进程同步
前言
在前面我提到过进程可以是独立进程或者协作进程,当进程是协作进程时。共享数据的并发访问可能会产生数据的不一致。这一章同样也是极其重要的一章。
背景(进程为什么要同步?)
还是以前的消费者–生产者问题,采用共享内存方案。代码如下:
// 生产者
while (true) {
/* produce an item and put in nextProduced */
while (count == BUFFER_SIZE)
; // do nothing
buffer [in] = nextProduced;
in = (in + 1) % BUFFER_SIZE;
count++;
}
// 消费者
while (true) {
while (count == 0)
; // do nothing
nextConsumed = buffer[out];
out = (out + 1) % BUFFER_SIZE;
count--;
/* consume the item in nextConsumed
}
在可能的情况下,生产者和消费者对counter进行操作的寄存器为同一寄存器。假设count = 5,同时让生产者执行count++,消费者执行count–。正确的结果为count = 5,但实际上,count可能的结果为4,5,6。
count = 4的情况:

发生错误的原因: 因为允许两个进程并发操作变量counter。像这样的情况,即多个进程并发访问和操作同一数据且执行结果与访问发生的特定顺序有关,称为竞争条件(race condition)。
为了避免竞争条件,需要确保一段时间内只有一个进程能操作变量counter。为了实现这种保证,要求进行一定形式的进程同步。
临界区问题
临界区(critical section): 每个进程有一个代码段称为临界区,该区中进程可能改变共同变量、更新一个表、写一个文件等。
临界区问题: 设计一个以便进程协作的协议。每个进程必须请求允许进入临界区。
- 进入区(entry section): 进入区控制访问以确保在任何时间内不超过一个进程得到临界区的访问权限。
- 临界区(critical section): 每个进程有一个代码段称为临界区,该区中进程可能改变共同变量、更新一个表、写一个文件等。
- 退出区(exit section): 退出区确保其它等待进入临界区的进程获得进程已经退出的消息。
临界区问题的解答必须满足的要求
- 互斥(mutual exclusion): 忙则等待。 如果进程P在其临界区内执行,那么其它进程都不能在其临界区执行。
- 前进(progress): 有空让进。如果无进程在临界区执行,若有进程进入应允许进入临界区。
- 有限等待(bounded waiting): 从一个进程做出进入临界区的请求,直到该请求允许为止,其它进程允许进入其临界区的次数有上限。
抢占内核与非抢占内核
非抢占内核: 非抢占内核不允许处于内核模式的进程被抢占。不会产生竞争条件,因为某个时刻只有一个进程处于内核模式。
抢占内核: 允许处于内核模式的进程被抢占,因此需要认真设计才不会产生竞争条件。
临界区问题的解答
在这一部分,我们将要学习多种临界区问题的解决方案。从硬件、软件、信号量、到软件API等一系列技术。
在上操作系统这门课时,这一部分直到考试也还有不懂的地方,我认为大概是操作系统最难理解的一部分了。所以希望能好好整理一遍,真正理解这些解答方法。
学习解答方法前的一些准备
锁的概念: 对于临界区代码,最多只有一个进程在执行。为了避免竞争条件,我们引入锁的概念。以下的算法也全部用到了这个概念。即一个进程在进入临界区之前必须得到锁,在退出临界区时必须释放锁。
原子操作: 一个完整的没有中断的操作,要么全做要么全不做,是一种不可分的操作。
原语: 一段完成一定功能的执行期间不能被中断的程序段。
Peterson算法
Peterson算法是一个经典的基于软件的临界区问题的解答,也是我们学习到的第一个算法
参考我的这一篇博客:Peterson算法
硬件同步
除了基于软件实现的基于软件的临界区问题的解答,我们也可以使用硬件来解决这类问题。
背景: 对于单处理器环境,临界区问题可简单地加以解决,即在修改共享变量是要禁止中断出现。但是在多处理器环境下,这种解决方案不可行。在多处理器上由于要将消息传递给所有处理器,所以禁止中断可能很费时。这种消息传递导致进入每个临界区都会延迟,进而会降低系统效率。
解决方法: 许多现代计算机系统提供了特殊硬件指令以允许能原子地检查和修改字的内容或交换两个字的内容。
由硬件指令实现互斥举例:
在下图中,TestAndSet()可以原子地执行,那么便可利用TestAndSet()实现一个互斥锁。

