150, 3432 取 3400 和 58760 取 59000,这个是为了方便获得类似90%请求的完成时间(小于等于该时间),99%请求的完成时间,下面具体的源码:
def _log_time_of_request(self, current_time):
t = int(current_time)
self.num_reqs_per_sec[t] = self.num_reqs_per_sec.setdefault(t, 0) + 1
self.last_request_timestamp = current_time
def _log_response_time(self, response_time):
if response_time is None:
self.num_none_requests += 1
return
self.total_response_time += response_time
if self.min_response_time is None:
self.min_response_time = response_time
self.min_response_time = min(self.min_response_time, response_time)
self.max_response_time = max(self.max_response_time, response_time)
# to avoid to much data that has to be transfered to the master node when
# running in distributed mode, we save the response time rounded in a dict
# so that 147 becomes 150, 3432 becomes 3400 and 58760 becomes 59000
if response_time < 100:
rounded_response_time = response_time
elif response_time < 1000:
rounded_response_time = int(round(response_time, -1))
elif response_time < 10000:
rounded_response_time = int(round(response_time, -2))
else:
rounded_response_time = int(round(response_time, -3))
# increase request count for the rounded key in response time dict
self.response_times.setdefault(rounded_response_time, 0)
self.response_times[rounded_response_time] += 1
master汇总信息
slave的每一个stats消息到达master后,都会触发master的slave_report事件,master也拥有自己的global_stats,因此只需要将对应的信息进行累加(可以理解是所有slave对应内容的汇总)。具体在StatsEntry的extend方法:
def extend(self, other):
"""
Extend the data from the current StatsEntry with the stats from another
StatsEntry instance.
"""
if self.last_request_timestamp is not None and other.last_request_timestamp is not None:
self.last_request_timestamp = max(self.last_request_timestamp, other.last_request_timestamp)
elif other.last_request_timestamp is not None:
self.last_request_timestamp = other.last_request_timestamp
self.start_time = min(self.start_time, other.start_time)
self.num_requests = self.num_requests + other.num_requests
self.num_none_requests = self.num_none_requests + other.num_none_requests
self.num_failures = self.num_failures + other.num_failures
self.total_response_time = self.total_response_time + other.total_response_time
self.max_response_time = max(self.max_response_time, other.max_response_time)
if self.min_response_time is not None and other.min_response_time is not None:
