一、引言
需求:保存一条数据:zmj-18-女-10000
-
运行时内存保存数据(变量/对象)
数据保存方式:变量、数组、集合、对象
缺点:临时存放空间,数据无法永久保存
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KGxMyK64-1588999837925)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1573785712724.png)]](https://img-blog.csdnimg.cn/20200509125437444.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0phdmFfbG92ZXJfenBhcms=,size_16,color_FFFFFF,t_70)
-
文件存储数据,借助于IO流技术
优点:永久性保存数据
问题:
- 不支持数据类型(文件中只有String类型)
- 文件存储不安全(可以随意更改文件内容)
- 不支持多用户访问
- 数据支持量小
二、数据库
-
概念:数据仓库,数据管理的软件
-
访问数据库的客户端(Client) ---- 数据库的服务器端(Server)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D4EdeP88-1588999837928)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1573788565972.png)]](https://img-blog.csdnimg.cn/20200509125543745.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0phdmFfbG92ZXJfenBhcms=,size_16,color_FFFFFF,t_70)
-
常见的数据库
关系型数据库:
oracle oracle公司(甲骨文) 收费
MySQL MySQLAB公司 被oracle收购 免费
DB2
SQLServer
非关系型数据库(NoSQL)
Mongodb Redis Memcache
-
数据库存储数据方式的相关概念
表:Table,用于存放数据
行:Row,代表一条数据
列 / 字段:Column,表示当前列数据的 含义。
– 主键:primary key,唯一标识数据库表中 的一条数据
– 外键:foreign key,用来体现两张表之间的关系。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ovlc7HQz-1588999837929)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1573796802818.png)]](https://img-blog.csdnimg.cn/20200509125618947.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0phdmFfbG92ZXJfenBhcms=,size_16,color_FFFFFF,t_70)
三 、数据库的安装
-
安装Oracle服务
① 安装 OracleXE.exe 程序
注意:a. 安装路径必须是英文路径
b. 计算机名字名字不能是中文(先改为英文,再安装oracle)
c. 360腾讯管家 不要运行
d. 安装需要用户数据密码,需要记住,后期用到
② 正常启动 Oracle服务,可以接收外部访问
a. 操作:计算机–>右键–>管理–>服务和应用程序–>服务–>OracleXxx 或是 下面菜单栏 -->右键 --> 启动任务管理器 --> 服务
b. 关注的服务
I. OracleServiceXE —> Oracle核心服务
II. OcaleXETNSLinstener —> Oracle 接受外部访问的服务
-
Oracle常用的客户端
① Sql-Plus
两种方式:
a. 菜单 -->找到运行sql命令
b. 菜单–> 搜索框中输入cmd --> sqlplushr
② iSql-Plus
a. 启动:浏览器访问:http://localhost:8080/apex
b. 登录:用户名和密码(管理员)
c. 解锁 hr 账户 :
管理–>数据库用户–>管理用户–>HR解锁
d. 重新登录:用户名hr + 密码
③ Sql-develeper(第三方)
登录输入以下信息:
a. 用户名
b. 密码
c. 数据库:XE(oracle便携版默认实例名) ORCL(企业版)
d. 连接为:用户身份类型(Normal/SYSDBA/SYSOPER)
超级管理员:sys system 拥有数据库所有权限
普通用户:hr 权限有限
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YbinZB8Q-1588999837930)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1573806840812.png)]](https://img-blog.csdnimg.cn/20200509125711787.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0phdmFfbG92ZXJfenBhcms=,size_16,color_FFFFFF,t_70)
四、SQL
- SQL:Structure Query Language ,结构化查询语言
- 作用:操作(查询、修改)数据库中某个用户下表中的数据
- 场景:HR用户下的员工表(employees
- 学习思路:人工操作 Excel 表格 ------> SQL书写
五、基本查询
-
语法结构: select 列名,列名,列名 from 表名;
关键词:
from : 明确数据来源的表
select:选择数据获取的列
-
查询部分列
–查询员工表中所有员工的 工号,姓名,薪资信息
–步骤:a. 确定数据来源的表 : from employees
b. 选择要获取的数据列:select 列名,列名
