Oracle读书笔记2:内存体系结构
内存结构概述
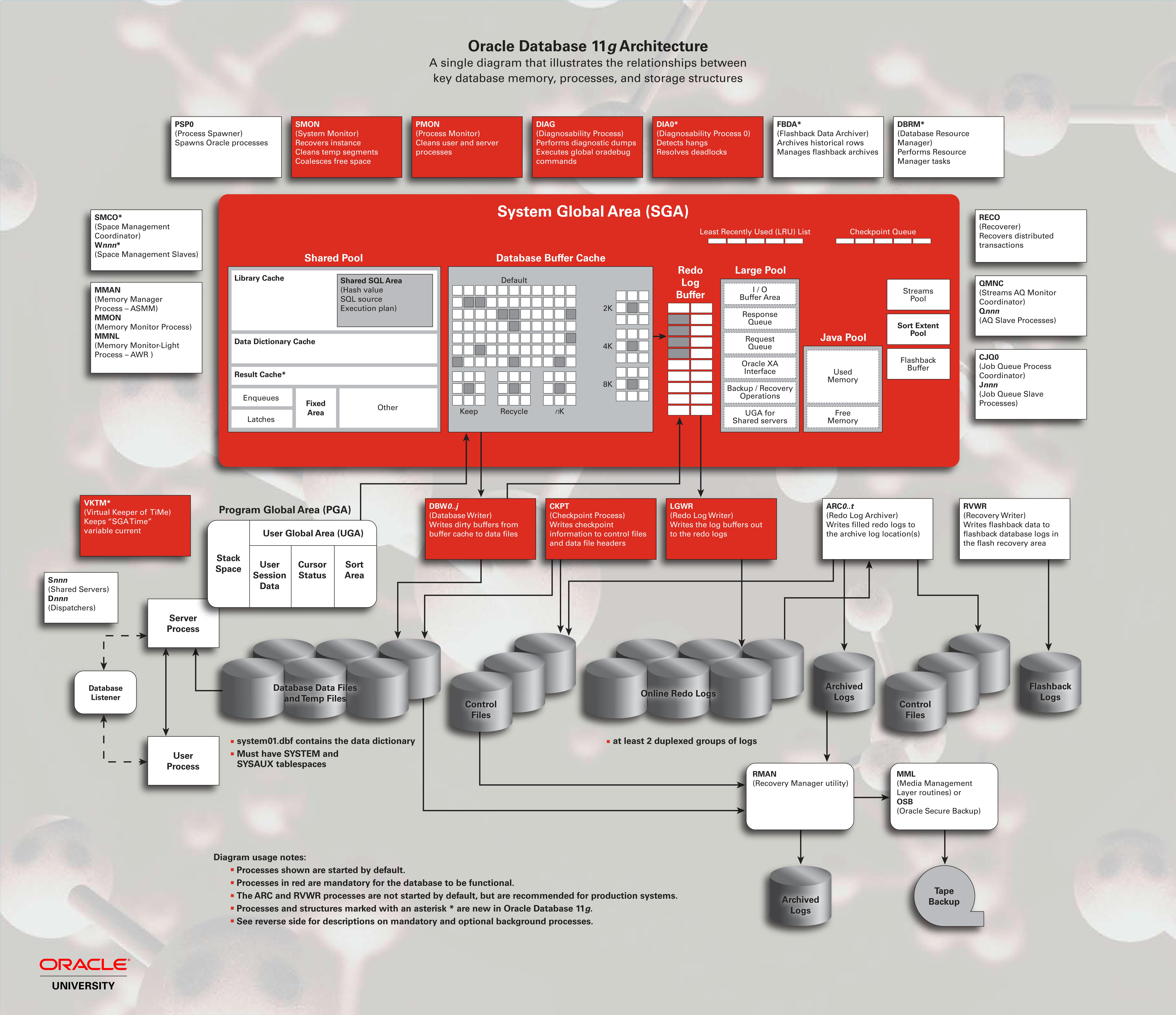
先放一张官方的体系结构图
SGA包含:数据库缓冲区缓存(Database Buffer Cache)
日志缓冲区(Redo Log Buffer)
共享池(Shared Pool)
这三个是必需的
大池(Large pool)
Java池(Java pool)
流池(stream pool)
这三个是可选的
此外,从图中可知SGA还包括了LRU list、Checkpoint Queue,Flashback Buffer、Sort Extent Pool
一.数据库缓冲区缓存(Database buffer cache)
DB buffer cache是Oracle用来执行SQL的工作区域,在更新数据时,用户的会话不直接更新磁盘上的数据。包含关键数据的数据块首先复制到数据库缓冲区缓存,更改应用于数据库缓冲区缓冲中这些数据库的副本。此后,块将在缓存中保留一段时间,直至其占有的缓冲区需要缓存另一个块为止。
在查询数据时,Oracle用户进程第一次需要特定数据时,将会先从DB buffer cache中搜索获取。如果该进程找到数据(称为高速缓存命中),则直接从内存中读取数据;如果没有找到数据(高速缓存未命中),则会话计算出哪些块包含关键的行,并将它们复制到DB buffer cache。此后,相关行传输到会话的PGA作进一步处理。与上面一样,此后块会在数据库缓冲区缓存中保留一段时间。
数据文件的格式被设置为固定大小的块。表行和其他数据对象存储在块中,根据块的大小和行的大小,每个块中可能有多个行,也可能有一个行延伸到多个块中。
注意:缓冲区的更新频率(或COMMIT的数量)与何时写回数据文件没有任何关系,对数据文件执行写操作由数据库写入器后台进程完成,数据库缓冲区缓存在实例启动时分配。
可以动态调整数据库缓冲区缓存的大小,也可以对其进行自动管理
free/unused:buffer cache初始化时或执行了alter system flush buffer_cache,这种状态下的buffer中没有存放任何数据
clean:从数据文件中读取的block还没有被修改,或者是dbwr将脏块写入数据文件,这两种情况下,buffer中的内容与数据文件中的block一致,也就是缓冲区中包含数据块的一致性读(CR)快照
dirty:buffer中的内容跟数据文件中block中的内容不一致,当块第一次复制到缓冲区中时,缓冲区是“干净缓冲区”,此时,缓冲区中的块的映像与磁盘上的块映像是相同的,当其中的块更新时,缓冲区将变脏。最终,脏缓冲区必须写回到数据文件,此时的缓冲区又变干净了
pinned:buffer当前被某个进程正在读取或修改
二.重做日志缓冲区(Redo log buffer)
日志缓冲区是小型的、用于短期存储将写入到磁盘上的重做日志的变更向量的临时区域
