Project 1 - Index file
这个项目呢,是尝试复刻一下数据库中的索引系统,只实现了内存版本的BPTree,索引文件并未建立成功(本博客持续更新ing)
文章目录
1.Abstract
The B+ tree index is an implementation of the B+ tree in the database, and is the most common and frequently used index in the database. So we are going to design an index file using B+ tree
2.Tasks Requirements


3.Design plan
3.1 Tasks TODO
We need to design a index file system, which use the B+ -tree. And it could count something.
- read the excel file
- search and count the item by traverse the file
- build the B+ tree
- I/O of B+ tree
- sync
3.2 Task schedule
- get Clear of out task
- install pip
- review B and learn B+ tree
- read the excel file
- search and count items by traverse the file
- build the B+ tree
- I/O of B+ tree
- sync
4.Outline Design
4.1 System Architecture Design
digraph hierarchy {
nodesep=1.0 // Increases the separation between nodes
node [color=Red,fontname=Courier,shape=box] // All nodes will this shape and colour
edge [color=Purple, style=dashed] // All the lines look like this
Index_File->{File_Traverse BP_Tree Extra_Func}
BP_Tree->{ConstructBPTree useItToCount IOofBPTree}
Extra_Func->{sync}
}
4.2 System functional structure design
4.2.1 File_Traverse
Using python to read the excel, and find the corresponding column, then traverse the whole column to find the corresponding item and count it
4.2.2 BPTree
First we are going to build the BPTree by the corresponding column according to the excel.
Then we are going to use the BPTree to search the items and count.
And we are goint to write the BPTree into the file to store it. Also we are going to read the BPTree file instead of excel due to the efficiency.
4.2.3 Extra_Func
Extra part is about the sync. We need to auto sync the data when we change something.
5.Detailed Design and implementation
5.1 Core technology(BPTree)
5.1.1 Hard disk
When the system reads data from the disk to the memory, it uses the disk block as the basic unit. The data in the same disk block will be read out at one time, rather than what needs to be taken.
The data of the B-Tree structure allows the system to efficiently find the disk block where the data is located.
B+Tree is an optimization based on B-Tree, making it more suitable for implementing external storage index structure.
5.1.2 Structure of BPTree
This is a B-Tree structure and the corresponding disk block structure

Optimize the B-Tree in the previous section. Since the non-leaf nodes of B+Tree only store key value information, assuming that each disk block can store 4 key values and pointer information, the structure after becoming B+Tree is as follows The picture shows:

The B+Tree index in the database can be divided into clustered index and secondary index. The implementation of the above B+Tree example graph in the database is a clustered index, and the leaf nodes in the B+Tree of the clustered index store the row record data of the entire table. The difference between a secondary index and a clustered index is that the leaf node of the secondary index does not contain all the data of the row record, but the clustered index key that stores the corresponding row data, that is, the primary key.
Additional, we need a list to save the repeat data on the leaf node.
5.2 Subsystem design and implementation
File Traverse
- First read the excel file:
def open_EXCEL(fileName):
start = time.clock()
print("Starting Opening "+fileName)
data = xlrd.open_workbook(fileName)
print("workbook opened")
table=data.sheet_by_name('Online Retail')
print("sheet found")
print("You have "+str(table.nrows - 1)+" items")
print("You have "+str(table.ncols)+" attributes")
print("Time used "+ str(time.clock()-start)+" while openning the file")
return table
I also added the timer to record the time when it open the file. And this is the screenshot when it completed:

- Second find the corresponding column and traverse, count
def count_NumberOfItems_By_Traverse(tagName,itemName,table):
print("Starting count "+itemName+" by traverse")
start = time.clock()
numberOfItems = 0
colNum=0
#first find the col number
while (1):
if (table.cell(0,colNum).value == tagName):
print("TAG is on "+str(colNum+1)+"th col")
break
if ((colNum==table.ncols-1) and not(table.cell(1,colNum)==tagName)):
print("TAG(COL) NOT FOUND!")
return 0
colNum=colNum+1
#traverse the column
for rowNums in range(table.nrows):
if table.cell(rowNums,colNum).value==itemName:
numberOfItems = numberOfItems+1
print("There are(is) "+str(numberOfItems)+" "+itemName+" in "+tagName)
print("Time used "+str(time.clock()-start)+" while counting")
return numberOfItems
Also the screenshots here:

BPTree(Memory Version)
The BPTree test result is here:

The struct of BPTree is:

L is the Fill factor, that is the max number of items stored in one leaf node.
M is the degree of the BPTree.
Bptree_leaf is the first leaf of the Tree
Bptree_root is the root node of the Tree
Key_value

class KeyValue(object):
__slots__ = ('key', 'value','item','itemList')
# key is the primary key of the table
# value is the pointer's value
# item is the corresponding item
# itemList is the list of the item(some times it is empty, some times it has values)
def __init__(self, key, value, item):
self.key = key
self.value = value
self.item = item
self.itemList = LeafList.LeafList()
def __str__(self):
return str((self.key, self.value))
def __cmp__(self, key):
if self.key > key:
return 1
elif self.key == key:
return 0
else:
return -1
def insert_into_itemList(self,item):
self.itemList.addItem(item)
def count_itemList(self):
return self.itemList.count()
def showList(self):
self.itemList.showList()
BPTree
The struct of BPTree is:
L is the Fill factor, that is the max number of items stored in one leaf node.
M is the degree of the BPTree.
Bptree_leaf is the first leaf of the Tree
Bptree_root is the root node of the Tree
class Bptree(object):
def __init__(self, M, L): # M为度, L为填充因子
if L > M:
raise InitError, 'L must be less or equal then M'
else:
self.__M = M
self.__L = L
self.__root = Bptree_Leaf(L)
self.__leaf = self.__root
@property
def M(self):
return self.__M
@property
def L(self):
return self.__L
# 查询是否存在某一个item的item.Description 为“item”的项目在BPTree里,此处传入的是item的description
def checkExits(self, item):
if len(self.search(item, item)) == 0:
return False
else:
return True
# 插入一个Item item(在判断出该item存在相应叶子节点后,插入该节点的ITEMLIST)
def insertItem(self, item):
def search_key(n, k):
if n.isleaf():
p = bisect_left(n.vlist, k)
return (p, n)
else:
p = bisect_right(n.ilist, k)
return search_key(n.clist[p], k)
node = self.__root
i,l = search_key(node,item.Description)
if (l.vlist[i] == item.Description):
l.vlist[i].insert_into_itemList(item)
else:
print("Item of "+item.Description+" inserted failed")
#插入一个 key_value,(与上面的insertItem不同,此处是插入一个新的节点)
def insert(self, key_value):
node = self.__root
def split_node(n1):
mid = self.M / 2
newnode = Bptree_InterNode(self.M)
newnode.ilist = n1.ilist[mid:]
newnode.clist = n1.clist[mid:]
newnode.par = n1.par
for c in newnode.clist:
c.par = newnode
if n1.par is None:
newroot = Bptree_InterNode(self.M)
newroot.ilist = [n1.ilist[mid - 1]]
newroot.clist = [n1, newnode]
n1.par = newnode.par = newroot
self.__root = newroot
else:
i = n1.par.clist.index(n1)
n1.par.ilist.insert(i, n1.ilist[mid - 1])
n1.par.clist.insert(i + 1, newnode)
n1.ilist = n1.ilist[:mid - 1]
n1.clist = n1.clist[:mid]
return n1.par
def split_leaf(n2):
mid = (self.L + 1) / 2
newleaf = Bptree_Leaf(self.L)
newleaf.vlist = n2.vlist[mid:]
if n2.par == None:
newroot = Bptree_InterNode(self.M)
newroot.ilist = [n2.vlist[mid].key]
newroot.clist = [n2, newleaf]
n2.par = newleaf.par = newroot
self.__root = newroot
else:
i = n2.par.clist.index(n2)
n2.par.ilist.insert(i, n2.vlist[mid].key)
n2.par.clist.insert(i + 1, newleaf)
newleaf.par = n2.par
n2.vlist = n2.vlist[:mid]
n2.bro = newleaf
def insert_node(n):
if not n.isleaf():
if n.isfull():
insert_node(split_node(n))
else:
p = bisect_right(n.ilist, key_value)
insert_node(n.clist[p])
else:
p = bisect_right(n.vlist, key_value)
n.vlist.insert(p, key_value)
if n.isfull():
split_leaf(n)
else:
return
insert_node(node)
self.insertItem(key_value.item)
# 查找从mi 到 ma之间的数值
def search(self, mi=None, ma=None):
result = []
node = self.__root
leaf = self.__leaf
if mi is None and ma is None:
raise ParaError, 'you need to setup searching range'
elif mi is not None and ma is not None and mi > ma:
raise ParaError, 'upper bound must be greater or equal than lower bound'
def search_key(n, k):
if n.isleaf():
p = bisect_left(n.vlist, k)
return (p, n)
else:
p = bisect_right(n.ilist, k)
return search_key(n.clist[p], k)
if mi is None:
while True:
for kv in leaf.vlist:
if kv <= ma:
result.append(kv)
else:
return result
if leaf.bro == None:
return result
else:
leaf = leaf.bro
elif ma is None:
index, leaf = search_key(node, mi)
result.extend(leaf.vlist[index:])
while True:
if leaf.bro == None:
return result
else:
leaf = leaf.bro
result.extend(leaf.vlist)
else:
if mi == ma:
i, l = search_key(node, mi)
try:
if l.vlist[i] == mi:
result.append(l.vlist[i])
return result
else:
return result
except IndexError:
return result
else:
i1, l1 = search_key(node, mi)
i2, l2 = search_key(node, ma)
if l1 is l2:
if i1 == i2:
return result
else:
result.extend(l.vlist[i1:i2])
return result
else:
result.extend(l1.vlist[i1:])
l = l1
while True:
if l.bro == l2:
result.extend(l2.vlist[:i2 + 1])
return result
else:
result.extend(l.bro.vlist)
l = l.bro
#遍历B+树,输出一个result[]
def traversal(self):
result = []
l = self.__leaf
while True:
result.extend(l.vlist)
if l.bro == None:
return result
else:
l = l.bro
#展示b+树
def show(self):
print 'this b+tree is:\n'
q = deque()
h = 0
q.append([self.__root, h])
while True:
try:
w, hei = q.popleft()
except IndexError:
return
else:
if not w.isleaf():
print w.ilist, 'the height is', hei
if hei == h:
h += 1
q.extend([[i, h] for i in w.clist])
else:
print [v.key for v in w.vlist], 'the leaf is,', hei
#删除节点
def delete(self, key_value):
def merge(n, i):
if n.clist[i].isleaf():
n.clist[i].vlist = n.clist[i].vlist + n.clist[i + 1].vlist
n.clist[i].bro = n.clist[i + 1].bro
else:
n.clist[i].ilist = n.clist[i].ilist + [n.ilist[i]] + n.clist[i + 1].ilist
n.clist[i].clist = n.clist[i].clist + n.clist[i + 1].clist
n.clist.remove(n.clist[i + 1])
n.ilist.remove(n.ilist[i])
if n.ilist == []:
n.clist[0].par = None
self.__root = n.clist[0]
del n
return self.__root
else:
return n
def tran_l2r(n, i):
if not n.clist[i].isleaf():
# 将i的最后一个节点追加到i+1的第一个节点
n.clist[i + 1].clist.insert(0, n.clist[i].clist[-1])
n.clist[i].clist[-1].par = n.clist[i + 1]
# 追加 i+1的索引值,以及更新n的i+1索引值
n.clist[i + 1].ilist.insert(0, n.clist[i].ilist[-1])
n.ilist[i + 1] = n.clist[i].ilist[-1]
n.clist[i].clist.pop()
n.clist[i].ilist.pop()
else:
# 如果 i不空,但是i+1节点为空
# 则将i中的最后一个追加到i+1的第一个中,并刷新n在i+1的索引值
# 上面的逻辑类似
n.clist[i + 1].vlist.insert(0, n.clist[i].vlist[-1])
n.clist[i].vlist.pop()
n.ilist[i] = n.clist[i + 1].vlist[0].key
def tran_r2l(n, i):
if not n.clist[i].isleaf():
n.clist[i].clist.append(n.clist[i + 1].clist[0])
n.clist[i + 1].clist[0].par = n.clist[i]
n.clist[i].ilist.append(n.ilist[i])
n.ilist[i] = n.clist[i + 1].ilist[0]
n.clist[i + 1].clist.remove(n.clist[i + 1].clist[0])
n.clist[i + 1].ilist.remove(n.clist[i + 1].ilist[0])
else:
n.clist[i].vlist.append(n.clist[i + 1].vlist[0])
n.clist[i + 1].vlist.remove(n.clist[i + 1].vlist[0])
n.ilist[i] = n.clist[i + 1].vlist[0].key
def del_node(n, kv):
if not n.isleaf():
p = bisect_right(n.ilist, kv)
if p == len(n.ilist):
if not n.clist[p].isempty():
return del_node(n.clist[p], kv)
elif not n.clist[p - 1].isempty():
tran_l2r(n, p - 1)
return del_node(n.clist[p], kv)
else:
return del_node(merge(n, p), kv)
else:
if not n.clist[p].isempty():
return del_node(n.clist[p], kv)
elif not n.clist[p + 1].isempty():
tran_r2l(n, p)
return del_node(n.clist[p], kv)
else:
return del_node(merge(n, p), kv)
else:
p = bisect_left(n.vlist, kv)
try:
pp = n.vlist[p]
except IndexError:
return -1
else:
if pp != kv:
return -1
else:
n.vlist.remove(kv)
return 0
del_node(self.__root, key_value)
#查看某个itemName 的所有订单
def showList(self,itemName):
print 'list of the '+itemName+' is:\n'
def search_key(n, k):
if n.isleaf():
p = bisect_left(n.vlist, k)
return (p, n)
else:
p = bisect_right(n.ilist, k)
return search_key(n.clist[p], k)
i,l = search_key(self.__root,itemName)
l.vlist[i].showList
#计算ItemList里面一共有多少个项目
def countList(self,itemName):
def search_key(n, k):
if n.isleaf():
p = bisect_left(n.vlist, k)
return (p, n)
else:
p = bisect_right(n.ilist, k)
return search_key(n.clist[p], k)
i, l = search_key(self.__root, itemName)
print ("There are " + str(l.vlist[i].count_itemList()) +" items")
LeafNode & InterNode
RootNode:
clist is for the child nodes of the rootNode. They are all InterNode under this circumstances.
ilist is the indexed designed layer. They stored all the values in the internal node. This is for index search.
And the length of clist is always larger 1 than length of ilist of course.