–sql: select employee_id,first_name,salary from employees;
-
查询所有列
–查询员工表中 所有员工的所有信息。
方式一:
- select employee_id,first_name,last_name,email,phone_number, manager_id,salary,job_id, department_id from employees;
方式二:
select * from employees;
注意:实际开发应用不建议使用 *
- 不会总是查询所有信息,用 * 查询效率低
- 开发角度,方式一的可读性较好
-
查询结果的列起别名[查询结果显示的列起名字]
语法:select 列名1 as 别名 , 列名2 as from 表名;
案例:查询员工表中所有员工的工号,名字,薪资信息,显示查询结果
select employee_id as 工号,first_name as 名字,salary as 薪资 from employees;
注意:a. 别名可以是中文或英文,可以包含空格,如果有空格则必须使用""(双引号) 引起来
b. as可以省略
-
查询结果的拼接 || (相当于 Java 中的 + )
案例:查询员工的工号,姓名(名+姓),薪资。
select employee_id as 工号,first_name|| last_name as 姓名,salary as 薪资 from employees;
案例:查询员工的工号,姓名(名+姓),薪资。(要求:名和姓之间有空格)
select employee_id as 工号,first_name|| ’ ’ || last_name as 姓名,salary as 薪资 from employees;
注意:在SQL中,字符串常量用 ‘’ (单引号)引起来。
-
查询结果做算数运算:+ - *
案例:查询员工的工号,姓名,年薪。
select employee_id ,first_name|| ’ ’ || last_name as 姓名,salary*12 as 年薪 from employees;
六、去重
-
场景:查询结果存在重复数据
语法:select distinct 列名 from 表名
案例:查询员工表中的部门id。
select distinct department_id from employees;
七、排序
-
关键字:order by 列名1 asc|desc , 列名2 asc|desc
注意 :asc 升序 desc 降序
语法:select … from … order by 排序所有依据的字段 asc|desc
案例1:查询员工工号,名字,薪资,并按照工资的降序排序进行展示。
select employee_id,first_name,salary from employees order by salary desc
案例2:查询工号,名字,工资,先按工资从大到小排列,工资相同时再按照工号从 小到大排列。
select employee_id,first_name,salary from employees order by salary desc,employee_id asc;
八、条件查询
-
语法:select … from … where 过滤条件
作用:对每一个查询的数据进行条件判断,将符合条件的存入查询结果。
-
等值查询:=
案例1:查询工资是17000的员工工号,名字,薪资。
select employee_id,first_name,salary from employees where salary = 17000;
案例2:查询姓为 King 的员工信息。
select employee_id,last_name,salary from employees where last_name = ‘King’
注意:
(1) 字符串常量必须用单引号引起来 ‘ ’
(2) 字符串常量严格区分大小写
-
不等值条件查询:!= > >= < <=
案例:查询工资大于10000的员工信息。
select employee_id,last_name,salary from employees where salary > 10000;
-
多条件查询:and or
案例:查询工资在 10000到20000的员工信息。
select employee_id,last_name,salary from employees where salary > 10000 and salary <20000;
-
区间查询
语法:select … from … where 字段 between 起始值 and 终止值
注意:闭区间, 字段 >= 起始值 and 字段 <= 终止值
案例:查询薪资在 10000 到 20000 间的员工,包含工资为10000和20000的员工。
方式一:select employee_id,last_name,salary from employees where salary >= 10000 and salary <= 20000;
方式二:select employee_id,last_name,salary from employees where salary between 10000 and 20000;
注意:在 between 的前面加 not 代表 不在此区间。
-
枚举查询
语法:select … from … where 字段 in (值1,值2,值3);
注意:in 前面添加 not,代表不在列举数据的结果。
案例:查询60、70、80号部门员工的信息。(工号、名字、薪资、部门编号)
方式一:select employee_id,last_name,salary,department_id from employees where department_id = 60 or department_id=70 or department_id= 90;
方式二:select employee_id,last_name,salary,department_id from employees where department_id in(60,70,90);
-
null值
语法:select … from … where 字段名 is null
作用:获取某字段值为null的查询结果
