1. 什么是DStream
-
Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark算子操作后的结果数据流。
-
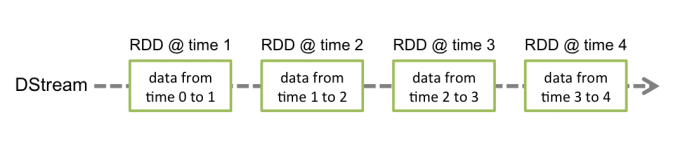
内部实现上,DStream是一系列连续的RDD来表示。每个RDD含有一段时间间隔内的数据
-
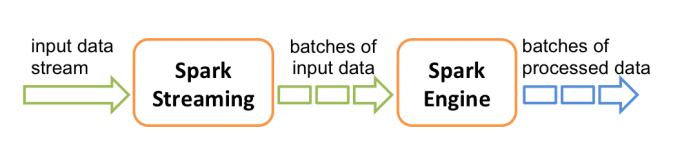
工作流程图如下: 接受到实时数据后,给数据分批次,然后传给Spark Engine处理最后生成该批次的结果
2. DStream相关的算子汇总
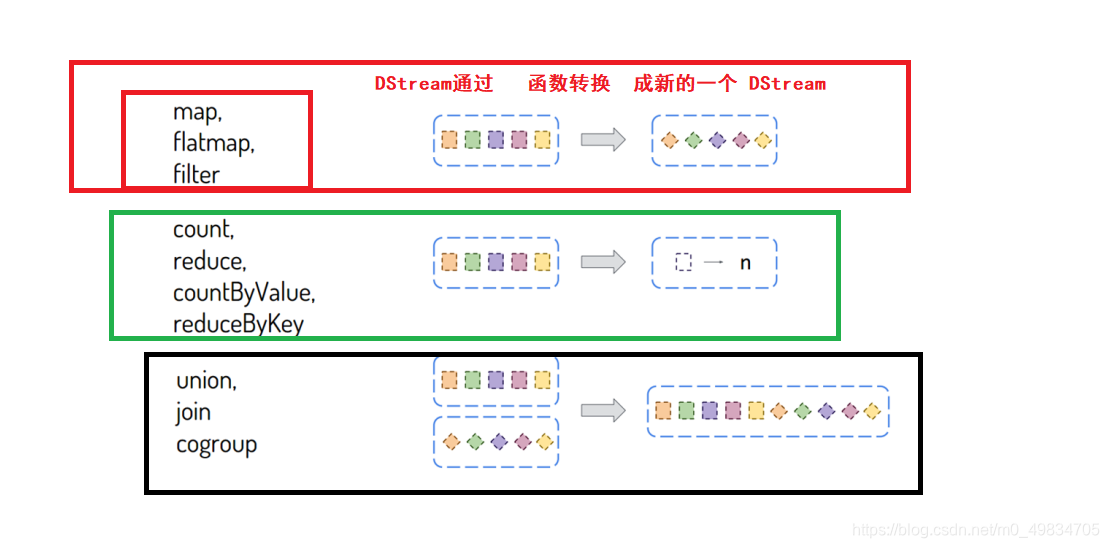
- 转换函数【Transformation转换算子】: 将一个DStream转换为另外一个DStream
- 注意:
- 1-SparkStreaming的Transformation算子比较有限,但是有的时候仍然需要使用
- 比如,需要对wordcount的结果进行排序,这里没有sortBy或sortByKey的算子
- 所以,借助于tranform的方法将DStream的数据转化成RDD进行操作

- 输出函数【Output Operations行动算子】: 将一个DStream输出到外部存储系统
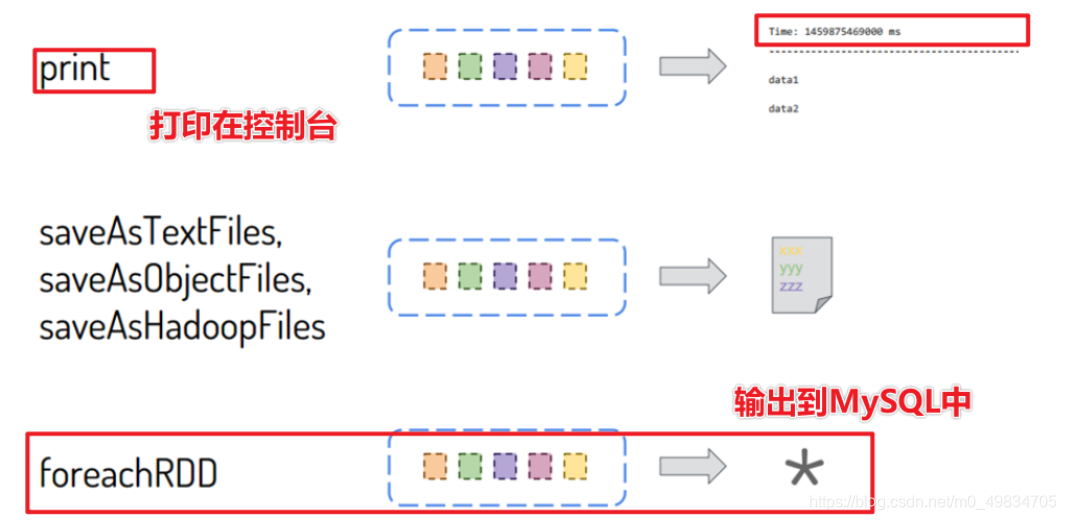
在SparkStreaming企业实际开发中,建议:能对RDD操作的就不要对DStream操作,当调用DStream中某个函数在RDD中也存在,使用针对RDD操作。
3. StreamingContext对象
- 1)、SparkCore
数据结构:RDD
SparkContext:上下文实例对象 - 2)、SparkSQL
数据结构:Dataset/DataFrame = RDD + Schema
SparkSession:会话实例对象, 在Spark 1.x中SQLContext/HiveContext - 3)、SparkStreaming
数据结构:DStream = Seq[RDD]
StreamingContext:流式上下文实例对象, 底层还是SparkContext
参数:划分流式数据时间间隔BatchInterval:1s,5s(演示)
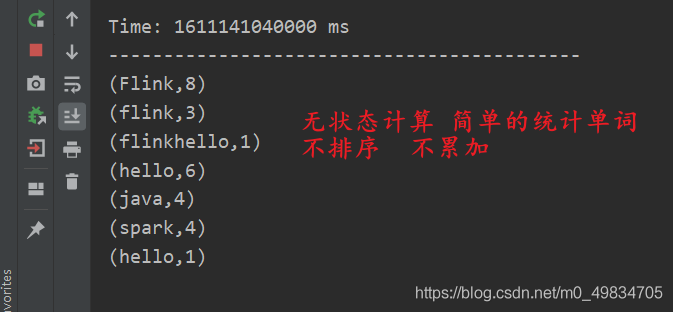
4. DStream算子实现wordcount实时计算案例
模拟TCP socket实现简单的实时计算wordcount
import org.apache.spark.streaming.dstream.{
DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{
