前言
上篇文章末尾,笔者聊到了一种叫做分层元数据管理模式。它主张的思想是将元数据进行分级对待,比如Cache+Persist层2种,cache拿来用于热点数据的访问,而persist层即持久层则存储那些冷的访问不频繁的数据,以此达到元数据的强扩展性和一个较好的访问性能。当今存储系统Alluxio就是使用了这种分层级对待的元数据管理模式。本文我们就来简单聊聊Alluxio的tier layer的元数据管理。
Alluxio内部元数据管理架构
相比较于将元数据全部load到memory然后以此提高快速访问能力的元数据管理方式,Alluxio在这点上做了优化改进,只cache那些active的数据,这是其内部元数据管理的一大特点。对于那些近期没有访问过的冷数据,则保存在本地的rocksdb内。
在Alluxio中,有专门的定义来定义上述元数据的存储,在内存中cache active数据的存储层,我们叫做cache store,底层rocksdb层则叫做baking store。
Alluxio就是基于上面提到的2层store做数据数据然后对外提供数据访问能力,架构图如下所示:
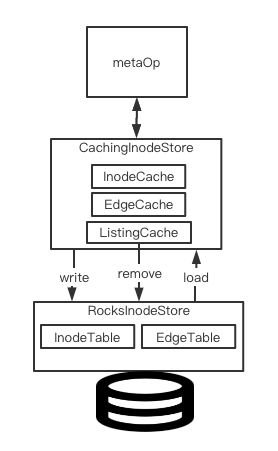
本文笔者这里想重点聊的点在于Cache store如何和上面Rocks store(Baking store)进行数据交互的。
Alluxio的支持异步写出功能的自定义Cache实现
在Cache store层,它需要做以下2件事情来保证元数据的正常更新:
- 及时将那些访问频率降低的热点数据移除并写出到baking store里去。
- 有新的数据访问来时,将这些数据从baking store读出来并加载到cache里去。
在上面两点中,毫无疑问,第一点是Alluxio具体要实现。那么Alluxio采用的是什么办法呢?用现有成熟Cache工具,guava cache?Guava cache自带expireAfterAccess能很好的满足上述的使用场景。
不过最终Alluxio并没有使用Guava cahce的方案。这点笔者认为主要的一点在于guava cahce不支持异步的entry过期写出功能。Gauva cache在更新过期entry时并没有开启额外线程的方式来做过期entry的处理,而是放在了后面的每次的cache访问操作里顺带做了。那么这里其实会有一个隐患:当cache很久没有被访问过了,然后下一次cache访问发生在已经超过大部分entry的过期时间之后,那么这时候可能会触发大量的cache更新重新加载的行为。此时Guava Cache本身将会消耗掉很多的CPU来做这样的事情,这也势必会影响Cache对外提供数据访问的能力。另外一点,Gauva Cache的entry更新是要带锁的,如果Cache entry更新的缓慢是会block住其它想要访问此entry的thread的。
结论是说,如果我们想要Cache entry能够被及时的移除以及更新,可以自己实现一个thread来触发更新的行为。下面是Guava cache的Git文档对这块的一个说明解释,里面也提到了为什么Guava Cahce为什么不在内部实现启动线程来做cache过期更新的原因:
When Does Cleanup Happen?
Caches built with CacheBuilder do not perform cleanup and evict values "automatically," or instantly after a value expires, or anything of the sort. Instead, it performs small amounts of maintenance during write operations, or during occasional read operations if writes are rare.
The reason for this is as follows: if we wanted to perform Cache maintenance continuously, we would need to create a thread, and its operations would be competing with user operations for shared locks. Additionally, some environments restrict the creation of threads, which would make CacheBuilder unusable in that environment.
Instead, we put the choice in your hands. If your cache is high-throughput, then you don't have to worry about performing cache maintenance to clean up expired entries and the like. If your cache does writes only rarely and you don't want cleanup to block cache reads, you may wish to create your own maintenance thread that calls Cache.cleanUp() at regular intervals.
