文章目录
在 Python 中,字符串就是一串字符的组合,它是不可变的、有限字符序列,包括可见字符、不可见字符(如空格符等)和转义字符。Python 通过 str 类型提供大量方法来操作字符串,如字符串的替换、删除、截取、复制、连接、比较、查找、分隔等。本篇博文将详细介绍操作字符串的一般方法。因为字符串在开发过程中,是非常常见的一种数据类型,在爬虫中经常都是对字符串进行操作,包括 URL 拼接、格式化、数据处理(替换、去除空白、截取等),所以读者需要对其常规操作进行熟练掌握,读者将本文收藏当作文档查阅工具使用也可。学习重点如下:
1. 如何定义字符串。
2. 字符串长度的计算和编码。
3. 字符串连接和截取。
4. 字符串查找和替换。
5. 熟悉字符串的其他常规操作。
1. 字符串基础
1.1 定义字符串
在 Python 中,可以使用很多种方式来进行字符串的定义。下面对各种定义方式进行详细地介绍与说明。注意:Python 不支持字符类型,单个字符也算是一个字符串。
(1) 单行字符串
在 Python 中,使用单引号(')和 双引号(")可以定义字符串,注意是成对出现。语法格式如下:
'单行字符串'
"单行字符串"
单引号和双引号常用于表示单行字符串,也可以在字符串中添加换行符(\n)间接定义多行字符串。在使用单引号定义的字符串中,可以直接包含双引号,而不必进行转义,而在使用双引号定义的字符串中,可以直接包含单引号,而不必进行转义。一句话讲:外双内单、外单内双。
示例:定义两个字符串,分别包含单引号和双引号,为了避免使用转义字符,则分别使用单引号和双引号定义字符串。
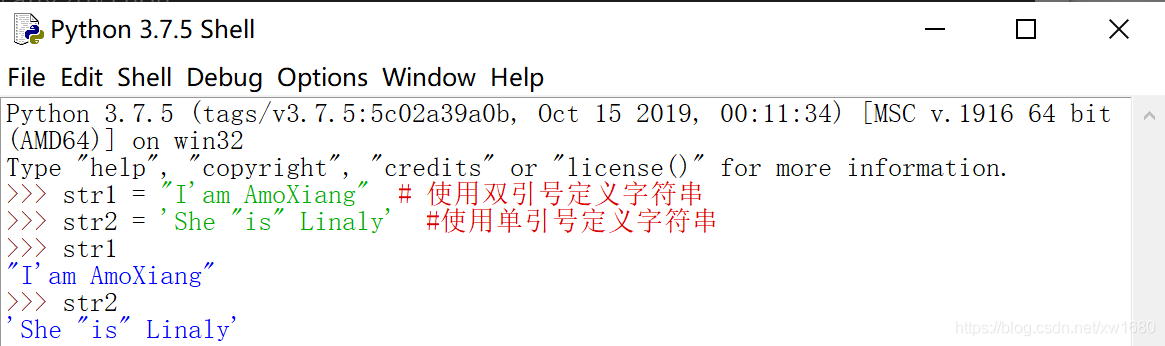
(2) 多行字符串
单引号、双引号定义多行字符串时,需要添加换行符 \n,而三引号不需要添加换行符,语法格式如下:
'''多行
字符串'''
"""多行
字符串"""
同时字符串中可以包含单引号、双引号、换行符、制表符,以及其他特殊字符,对于这些特殊字符不需要使用反斜杠(\)进行转义。另外,三引号中还可以包含注释信息。
三引号可以帮助开发人员从引号和转义字符的泥潭里面解脱出来,确保字符串的原始格式。但是平时我们使用得最多的还是单行字符串,三引号一般用于函数注释、类注释、定义 SQL 语句等,读者可以在 源码中看到大量三引号的应用,如下:

本示例使用三引号定义一个 SQL 字符串。如下:
str3 = """
CREATE TABLE users( # 表名
name VARCHAR(8), # 姓名字段
id INTEGER, # 编号字段
password INTEGER) # 密码字段
"""
print(str3)
(3) 使用 str() 函数
使用 str() 函数可以创建空字符串,也可以将任意类型的对象转换为字符串。下面示例演示使用 str() 函数创建字符串的不同形式。
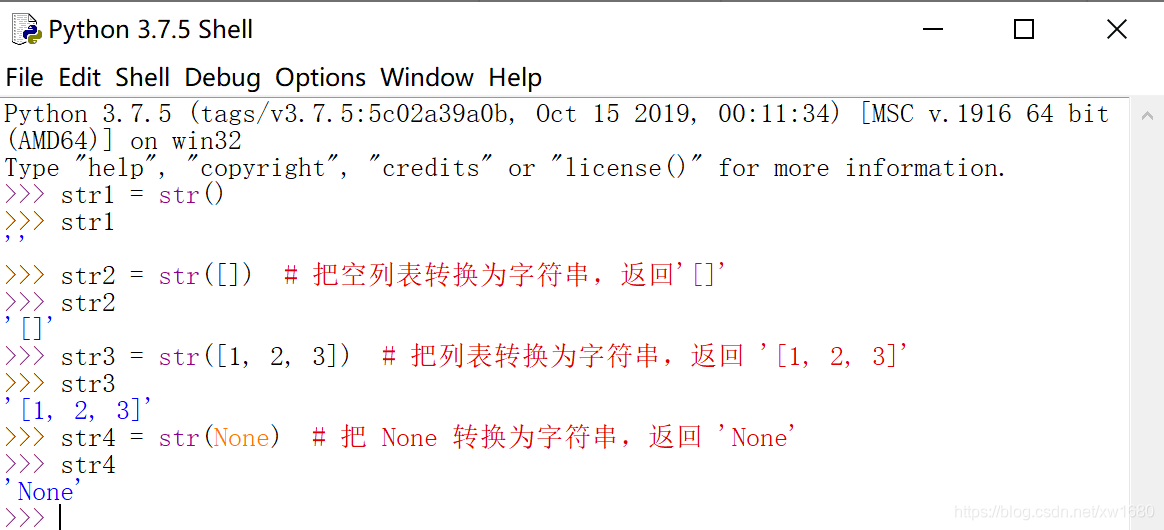
注意:str() 函数的返回值由类型的 __str__ 魔法方法决定。 下面示例自定义一个 list 类型,定义 __str__ 魔法方法的返回值为 list 字符串表示,同时去掉左右两侧的中括号分隔符。
class MyList(list): # 自定义 list类型,继承于list