Seconds, StreamingContext}
import org.apache.spark.{
SparkConf, SparkContext}
/**
* @author liu a fu
* @date 2021/1/20 0020
* @version 1.0
* @DESC 第一个SparkStreaming wordcount案例 不会累加(称之为无状态计算)
*
* 1-首先声明StreamingContext申请资源,进入调用sparkContext
* 2-这里从socket接受数据,从node1节点下安装nc服务,使用nc -lk 9999端口发送数据**
* 3-将接受到的数据进行Tranformation转换
* 4-使用OutPutOpration操作输出结果
* 5-开启start,streamingcontext.start开启接受数据
* 6-指导StreamingContext.awaitTermination停止
* 7-StreamingContext.stop
*/
object _01StreamingCompution {
def main(args: Array[String]): Unit = {
//1-首先声明StreamingContext申请资源,进入调用sparkContext
val conf: SparkConf = new SparkConf()
.setMaster("local[8]")
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(5)) //每经过5秒处理一次数据
sc.setLogLevel("WARN")
//2-这里从socket接受数据,从node1节点下安装nc服务,使用nc -lk 9999端口发送数据
val receiveDS: ReceiverInputDStream[String] = ssc.socketTextStream("node1", 9999) //指定主机和端口
//3-将接受到的数据进行Tranformation转换
val resultDS: DStream[(String, Int)] = receiveDS
.flatMap(_.split("\\s+"))
.map((_, 1))
.reduceByKey(_ + _)
//4-使用OutPutOpration操作输出结果-----------print属于类似于action算子的
resultDS.print()
//5-开启start,streamingcontext.start开启接受数据
ssc.start() //Start the execution of the streams.