If you want to schedule regular cache maintenance for a cache which only rarely has writes, just schedule the maintenance using ScheduledExecutorService.
OK,下面我们就来看看Alluxio内部实现的带异步写出outdated entry功能的cache实现。这里我们对着其代码实现做具体阐述。
首先是上面架构图中的CachingInodeStore的定义:
public final class CachingInodeStore implements InodeStore, Closeable {
private static final Logger LOG = LoggerFactory.getLogger(CachingInodeStore.class);
// Backing store用户数据写出持久化的store
private final InodeStore mBackingStore;
private final InodeLockManager mLockManager;
// Cache recently-accessed inodes.
@VisibleForTesting
final InodeCache mInodeCache;
// Cache recently-accessed inode tree edges.
@VisibleForTesting
final EdgeCache mEdgeCache;
@VisibleForTesting
final ListingCache mListingCache;
// Starts true, but becomes permanently false if we ever need to spill metadata to the backing
// store. When true, we can optimize lookups for non-existent inodes because we don't need to
// check the backing store. We can also optimize getChildren by skipping the range query on the
// backing store.
private volatile boolean mBackingStoreEmpty;
...
public CachingInodeStore(InodeStore backingStore, InodeLockManager lockManager) {
mBackingStore = backingStore;
mLockManager = lockManager;
AlluxioConfiguration conf = ServerConfiguration.global();
int maxSize = conf.getInt(PropertyKey.MASTER_METASTORE_INODE_CACHE_MAX_SIZE);
Preconditions.checkState(maxSize > 0,
"Maximum cache size %s must be positive, but is set to %s",
PropertyKey.MASTER_METASTORE_INODE_CACHE_MAX_SIZE.getName(), maxSize);
float highWaterMarkRatio = ConfigurationUtils.checkRatio(conf,
PropertyKey.MASTER_METASTORE_INODE_CACHE_HIGH_WATER_MARK_RATIO);
// 最高水位的计算
int highWaterMark = Math.round(maxSize * highWaterMarkRatio);
float lowWaterMarkRatio = ConfigurationUtils.checkRatio(conf,
PropertyKey.MASTER_METASTORE_INODE_CACHE_LOW_WATER_MARK_RATIO);
Preconditions.checkState(lowWaterMarkRatio <= highWaterMarkRatio,
"low water mark ratio (%s=%s) must not exceed high water mark ratio (%s=%s)",
PropertyKey.MASTER_METASTORE_INODE_CACHE_LOW_WATER_MARK_RATIO.getName(), lowWaterMarkRatio,
PropertyKey.MASTER_METASTORE_INODE_CACHE_HIGH_WATER_MARK_RATIO, highWaterMarkRatio);
// 最低水位的计算
int lowWaterMark = Math.round(maxSize * lowWaterMarkRatio);
mBackingStoreEmpty = true;
CacheConfiguration cacheConf = CacheConfiguration.newBuilder().setMaxSize(maxSize)
.setHighWaterMark(highWaterMark).setLowWaterMark(lowWaterMark)
.setEvictBatchSize(conf.getInt(PropertyKey.MASTER_METASTORE_INODE_CACHE_EVICT_BATCH_SIZE))
.build();
// 将上述cache相关配置值传入cache中
mInodeCache = new InodeCache(cacheConf);
mEdgeCache = new EdgeCache(cacheConf);
mListingCache = new ListingCache(cacheConf);
}
这里我们主要看mInodeCache这个cache,它保存了最近访问过的inode。
class InodeCache extends Cache<Long, MutableInode<?>> {
public InodeCache(CacheConfiguration conf) {
super(conf, "inode-cache", MetricKey.MASTER_INODE_CACHE_SIZE);
}
...
