简单的Hash函数介绍
在进入Merkle树之前,先简单地介绍一下哈希函数。假设有下面的哈希函数:
其中, 是一个定长的数值,作为输入 和 的哈希值。 的特点是,如果 或者 中有一个值发生了变化,那么它的数值将会与原来完全不一致,而且这种不一致的变化是没有任何规律可言的。同时,我们也不可能根据 的值反推出 和 的数值。哈希函数的特点保证了对于任意的两个输入组合,都有唯一的输出数值与之对应,这个特性可以用于校验输入函数参数的性质。
Merkle树的基本架构
Merkle树一般是一个满二叉树,当然,某些情况下也可以是
叉的。一棵Merkle树的结构如下:
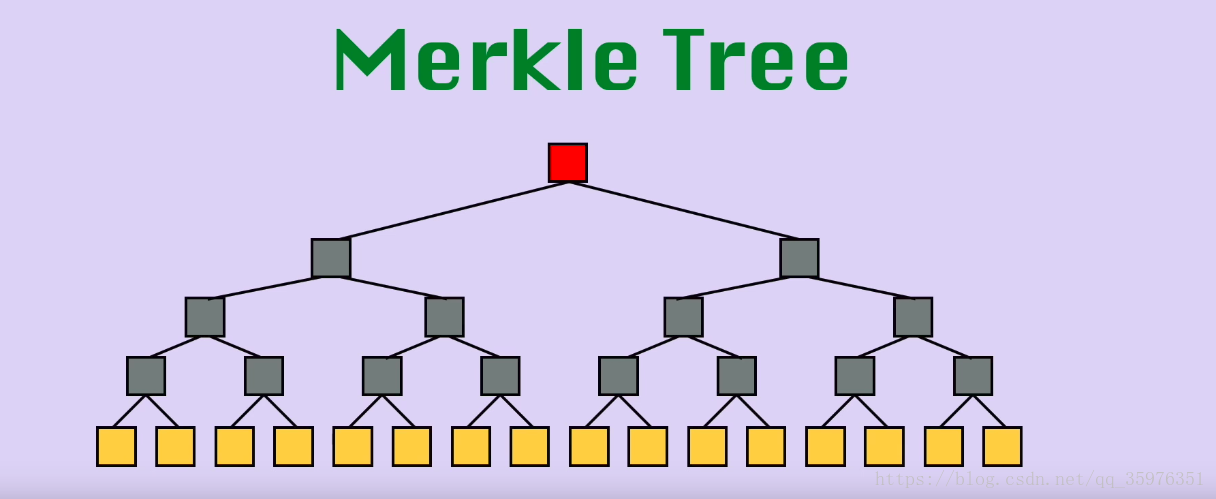
红色的是根结点,灰色的是非叶子结点,黄色的是叶子结点。叶子结点的数值是直接根据数据块的值与0作为参数,经过Hash运算得来的,而灰色结点的值是以两个孩子结点的hash值作为输入,经过Hash运算得来的。
下面给出一棵简单的教程:
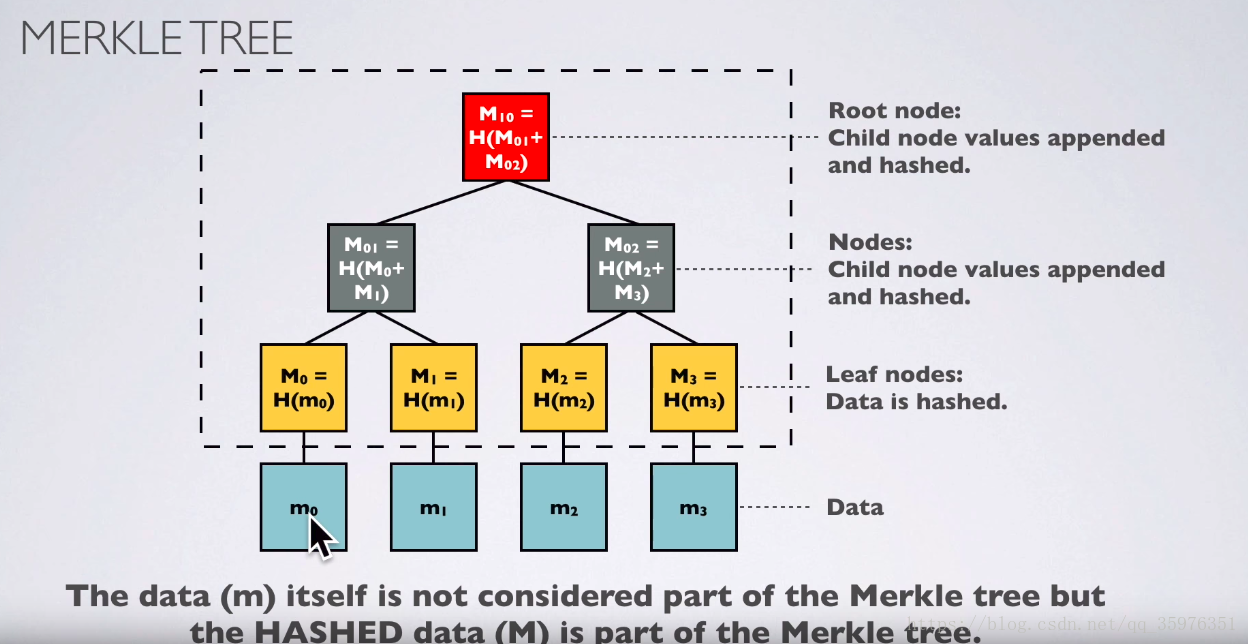
不过,这里的Hash函数与我们介绍的有一些差异。图片中使用了孩子结点哈希值之和作为输入,而我们不进行求和,直而是直接输入两个孩子结点的参数。把图中叶子结点的哈希函数改成:
非叶子结点哈希函数改成:
其中 是该结点的两个孩子, 是两个孩子的哈希值。
如果出现需要处理的数据块是奇数个,只需要把这些数据块中的任意一个复制一份凑成偶数个就行,一般选择复制最后一个块。
综上可知,一棵Merkle树有如下特点:
- 叶子结点的值是实际数据块的Hash值。