注意:is 后面添加 not,代表此字段不为null的查询结果
案例1:查询员工表中,没有提成的员工信息。
select employee_id,last_name,salary,department_id from employees where commission_pct is null;
案例2:查询部门id不为null的员工信息。
select employee_id,last_name,salary,department_id from employees where commission_pct is null;
-
模糊查询
语法:select … from … where 字段名 like ‘格式字符串’;
注意:格式字符串包含:字符串常量和通配符
通配符:% 代表0~n个任意字符
_代表任意一个字符
案例1:查询员工表中姓以 K 开头的员工信息。(工号、名字、姓、薪资)
select employee_id,first_name,last_name salary from employees where last_name like ‘K%’;
案例2:查询员工表中姓长度为4的员工信息。(工号、名字、姓、薪资)
select employee_id,first_name,last_name salary from employees where last_name like ‘’;
案例3:查询员工表中姓的倒数第3个符号是a的员工信息。
select employee_id,first_name,last_name salary from employees where last_name like ‘%a__’;
案例4:查询员工表中姓长度为8,倒数第三个符号位a的员工信息。
select employee_id,first_name,last_name salary from employees where last_name like ‘___a’;
-
总结:
条件查询 和 排序综合应用语法:
select … from … where 过滤条件 order by 字段名 desc|asc
九、特殊关键词
-
dual:虚表,一行一列的表。
a. 从数据角度,没有意义
b. 维护Oracle的sql语句语法的完整性
-
sysdate:当前系统时间,包含 年、月、日、时、分、秒
案例:显示当前系统时间
select sysdate from dual
注意: iSql-Plus中显示日期格式:日-月-年 (18-11月-19)
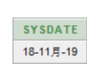
Sql-develeper中显示日期:年/月/日(2019/11/19)

-
systimestamp:[时间戳]当前系统时间,包含 年、月、日、时、分、秒、毫秒
十、函数
- 概念:特定功能的命令。
-
单行函数
特点:作用于表中每行数据,有一行数据则函数就执行一次
常用:
a. to_char(date , ‘格式字符串’):将日期转换为字符串
-
常见的格式字符串:
- 年:yyyy 月:mm 日:dd
- 时:hh24 二十四小时制
- 分:mi 秒:ss 星期:day
-
作用1:把给定的日期类型数据 按照 指定字符串格式进行显示。
-
案例1:查询当前系统时间:2019-11-18 17:59:23
- select to_char(sysdate,‘yyyy-mm-dd hh24:mi:ss’) from dual;
-
案例2:查询员工的员工信息,工号、名字、薪资、入职日期(yyyy-mm-dd)
- select employee_id,first_name,salary, to_char(hire_date,‘yyyy-mm-dd’) from employees;
-
-
作用2:获取日期数据的各个部分,例如:年、月等
-
案例1:显示员工入职的年份。
-
select employee_id,first_name,salary,to_char(hire_date,‘yyyy’) from employees;
-
案例2:查询1987年上半年入职的员工信息。
- select * from employees where to_char(hire_date,‘yyyy’)=‘1997’ and to_char(hire_date,‘mm’)<=6;
-
-
b. to_date(‘日期字符串’,‘格式字符串’) :将字符串转换为日期
-
常见日期格式:
- 年:yyyy 月:mm 日:dd
- 时:hh24 二十四小时制
- 分:mi 秒:ss 星期:day
-
案例1:将 ‘2020-10-10’ 转换为日期展示。
- select to_date(‘2020-10-10’,‘yyyy-mm-dd’) from dual;
-
案例2:查看 ‘2020-10-01’ 号是星期几。
- 思路:字符串类型日期 —>to_date()—>日期类型数据 —>to_char()–>获取星期部分
- select to_char(to_date(‘2020-10-01’,‘yyyy-mm-dd’),‘day’) from dual;
-
扩展:两个日期类型的数据可以直接进行 + - (加减)运算,默认以天为单位。
- 案例1:查询员工表中所有员工入职的天数。
- select employee_id,salary,hire_date,salary,sysdate-hire_date from employees;
- 案例2:查询自己出生的天数。
- 案例1:查询员工表中所有员工入职的天数。
-
-
组函数
特点:作用在表中的一组数据,有一组数据则函数执行一次。
常见组函数:
- max(字段名) : 该字段值中的最大值
- min(字段名):最小值
- sum(字段名):求和
- avg(字段名):平均值
- select max(salary) from employees;
select min(salary) from employees;
select sum(salary) from employees;
select avg(salary) from employees;
- select max(salary) from employees;
注意:以上4个组函数,计算时会忽略null值。