def __init__(self, value): # 类型初始化函数
self.value = list(value) # 把接收的参数转换为列表并存储起来
def __str__(self): # 类型字符串表示函数
# 把传入的值转换为字符串,并去掉左右两侧的中括号分隔符
return str(self.value).replace("[", "").replace("]", "")
s = str(MyList([1, 2, 3])) # 把自定义类型实例对象转换为字符串
print(s) # 默认为"[1, 2, 3]" 实际输出结果为:"1, 2, 3"
1.2 转义字符
在 Python 字符串中如果显示特殊字符,必须经过转义才能够显示。例如,换行符需要使用 \n 表示,制表符需要使用 \t 表示,单引号需要使用 \' ,双引号需要使用 \" 表示,等等。Python 可用的字符转义序列说明如下表所示:
| 转 义 序 列 | 含 义 |
|---|---|
| \newline(下一行) | 忽略反斜杠和换行 |
| \\ | 反斜杠(\) |
| \’ | 单引号(’) |
| \" | 双引号(") |
| \a | ASCII 响铃(BEL) |
| \b | ASCII 退格(BS) |
| \f | ASCII 换页(FF) |
| \n | ASCII 换行(LF) |
| \r | ASCII 回车(CR) |
| \t | ASCII 水平制表(TAB) |
| \v | ASCII 垂直制表(VT) |
| \ooo | 八进制的 ooo 的字符。与标准C中一样,最多可接收3个八进制数字 |
| \xhh | 十六进制值 hh 的字符。与标准C不同,只需要2个十六进制数字 |
| \N{name} | Unicode 数据库中名称为 name 的字符。【提示】:只在字符串字面值中识别的转义序列 |
| \uxxxx | 16 位的十六进制值为 xxxx 的字符。4个十六进制数字是必需的。【提示】:只在字符串字面值中识别的转义序列 |
| \Uxxxxxxxx | 32 位的十六进制值为 xxxxxxxx 的字符,任何 Unicode 字符可以这种方式被编码。8个十六进制数字是必需的。【提示】:只在字符串字面值中识别的转义序列 |
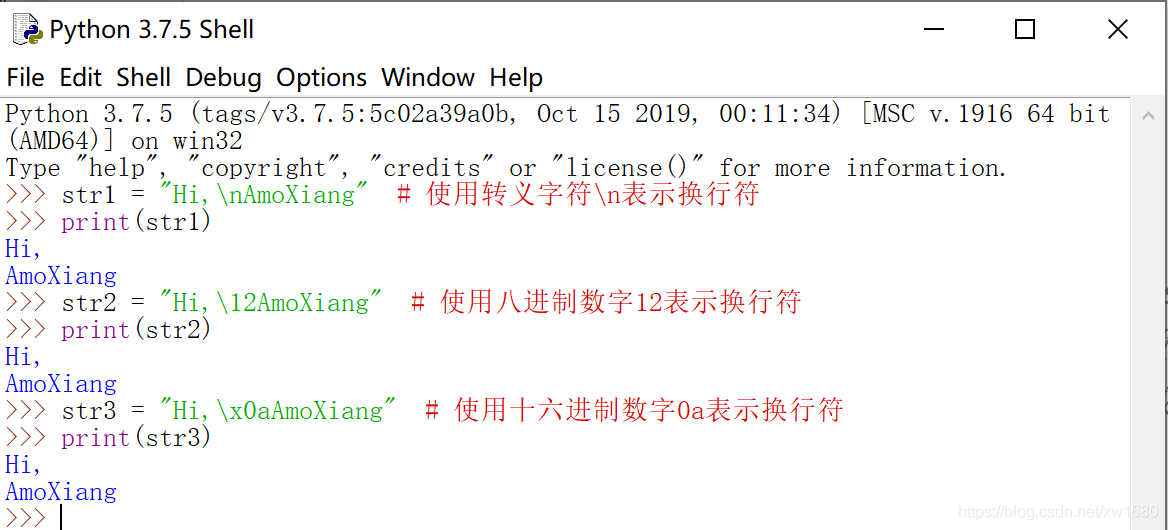
【示例1】本示例分别使用转义字符、八进制数字、十六进制数字表示换行符。
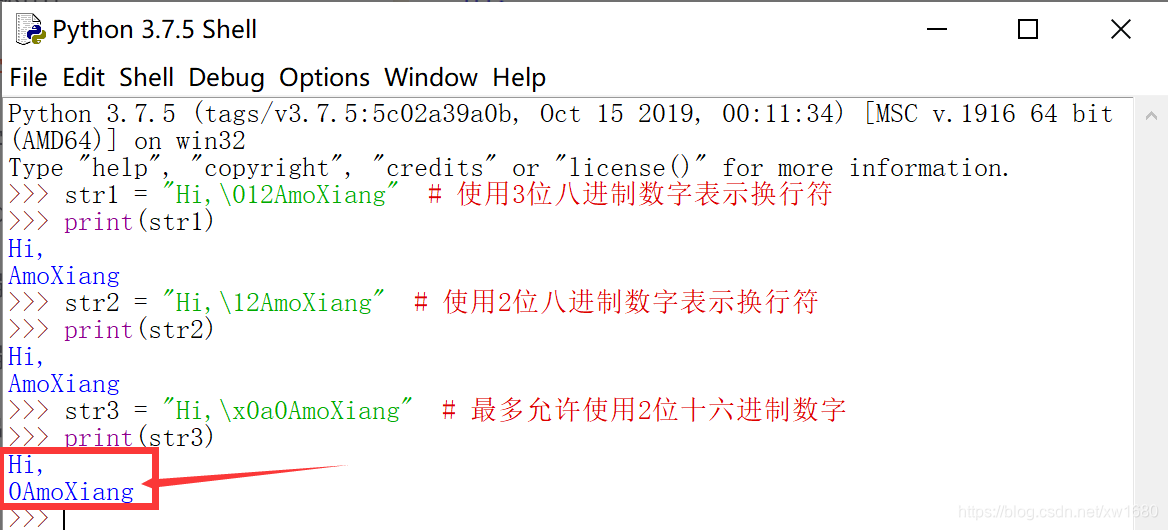
【示例2】如果八进制数字不满3位,则首位自动补充0。如果八进制数字超出3位,十六进制数字超出2位,超出数字将视为普通字符显示。
1.3 原始字符串
在 Python3 中,字符串常见有 3 种形式:普通字符串(str)、Unicode 字符串(unicode)和原始字符串(也称为原义字符串)。
原始字符串的出现目的:解决字符串中显示特殊字符。在原始字符串里,所有的字符都直接按照字面的意思来使用,不支持转义序列和非打印的字符。