//6-指导StreamingContext.awaitTermination停止,有任何的异常都会触发停止
ssc.awaitTermination()
//7-StreamingContext.stop
ssc.stop()
}
}
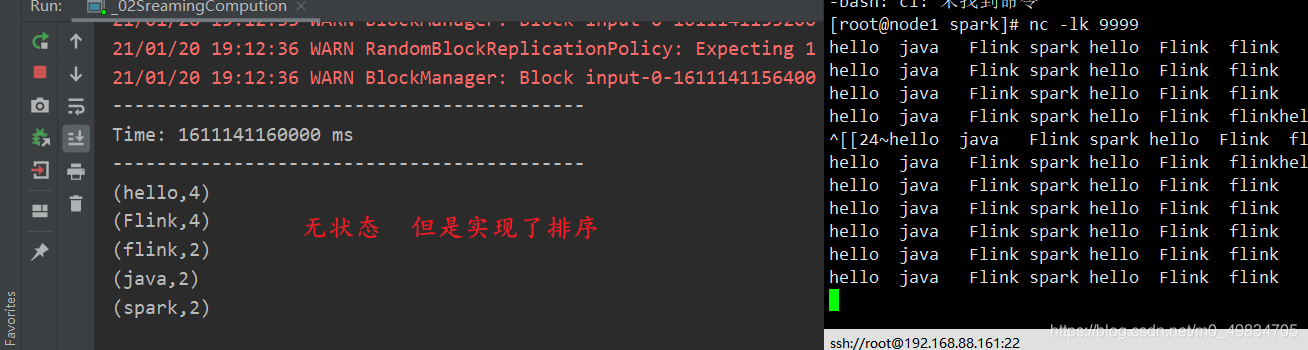
模拟TCP 实现排序(transform转换算子 + sortBy实现)
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{
DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{
Seconds, StreamingContext}
import org.apache.spark.{
SparkConf, SparkContext}
/**
* @author liu a fu
* @date 2021/1/20 0020
* @version 1.0
* @DESC 实现wordcount统计后的排序输出
*/
object _02SreamingCompution {
def main(args: Array[String]): Unit = {
//1-首先声明StreamingContext申请资源,进入调用sparkContext
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getSimpleName.stripSuffix("$")).setMaster("local[3]")
val sc = new SparkContext(conf)
val scc = new StreamingContext(sc, Seconds(5))
sc.setLogLevel("WARN")
//2-这里从socket接收数据
val reviceDS: ReceiverInputDStream[String] = scc.socketTextStream("node1", 9999)
//3-将接收的数据进行Tranformation转换
val resultDS: DStream[(String, Int)] = reviceDS
.flatMap(_.split("\\s+"))
.map((_, 1))
.reduceByKey(_ + _)
//实现排序操作
val output: DStream[(String, Int)] = resultDS.transform(iter => {
val valueRDD: RDD[(String, Int)] = iter.sortBy(_._2, false) //按照第二个进行排序 value
valueRDD
})
//4-使用OutPutOpration操作输出结果-----------print属于类似于action算子的
output.print()
//5-开启start,streamingcontext.start开启接受数据
scc.start()
scc.awaitTermination()
scc.stop()
}
}
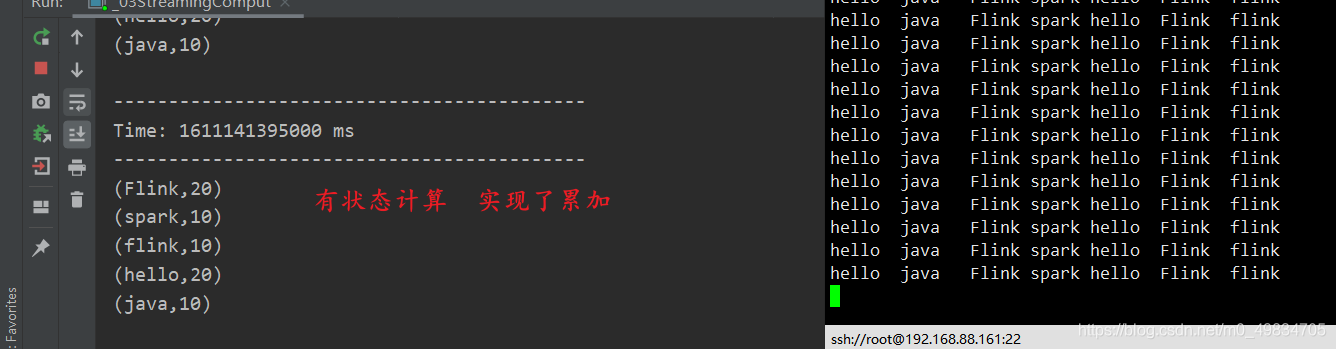
TCP 实现有状态 累加(updateStateByKey算子 定义方法)
import org.apache.spark.streaming.dstream.{
DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{
Seconds, StreamingContext}
import org.apache.spark.{