self.min_response_time = min(self.min_response_time, other.min_response_time)
elif other.min_response_time is not None:
# this means self.min_response_time is None, so we can safely replace it
self.min_response_time = other.min_response_time
self.total_content_length = self.total_content_length + other.total_content_length
for key in other.response_times:
self.response_times[key] = self.response_times.get(key, 0) + other.response_times[key]
for key in other.num_reqs_per_sec:
self.num_reqs_per_sec[key] = self.num_reqs_per_sec.get(key, 0) + other.num_reqs_per_sec[key]
for key in other.num_fail_per_sec:
self.num_fail_per_sec[key] = self.num_fail_per_sec.get(key, 0) + other.num_fail_per_sec[key]
核心指标
Locust核心的指标其实就4个:
- 并发数
- RPS
- 响应时间
- 异常率

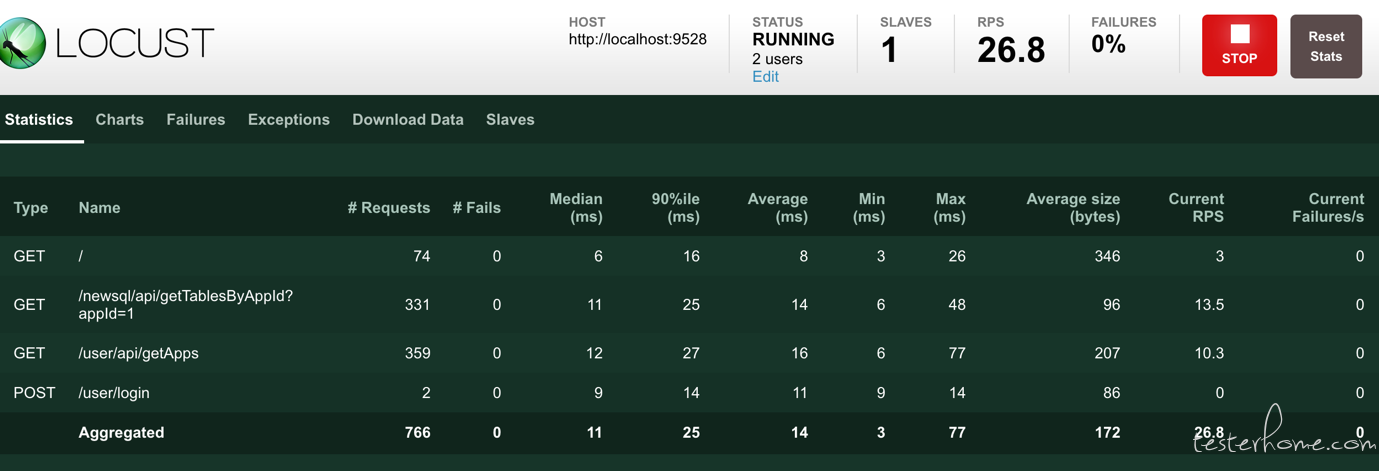
我们还是回到文章开头的那个json:
{
"stats": [],
"stats_total": {},
"errors": {},
"user_count": 10
}
结合上方Locust的压测过程截图,我们可以看到,各个接口的指标其实就是stats对象里的各个字段,而最下方汇总的Aggregated这一行则对应stats_total的各个字段,尽管这个json只是slave单个stats消息的内容,却也是最终要显示的内容,只是master对各个消息做了汇总而已。汇总的方式也相当简单,请见上方的StatsEntry的extend方法。
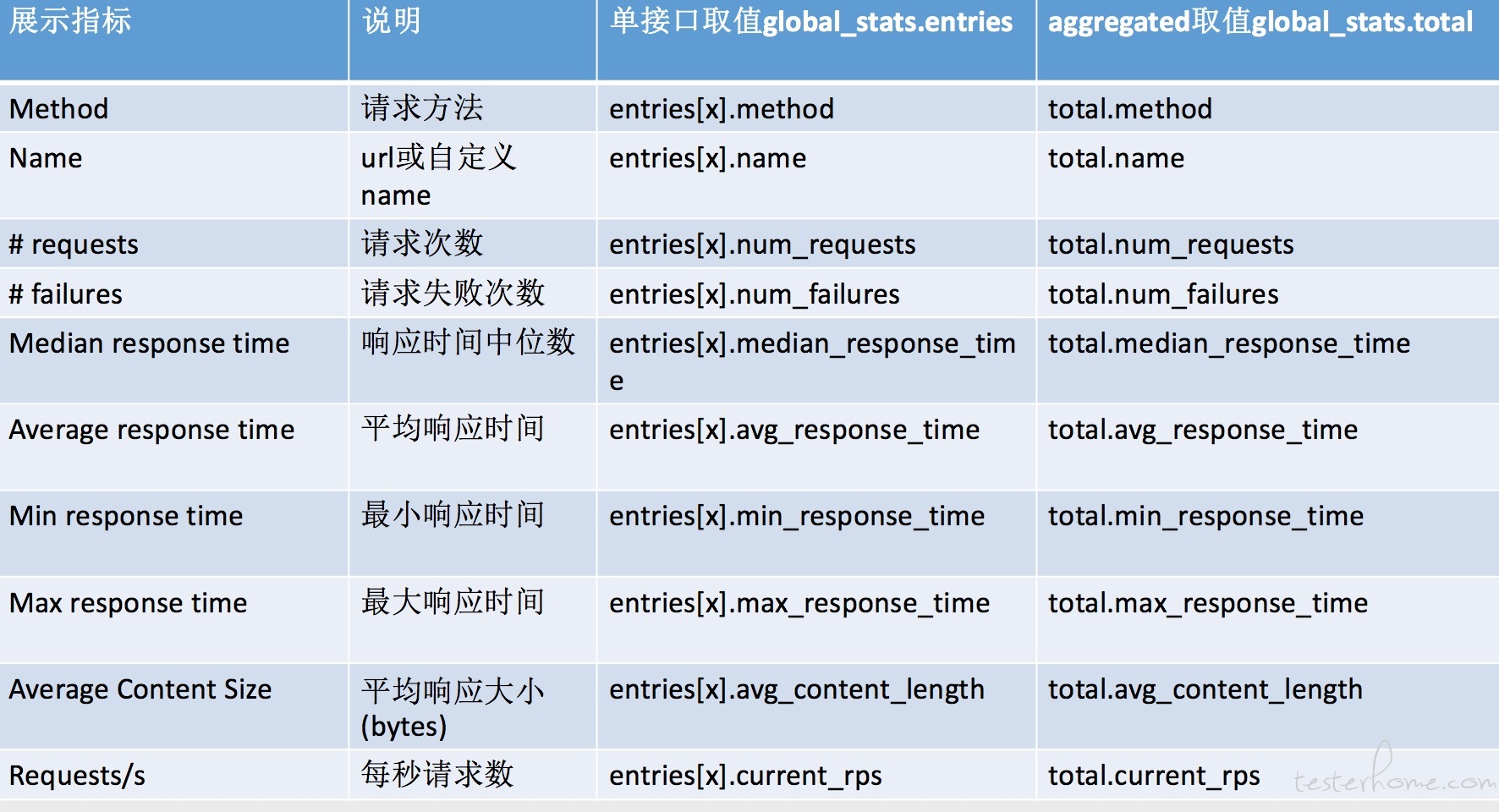
因为master和web模块是一起部署的,因此web可以直接使用master的global_stats对象并展示其内容,可以做到动态显示。
本文讲解的eventHook基于Locust的1.x版本。
四、事件钩子
Locust中的事件钩子,我认为设计得非常巧妙,所以最后再来讲一下它。event.py模块包含了两个类,一个是事件钩子定义类EventHook,一个是事件钩子类型类Events,为不同的事件提供hook。事件处理函数注册相应的hook以后,我们可以很方便的的基于event触发处理函数,实现事件驱动。
EventHook定义了三个方法:
def add_listener(self, handler):
self._handlers.append(handler)
return handler
def remove_listener(self, handler):
self._handlers.remove(handler)
def fire(self, *, reverse=False, **kwargs):
if reverse:
handlers = reversed(self._handlers)
else:
handlers = self._handlers
for handler in handlers:
handler(**kwargs)
可以看到add_listener、remove_listener的作用是注册或删除监听函数,fire方法是触发处理函数。EventHook的实现相比Locust 0.x版本有较大改变(不再使用Python的内置魔方方法)。
Events中包含了11个事件钩子,分别是:

事件钩子的实现原理
事件钩子的原理可以简单理解成,1.定义处理函数 ——> 2.注册到某个eventHook ——> 3.在某个时机触发eventHook ——> 4.该eventHook遍历执行所有处理函数。在代码层面就是定义函数,然后add_listener,最后在想要的位置触发eventHook的fire方法并传入定义好的参数,这里参数是固定的,不能随意传入,之所以每个处理函数都能对参数进行修改,是因为这里的参数传递是『引用传递』,明白了这一点就算是掌握了EventHook的基本原理。
其中Locust本身预定义并注册了一些处理函数,比如事件钩子report_to_master、worker_report都有对应的处理函数,实现分布式模式下数据上报时数据的构造和计算,比如事件钩子init,初始化master的WebUI。
事件钩子的作用
那么,事件钩子究竟有什么作用?
在我看来有以下作用:
- 代码解耦,比如解耦Runner和Stats模块。
- 提供扩展性,通过预置的钩子和触发点,为使用者提供了可扩展的特性。
举扩展性的例子,使用者可以很轻松地:
- 往worker上报的stats消息添加自定义数据
- 在Locust实例启动时在WebUI中添加自定义接口
- 在每次请求成功或失败之后做一些额外的事情
