Redis基本数据类型
前言
在日常开发中,我们一般都选择关系型数据库来存储数据,如MySQL,Oracle等,但是在并发量比较大的业务场景,关系型数据库往往会成为系统瓶颈,无法完全满足我们的需求,所以就诞生了非关系型数据库,即NoSQL数据库。
NoSQL数据库最常见的解释是“non-relational”,也有人解释为“Not Only SQL”。非关系型数据库不保证事务,也就是不具备ACID特性,这也是非关系型数据库和关系型数据库最大的区别,而我们即将介绍的Redis就属于NoSQL数据库的一种。
PS:本系列文章基于Redis5.0.5版本。
为什么需要NoSQL数据库
相比较于传统的关系型数据库,NoSQL数据库具有如下优点:
- 1、数据之间无关联关系,非常易于扩展
- 2、支持海量数据的读写,高并发下性能更高
- 3、支持分布式存储,而且扩缩容简单
同时,NoSQL数据库的种类也非常多,按照不同的数据存储类型划分的话主要有以下常见的NoSQL数据库:
- 1、key-value存储。如:Redis和MemcaheDB
- 2、文档存储。如:MongoDB
- 3、列存储。如:HBase
- 4、图(Graph)存储。如:Neo4j
- 5、对象存储
- 6、其他类型不再列举
什么是Redis
Redis全称:REmote DIctionary Service,即远程字典服务。Redis是一个开源的(遵守BSD协议)、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库。
Redis具有以下特性:
- 1、支持丰富的数据类型。如字符串(strings),散列(hashes),列表(lists),集合(sets),有序集合(sorted sets)与范围查询, bitmaps等。
- 2、功能丰富。提供了持久化机制,过期策略,订阅/发布等功能
- 3、高性能,高可用且支持集群
- 4、提供了多种语言的API
Redis基本知识介绍
Redis当中采用key和value形式存储,key和value的最大长度限制是512M。
Redis默认有16个数据库,这个可以在配置文件redis.conf中做出修改:
databases 16
这16个数据库以编号0-15命名,不支持修改名字,而且各个数据库之间的数据并不具备隔离性,比如我们切换到任意一个数据库,执行命令flushall就可以清空所有数据库的数据,所以并不建议通过数据库来隔离不同的业务系统数据,但是我们可以针对同一个业务系统中的不同模块将其设置到不同的数据库中。
常用数据库操作命令
- 切换数据库。切换数据库之后会显示当前所在数据库编号,默认0号数据库不显示编号。
select 数据库编号

下面图示可以看到,我们是在0号数据库设值,所以切换到其他数据库中无法取到值:

- 清空当前数据库
flushdb
- 清空所有数据库
flushall
Redis数据类型
Redis中支持的数据类型到5.0.5版本为止,一共有9种。分别是:
- 1、Binary-safe strings(二进制安全字符串)
- 2、Lists(列表)
- 3、Sets(集合)
- 4、Sorted sets(有序集合)
- 5、Hashes(哈希)
- 6、Bit arrays (or simply bitmaps)(位图)
- 7、HyperLogLogs
- 8、 geospatial
- 9、Streams
虽然这里列出了9种,但是我们最常用的就是前面5种。
在Redis中,针对每种数据类型都提供了不同的类型的命令,下面就让我们依次来介绍一下。
1.Binary-safe strings(二进制安全字符串)
字符串类型是我们使用最广泛的一种类型,而且Redis中的key值只能用字符串来存储,而value就可以支持9种数据类型。
Redis当中的字符串可以存储三种数据类型:
- 字符串
- 整数
- 浮点数
所以我们字符串类型的操作命令还包括了自增命令,下面我们来看一下字符串类型的常用操作命令
常用命令
下面介绍几个常用的操作命令:
- 设值(只能设值单个key和value)
set key value
- 设值(多个key和value)
mset key1 value1 key2 value2
- 取单个值
get key
- 取多个值
get key1 key2

- 查看当前数据库所有的键(这个操作慎用,键值过多时可能会直接崩溃)
keys *
- 查看当前数据库键的总数(返回一个integer)
dbsize
- 查看键是否存在当前数据库(返回的是一个整型:0-否 1-是)
exists key
- 重命名键
rename oldKey newKey

