一、MySQL 数据类型
MySQL所有数据类型如下图所示:
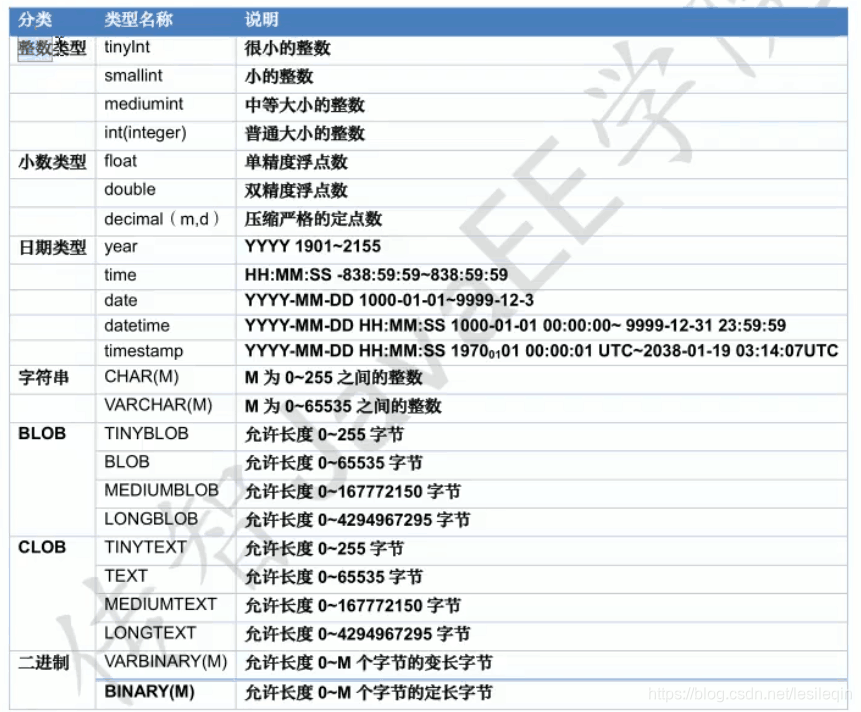
其中常用的如下表所示:
| 类型名称 | 说明 |
|---|---|
int |
普通大小的整数 |
double |
双精度浮点数,即小数 |
date |
日期,只包含年月日:yyyy-MM-dd |
datetime |
日期,包含年月日时分秒:yyyy-MM-dd HH:mm:ss |
timestamp |
时间戳类型,包含年月日时分秒:yyyy-MM-dd HH:mm:ss如果将来不给这个字段赋值或赋值为null,则默认使用当前系统时间来自动赋值 |
varchar |
字符串 |
二、SQL
SQL全称为:Structured Query Language,是一种结构化查询语言。它定义了所有操作关系型数据库的规则,每一种数据库操作的方式存在不一样的地方,称为:“方言”。本文章仅介绍MySQL
1、数据定义语言 DDL
DDL全称为Data Definition Language,它可以操作数据库和表,下面分别介绍:
操作数据库
1)创建:
创建数据库:
create database 数据库名称;
创建数据库,判断该数据库不存在再创建:
create database if not exists 数据库名称;
创建数据库,并指定字符集
create database 数据库名称 character set 字符集名;
创建数据库,判断是否存在,并指定字符集:
create database if not exists 数据库名称 character set 字符集名;
2)查询:
查询所有数据库的名称:
show databases;
查看某个数据库的字符集,查询某个数据库的创建语句:
show create database 数据库名称;
3)修改:
修改数据库的字符集:
alter database 数据库名称 character set 字符集名称;
4)删除:
删除数据库:
drop database 数据库名称;
判断数据库是否存在,存在再删除:
drop database if exists 数据库名称;
5)使用数据库:
查询当前正在使用的数据库名称:
select database();
使用数据库:
use 数据库名称;
操作表
1)创建:
创建表:
create table 表名(
列名1 数据类型1,
列名2 数据类型2,
……
列名n 数据类型n
);
注意:最后一列,不需要加逗号!
