实现原理
在复制算法中,回收器将堆空间划分为两个大小相等的半区 (semispace),分别是 **来源****空间(fromspace) **和 **目标空间(tospace) **。在进行垃圾回收时,回收器将存活对象从来源空间复制到目标空间,复制结束后,所有存活对象紧密排布在目标空间一端,最后将来源空间和目标空间互换。半区复制算法的概要如下图所示。
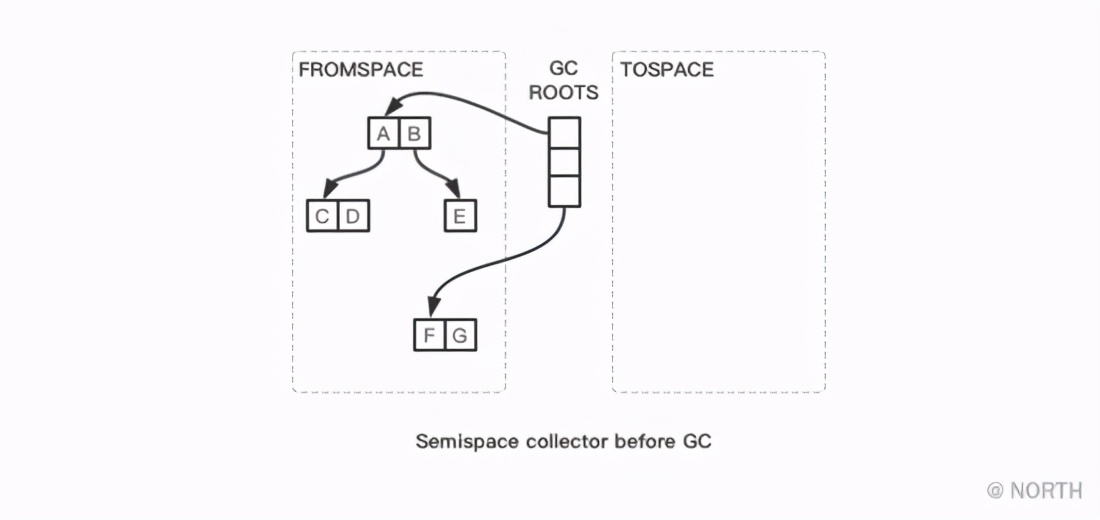
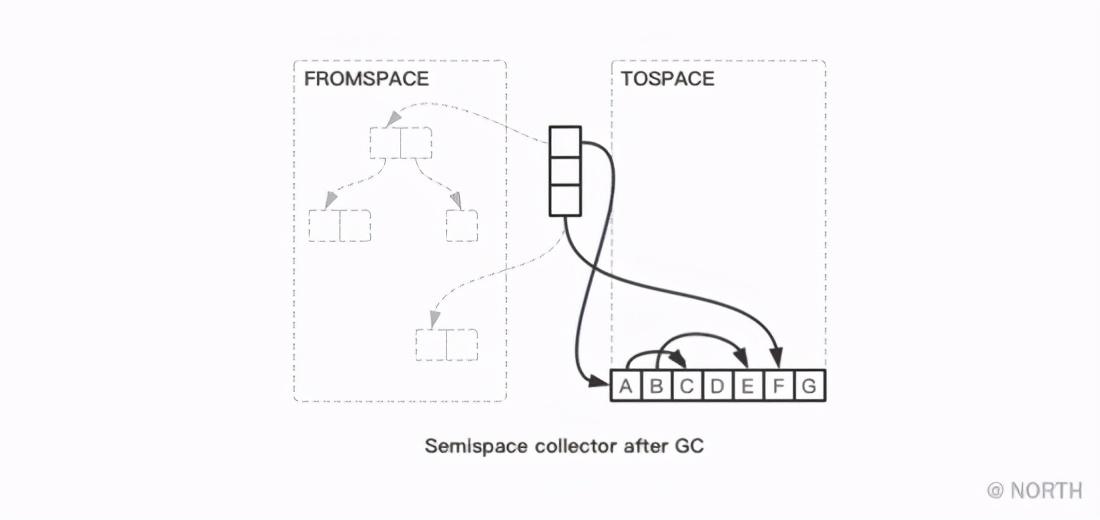
接下来看下代码如何实现?主要流程很简单,有一个 free 指针指向TOSPACE的起点,从根节点开始遍历,将根节点及其引用的子节点全部复制到TOSPACE,每复制一个对象,就把 free指针向后移动相应大小的位置,最后交换FROMSPACE和TOSPACE,大致可用如下代码描述:
collect() {
// 变量前面加*表示指针
// free指向TOSPACE半区的起始位置
*free = *to_start;
for(root in Roots) {