}
我们看到InodeCache底层继承的是Cache<K, V>这个类,我们继续进入这个类的实现,
public abstract class Cache<K, V> implements Closeable {
private static final Logger LOG = LoggerFactory.getLogger(Cache.class);
private final int mMaxSize;
// cache的高水位值,当当前cache entry总数超过此值时,会触发entry的写出
private final int mHighWaterMark;
// cache的低水位值,每次cache写出清理后的entry总数
private final int mLowWaterMark;
// 每次过期写出entry的批量大小
private final int mEvictBatchSize;
private final String mName;
// cache map,为了保证线程安全,使用了ConcurrentHashMap
@VisibleForTesting
final ConcurrentHashMap<K, Entry> mMap;
// TODO(andrew): Support using multiple threads to speed up backing store writes.
// Thread for performing eviction to the backing store.
@VisibleForTesting
// entry移除写出线程
final EvictionThread mEvictionThread;
...
简单而言,Alluxio的Cache类工作的本质模式是一个ConcurrentHashMap+EvictionThread的模式。因为涉及到Map并发操作的情况,所以这里使用了ConcurrentHashMap。然后再根据这里阈值的定义(高低watermark值的设定),进行entry的写出更新。
下面我们直接来看EvictionThread的操作逻辑,
class EvictionThread extends Thread {
@VisibleForTesting
volatile boolean mIsSleeping = true;
// 存储需要被清理出去的cache entry
private final List<Entry> mEvictionCandidates = new ArrayList<>(mEvictBatchSize);
private final List<Entry> mDirtyEvictionCandidates = new ArrayList<>(mEvictBatchSize);
private final Logger mCacheFullLogger = new SamplingLogger(LOG, 10L * Constants.SECOND_MS);
...
@Override
public void run() {
while (!Thread.interrupted()) {
// 如果当前map总entry数未超过高水位置,则线程进行wait等待
while (!overHighWaterMark()) {
synchronized (mEvictionThread) {
if (!overHighWaterMark()) {
try {
mIsSleeping = true;
mEvictionThread.wait();
mIsSleeping = false;
} catch (InterruptedException e) {
return;
}
}
}
}
if (cacheIsFull()) {
mCacheFullLogger.warn(
"Metastore {} cache is full. Consider increasing the cache size or lowering the "
+ "high water mark. size:{} lowWaterMark:{} highWaterMark:{} maxSize:{}",
mName, mMap.size(), mLowWaterMark, mHighWaterMark, mMaxSize);
}
// 如果当前map总entry数超过高水位置,则开始准备进行entry的写出清理,map entry数量清理至低水位置
evictToLowWaterMark();
}
}
}
继续进入evictToLowWaterMark方法,
private void evictToLowWaterMark() {
long evictionStart = System.nanoTime();
// 计算此处entry移除会被移除的数量
int toEvict = mMap.size() - mLowWaterMark;
// 当前移除entry的计数累加值
int evictionCount = 0;
// 进行entry的写出移除
while (evictionCount < toEvict) {
if (!mEvictionHead.hasNext()) {
mEvictionHead = mMap.values().iterator();
}
// 遍历mapentry,进行需要被移除的entry数的收集
fillBatch(toEvict - evictionCount);
// 进行entry的写出清理
evictionCount += evictBatch();
}
if (evictionCount > 0) {
LOG.debug("{}: Evicted {} entries in {}ms", mName, evictionCount,
(System.nanoTime() - evictionStart) / Constants.MS_NANO);
}
}
上面fillBatch的entry数收集过程如下所示,
private void fillBatch(int count) {
// 单次移除entry数的上限值设定
int targetSize = Math.min(count, mEvictBatchSize);
// 当待移除entry未达到目标值时,继续遍历map寻找未被引用的entry
while (mEvictionCandidates.size() < targetSize && mEvictionHead.hasNext()) {
Entry candidate = mEvictionHead.next();
// 如果entry被外界引用,则将其引用值标记为false,下次如果还遍历到此entry,此entry将被收集移除
// 当entry被会访问时,其reference值会被标记为true。
if (candidate.mReferenced) {