- 删除键(多个以空格隔开,返回的是成功删除键的个数)
del key

- 查看键的类型
type key

- 自增1(如果value不是整数,则会报错)
incr key
- 自增指定大小(如果value不是整数,则会报错)
incrby key 需要自增的数字

- 设值,如果key已经存在则设置失败
setnx key value # 设置单个key
mset key1 value1 key2 value2 # 设置多个key

PS:setnx和mset是原子操作,必须所有都设置成功才会返回true,其还有参数可以设置过期时间,一般分布式锁就是基于带过期时间的这个命令来实现的。
- 带过期时间设置key
set key value EX|PX 18 # EX表示秒,PX表示毫秒
下面这个例子就是设置了5秒后自动过期

- 单独设置过期时间。不过一般为了保证原子性,我们都是使用上面set直接带时间的命令。
expire key
应用场景
字符串类型的应用场景非常丰富,正常的热点数据都可以采用字符串类型来进行缓存,主要可以应用如下场景:
- 1、热点数据及其对象缓存
- 2、分布式Session共享
- 3、分布式锁(利用setnx命令)
- 4、Redis独立部署,可以用来作为全局唯一ID
- 5、利用其原子性递增命令,可以作为计数器或者限流等
2.Lists(列表)
Redis中的List列表内部的元素也是字符串,我们可以将指定元素添加到列表中的指定位置。列表数据类型的操作命令一般都会有小写字母l开头。
常用命令
来看一些常用的操作命令:
- 将一个或者多个value插入到列表key的头部,key不存在则创建key
lpush key value1 value2
- 将value插入到列表key的头部,key不存在则不做任何处理
lpushx key value1 value2
- 移除并返回key值的列表头元素
lpop key
- 将一个或者多个value插入到列表key的尾部,key不存在则创建key
rpush key value1 value2
- 将一个或者多个value插入到列表key的尾部,key不存在则不做任何处理
rpushx key value
- 移除并返回key值的列表尾元素
rpop key
- 返回key列表的长度
llen key
- 返回key列表中下标为index的元素。头部从0开始,尾部从-1开始
lindex key index
- 返回key列表中下标start(含)到stop(含)之间的元素
lrange key start stop
- 将value设置到key列表中指定index位置。key不存在或者index超出范围则会报错
lset key index value
- 截取列表中[start,end]之间的元素,并替换原列表保存
ltrim key start end

3.Sets(集合)
Redis中的集合是一个String类型的无序集合,集合中元素唯一不可重复。
常用命令
Set集合的操作命令一般都以s开头,下面就列举一些常用的命令:
- 将一个或多个元素member加入到集合key当中,并返回添加成功的数目,如果元素已存在则被忽略
sadd key member1 member2
- 判断元素member是否存在集合key中
sismember key member
- 移除集合key中的元素,不存在的元素会被忽略
srem key member1 member2
- 将元素member从集合source中移动到dest中,如果member不存在,则不执行任何操作
smove source dest member
- 返回集合key中所有元素
smembers key

