本文来自ICIP2020论文《CNN ORIENTED COMPLEXITY REDUCTION OF VVC INTRA ENCODER》

VVC复杂度增加很大一部分是因为其块划分方式,除了四叉树划分还支持二叉树和三叉树划分。该论文通过使用CNN在All Intra(AI)模式下预测块的划分方式减少计算复杂度。
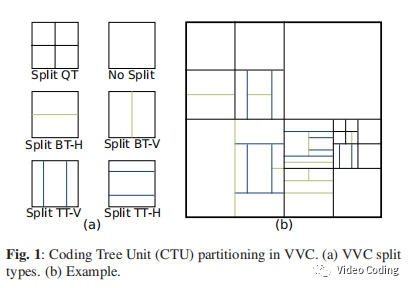
上图Fig.1是VVC的块划分模式,二叉树和三叉树可以在水平和垂直方向上划分产生矩阵子块。VVC需要对每种划分模式计算RD cost,选择RD cost的作为最终模式计算量非常大。论文通过实现一个CNN,以64x64的亮度块作为输入,输出一个向量表示每个4x4块边界的概率。通过这个向量编码器可以跳过一些不可能的划分模式。
CNN结构
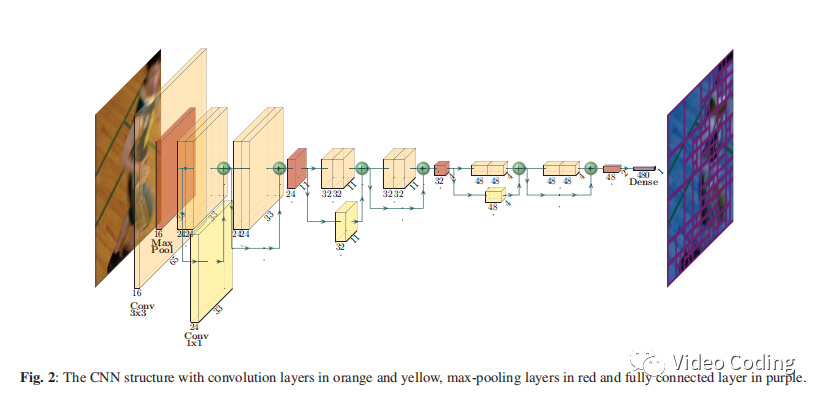
论文提出的CNN结构基于ResNet,如上图Fig.2所示。网络输入为64x64的亮度CU,输出为480维向量。由于帧内预测需要使用左边一列和上边一行的信息,所以实际网络输入为65x65。
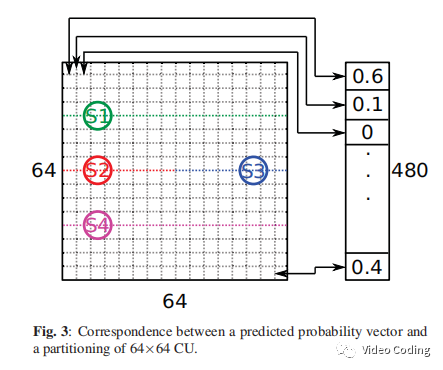
上图Fig.3是CU划分和输出向量。例如向量第一个值表示左上角4x4块下边界的概率。
训练过程
训练就是通过优化CNN权重使得损失函数值最小,损失函数定义如下:
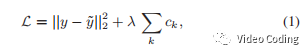
其中y是ground truth向量,lambda=10^-5,c_k是惩罚项。使用Adam optimizer来优化CNN网络。训练使用python3.6下的tensorflow框架以keras做后端。GPU为RTX 2080Ti,batch size为256,共训练10 epochs。
训练集由65x65的亮度块和对应的ground truth向量组成。65x65的亮度块从Div2k1数据集和4K图像数据集中提取出来。由于我们在AI配置下实验,所以只使用数据集中的静态图像而不是视频,这比只使用视频数据集的训练带来了更多的多样性。CNN输入的65x65的亮度块归一化到[0,1]。ground truth向量是将输入图像在VTM6.1 AI配置下编码后计算得到,收集每个64x64块的划分信息生成480维向量(1表示划分,0表示不划分)。
VTM中使用CNN
要在VTM6.1中集成上面训练好的CNN模型。由于CNN是在python中训练的,使用frugally-deep library在c++中调用。
上面Fig.3展示了使用CNN判断一些水平划分模式(BTH和TTH)是否跳过。边界划分概率通过下面方式计算,首先计算S1,S2,S3,S4的平均概率,分别表示为P(S1),P(S2),P(S3),P(S4)。BTH划分概率由S2和S3中较小的概率决定,
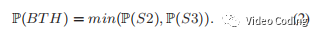
TTH划分概率由S1和S4计算,min(P(S1),P(S4))。垂直划分模式(BTV,TTV)计算方式类似。四叉树划分模式QT的划分概率由BTH和BTV的概率决定(即水平和垂直都进行二叉树划分相对于进行四叉树划分),
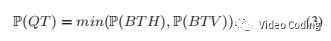
对上面的模式获得概率后就可以判断该边界是不是需要按该模式划分,
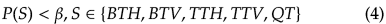
如果概率小于阈值beta则跳过该模式。当beta越大时,划分的次数越少,复杂度降低的更多同时编码失真也更大。论文中beta范围为[0,100]。
实验
实验在VTM6.1中AI配置下进行,操作系统为ubuntu16.04.5,Intel Xeon E5-2603处理器1.70GHz主频。测试集为官方测试序列,共包含26条序列分为6类, A (3840x2160),B (1920x1080), C (832x480), D (416x240), E (1280x720),F(832x480到1920x1080)。量化参数QP为22,27,32,37。
评价指标使用BD-Rate和复杂度降低(编码时间减少),
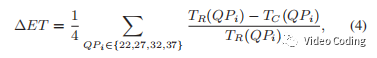
其中T-R是正常编码时间,T_C是加入文中算法后的编码时间(不包括CNN执行时间)。

上表是和几个算法的结果比较,beta=10,20,30。可以看到尤其是在高分辨率视频上文中算法表现更好,这是因为CNN的训练集由1080p和4k图像构成。
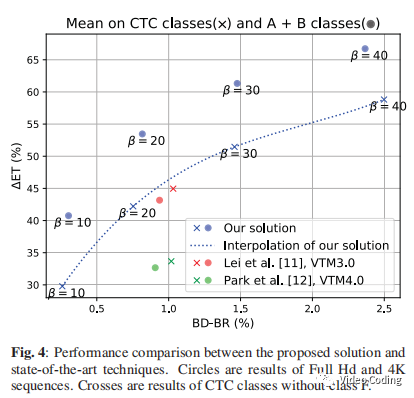
上图是本文算法和其他算法的复杂度降低与BD-Rate关系图。包括A-E序列,其中A-B序列用圆圈表示其他用叉表示。
更详细的内容请参考ICIP2020论文《CNN ORIENTED COMPLEXITY REDUCTION OF VVC INTRA ENCODER》
感兴趣的请关注微信公众号Video Coding