-
count(列名):对该字段非null值计数、统计。
- 统计员工表中员工的数量。
- select count(employee_id) from employees;
-
count(*):统计查询结果的行数
- 统计员工表中1997年入职的员工人数。
- select count(*) from employees where to_char(hire_date,‘yyyy’) = 1997;
总结
SQL语法结构:select 列名 from 表名 where 过滤条件 order by 列名 asc|desc
关键词的作用:
- from : 确定数据来源的表
- where:对数据过滤,保留满足条件的数据
- select:选择要展示列或者处理后的信息
- order by:对满足where条件之后,且select关键词选择完毕列之后的内容,
- 按照字段进行排序展示。
SQL执行的顺序:
from --> where —> select —> order by
十一、分组
-
语法:select … from … where … group by 字段名1,字段名2 order by …
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KK1oZvqG-1588999837933)(E:\02_第二阶段\备课\oracle\1574131316072.png)]](https://img-blog.csdnimg.cn/20200509130018848.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0phdmFfbG92ZXJfenBhcms=,size_16,color_FFFFFF,t_70)
-
案例1:查询各个部门的最高薪资。
分析:
- 确定分组依据是部门编号:group by department_id
--> 部门号相同归为一组,有几个不同的部门编号,就会被分为几个组
- 每组应用组函数:max() 最高工资
- select max(salary) from employees group by department_id;
案例2:统计 各个岗位的人数。
分析:
-
确定分组依据是:岗位编号 group by job_id
-
每组应用组函数:count(*) 统计
- select count(*) from employees group by job_id;
案例3:统计各个部门各岗位的平均工资。
- select department_id, job_id, avg(salary) from employees
group by department_id, job_id
案例4:统计1997年各个月份入职的员工人数。
分析:
-
确定分组依据:月份 group by to_char(hire_date,‘mm’)
-
每组应用组函数:count(*) 统计
-
select count(*) from employees
where to_char(hire_date,‘yyyy’)=1997
group by to_char(hire_date,‘mm’);
-
-
注意事项:
-
(1) 只有group by 后出现的字段,才能出现在select中
(2) group by后没有出现的字段,配合组函数后,也可以出现在select中
(3) group by 出现的函数,在select中必须使用完全相同的函数,包括参数
-
SQL执行顺序:
from:确定表
where:对数据进行条件过滤操作 [筛选出符合where条件的数据]
group by:对满足where条件之后的数据进行分组 操作 [数据变成组数据]
select :选择要展示的信息
order by:排序
十二、分组过滤
-
作用:对分组之后的数据进行过滤。
语法:select … from … where … group by … having 组数据过滤条件 order by …
-
案例1:统计平均工资超过 8000的部门id 和 平均工资。
错误的写法:where中不能使用组函数
-
select department_id, avg(salary) from employees
where avg(salary)>8000 group by department_id
正确的写法:应用 having 对分组后的数据进行过滤
-
select department_id, avg(salary) from employees
group by department_id having avg(salary)>8000;
案例2:统计部门80、90的总工资及部门id。
思路1:
-
分组:group by department_id
-
分组后过滤:having department_id in(80 , 90)
-
对满足having过滤的组,组函数统计:sum(salary)
-
select department_id,avg(salary) from employees
group by department_id having department_id in(80,90);
-
思路2:
- 使用where关键字,对原表数据进行过滤操作:
where department_id in (80,90)
-
根据部门id进行分组:group by department_id
-
对每个组使用组函数:sum(salary)
结论:
- where是 在分组之前对数据进行过滤,效率相对较高
- having是在分组之后对数据进行过滤,效率相对较低
- 如果过滤条件既可以使用having,也可以使用where,则 优先使用where
SQL的结构 及执行顺序总结
语法:select … from … where … group by … having 组数据过滤条件 order by …
执行顺序:
- from:确定表
- where:对数据进行条件过滤操作 [筛选出符合where条件的数据]
- group by:对满足where条件之后的数据进行分组 操作 [数据变成组数据]
- having :对分组之后的数据进行过滤
- select :选择要展示的信息
- order by:排序
-