在左图中,TestAndSet()方法的作用为获得target锁的状态,改为TRUE,并返回锁原来的状态。其实函数结果只有两种情况:
- 入参target为true,改为true,返回true。
- 入参target为false,改为true,返回true。
在右图中,可实现进程中的互斥锁。lock为共享变量,初始化为false。在while中,TestAndSet()方法不断循环。如果lock一直为true,则while一直循环。直到有其它进程从临界区出来之后释放lock,在一瞬间,lock = false,TestAndSet()将lock改为true,并返回false,进程跳出while,进入临界区。此时lock = true,其它进程不可能再进入临界区,满足了互斥性要求。直到进程在临界区执行完毕并将lock改为false。
再看另一种互斥锁:

在左图中,Swap()不断交换a和b的值,这个原理和上一个十分相似。
看右图中的在进程中的具体实现,假设进程 P 1 P_1 P1想要进入临界区,但有其它进程在临界区,所以lock锁为true。进程 P 1 P_1 P1不断执行while循环,不断交换lock和key的值,即两个true不断交换。当其它进程释放锁lock的时候,while循环执行Swap()交换lock和key的值,式key = false,lock = true。跳出循环,并上锁。进程在临界区执行完毕,释放锁。
信号量
信号量用法
在看信号量时,有一个困扰我的问题。如果Peterson是利用软件实现的,硬件同步是利用特定硬件指令实现的。那信号量不也是软件吗。“基于硬件的临界区问题的解决方案,对于应用程序员而言,使用比较复杂。为了解决这个困难,可以使用称为信号量(semaphore)的同步工具。”
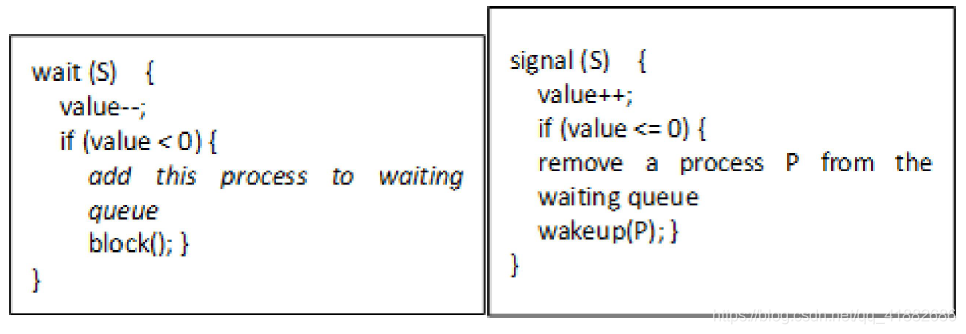
信号量的属性: 信号量S是一个整数变量,除了初始化外,它只能通过两个标准原子操作wait()和signal()来访问。这些操作原来被称为P和V。
下图为最基础的一种wait()与signal()的实现方式:

信号量的分类: 通常操作系统区分计数信号量与二进制信号量。计数信号量的值域不受限制,而二进制信号量的值只能为0或1。在有些系统中,将二进制信号量称为互斥锁。
基本的互斥实现:
do{
waiting(mutex);
//临界区
signal(mutex);
// 剩余区
}while(TRUE)
信号量实现
忙等待(busy waiting): 这是上方定义的信号量的缺点之一。当一个进程位于其临界区内时,任何其它试图进入其临界区的进程都必须在其进入代码中连续的循环。这样会使等待的进程一直占用CPU,浪费了CPU时钟,因为这本来可有效地位其它进程所使用。忙等待也叫做自旋锁。
忙等待的优势: 不需要进行上下文切换,减少了系统开销。
解决忙等待: 修改wait()和signal()的定义。使进程不是忙等而是阻塞自己。阻塞操作将一个进程放入到与信号量相关的等待队列中,并将该进程的状态切换成等待状态。接着,控制转到CPU调度程序,以选择另一个进程来执行。
唤醒进程: 进程的重新执行是通过wakeup()来实现的。进程的阻塞则通过block()实现。
等待队列: 等待队列可以利用进程控制块PCB中的一个链接域来加以轻松实现。信号量的正确使用并不依赖于信号量链表的特定排队机制。
死锁与饥饿
死锁: 具有等待队列的信号量的实现可能导致这样的情况:两个或多个进程无限地等待一个事件,而该事件只能由这些等待进程之一来产生。

在上图中,如果P1和P0同时执行,就会导致死锁。
饥饿: 即无限期阻塞
经典同步问题(信号量解决)
1. 有限缓冲问题(bounded-buffer problem)
生产者-消费者的有限缓冲问题。
信号量解决方案: 假定缓冲池有n个缓冲项,每个缓冲项能存一个数据项。
- 信号量mutex 提供了对缓冲池访问的互斥要求,初始化mutex=1。
- 信号量empty表示空缓冲项的个数,初始化empty = n。
- 信号量full表示满缓冲项的个数,初始化full = 0。