copy(*free, root);
}
// 交换FROMSPACE和TOSPACE
swap(*from_start,*to_start);
}
核心函数 copy 的实现如下所示:
copy(*free,obj) {
// 检查obj是否已经复制完成
// 这里的tag仅是一个逻辑上的域
if(obj.tag != COPIED) {
// 将obj真正的复制到free指向的空间
copy_data(*free,obj);
// 给obj.tag贴上COPIED这个标签
// 即使有多个指向obj的指针,obj也不会被复制多次
obj.tag = COPIED;
// 复制完成后把对象的新地址存放在老对象的forwarding域中
obj.forwarding = *free;
// 按照obj的长度将free指针向前移动
*free += obj.size;
// 递归调用copy函数复制其关联的子对象
for(child ingetRefNode(obj.forwarding)){
*child = copy(*free,child);
}
}
returnobj.forwarding;
}
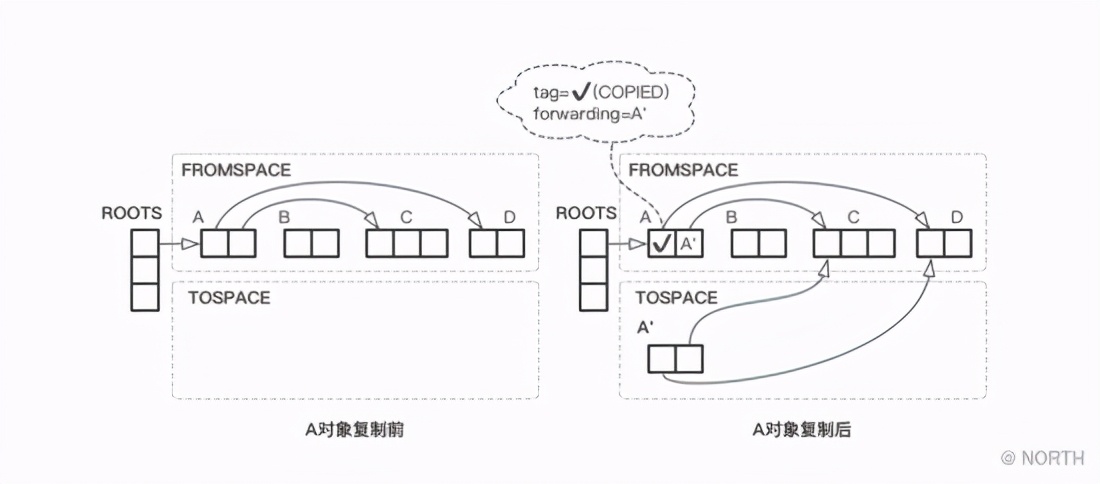
在这段代码中需要注意两个问题,其一是 tag=COPIED 只是一个逻辑上的概念,用来区分对象是否已经完成复制,以确保即使这个对象被多次引用,也仅会复制一次;另外一个问题则是 forwarding 域, forwarding指针 在前面已经多次提到过,主要是用来保存对象移动后的新地址,比如在标记整理算法中,对象移动后需要遍历更新对象的引用关系,就需要使用 forwarding指针 来查找其移动后的地址,而在复制算法中,其作用类似,如果遇到已复制完成的对象,直接通过forwarding域把对象的新地址返回即可。整个复制算法的基本致流程如下图所示。
接下来用一个详细的示例看看复制算法的大致流程。堆中对象的关系如下图所示,其中free指针指向TOSPACE的起点位置。
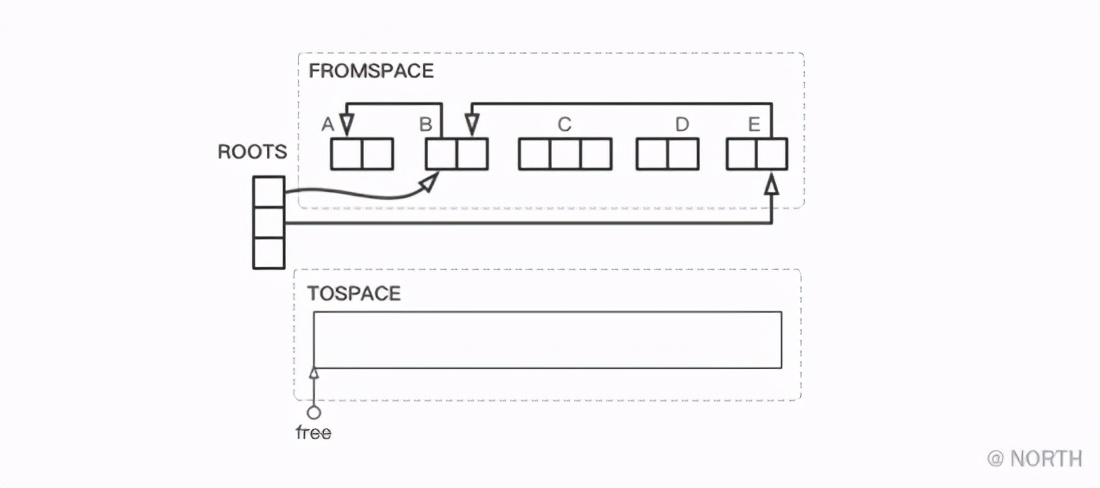
首先,从根节点出发,找到它直接引用的对象B和E,其中对象B首先被复制到TOSPACE。B被复制后的堆的关系如下图所示。