复制表:
create table 表名 like 被复制的表名;
2)查询:
查询某个数据库中的所有表名称:
show tables;
查询表结构:
desc 表名;
3)修改:
修改表名:
alter table 表名 rename to 新的表名;
修改表的字符集:
alter table 表名 character set 字符集名称;
添加一列:
alter table 表名 add 列名 数据类型;
修改列名称、类型:
#同时修改列名和数据类型
alter table 表名 change 列名 新列名 新数据类型;
#仅修改某列的数据类型
alter table 表名 modify 列名 新数据类型;
删除列:
alter table 表名 drop 列名;
4)删除:
删除表:
drop table 表名;
判断是否存在,存在再删除表:
drop table if exists 表名;
2、数据操纵语言 DML
DML全称为Data Manipulation Language,它可以增删改表中的数据
1)添加数据:
语法:
insert into 表名(列名1,列名2,...,列表n) values (值1,值2,...,值n);
注意:
- 列名和值要一一对应
- 如果表名后不定义列名,则默认给所有列添加值
insert into 表名 values (值1,值2,...,值n); - 除了数字类型,其他类型需要使用引号(单双引号都可以)引起来
2)删除数据:
语法:
delete from 表名 [where 条件]
注意:
- 如果不加条件,则删除表中所有记录
- 如果要删除所有记录:
delete from 表名; -- 不推荐使用,有多少条记录就会执行多少次删除操作,效率低 truncate table 表名; -- 推荐使用,先删除表,然后再创建一张一模一样的表,效率高
3)修改数据:
语法:
update 表名 set 列名1=值1 , 列名2=值2 , ... [where 条件]
注意:如果不加条件,则会将表中所有记录全部修改
3、数据查询语言 DQL
DQL全称为Data QueryLanguage,是SQL中最常用的!标记一个Triple star!⭐️⭐️⭐️
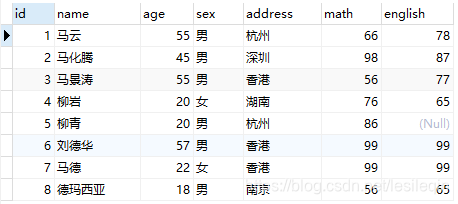
这个部分结合案例来学习,首先创建一个数据库,再创建一张表,再插入几条数据:
-- 如果college数据库不存在,则创建
create database if not exists college;
-- 使用该数据库
use college;
-- 创建student表
create table student(
id int, -- 编号
name varchar(20), -- 姓名
age int, -- 年龄
sex varchar(5), -- 性别
address varchar(100), -- 地址
math int, -- 数学
english int -- 英语
);
-- 插入数据
insert into student (id,name,age,sex,address,math,english) values
(1,'马云',55,'男','杭州',66,78),
(2,'马化腾',45,'男','深圳',98,87),
(3,'马景涛',55,'男','香港',56,77),
(4,'柳岩',20,'女','湖南',76,65),
(5,'柳青',20,'男','杭州',86,NULL),
(6,'刘德华',57,'男','香港',99,99),
(7,'马德',22,'女','香港',99,99),
(8,'德玛西亚',18,'男','南京',56,65);
操作结果如下图所示:
现在开始学习DQL:
基础查询
-- 查询student表中所有数据
select * from student;
-- 查询 姓名 和 年龄
select name,age from student;
-- 去除重复结果集
select distinct address from student;
-- 计算 math 和 english 分数之和
select name,math,english,math+english from student;
-- 如果有null,参与的运算,计算结果均为null
select name,math,english,math+IFNULL(english,0) from student;
-- 起别名
select name as 姓名,math as 数学,english as 英语 ,math+IFNULL(english,0) as 总分 from student;
-- 起别名 as 可以省略不写
select name 姓名,math 数学,english 英语 ,math+IFNULL(english,0) 总分 from student;
条件查询
运算符
| 比较运算符 | 说明 |
|---|---|
>、<、<=、>=、=、<> |
<>在sql中表示不等于,在mysql中也可以使用!=,但是没有== |
between...and |
在一个范围内,如between 100 and 200,相当于大于等于100且小于等于200 |
IN(集合) |
集合表示多个值,使用逗号分隔 |
LIKE '张%' |
模糊查询 |
IS NULL |
查询某一列为NULL的值,注意,不能写=NULL |
逻辑运算符
| 逻辑运算符 | 说明 |
|---|---|
and 或 && |
与,建议使用前者 |
or 或 || |
或 |
not 或 ! |
非 |
-- 查询math分数大于80分的同学
select * from student where math > 80;
-- 查询english分数小于或等于80分的同学
select * from student where english <= 80;
-- 查询age等于20的同学
select * from student where age = 20;
-- 查询age不等于20的同学
select * from student where age != 20;
select * from student where age <> 20;
-- 查询age在20到30之间的通信
select * from student where age between 20 and 30;
select * from student where age >= 20 and age <= 30;
-- 查询age在22、18、20的同学
select * from student where age in(22,18,20);
select * from student where age = 22 or age = 18 or age = 20;
-- 查询英语成绩为null的同学
select * from student where english is null;
-- 查询英语成绩不为null的同学
select * from student where english is not null;
/*
like 模糊查询
占位符:
_ :单个任意字符
% :多个任意字符
*/
-- 查询姓马的同学
select * from student where name like '马%';
-- 查询第二个字是化的人
select * from student where name like '_化%';
-- 查询姓名是三个字的人
select * from student where name like '___';
-- 查询姓名中包含德的人
select * from student where name like '%德%';
排序查询
语法:order by 子句
select * from student order by 排序字段1 排序方式1 , 排序字段2 排序方式2;
排序方式:
ASC:升序,默认的DESC:降序
注意:如果有多个排序条件,则当前面的条件值一样时,才会判断第二条件。
-- 升序排列数学成绩
select * from student order by math ;
select * from student order by math asc;
-- 降序排列数学成绩
select * from student order by math desc;
-- 升序排列数学成绩,如果数学成绩一样,则升序排列英语成绩
select * from student order by math asc , english asc;
聚合函数
聚合函数就是:将一列数据作为一个整体,进行纵向计算。
常用的聚合函数有:
count:计算个数
1、一般选择非空的列:主键
2、count(*)max:计算最大值min:计算最小值sum:计算和avg:计算平均值
注意:聚合函数的计算,排除null值,有两个解决方法:1、选择不包含非空的列进行计算;2、IFNULL函数
-- name的个数
select count(name) from student;
-- 计算english的个数
select count(english) from student;
-- 不排除非空
select count(ifnull(english,0)) from student;
-- 计算数学成绩最大值
select max(math) from student;
-- 计算数学成绩最小值
select min(math) from student;
-- 计算英语成绩和
select sum(english) from student;
-- 计算数学成绩平均分
select avg(math) from student;
分组查询
语法:group by 分组字段;
注意:
- 分组之后查询的字段:分组字段、聚合函数
where和having的区别?