原始字符串的这个特性让一些工作变得非常方便。例如,在使用正则表达式的过程中,正则表达式字符串,通常是由代表字符、分组、匹配信息、变量名和字符类等特殊符号组成。当使用特殊字符时,\字符 格式的特殊字符容易被歧义,这时使用原始字符串就会派上用场。可以使用 r 或 R 来定义原始字符串,这个操作符必须紧靠在第一个引号前面。语法格式如下:
r"原始字符串"
R"原始字符串"
【示例】定义文件路径的字符串时,会使用很多反斜杠,如果每个反斜杠都用歧义字符串来表示会很麻烦,可以采用下面代码来表示。
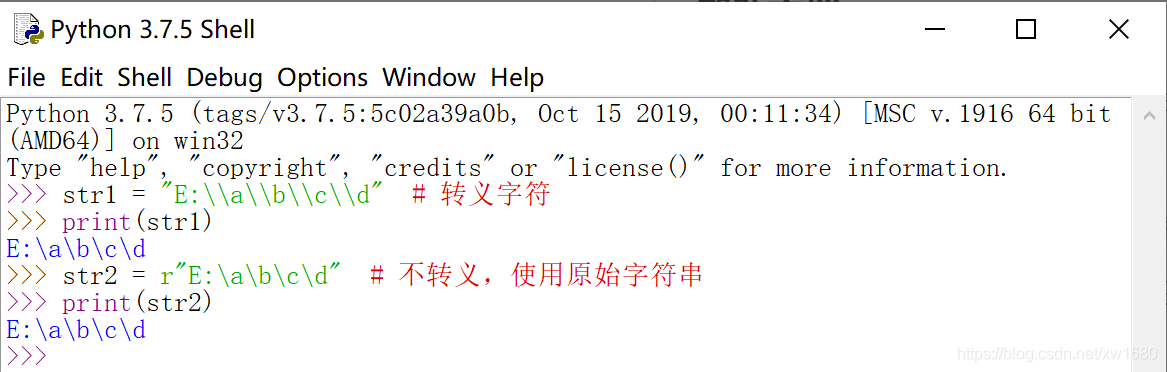
1.4 Unicode 字符串
从 Python 1.6 开始支持 Unicode 字符串,用来表示双字节、多字节字符、实现与其他字符编码的格式转换。在 Python 中,定义 Unicode 字符串与定义普通字符串一样简单,语法格式如下:
u'Unicode 字符串'
U"Unicode 字符串"
引号前面的操作符 u 或 U 表示创建的是一个 Unicode 字符串。如果想加入特殊字符,可以使用 Unicode 编码。例如:
str1 = u"Hello\u0020World"
print(str1) # 输出:Hello World
被替换的 \u0020 标识符表示在给定位置插入编码值为 0x0020 的 Unicode 字符(空格符)。Unicode 字符串的作用:u 操作符后面字符串将以 Unicode 格式进行编码,防止因为源码存储格式问题,导致再次使用时出现乱码。
unicode() 和 unichr() 函数可以作为 Unicode 版本的 str()和chr()。unicode()函数可以把任何 Python 的数据类型转换成一个 Unicode 字符串,如果对象定义了 __unicode__() 魔术方法,它还可以把该对象转换成相应的 Unicode 字符串。unichr() 函数和chr()函数功能基本一样,只不过返回 Unicode 的字符。
1.5 字符编码类型
字符编码就是把字符集中的字符编码为指定集合中某一对象,以便文本在计算机中存储和传递。常用字符编码类型如下。
- ASCII:全称为美国国家信息交换标准码,是最早的标准编码,使用 7 个或8个二进制位进行编码,最多可以给 256 个字符分配数值,包括 26 个大写与小写字母、10 个数字、标点符号、控制字符以及其他符号。
- GB2312:一个简体中文字符集,由 6763 个常用汉字和 682 个全角的非汉字字符组成。GB2312 编码使用两个字节表示一个汉字,所以理论上最多可以表示 256×256 =65536 个汉字。这种编码方式仅在中国通行。
- GBK:该编码标准兼容 GB2312,并对其进行扩展,也采用双字节表示。其共收录汉字 21003个、符号 883 个,提供 1894 个造字码位,简、繁体字融于一库。
- Unicode:是为了解决传统字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。Unicode 通常用两个字节表示一个字符,原有的英文编码从单字节变成双字节,只需要把高字节全部填为 0 即可。
- UTF-8:为了提高 Unicode 的编码效率,于是就出现了 UTF-8 编码。UTF-8 可以根据不同的符号自动选择编码的长短。比如英文字母可以只用1个字节就够了。
