我是一个用惯Loadrunner的人,由于Loadrunner过于重量级,不方便在云端部署和使用,所以平常在这方面只能选择Jmeter,Jmeter的开源性和轻量化是我最喜欢的地方,但是Jmeter的脚本开发模式是我最不喜欢的地方:jmx脚本对应的XML格式太不直观,不方便维护和管理,代码调试也不方便(对于我们这些不愿意依赖于脚本录制的人来说,这点很重要),另外不喜欢的就是Jmeter的性能和稳定性,即使用了Non-GUI + 分布式压测的模式,Master节点的承受能力也不如Loadrunner。
所以我真的比较倾向于找一款既能像Loadrunner那样高性能高 稳定性,代码维护管理自如,又能像Jmeter那样轻量级的、高扩展性的测试工具。目前来看好像不存在这种工具,但是有一款性能测试工具叫Gatling,与Jmeter进行分析比较了一下,觉得它很有潜力,兴许哪一天,它借鉴了Jmeter的一些优点,就达到了我的要求,或者Jmeter借鉴一下它,做个翻天腹地的改造,那也未尝不可。
对于Gatling的优点网上也总结了很多,我也不多说,但是光从测试场景配置上来说,Gatling就不输Loadrunner,拿例子来说明:
setUp(
scn.inject(
nothingFor(4 seconds), // 场景1
atOnceUsers(10), // 场景2
rampUsers(10) over(5 seconds), // 场景3
constantUsersPerSec(20) during(15 seconds), // 场景4
constantUsersPerSec(20) during(15 seconds) randomized, // 场景5
rampUsersPerSec(10) to(20) during(10 minutes), // 场景6
rampUsersPerSec(10) to(20) during(10 minutes) randomized, // 场景7
splitUsers(100) into(rampUsers(10) over(10 seconds)) separatedBy(10 seconds), // 场景8
splitUsers(100) into(rampUsers(10) over(10 seconds)) separatedBy(atOnceUsers(30)), // 场景9
heavisideUsers(100) over(20 seconds) // 场景10
).protocols(httpConf)
)
以上代码包含了10个场景的例子:
- nothingFor(4 seconds)
在指定的时间段(4 seconds)内什么都不干 - atOnceUsers(10)
一次模拟的用户数量(10)。 - rampUsers(10) over(5 seconds)
在指定的时间段(5 seconds)内逐渐增加用户数到指定的数量(10)。 - constantUsersPerSec(10) during(20 seconds)
以固定的速度模拟用户,指定每秒模拟的用户数(10),指定模拟测试时间长度(20 seconds)。 - constantUsersPerSec(10) during(20 seconds) randomized
以固定的速度模拟用户,指定每秒模拟的用户数(10),指定模拟时间段(20 seconds)。用户数将在随机被随机模拟(毫秒级别)。 - rampUsersPerSec(10) to (20) during(20 seconds)
在指定的时间(20 seconds)内,使每秒模拟的用户从数量1(10)逐渐增加到数量2(20),速度匀速。 - rampUsersPerSec(10) to (20) during(20 seconds) randomized
在指定的时间(20 seconds)内,使每秒模拟的用户从数量1(10)增加到数量2(20),速度随机。 - splitUsers(100) into(rampUsers(10) over(10 seconds)) separatedBy(10 seconds)