2. 读者-写者问题
一个数据库可以为多个并发进程所共享。对于一些数据,有的进程只需要读数据库,而其它进程可能需要更新和写数据库。需要读的进程称为读者,需要写的进程称为写者。
对于共享数据,如果有多个读者同时访问,那么不会出现什么问题。但是,如果有写者和其它线程同时访问共享对象,很可能导致混乱。
为了确保不会导致这样的混乱,要求写者对共享数据库有排他的访问。这一问题称为读者-写者问题。
第一读者写者问题与第二读者写者问题
第一读者写者问题: 要求没有读者需要保持等待除非有一个写者已获得允许以使用共享数据。
第二读者写者问题: 如果一个写者等待访问对象,那么不会有新的读者开始读操作。
第一读者写者问题的解答
- 信号量mutex 确保在更新readcount时的互斥,初始化mutex = 1。
- 信号量wrt供写者作为互斥信号量,为读者和写者进程所共用,初始化wrt = 1。
- 信号量readcount用来表示有多少个读者,初始化readcount = 0。

这个解决方案的逻辑是读者优先,所以可能会导致写者饥饿。写者进程逻辑简单一些,只要获得wrt锁,就可以运行,执行完之后释放锁。读者这边,只要是有段readcount变化的区域都要加上mutex互斥锁,避免多个读者引起的混乱。当有读者进程时,读者数量加一,并拿走写者的wrt互斥锁,如果有读者进程不断的进来,readcount便会一直加。只要读者不全部执行完毕,就不会释放wrt锁。举个例子,如果有十个读者进程,在第一个读者进程执行的时候,拿走wrt锁。之后剩余的9个进程都执行,readcount = 10。接着每有一个读者进程执行完毕,readcount–。当readcount = 0时,释放wrt锁。写者进程才能进行。如果有更多的读者进程,那么写者等不到锁,就会饥饿。
3. 哲学家进餐问题
这个是一个非常有意思的问题。光看名字就知道了。
问题: 假设有5个哲学家,他们一生用来思考和吃饭。这些哲学家共用一个圆桌,在桌子中央有一碗米饭,在桌子上放有5支筷子。他们会感到饥饿,并试图拿起与他相邻的两只筷子。当一个饥饿的哲学家有两只筷子时,他就能吃饭了。吃完后,他会把两支筷子,并继续开始思考。

一种容易想到的会导致死锁的方案: 哲学家依次拿起相邻的两支筷子,当都拿起时,就可以吃饭了。

可行的解决方法:
- 最多只允许4个哲学家同时坐在桌子上。
- 只有两个筷子同时可用时才允许一个哲学家拿起它们
- 给哲学家编号,奇数哲学家先拿起左边再拿起右边,偶数哲学家先拿起右边再拿起左边。
- 使用管程(monitor)(马上会提到)
管程
为什么要使用管程?
虽然信号量提供了一种方便且有效的机制来处理进程同步,但是使用不正确仍然会导致一些时序错误,比如无意的编程错误或者不合作的程序员有意为之。
比如像这种:
do{
signal(mutex);
//临界区
signal(mutex);
// 剩余区
}while(TRUE)
或者:
do{
wait(mutex);
//临界区
wait(mutex);
// 剩余区
}while(TRUE)
为了尽量减少这种错误,我们使用管程。
管程的使用
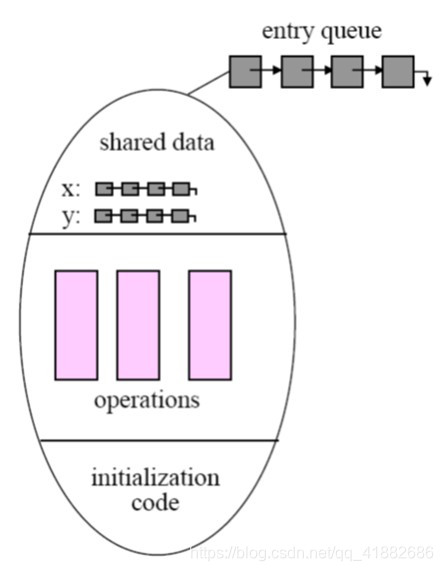
管程: 管程是一种高层次的抽象构造,可以提供一种便捷且有效的进程同步机制。管程类型提供了一组由程序员定义的、在管程内互斥的操作。管程中包括一组变量的声明核对这些变量操作的子程序和函数的实现(可以近似理解为管程是一个高级语言中的类的定义,与一般类不同的是,管程有条件变量可用于控制进程之间的同步)。管程的结构可以确保一次只能有一个进程在管程内活动。
monitor monitor-name
{
// shared variable declarations
procedure P1 (…) {
…. }
…
procedure Pn (…) {
……}
Initialization code ( ….) {
… }
…
}
管程的进程重启
- 一个简单解决方法是使用FCFS顺序。
- 条件构造: 为进程加一个整数优先值。当执行x.singal(),所有的等待的进程的最小优先值会被重新启动。
管程的一些问题
管程其实还是不能解决一些时序错误,更多的是提供了一中不易犯错的规范。
哲学家问题的管程解决
对于哲学家 d p i dp_i dpi,可用以下操作来申请吃饭
dp.pickup(i);
//eating
dp.putdown(i);
管程的具体实现:
monitor DP
{
enum {
THINKING; HUNGRY, EATING} state [5] ;
condition self [5];
void pickup (int i) {
state[i] = HUNGRY;
test(i);
if (state[i] != EATING)
self [i].wait;
}
void putdown (int i) {
state[i] = THINKING;
// test left and right neighbors
test((i + 4) % 5);
test((i + 1) % 5);
}
void test (int i) {
if ( (state[(i + 4) % 5] != EATING) &&
(state[i] == HUNGRY) &&
(state[(i + 1) % 5] != EATING) ) {
state[i] = EATING ;
self[i].signal () ;
}
}
initialization_code() {
for (int i = 0; i < 5; i++)
state[i] = THINKING;
}
}
并发原子操作
串行化能力
在多个事务同时执行的情况,因为每个事务是原子性的,所以的事务的并发执行必须相当于这些事务按任意顺序任意执行,即串行化。
串行调度: 每个事务原子地执行的调度叫做串行调度。
下图为串行调度, T 1 T_1 T1紧紧跟在 T 0 T_0 T0之后