读者想要详细了解可以点击 编码百度百科 进行学习。
1.6 字节串
在 Python 中,有两种常用的字符串类型,分别为 str 和 bytes。其中, str 表示 Unicode 字符(ASCII或者其他),bytes 表示二进制数据(包括编码的文本)。这两种类型的字符串不能拼接在一起使用。通常情况下,str 在内存中以 Unicode 表示,一个字符对应若干个字节。但是如果在网络上传输,或者存到磁盘上,就需要把 str 转换为字节类型,即 bytes 类型。
字节串(bytes)也称字节序列,是不可变的序列,存储以字节为单位的数据。提示:bytes 类型是 Python3 新增的一种数据类型。字节串与字符串的比较:
- 字符串是由多个字符构成,以字符为单位进行操作。默认为 Unicode 字符,字符范围为 0~65535。字符串是字符序列,它是一种抽象的概念,不能直接存储在硬盘,用以显示供人阅读或操作。
- 字节串是由多个字节构成,以字节为单位进行操作。字节是整型值,取值范围 0~255。字节串是字节序列,因此可以直接存储在硬盘。
除了操作单元不同外,字节串与字符串的用法基本相同。它们之间的映射被称为解码或编码。定义字节串的方法如下:
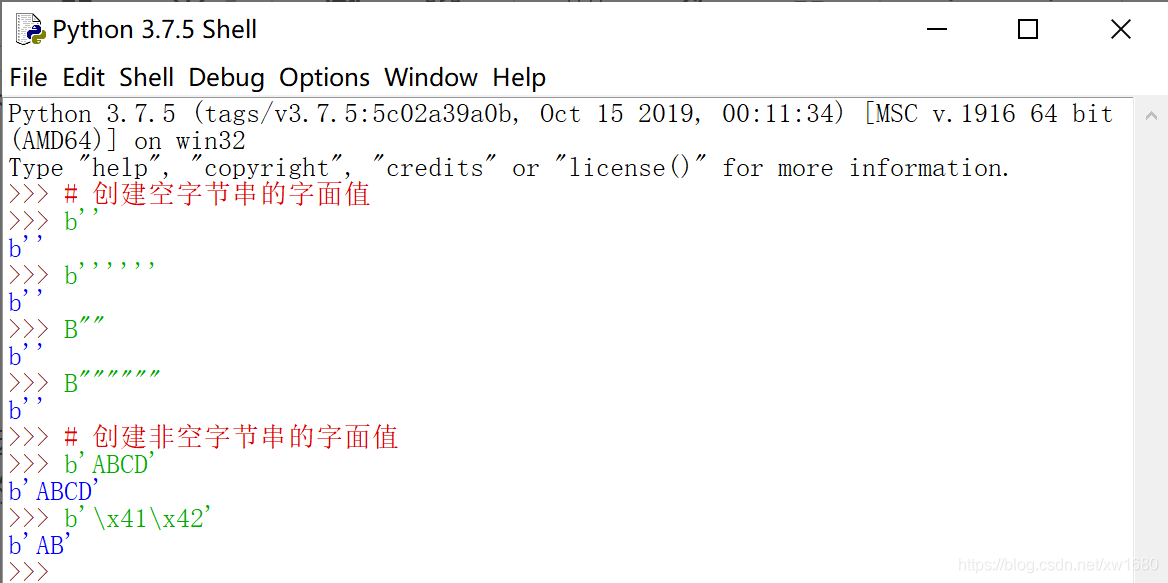
(1) 使用字面值
以 b 操作符为前缀的 ASCII 字符串。语法格式如下:
b"ASCII 字符串"
b"转义序列"
字节是 0~255 之间的整数,而 ASCII 字符集范围为 0~255,因此它们之间可以直接映射。通过转义序列可以映射更大规模的字符集。
【示例1】下面示例使用字面值直接定义字符串。
(2) 使用 bytes() 函数
使用 bytes() 函数可以创建一个字节串对象,简明语法格式如下:
bytes() # 生成一个空的字节串,等同于b''
bytes(整型可迭代对象) # 用可迭代对象初始化一个字节串,元素必须为[0,255]中的整数
bytes(整数n) # 生成n个值为零的字节串
bytes('字符串', encoding='编码类型') # 使用字符串的转换编码生成一个字节串
【示例2】下面示例使用 bytes()函数创建多个字节串对象。

字节串是不可变序列,使用 bytearray() 可以创建可变的字节序列,也称为字节数组(bytearray)。数组是每个元素类型完全相同的一组列表,因此可以使用操作列表的方法来操作数组。
bytearray() 函数的简明语法格式如下:
bytearray() # 生成一个空的可变字节串,等同于 bytearray(b'')
bytearray(整型可迭代对象) # 用可迭代对象初始化一个可变字节串,元素必须为 [0, 255] 中的整数
bytearray(整数n) # 生成 n 个值为零的可变字节串
bytearray(字符串, encoding='utf-8') # 用字符串的转换编码生成一个可变字节串
1.7 字符编码和解码
在编码转换时,通常以 Unicode 作为中间码,即先将一种类型的字符串解码(decode)成 Unicode,再从 Unicode 编码(encode)成另一种类型的字符串。
(1) 使用 encode()