4.Sorted Sets(有序集合)
Redis中的有序集合和集合的区别是有序集合中的每个元素都会关联一个double类型的分数,然后按照分数从小到大的顺序进行排列。
常用命令
Sorted Sets集合的操作命令一般都以z开头,下面就列举一些常用的命令:
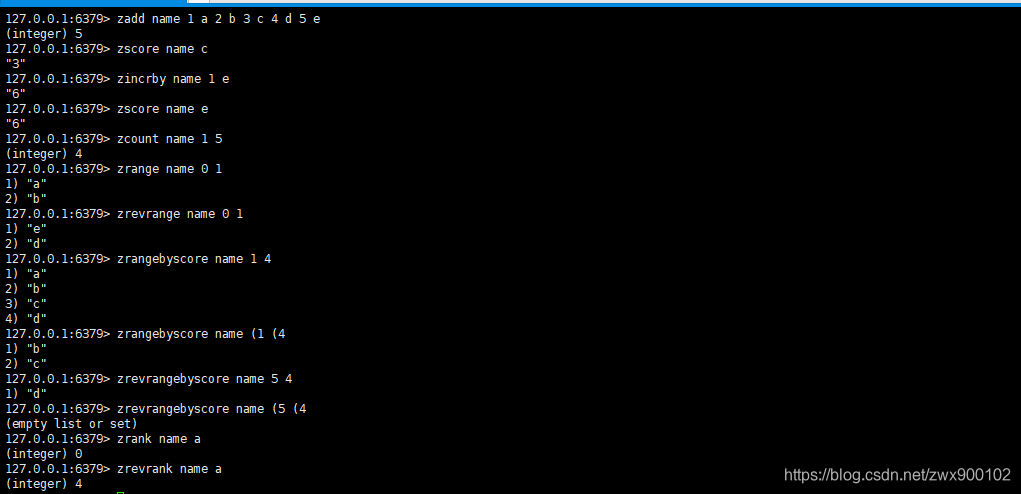
- 将一个或多个元素member及其score添加到有序集合key中
zadd key score1 member1 score2 member2
- 返回有序集合key中member成员的score
zscore key member
- 将有序集合key中的member加上num ,num可以为负数
zincrby key num member
- 返回有序集合key中score值在min(含)到max(含)之间的member数量
zcount key min max
- 返回有序集合key中score从小到大排列后start(含)到end(含)之间的所有member
zrange key start stop
- 返回有序集合key中score从大到小排列后start(含)到end(含)之间的所有member
zrevrange key start stop
- 返回有序集合中score从min到max的所有元素,按score从小到大排列。注意这里默认是闭区间,但是可以在max和min前面加上(或者[来控制开闭区间
zrangebyscore key min max
- 返回有序集合中score从max到min的所有元素,按score从大到小排列。注意这里默认是闭区间,但是可以在min和max前面加上(或者[来控制开闭区间
zrevrangebyscore key max min
- 返回有序集合中member中元素排名(从小到大),返回的结果从0开始计算
zrank key member
- 返回有序集合中member中元素排名(从大到小),返回的结果从0开始计算
zrevrank key member
- 返回有序集合中min和max之间的member数量。注意这个命令中的min和max前面必须加(或者[来控制开闭区间,特殊值-和+分别表示负无穷和正无穷
zlexcount key min max
5.Hashes(哈希)
哈希表中存储的是一个key和value的映射表。操作哈希数据类型的命令一般都是h开头。
常用命令
下面就是一些常用命令的示例:
- 将哈希表key中域field的值设置为value
hset key field value #设置单个field
hmset key field1 value1 field2 value2 #设置多个field
- 将哈希表key中域field的值设置为value,如果field已存在,则不执行任何操作
hsetnx key field value
- 获取哈希表key中的域field对应的value
hget key field
- 获取哈希表key中的多个域field对应的value
hmget key field1 field2
- 删除哈希表key中的一个或者多个field
hdel key field1 field2
- 返回哈希表key中域的数量
hlen key
- 为哈希表key中的域field的值加上增量increment,increment可以为负数,如果field不是数字则会报错
hincrby key field increment
- 为哈希表key中的域field的值加上增量increment,increment可以为负数,如果field不是float类型则会报错
hincrbyfloat key field increment
- 为哈希表key中的域field的值加上增量increment,increment可以为负数,如果field不是数字则会报错
hincrby key field increment
- 获取哈希表key中的所有域
hkeys key
- 获取哈希表中所有域的值
hvals key

应用场景
哈希类型和字符串类型其实非常像,所以基本上字符串能做的事情,哈希都能做,而且在有些场景下利用哈希的分类存储,将会更加高效。
6.Bit arrays (or simply bitmaps)位图
位图bitmap就是通过最小的单位bit来进行0或者1的设置,表示某个元素对应的值或者状态,其值只能是0或者1,表示是或者否。所以这个一般用于统计是否登录,是否收藏等非否即是的数据。
比如存储数据格式一般为:100110000111,这里的0和1就是bit值,设置的时候可以设置指定位置(偏移量)的bit值。
PS:位图的底层存储数据结构也是采用的字符串对象。
常用命令
位图数据类型主要提供了以下命令:
- 对key所储存的字符串值,设置或清除指定偏移量offset上的位(bit)值。offset参数必须大于或等于0且小于 2^32 (bit 映射被限制在 512 MB 之内)。
setbit key offset value
- 获取指定偏移量offset上的bit值
getbit key offset
- 计算给定字符串中,被设置为1的bit数量,start和end可以省略则统计全部,0表示第1位,-1表示最后一位
bitcount key [start] [end]
- 返回位图中第一个值为bit的二进制位的位置,start和end可以省略,0表示第1位,-1表示最后一位
bitpos key bit [start] [end]