非串行调度(并行调度): 如果允许两个及以上事务重叠执行,那么这样的调度就不再是串行的。非串行调度并不意味着其结果不正确。
下图为非串行调度:
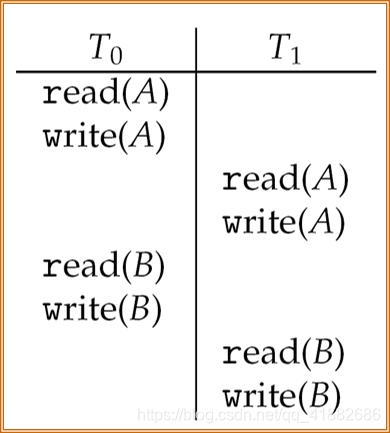
冲突可串行化: 上图非串行调度中 T 0 T_0 T0的write(A)和 T 1 T_1 T1的read(A)是冲突操作。
冲突操作(conflicting operation): 在非串行调度中,对于两个事务,执行顺序为 O i O_i Oi和 O j O_j Oj,如果访问相同的数据项且操作中至少有一个write操作,那么就说 O i O_i Oi和 O j O_j Oj冲突。
冲突可串行化: 如果上图中的非串行调度可以通过一系列非冲突操作转化为串行调度,那么就说冲突可串行化。
加锁协议
确保串行化能力的一种方法是为每个数据项关联一个锁,并要求每个事务遵循加锁协议。
共享锁: 如果事务 T i T_i Ti获得了数据项Q的共享模式锁(记为S),那么 T i T_i Ti可读取这一项,但不能修改它。
排他锁: 如果事务 T i T_i Ti获得了数据项Q的排他模式锁(记为X),那么 T i T_i Ti可读取这一项,也能修改它。
两段加锁协议: 这个协议要求每个事务按两个阶段来发出加锁和放锁需求。
- 增长阶段: 事务可获得锁,但不能释放锁。
- 收缩阶段: 事务可释放锁,但不能获得锁。
两阶段加锁协议保证了冲突串行化,但它不能确保不会死锁。
基于时间戳协议
对于上述的加锁协议,每对冲突事务的顺序是由执行时它们所请求的第一次不兼容的锁确定的。
确定串行化顺序的另一方法是事先在事务之前选择一个顺序。这样做的最为常用的方法是使用时间戳排序方案。
实现:
- 对于系统中的每个事务 T i T_i Ti,都为之关联一个唯一固定的时间戳,并记为TS( T i T_i Ti)。
- 这个时间戳在事务 T i T_i Ti开始执行前由系统赋予。
- 可以采用系统时钟或逻辑计数器作为时间戳。
- 如果TS( T i T_i Ti)<TS( T j T_j Tj),那么系统必须确保所产生的调度相当于事务 T i T_i Ti在事务 T j T_j Tj之前的串行化调度。
两阶段加锁协议保证了冲突串行化,且不会死锁。
有的调度在两阶段加锁有可能,而在时间戳下却不可能,反之亦然。