如何使用钩子
在Locust 1.x版本之前,使用以下方法定义和注册钩子:
def on_report_to_master(client_id, data):
data["stats"] = global_stats.serialize_stats()
data["stats_total"] = global_stats.total.get_stripped_report()
data["errors"] = global_stats.serialize_errors()
global_stats.errors = {}
def on_slave_report(client_id, data):
for stats_data in data["stats"]:
entry = StatsEntry.unserialize(stats_data)
request_key = (entry.name, entry.method)
if not request_key in global_stats.entries:
global_stats.entries[request_key] = StatsEntry(global_stats, entry.name, entry.method)
global_stats.entries[request_key].extend(entry)
...
events.report_to_master += on_report_to_master
events.slave_report += on_slave_report
在1.x及之后的版本有两种使用方式:
# 方式一与之前类似
def on_report_to_master(client_id, data):
data["stats"] = stats.serialize_stats()
data["stats_total"] = stats.total.get_stripped_report()
data["errors"] = stats.serialize_errors()
stats.errors = {}
def on_worker_report(client_id, data):
for stats_data in data["stats"]:
entry = StatsEntry.unserialize(stats_data)
request_key = (entry.name, entry.method)
if not request_key in stats.entries:
stats.entries[request_key] = StatsEntry(stats, entry.name, entry.method, use_response_times_cache=True)
stats.entries[request_key].extend(entry)
for error_key, error in data["errors"].items():
if error_key not in stats.errors:
stats.errors[error_key] = StatsError.from_dict(error)
else:
stats.errors[error_key].occurrences += error["occurrences"]
stats.total.extend(StatsEntry.unserialize(data["stats_total"]))
events.report_to_master.add_listener(on_report_to_master)
events.worker_report.add_listener(on_worker_report)
# 方式二,使用装饰器
@events.report_to_master.add_listener
def on_report_to_master(client_id, data):
"""
This event is triggered on the worker instances every time a stats report is
to be sent to the locust master. It will allow us to add our extra content-length
data to the dict that is being sent, and then we clear the local stats in the worker.
"""
data["content-length"] = stats["content-length"]
stats["content-length"] = 0
@events.worker_report.add_listener
def on_worker_report(client_id, data):
"""
This event is triggered on the master instance when a new stats report arrives
from a worker. Here we just add the content-length to the master's aggregated
stats dict.
"""
stats["content-length"] += data["content-length"]
第二种方式更加简洁,不容易忘记注册处理函数。