反复执行所定义的模拟步骤(rampUsers(10) over(10 seconds)),每次暂停指定的时间(10 seconds),直到总数达到指定的数量(100) - splitUsers(100) into(rampUsers(10) over(10 seconds)) separatedBy(atOnceUsers(30))
反复依次执行所定义的模拟步骤1(rampUsers(10) over(10 seconds))和模拟步骤2(atOnceUsers(30)),直到总数达到指定的数量(100)左右 - heavisideUsers(100) over(10 seconds)
在指定的时间(10 seconds)内使用类似单位阶跃函数的方法逐渐增加模拟并发的用户,直到总数达到指定的数量(100).简单说就是每秒并发用户数递增。
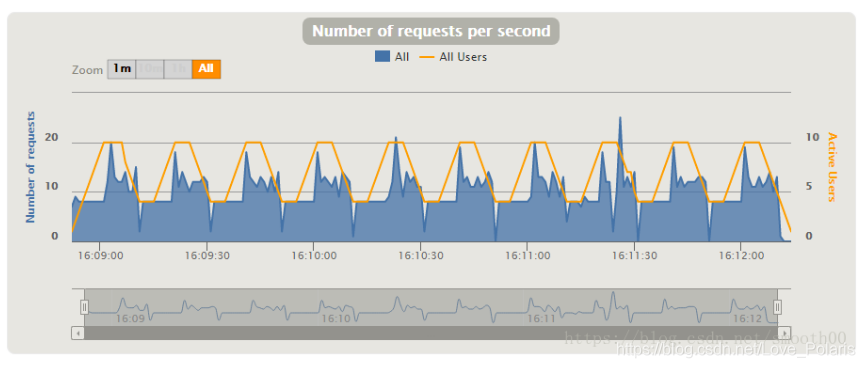
就拿场景8来说,可以制造一种波浪型压力,非常适合模拟一种脉冲式的压力测试或是某类稳定性测试(压力按波峰波谷有规律的分布),如下所示:
虽然Gatling很让我们惊奇,但就目前来说,还远没有达到我们的最佳选择,不过研究它已经非常有必要了,毕竟一个好工具的普及不是一天两天的事。Jmeter有那么多不如意的地方,但我们还得继续用呀,现在脚本的易维护性方面还不是最重要的问题,最紧迫的是如何对Jmeter进行减负,以实现稳定超高并发测试,目前只能考虑以下的方式进行:
减负一,优化监听(GUI模式,尽量不考虑)
1.“查看结果树”,需要勾选“仅日志错误”,这样只会保存错误日志到内存,数据不会多。如果保存所有,那么会保存每个请求信息和相关信息,而且这些数据都是保存到jvm内存的,且常驻数据无法回收,上万十万大量请求很快就会压垮jmeter。
2.“聚合报告”中小并(100以内)发可以保留;高并发去掉,添加“Simple Data Writer”且保存csv格式数据。“聚合报告”是非常消耗cpu的。
3.其他监听组件可以都去掉,测试完后通过保存的结果,线下生成图表报告
减负二,优化监听(Non-GUI命令行模式)
1.“查看结果树”,需要勾选“仅日志错误”,需要设置路径,保存错误信息到文件,并且保存所有信息(点击Configure,勾选所有非CSV选项)
2.“聚合报告”命令行下无效
3. 其他监听组件可以都去掉,基本在Non-GUI下无效
减负三,结果文件优化
- 结果数据一定要保存为CSV格式(比起xml格式,每条数据会少很多)(可以用Non-GUI命令指定csv日志保存)
2.“查看结果树”保存的错误信息要保存为xml,可以保存完整结果信息,方便错误分析
减负四,如果要超高并发建议不要直接使用分布式压测
- jmeter分布部署只是缓解问题,没根本解决问题,高并发时master机器承受的压力很大,形成单点,无法在高并发时提供稳定负载
- 数据会写可能丢失
- 解决方法:需要手工运行slave,或利用jenkins同时触发多台slave
减负五,再强调一下,建议用Non-GUI命令行模式运行,并且选择Linux环境运行Jmeter也是很有必要的
- 用Non-GUI运行jmeter生成csv报告,但别输出html报告(需要高jvm内存来完成,所以分成两步进行)
- 修改jmeter的jvm内存(建议物理内存的一半,HEAP的xms和xmx,1G的csv报告建议对应2G的xmx大小),用高jvm内存来转换csv报告至html报告(内存不够就换机器来转换报告)
减负六,可以选择用Jmeter + Grafana + InfluxDB的方式,来代替报告文件的生成,参考我的另一篇文章《关于Jmeter长时间压测的可视化监控报告》
- 将Jmeter分布式集群去中心化,Master节点不再负责收集和处理测试数据,只负责调度slave节点
- 支持多Master-slave,形成多路Jmeter测试集群(利用Jenkins或其他调度工具同时触发调度测试)