One InterNode:
The same as rootNode. Because root node is one of the special interNode.

Finally to the LeafNode layer:

LeafNode:
bro is the next leaf node of the leaf
par is the parent node of the leaf
vlist is the value list of the leaf. It stores the KeyValue.

class Bptree_InterNode(object):
def __init__(self, M):
if not isinstance(M, int):
raise InitError, 'M must be int'
if M <= 3:
raise InitError, 'M must be greater then 3'
else:
self.__M = M
self.clist = [] # 如果是index节点,保存 Bptree_InterNode 节点信息
# leaf节点, 保存 Bptree_Leaf的信息
self.ilist = [] # 保存 索引节点
self.par = None #
def isleaf(self):
return False
def isfull(self):
return len(self.ilist) >= self.M - 1
def isempty(self):
return len(self.ilist) <= (self.M + 1) / 2 - 1
@property
def M(self):
return self.__M
class Bptree_Leaf(object):
def __init__(self, L):
if not isinstance(L, int):
raise InitError, 'L must be int'
else:
self.__L = L
self.vlist = []
self.bro = None
self.par = None
def isleaf(self):
return True
def isfull(self):
return len(self.vlist) > self.L
def isempty(self):
return len(self.vlist) <= (self.L + 1) / 2 # 删除的填充因子
@property
def L(self):
return self.__L
BPTree bisect_right and bisect_left
Return the index where to insert item x in list a, assuming a is sorted.
The return value i is such that all e in a[:i] have e <= x, and all e in a[i:] have e > x. So if x already appears in the list, a.insert(x) will insert just after the rightmost x already there. Optional args lo (default 0) and hi (default len(a)) bound the slice of a to be searched.
def bisect_right(a, x, lo=0, hi=None):
if lo < 0:
raise ValueError('lo must be non-negative')
if hi is None:
hi = len(a)
while lo < hi:
mid = (lo + hi) // 2
if x < a[mid]:
hi = mid
else:
lo = mid + 1
return lo
def bisect_left(a, x, lo=0, hi=None):
if lo < 0:
raise ValueError('lo must be non-negative')
if hi is None:
hi = len(a)
while lo < hi:
mid = (lo + hi) // 2
if a[mid] < x:
lo = mid + 1
else:
hi = mid
return lo
Some Errors
class InitError(Exception):
pass
class ParaError(Exception):
pass
BPTree(File Version)
NOT IMPLEMENTED YET
Sync
NOT IMPLEMENTED YET
Comparision of traverse and BPTree search