使用字符串对象的 encode()方法可以根据参数 encoding 指定的编码格式将字符串编码为二进制数据的字节串,语法格式如下:
str.encode(encoding='UTF-8', errors='strict')
str 表示字符串对象:参数 encoding 表示要使用得编码类型,默认为 UTF-8 ,参数 errors 设置不同错误的处理方案,默认为 strict,表示遇到非法字符就会抛出异常,其他取值包括 ignore(忽略非法字符)、replace(用 ? 替换非法字符)、xmlcharrefreplace (使用 XML 的字符引用)、backslashreplace ,以及通过 codecs.register_error() 注册的任何值。
【示例1】本例使用 encode()方法对 中文 字符串进行编码。
u = "中文"
str1 = u.encode("gb2312")
print(str1)
str2 = u.encode("gbk")
print(str2)
str3 = u.encode("utf-8")
print(str3)
(2) 使用 decode()
与 encode() 方法操作相反,使用 decode()方法可以解码字符串,即根据参数 encoding 指定的编码格式将二进制数据的字节串解码为字符串。语法格式如下:
str.decode(encoding='UTF-8', errors='strict')
str 表示被 decode()解码的字节串,该方法的参数与 encode()方法的参数用法相同。最后返回解码后的字符串。
【示例2】针对示例1,可以使用下面代码对编码字符串进行解码。
u = "中文"
str1 = u.encode("gb2312")
u1 = str1.decode("gb2312")
print(u1) # 输出:中文
u2 = str1.decode("utf-8") # 报错,因为str1是gb2312编码的
"""
报错如下:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd6 in position 0: invalid continuation byte
"""
encode()和decode()方法的参数编码格式必须一致,否则将抛出上面代码所示的异常。
1.8 字符串的长度
计算字符串的长度可以使用 len()函数。例如:
s1 = "中国China" # 定义字符串
print(len(s1)) # 输出为7
从上面结果可以看出,在默认情况下,len()函数计算字符串的长度是区分字母、数字和汉字的,每个汉字视为一个字符。
但是,在实际开发中,有时候需要获取字符串的字节长度。在 UTF-8 编码中,每个汉字占用3个字节,而在 GBK 或 GB2312中,每个汉字占用 2 个字符。例如:
s1 = "中国China" # 定义字符串
print(len(s1.encode())) # 输出为11
print(len(s1.encode("gbk"))) # 输出为9
从上面代码可以看出,两行输出代码的结果并不相同,第 2 行 print(len(s1.encode())) 使用默认的 UTF-8 编码,则字节长度为11,即每个汉字占用 3 个字节,而第 3 行print(len(s1.encode(“gbk”))) 使用 GBK 编码,则字节长度为 9,即每个汉字占用 2 个字节。