- 每个非叶子结点的值,都是孩子结点的Hash值。根结点称为Merkle根
- 如果树是二叉树的话,称为二叉Merkle树,且二叉Merkle树一定是满二叉树(奇数叶子凑成偶数个)
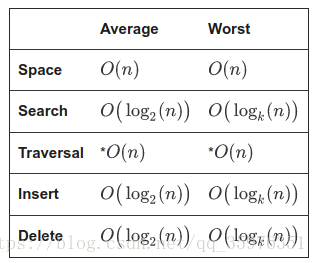
给出复杂度的一些性质:
Merkle树的优势
很自然的,我们会想到一个问题,为什么使用Merkle树,而不是直接把所有叶子结点经过一次Hash计算之后,直接给出结论?比如像上面的介绍图中,共有16个叶子结点,那么总共需要进行16次Hash运算即可:
用图表示为:

而如果使用Merkle树的话,会经过32次的哈希运算,这似乎与我们的常识不符合。
设想下面的一个场景:
A以上面的图片的形式给B发送了一个处理完的Hash数据,就是上面的那个红色Root数据。现在A同学要向B同学证明
的数据没有被更改过,那么A需要向B发送
到
的所有数据,B需要把这些数据重新进行Hash运算才可以验证数据的正确性。显然,上面操作的复杂度是
。虽然在第一次加密的时候运算简单了,但是给后期验证带来计算的麻烦。而在实际的区块链中,系统进行验证的次数要远远多于加密运算,因此这不是一个好的方式。
然后我们再来看使用Merkle树的优势:
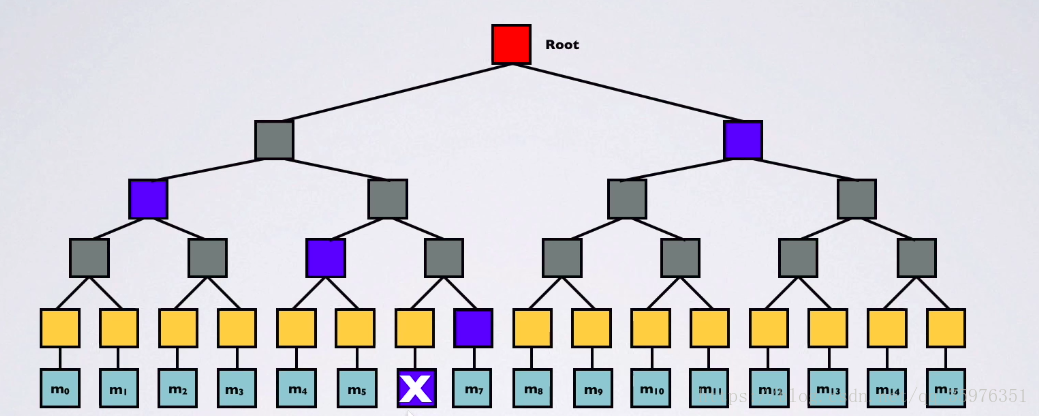
同样是进行
的数据验证,A仅需要给B发送图中蓝色的结点即可。在二叉树的情况下,它的计算复杂度仅仅是
,
是数据块的个数,因此把验证数据的复杂度从线性时间降低到了对数时间。同时,由于验证数据集的简化,我们还可以节约出大量的内存空间。综上所述,我们使用Merkle树这种结构来组织区块链的有关数据。