会话服务器进程不将重做记录直接写入重做日志文件,否则每当执行DML语句时,会话将不得不等待磁盘I/O,相反,会话将重做记录写入内存的日志缓冲区,此后,LGWR触发时,日志缓冲区写出到重做日志文件。因此,日志缓冲区对磁盘的一次写入是来自多个事务的一批变更向量。
日志缓冲区是一个循环缓冲区(环形)
Redo log buffer的工作流程大致如下
事务执行DML,重做记录写入log buffer,到缓冲区的1/3,内存就会被LGWR把记录刷走到磁盘里,然后被刷走的记录将会被新的记录覆盖。
不可设置小于默认值的日志缓冲区,如果尝试这么做,则日志缓冲区会被设置为默认大小
不建议设置大于默认值的日志缓冲区,这样做意味着在COMMIT时,需要写入到磁盘的内容更多,完成提交的时间跟会话恢复工作所耗费的时间更长
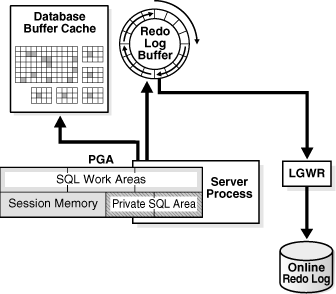
日志缓冲区在启动实例时分配,大小固定不变,如果不重新启动实例,就不能在随后调整其大小,且无法对其进行自动管理。在活动高峰时刻,变更向量的生成速度可能高于日志写入器的写出速度,如果发生这种情况,在日志写入器清理缓冲区时,所有的DML将停止数毫秒,因此DML的速度不能超过LGWR将变更向量转储到联机重做日志文件的速度,如果重做生成是限制数据库性能的因素,唯一的选项是使用RAC,因为每个实例都有自己的日志缓冲区和LGWR,这样就可以将重做数据并行写入磁盘
三.共享池(shared pool)
共享池主要包括4个组件:
库缓存
数据字典高速缓存
服务器结果缓存
保留池
共享池的大小是动态的,可以对其进行自动管理
1.库缓存
库缓存用于分析SQL语句及存储可执行的SQL或PL/SQL代码,该缓存包含共享SQL区域(Shared SQL Area),以及控制结构,比如锁和库缓存句柄。在共享服务器体系结构中,库缓存还包含私有SQL区域(Pricate SQL Area)。共享SQL区域中存放着已解析的SQL语句,SQL执行计划以及已解析并编译的PL/SQL程序单元。
当执行SQL语句时,如果该语句的解析存在于库缓存中并且可以共享,那么数据库将重用这段代码,称为软解析或库缓存命中,否则,数据库必须对该语句进行解析,计算出它的含义以及执行方法,比如from后面跟的是表还是视图?表中有哪些列?用户是否有权限查看该表,这些都需要查询数据字典得到答案。在了解语句的真实含义后,服务器将生成执行计划,以最佳的方式执行它。这样的解析过程被称为是硬解析或库缓存未命中。
实际情况中应尽量避免大量的硬解析,因为数据库对新的SQL语句进行语法分析时,会从共享池中分配内存,该内存的大小取决于语句的复杂程度。Oracle使用共享SQL区域来处理SQL语句,所有用户都可以访问该区域,而Oracle可以识别两个用户执行相同SQL语句的情况,从而这些用户可以使用相同的执行计划。
数据库处理程序单元跟处理SQL语句很相似,数据库会分配一块共享区域来存放PL/SQL程序解析并编译后的形式,分配一块专用区域来保存特定于运行程序单元的会话的值,包括本地、全局和程序包变量以及执行SQL的缓冲区。如果多个用户运行相同的程序时,每个用户都会被分配一块单独的专用SQL区域副本,该区域存储会话特定的值,并访问同一块共享SQL区域。