因此,由于不同字符占用字节数不同,当计算字符串的字节长度时,需要考虑使用编码进行计算。在 Python 中,字母、数字、特殊字符一般占用 1 个字节,汉字一般占用 2~4 个字节。
1.9 访问字符串
Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。Python 访问字符串中的字符有两种方式。
(1) 索引访问
在 Python 中,字符串是一种有序序列,字符串里的每一个字符都有一个数字编号标识其在字符串中的位置,从左至右依次是:0、1、2、…、n-1,从右至左依次是 -1、-2、-3、…、-n(其中 n 是字符串的长度)。
【示例1】通过索引来访问字符串中的某个字符。

(2) 切片访问
使用切片可以获取字符中某个范围的子字符串。语法格式如下:
str[start:end:step]
参数 start 为起点,end 为终点,step 为步长,返回字符串由从 start 到 end-1 的字符组成。
【示例2】下面示例演示一些字符串切片操作。

提示:当切片的第 3 个参数为负数时,表示逆序输出,即输出顺序为从右到左,而不是从左到右。
1.10 遍历字符串
在字符串过滤、筛选和编码时,经常需要遍历字符串。遍历字符串的方法有多种,具体说明如下。
1.10.1 使用 for 语句
【示例1】使用 for 语句循环遍历字符串,然后把每个字符都转换为大写形式并输出。
s1 = "python" # 定义字符串
L = [] # 定义临时备用列表
for i in s1: # 迭代字符串
L.append(i.upper()) # 把每个字符转换为大写形式
print("".join(L)) # 输出大写字符串 PYTHON
1.10.2 使用 range()
使用 range() 函数,然后把字符串长度作为参数传入。
【示例2】针对示例1,也可以按照以下方式遍历字符串。
s1 = "python" # 定义字符串
L = [] # 定义临时备用列表
for i in range(len(s1)): # 根据字符串长度遍历字符串下标数字,
# 从0开始,直到字符串长度
L.append(s1[i].upper()) # 把每个字符转换为大写形式
print("".join(L)) # 输出大写字符串 PYTHON
1.10.3 使用 enumerate()
enumerate()函数将一个可迭代的对象组合为一个索引序列。
【示例3】针对示例1,使用 enumerate() 函数将字符串转换为索引序列,然后再迭代操作。
s1 = "python" # 定义字符串
L = [] # 定义临时备用列表
for i, char in enumerate(s1): # 把字符串转换为索引序列,然后再遍历
L.append(char.upper()) # 把每个字符转换为大写形式
print("".join(L)) # 输出大写字符串 PYTHON
1.10.4 使用 iter()
使用 iter()函数可以生成迭代器。语法格式如下:
iter(object[, sentinel])