6.Read the PostgreSQL and understand
I read the PG source code. And found the index part, here are some of my understandings:
The index types provided by PostgreSQL are, B-Tree, hash, gist and gin. And by default, it will construct the B-tree.
digraph hierarchy {
nodesep=1.0 // Increases the separation between nodes
node [color=Red,fontname=Courier,shape=box] // All nodes will this shape and colour
edge [color=Purple, style=dashed] // All the lines look like this
Index->{B_tree Hash gist gin}
}
B-tree
Default index of PostgreSQL.
PostgreSQL B-Tree is a changed version of (high-concurrency B-tree management algorithm),
PostgreSQL的B-tree分为集中类别

其中meta page和root page是必须有的,meta page需要一个页来存储,表示指向root
page的page id。
我们可以使用pageinspect插件,内窥B-Tree的结构。
层次可以从bt_page_stats的btpo得到,代表当前index page所处的层级。
随着记录数的增加,一个root page可能存不下所有的heap item,就会有leaf page,甚
至branch page,甚至多层的branch page。
一共有几层branch 和 leaf,就用btree page元数据的 level 来表示。

0层结构
0层结构,只有meta和root页。
root页最多可以存储的item数,取决于索引字段数据的长度、以及索引页的大小。

SQL语句:
postgres=# create extension pageinspect;
postgres=# create table tab1(id int primary key, info text);
CREATE TABLE
postgres=# insert into tab1 select generate_series(1,100), md5(random()::text);
INSERT 0 100
postgres=# vacuum analyze tab1;
VACUUM
查看meta page,可以看到root page id = 1 。
索引的level = 0, 说明没有branch和leaf page。