1、where在分组之前进行限定,如果不满足条件,则不参与分组。having在分组之后限定,如果不满足结果,则不会被查询出来
2、where后不可以跟聚合函数,having可以进行聚合函数的判断
-- 按照性别分组,分别查询男、女同学的数学平均分
select sex,avg(math) from student group by sex;
-- 按照性别分组,分别查询男、女同学的数学平均分、人数
select sex,avg(math),count(id) from student group by sex;
-- 按照性别分组,分别查询男、女同学的数学平均分、人数,要求:分数低于70分的人,不参与分组
select sex,avg(math),count(id) from student where math>70 group by sex;
-- 按照性别分组,分别查询男、女同学的数学平均分、人数,要求:分数低于70分的人,不参与分组,分组之后,人数要大于等于2个人
select sex,avg(math),count(id) from student where math>70 group by sex having count(id) >= 2;
分页查询
语法:limit 开始的索引 , 每页查询的条数
公式:开始的索引 = (当前页码 - 1)* 每页的条数
注意:limit是一个MySQL方言
-- 每页显示3条记录
select * from student limit 0,3; -- 第一页
select * from student limit 3,3; -- 第二页
select * from student limit 6,3; -- 第三页
4、数据控制语言 DCL
DCL全称Data Control Language,他是专门用来管理数据库用户的
管理用户
%表示可以在任意主机使用用户登陆数据库
1、添加用户
create user '用户名'@'主机名' identified by '密码';
2、删除用户
drop user '用户名'@'主机名';
3、修改用户密码
update user set password = password('新密码') where user = '用户名';
set password for '用户名'@'主机名' = password('新密码');
4、查询用户
#切换到 mysql 数据库
use mysql;
#查询 user 表
select * from user;
权限管理
1、查询权限
show grants for '用户名'@'主机名';
2、授予权限
grant 权限列表 on 数据库名.表名 to '用户名'@'主机名';
#授予所有权限
grant all on *.* to '用户名'@'%';
3、撤销权限
revoke 权限列表 on 数据库名.表名 from '用户名'@'主机名';
三、约束
约束:对表中的数据进行限定,保证数据的正确性、有效性和完整性。
分类如下表所示:
| 约束 | 关键字 |
|---|---|
| 主键约束 | primary key |
| 非空约束 | not null |
| 唯一约束 | unique |
| 外键约束 | foreign key |
非空约束: 值不能空
-- 创建表时添加约束条件
create table stu(
int id,
name varchar(20) not null; -- 添加非空约束
);
-- 删除name的非空约束
alter table stu modify name varchar(20);
-- 添加name的非空约束
alter table stu modify name varchar(20) not null;
唯一约束: 值不能重复
-- 创建表时添加唯一约束
create table if not exists stu(
int id;
phone_number varchar(20) unique;
);
-- 删除phone_number的唯一约束
alter table stu drop index phone_number;
-- 添加phone_number的唯一约束
alter table stu modify phone_number varchar(20) unique;
主键约束: 非空且唯一,一张表只能有一个字段为主键,是表中记录的唯一标识
-- 创建表时添加主键约束
create table if not exists stu(
id int primary key, -- 给id字段添加主键约束
name varchar(20)
);
-- 删除主键约束
alter table stu drop primary key;
-- 添加主键约束
alter table stu modify id int primary key;
-- 删除表
drop table stu;
-- 添加主键约束的自动增长
create table if not exists stu(
id int primary key auto_increment,
name varchar(20)
);
-- 删除自动增长
alter table stu modify id int;
-- 添加自动增长
alter table stu modify id int auto_increment;
注意:自动增长是根据上一条记录增长值的。
外键约束: 让表与表之间产生联系,从而保证数据正确性
在创建表的时候,可以添加外键:
create table 表名(
....