candidate.mReferenced = false;
continue;
}
// 如果此entry已经被标记为没有引用,则加入到待移除entry列表内
mEvictionCandidates.add(candidate);
if (candidate.mDirty) {
mDirtyEvictionCandidates.add(candidate);
}
}
}
然后是entry写出操作,
private int evictBatch() {
int evicted = 0;
if (mEvictionCandidates.isEmpty()) {
return evicted;
}
// 进行entry的写出,entry分为两类
// 如果entry值和baking store里保存的是一致的话:则直接从map里进行移除即可
// 如果entry值和baking store对比是发生过更新的,则额外还需要进行flush写出,然后map里再进行移除
flushEntries(mDirtyEvictionCandidates);
for (Entry entry : mEvictionCandidates) {
if (evictIfClean(entry)) {
evicted++;
}
}
mEvictionCandidates.clear();
mDirtyEvictionCandidates.clear();
return evicted;
}
我们可以看到entry移除的过程其实还会被分出两类,这其中取决于此entry值和baking store中持久化保存的值是否一致。
- 第一类,只需从cache map中进行移除
- 第二类,从cache map中进行移除,还需要写出到baking store。
这里是由cache Entry的dirty属性值来确定的,
protected class Entry {
protected K mKey;
// null value means that the key has been removed from the cache, but still needs to be removed
// from the backing store.
@Nullable
protected V mValue;
// Whether the entry is out of sync with the backing store. If mDirty is true, the entry must be
// flushed to the backing store before it can be evicted.
protected volatile boolean mDirty = true;
,,,
evictBatch的flushEntries方法取决于继承子类如何实现baking store的写出。
/**
* Attempts to flush the given entries to the backing store.
*
* The subclass is responsible for setting each candidate's mDirty field to false on success.
*
* @param candidates the candidate entries to flush
*/
protected abstract void flushEntries(List<Entry> candidates)
Map entry的异步写出过期entry过程说完了,我们再来看另一部分内容Entry的访问操作get/put, delete的操作。
这里我们以put操作为例:
/**
* Writes a key/value pair to the cache.
*
* @param key the key
* @param value the value
*/
public void put(K key, V value) {
mMap.compute(key, (k, entry) -> {
// put操作callback接口方法
onPut(key, value);
// 如果是cache已经满了,则直接写出到baking store里
if (entry == null && cacheIsFull()) {
writeToBackingStore(key, value);
return null;
}
if (entry == null || entry.mValue == null) {
onCacheUpdate(key, value);
return new Entry(key, value);
}
// 进行entry的更新
entry.mValue = value;
// 标记entry reference引用值为true,意为近期此entry被访问过,在get,remove方法中,也会更新此属性值为true
entry.mReferenced = true;
// 标记此数据为dirty,意为从baking load此entry值后,此值发生过更新
entry.mDirty = true;
return entry;
});
// 随后通知Eviction线程,判断是否需要进行entry的移除,在get,remove方法中,也会在末尾调用此方法
wakeEvictionThreadIfNecessary();
}
在上面方法的最后一行逻辑,会第一时间激活Eviction线程来做entry的移除操作,这样就不会存在前文说的短期内可能大量entry的写出移除操作了。这点和Guava cache的过期更新策略是不同的。
以上就是本文所讲述的主要内容了,其中大量篇幅介绍的是Alluxio内部Cache功能的实现,更详细逻辑读者朋友们可阅读下文相关类代码的链接进行进一步的学习。
引用
[1].https://github.com/google/guava/wiki/CachesExplained#refresh
[2].https://dzone.com/articles/scalable-metadata-service-in-alluxio-storing-billi
[3].https://dzone.com/articles/store-1-billion-files-in-alluxio-20
[4].https://github.com/Alluxio/alluxio/blob/master/core/server/master/src/main/java/alluxio/master/metastore/caching/CachingInodeStore.java
[5].https://github.com/Alluxio/alluxio/blob/master/core/server/master/src/main/java/alluxio/master/metastore/caching/Cache.java