1层结构
1层结构,包括meta page, root page, leaf page
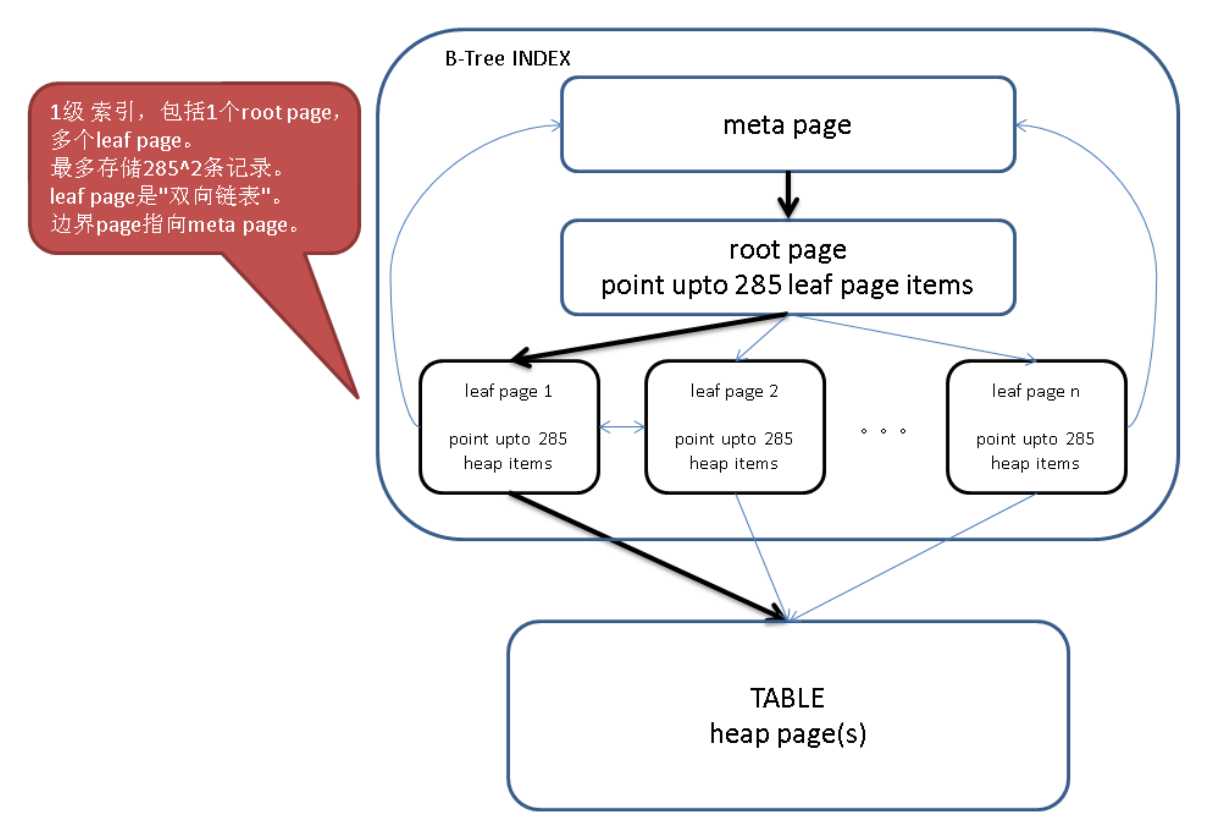
SQL语句:
postgres=# truncate tab1;
TRUNCATE TABLE
postgres=# insert into tab1 select generate_series(1,1000), md5(random()::text);
INSERT 0 1000
postgres=# vacuum analyze tab1;
VACUUM
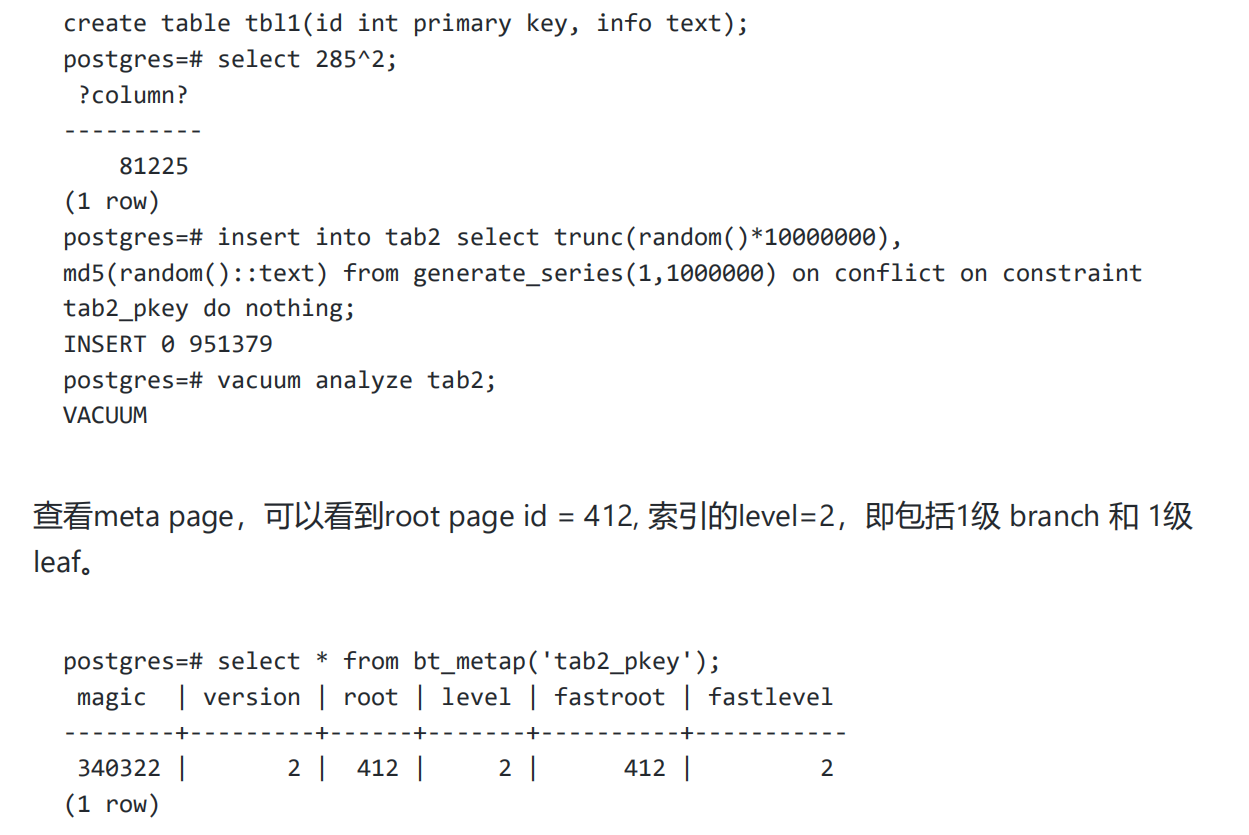
查看meta page,可以看到root page id = 3, 索引的level = 1。
level = 1 表示包含了leaf page。