外键列,
constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称)
);
删除外键:
alter table 表名 drop foreign key 外键名称;
创建表之后,添加外键
alter table 表名 add constraint 外键名称 foreign key (外键字段名称) references 主表名称(主表列名称);
级联操作(更新或删除主表数据,从表也会相应改变):
级联分类:
- 级联更新:
on update cascade - 级联删除:
on delete cascade
也可以同时设置
语法:
alter table 表名 add constraint 外键名称
foreign key (外键字段名称) references 主表名称(主表列名称)
on update cascade
on delete cascade;
演示:
use college;
-- 外键约束
-- 创建部门表(id,dep_name,dep_location)
-- 一方,主表
create table department(
id int primary key auto_increment,
dep_name varchar(20),
dep_location varchar(20)
);
-- 创建员工表(id,name,age,dep_id)
-- 多方,从表
create table employee(
id int primary key auto_increment,
name varchar(20),
age int,
dep_id int, -- 外键对应主表的主键
constraint emp_dep_fk foreign key (dep_id) references department(id)
);
-- 添加两个部门
insert into department values (null,'研发部','广州'),(null,'销售部','深圳');
select * from department;
-- 添加员工,dep_id表示员工所在部门
insert into employee (name,age,dep_id) values
('张三',20,1),
('李四',21,1),
('王五',20,1),
('老王',20,2),
('小王',22,2),
('大王',18,2);
-- 删除外键
alter table employee drop foreign key emp_dep_fk;
-- 添加外键
alter table employee add constraint emp_dep_fk foreign key (dep_id) references department(id);
-- 设置外键 级联更新与级联删除
alter table employee add constraint emp_dep_fk
foreign key (dep_id) references department(id)
on update cascade
on delete cascade;
四、多表查询
首先创建两张表,准备一下数据:
create database if not exists db2;
use db2;
-- 新建部门表
create table dept(
id int primary key auto_increment,
name varchar(20)
);
-- 新建员工表
create table emp(
id int primary key auto_increment,
name varchar(10),
gender char(1), -- 性别
salary double, -- 工资
join_date date, -- 入职日期
dept_id int,
foreign key (dept_id) references dept(id) -- 外键,管不部门表的主键
);
-- 插入数据
insert into dept values (null,'开发部'),(null,'市场部'),(null,'财务部');
insert into emp values
(null,'孙悟空','男',7200,'2013-02-24',1),
(null,'猪八戒','男',3600,'2010-12-02',2),
(null,'唐僧','男',9000,'2006-08-08',2),
(null,'白骨精','女',5000,'2015-10-07',3),
(null,'蜘蛛精','女',4500,'2011-03-14',1);
内连接查询
#隐式内连接查询
-- 查询所有员工信息和对应部门信息
select * from emp,dept where emp.dept_id = dept.id;
-- 查询员工表的名称,性别,部门表的名称
select emp.name,emp.gender,dept.name from emp,dept where emp.dept_id = dept.id;
-- 规范写法
select
t1.name, -- 员工表姓名
t1.gender, -- 员工表性别
t2.name -- 部门表名称
from
emp t1, -- 员工表
dept t2 -- 部门表
where
t1.dept_id = t2.id;
#显式内连接查询
select * from emp inner join dept on emp.dept_id = dept.id;
select * from emp join dept on emp.dept_id = dept.id; -- inner可以省略
外连接查询
#左外连接:查询左表所有数据及其交集部分
-- 查询所有员工信息,如果员工有部门,则查询部门名称,没有部门,则不显示部门名称
select
t1.*,t2.name
from
emp t1
left join dept t2 on t1.dept_id = t2.id
#右外连接:查询右表所有数据及其交集部分
select
t1.*,t2.name
from
emp t1
right join dept t2 on t1.dept_id = t2.id;
子查询
#子查询:查询中嵌套查询,称为嵌套的查询为子查询
-- 查询工资最高的员工信息
select * from emp where emp.salary = (select max(emp.salary) from emp);
-- 查询员工工资小于平均工资的人
select * from emp where emp.salary < (select avg(emp.salary) from emp);
-- 查询财务部和市场部所有员工信息
select * from emp where emp.dept_id in (select dept.id from dept where dept.name in ('财务部','市场部'));
-- 查询员工的入职日期是2011-11-11之后的员工信息和部门信息
select * from dept t1,(select * from emp where emp.join_date > '2011-11-11') t2 where t1.id = t2.dept_id;