2.数据字典高速缓存
该缓存保存最近使用的数据库对象的定义:表、索引、用户和其他元数据定义的描述,也被称为行缓存因为它是以行的形式存储数据而不是以缓冲区的形式
3.服务器结果缓存
与缓冲池不同,服务器结果缓存保存的是结果集而不保留数据块,服务器结果缓存包含SQL结果缓存和PL/SQL函数结果缓存,它们共享相同的基础结构。假设重复运行相同的语句,如果结果在缓存里,数据库将立即返回它们,通过这样的方式,数据库避免了重复读取块和重新计算结果的操作。但只要事务修改用于构造缓存结果的数据库对象的数据或元数据,数据库就会自动使缓存的结果无效
4.保留池
共享池的内存分配和重用
数据库在分析新的SQL语句时分配共享池内存,内存大小取决于语句的复杂程度。通常共享池中的项目是根据LRU算法来进行删除的,该机制可以最小化SQL语句执行的开销。如果新的项目需要空间,数据库将根据LRU算法来释放内存。
在以下情况下,Oracle也会从共享池中刷新共享SQL区域:
使用DBMS_STATS程序包更新或删除表、集群或索引的统计信息时,将从共享池中刷新所有包含引用了所分析的方案对象的语句的共享SQL区域。下次运行经过刷新的语句时,将在新的共享SQL区域中对该语句进行语法分析。
如果在SQL 语句中引用了某个模式对象,并且随后以任何方式修改了该对象,则共享SQL 区域会失效(被标记为无效),下次运行该语句时必须重新进行语法分析。
如果更改数据库的全局数据库名,则会从共享池刷新所有信息。
通过ALTER SYSTEM FLUSH SHARED_POOL语句来手动刷新共享池。
共享池的大小是动态的,可以对其进行自动管理,也可以随时将其调大或调小
四.大池(Large pool)
大池属于可选内存区域,如果创建了大池,则那些在不创建大池的情况下使用共享池内存的不同进程将自动使用大池。大池的一个主要用途是供共享的服务器进程使用,如并行执行服务器,在缺少大池的情况下,这些进程将使用共享池中的内存,这会导致对共享池的恶性争用。
大池为以下对象提供大型内存分配:
共享服务器的会话内存和Oracle XA 接口(在事务处理与多个数据库交互时使用)
I/O 服务器进程
Oracle DB 备份和还原操作
大池的大小可以动态调整,而且可以自动管理
五.Java池(Java pool)
只有当应用程序需要在数据库中运行Java存储过程时,才需要Java池
注意:Java代码不在Java池中缓存,而是在共享池中缓存,与PL/SQL代码的缓存方式相同
Java池的大小是动态的,而且可以自动管理
六.流池(Stream pool)
流池供Oracle流使用。
流使用的机制是:从重做日志提取变更向量,并使用这些重新构造执行的语句,这些语句在远程数据库进行
从重做日志提取更改的进程以及应用更改的进程将用到流池
流池的大小是动态的,而且可以自动管理