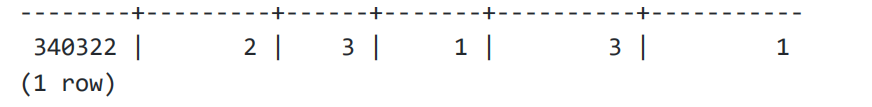
2层结构
记录数超过1层结构的索引可以存储的记录数时,会分裂为2层结构,除了meta page和
root page,还可能包含1层branch page以及1层leaf page。
如果是边界页(branch or leaf),那么其中一个方向没有PAGE,这个方向的链表信息都统
一指向meta page。

Hash index
The hash index can only handle simple equality comparisons. When an indexed column involves the use of = operator for comparison, the query planner will consider the use of hash index.
Hash index operations currently do not record WAL-log, so if there are no write changes, the Hash index may need to be rebuilt with REINDEX after the database crashes. In addition, after the initial basic backup, changes to the Hash index are not replicated through streaming or file-based replication, so they give wrong answers to subsequent queries that use them. For these reasons, the use of Hash indexes is currently discouraged.
Gist index
The gist index is not a single index type, but an architecture on which many different indexing strategies can be implemented. Therefore, the specific operator types that can be indexed by gist are highly dependent on the indexing strategy (operator class)
GiST index is not a single index, but an infrastructure that can implement many different indexing strategies. Therefore, the specific operators that can use the GiST index vary according to the indexing strategy (operator class).
Gin index
GIN index is an inverted index, which can handle values containing multiple keys (such as arrays). Similar to gist, gin supports user-defined indexing strategies, and the specific operator types that can use GIN indexes vary according to the indexing strategies.
7.Index usecase in PostgreSQL
基本语法:
create [unique |fulltext |spatial] index index_name on table_name (col_name[length],…) [ ASC | DESC ]
1、创建普通索引:B-tree索引
create index idx_contacts_name on contacts(name);
–创建唯一索引:
create unique index idx_emp on emp(id);
–创建组合索引:
create index idx_emp on emp(id,name);
2、数组索引
create index idx_contacts_phone on contacts using gin(phone);
注:phone在contacts表中是一个数组类型
3、降序索引
create index idx_contacts_name on contacts(name desc);
4、指定存储参数
create index idx_contacts_name on contacts(name) with(fillfactor=50);
注:fillfactor是常用的存储参数
5、指定空值排在前面
create index idx_contacts_name on contacts(name desc nulls first);
6、避免创建索引的长时间阻塞,可以在index关键字后面增加concurrently关键字,可以减少索引的阻塞时间
create index concurrently idx_contacts_name on contacts(name desc);
注意,重建索引时不支持concurrently ,可以新建一个索引,然后删除旧索引,另外并发索引被强制取消,可能会留下无效索引,这个索引将会导致更新变慢,如果是唯一索引,还会导致插入重复值失败。
7、修改索引
索引重命名:alter index name rename to new_name;
设置表空间:alter index name set tablespace tablespace_name;
设置存储参数:alter index name set(storage_parameter=value[,…])
重设存储参数:alter index name reset(storeage_parameter[,…])
8、删除索引
drop index if exists idx_emp;
9、cascade会把索引和依赖索引的对象全部删除
8.Conclusion
-
索引并非越多越好。如果一个表中有大量的索引,那么不仅会占用大量磁盘空间,还会影响:insert、delete、update等语句的性能,因为更改表中的数据时,索引也会进行调整和更新。
-
避免对经常更新的表进行过多索引,并且索引中的列要尽可能少。对经常用于查询的字段应该创建索引,但要避免添加不必要的字段。
-
数据量小的表最好不要使用索引。数据较少时,查询花费的时间可能比遍历索引的时间还要短,索引可能不会产生优化效果。
-
在条件表达式中经常用到的不同值较多的列上建立索引,在不同值少的列上不要建立索引。
-
当唯一性是某种数据本身的特征时,指定唯一索引。使用唯一索引能够确保定义的列的数据完整性,提高查询速度。
-
频繁进行排序或分组(进行group by或order by操作)的列上建立索引。如果待排序的列有多个,可以在这些列上建立组合索引