参数 object 表示支持迭代的集合对象,sentinel 是一个可选参数,如果传递了第 2 个参数,则参数 object 必须是一个可调用的对象(如函数),此时,iter() 函数将创建一个迭代器对象,每次调用这个迭代器对象的 __next__() 方法时,都会调用 object。
【示例4】针对示例1,使用 iter() 函数将字符串生成迭代器,然后再遍历操作。
s1 = "python" # 定义字符串
L = [] # 定义临时备用列表
for item in iter(s1): # 把字符串生成迭代器,然后再遍历
L.append(item.upper()) # 把每个字符转换为大写形式
print("".join(L)) # 输出大写字符串 PYTHON
1.10.5 逆序遍历
逆序遍历就是从右到左反向迭代对象。
【示例5】本示例演示了 3 种逆序遍历字符串的方法。
s1 = "Python"
print("1. 通过下标逆序遍历:")
for i in s1[::-1]:
print(i, end="")
print("\n2. 通过下标逆序遍历:")
for i in range(len(s1) - 1, -1, -1):
print(s1[i], end="")
print("\n3. 通过reversed()逆序遍历:")
for i in reversed(s1):
print(i, end="")
1.11 案例:判断两个字符串是否为变形词
假设给定两个字符串 str1、str2,判断这两个字符串中出现的字符是否一致,字符数量是否一致,当两个字符串的字符和数量一致时,则称这两个字符串为变形词。例如:
str1 = "python", str2="thpyon", 返回True
str2 = "python", str2="thonp", 返回False
示例代码如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:2.判断两个字符串是否为变形词.py
@time:2021/01/16
"""
def is_deformation(str1, str2): # 定义变形词函数
if str1 is None or str2 is None or len(str1) != len(str2): # 当条件不符合时
return False # 返回False
if len(str1) == 0 and len(str2) == 0: # 当两个字符串长度都为0时
return True # 返回True
dic = dict() # 定义一个空字典
for char in str1: # 循环遍历字符串str1
if char not in dic: # 判断字符是否在字典中
dic[char] = 1 # 不存在时,赋值为1
else:
dic[char] = dic[char] + 1 # 存在时字符的值累加
for char in str2: # 循环遍历字符串str2
if char not in dic: # 当str2的字符不在字典中时 返回False
return False
else:
dic[char] = dic[char] - 1 # 当str2和str1的字符种类一致时,字典中的字符值自减1