应用场景
这个一般应用在非否即是的场景,比如说是否登录,用户是否留存,是否收藏商品,是否点赞等等。
7.HyperLogLogs
HyperLogLog是Redis 2.8.9 版本新增的一种用来做基数统计算法的数据结构。其优点是在输入元素的数量或者体积非常大时,计算基数所需的空间总是固定的、并且是很小的。这种数据结构一般用于统计UV之类的信息。
HyperLogLog本身是一种算法,其来源于论文《HyperLogLog the analysis of a near-optimal cardinality estimation algorithm》,大家如果对这种算法感兴趣的可以去了解一下。
在Redis里面,每个HyperLogLog键只需要花费12KB内存,就可以计算接近2^64 个不同元素的基数,但是也可能有0.81%的错误率。
PS:HyperLogLogs的底层存储数据结构也是采用的字符串对象。
常用命令
这种数据类型主要提供了以下三个命令:
- 将任意数量的元素添加到指定的HyperLogLog中的key里面
pfadd key element1 element2
- 获取一个或者多个key的基数
pfcount key1 key2
- 将多个sourcekey合并到一个destkey中,合并后的destkey中的基数接近于合并前所有sourcekey的并集
pfmerge destkey sourcekey1 sourcekey2

从上面我们可以看到,存进去之后并没有取出来的命令,所以这个一般就是用来统计,而且需要能接受误差。
比如上面的示例中,假如u1 u2 u3 u4就是用户id,那么我不需要判断,只要用户来访问一次网页我就存一次,最后通过pfcount取出来的值就是去重后的值(也就是上面所说的基数),虽然说有一定误差,但是像uv这种统计数据是可以接受误差的。
应用场景
这个一般应用在可以接受误差场景的数据统计,比如说UV统计等场景
8.geospatial(地理位置)
geospatial是Redis在3.2版本中新增的一种具有半径查询的地理空间索引数据类型。一般用来存储并计算两地之间的距离。
PS:HyperLogLogs的底层存储数据结构也是采用的有序集合对象。
常用命令
以下就是一些常用命令:
- 将给定的空间元素(纬度、经度、名字)添加到指定的键key里面。其中有效的经度介于 -180 度至 180 度之间,有效的纬度介于-85.05112878 度至 85.05112878 度之间。
geoadd key longitude latitude member
- 从键key里面返回所有给定位置元素的位置(经度和纬度)。
geopos key member1 member2
- 返回两个给定位置之间的距离。默认单位是米(m),可以通过unit指定,unit支持以下类型:米(m),千米(km),英里(mi),英尺(ft)。
geodist key member1 member2 [unit]
- 以给定的经纬度为中心,返回键包含的位置元素当中,与中心的距离不超过给定最大距离的所有位置元素。
georadius key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [ASC|DESC] [COUNT count]
- 以给定的元素为中心,返回键包含的位置元素当中,与中心的距离不超过给定最大距离的所有位置元素。
georadiusbymember key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [ASC|DESC] [COUNT count]
最后两个命令基本上是一样的,一个是需要指定经纬度,一个是会自动读取某一个元素的经纬度。主要参数含义如下(单位就不重复介绍了):
- WITHDIST : 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。 距离的单位和用户给定的范围单位保持一致。
- WITHCOORD :将位置元素的经度和维度也一并返回。
- WITHHASH :以52位有符号整数的形式, 返回位置元素经过原始geohash编码的有序集合分值。这个选项主要用于底层应用或者调试, 实际中的作用并不大。
- ASC:根据中心的位置, 按照从近到远的方式返回位置元素。
- DESC:根据中心的位置, 按照从远到近的方式返回位置元素。
- COUNT:指定返回的个数。对计算性能影响不大,但是如果返回的区域非常多的情况下,使用count可以节省带宽
应用场景
这个应用场景就很明显了,只有需要计算地理位置相关的场景才会需要。
9.Streams
Streams是Redis5.0推出的一种数据类型。支持多播的可持久化消息队列,用于实现发布订阅功能,Streams的设计借鉴了kafka。Stream是Redis中最复杂的一种数据类型,在这里我们不展开介绍,后面介绍分布/订阅功能的时候再单独介绍这种数据类型及其强大复杂的操作API。
总结
本文主要介绍了Redis中9种基本数据类型及其常用的操作命令和应用场景进行分析,Redis中的数据类型非常丰富,虽然大部分情况下字符串类型就够用了,但是在某些特定场景使用特定类型将会更加高效和优雅。
下一篇,我们将介绍一下Redis中数据类型底层的数据结构。
请关注我,和孤狼一起学习进步。