SparkConf, SparkContext}
/**
* @author liu a fu
* @date 2021/1/20 0020
* @version 1.0
* @DESC SparkStreaming wordcount案例 会累加(称之为有状态计算)
*/
object _03StreamingComput {
/**
* 这里自己定义的一个方法用于累加 和 判断历史值是否存在
* @param currentValue 这里是当前的值,需要是用sum累加
* @param historyValue 这里是历史的值,判断历史的值是否存在,如果存在直接使用,如果不存在赋值为0
* @return
*/
def updateFunc(currentValue:Seq[Int],historyValue:Option[Int]):Option[Int] = {
val addSum = currentValue.sum + historyValue.getOrElse(0)
Option(addSum)
}
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getSimpleName.stripSuffix("$")).setMaster("local[5]")
val sc = new SparkContext(conf)
val scc = new StreamingContext(sc, Seconds(5))
sc.setLogLevel("WARN")
scc.checkpoint("data/checkpoint/check001")
2-这里从socket接受数据,从node1节点下安装nc服务,使用nc -lk 9999端口发送数据
val reviceDS: ReceiverInputDStream[String] = scc.socketTextStream("node1", 9999)
//3-将接受到的数据进行Tranformation转换
val resultDS: DStream[(String, Int)] = reviceDS
.flatMap(_.split("\\s+"))
.map((_, 1))
.updateStateByKey(updateFunc)
//4-使用OutPutOpration操作输出结果-----------print属于类似于action算子的
resultDS.print()
//5-开启start,streamingcontext.start开启接受数据
scc.start() //Start the execution of the streams.
//6-指导StreamingContext.awaitTermination停止,有任何的异常都会触发停止
scc.awaitTermination()
scc.stop()
}
}
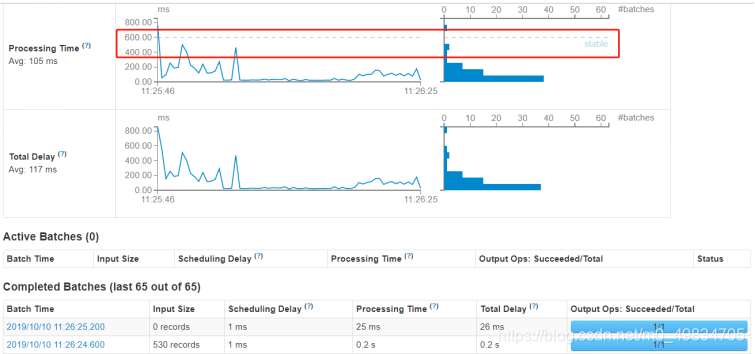
5. 应用的监控界面
运行上述词频统计案例,登录到WEB UI监控页面:http://localhost:4040,查看相关监控信息。
扫描二维码关注公众号,回复:
12166712 查看本文章

-
其一、Streaming流式应用概要信息
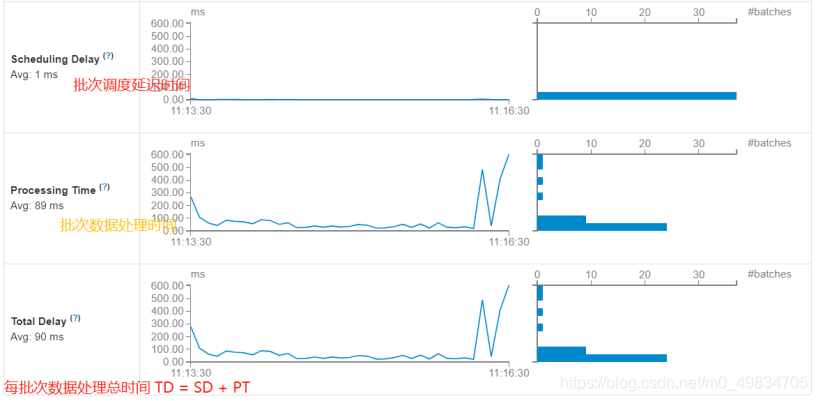
每批次Batch数据处理总时间TD = 批次调度延迟时间SD + 批次数据处理时间PT。

-
性能衡量标准
SparkStreaming实时处理数据性能标准:
每批次数据处理时间TD <= BatchInterval每批次时间间隔