# 字符的值小于0,即字符串的字符数量不一致 返回False 否则返回True
if dic[char] < 0:
return False
return True
str1 = "python"
str2 = "thpyon"
str3 = "hello"
str4 = "helo"
# 输出:python thpyon is deformation: True
print(str1, str2, "is deformation:", is_deformation(str1, str2))
# 输出:hello helo is deformation: False
print(str3, str4, "is deformation:", is_deformation(str3, str4))
1.12 案例:字节串的应用
1.12.1 计算md5
在计算 md5 值的过程中,有一步要使用 update 方法,而该方法只接受 bytes 类型数据。
import hashlib
string = "123456"
m = hashlib.md5() # 创建md5对象
str_bytes = string.encode(encoding='utf-8')
print(type(str_bytes)) # <class 'bytes'>
m.update(str_bytes) # update方法只接收bytes类型数据作为参数
str_md5 = m.hexdigest() # 得到散列后的字符串
print('MD5散列前为 :' + string) # MD5散列前为 :123456
print('MD5散列后为 :' + str_md5) # MD5散列后为 :e10adc3949ba59abbe56e057f20f883e
1.12.2 二进制读写文件
使用二进制方式读写文件时,均要用到 bytes 类型,二进制写文件时,write()方法只接受 bytes 类型数据,因此需要先将字符串转成 bytes 类型数据;读取二进制文件时,read()方法返回的是 bytes 类型数据,使用 decode()方法可将 bytes 类型转成字符串。
f = open('data.txt', 'wb')
text = '二进制写文件'
text_bytes = text.encode('utf-8')
f.write(text_bytes)
f.close()
f = open('data.txt', 'rb')
data = f.read()
print(data, type(data))
str_data = data.decode('utf-8')
print(str_data)
f.close()
1.12.3 socket编程
使用 socket 时,不论是发送还是接收数据,都需要使用 bytes 类型数据。关于网络编程,请点击 Python网络编程 进行学习。
至此今天的案例就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习 Python 基础的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!