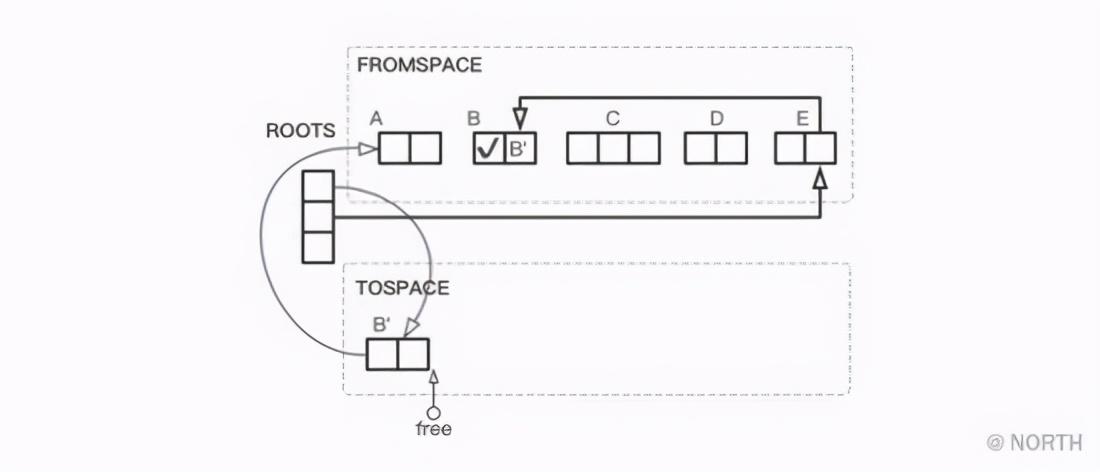
这里将B被复制后生成的对象成为B’,而原来的对象B中 tag 域已经打上复制完成的标签,而 forwarding指针 也存放着B’的地址。
对象B复制完成后,它引用的对象A还在FROMSPACE里,接下来就会把对象A复制到TOSPACE中。
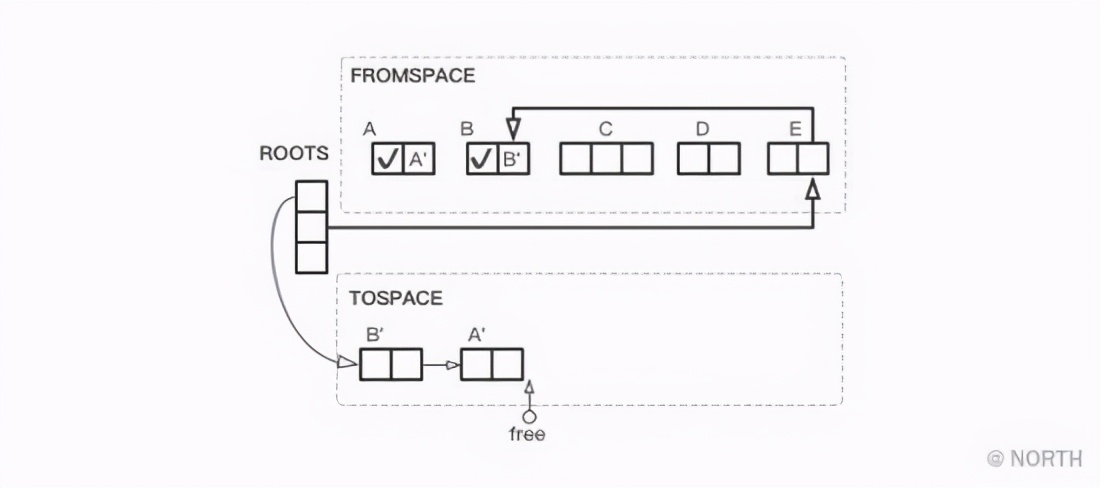
接下来复制从根引用的对象E,以及其引用对象B,不过因为B已经复制完成,所以只需要把从E指向B的指针换成指向B’的指针即可。
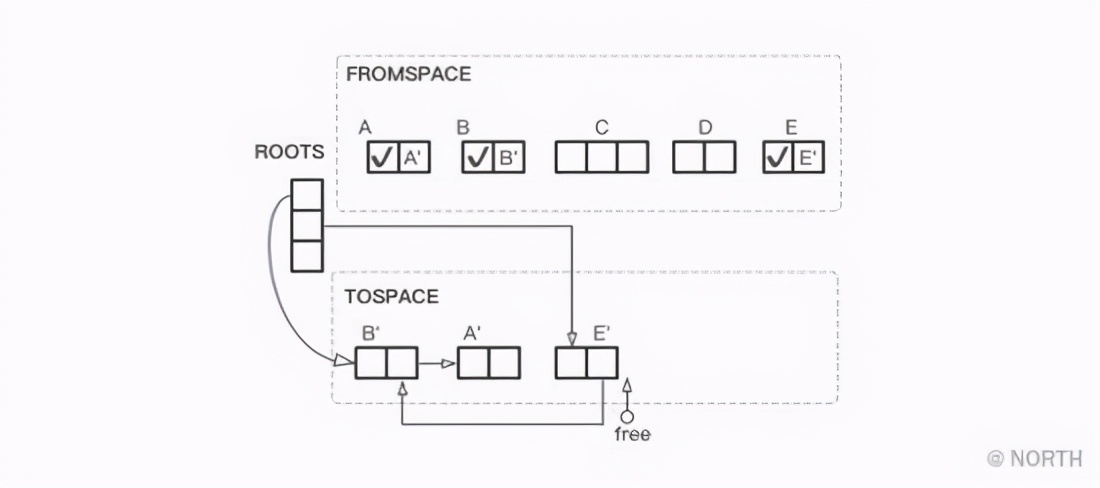
最后只要把FROMSPACE和TOSPACE互换,GC就结束了。GC结束时堆的状态如下图所示。
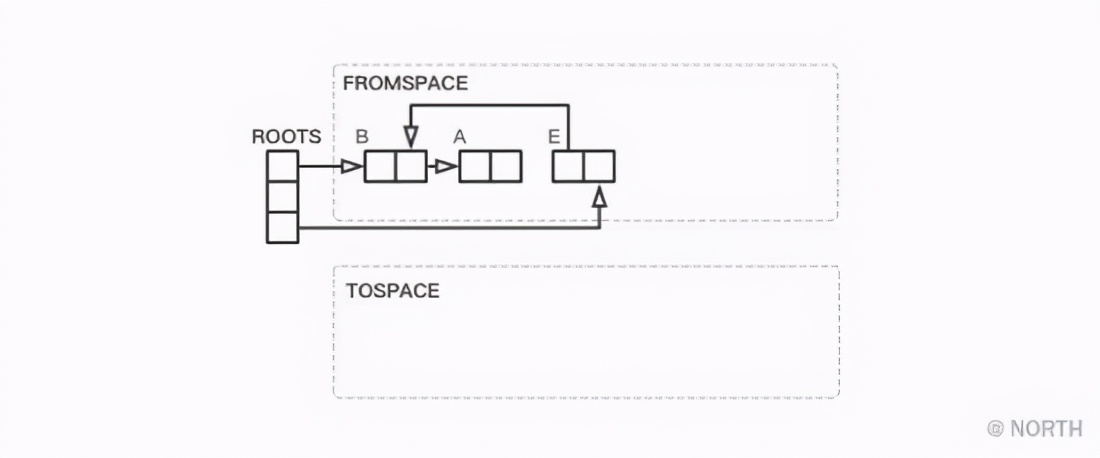
在这儿,程序的搜索顺序是按B、A、E的顺序搜索对象的,即以深度优先算法来搜索的。
算法评价
复制算法主要有如下优势:
- 吞吐量高:整个GC算法只搜索并复制存活对象,尤其是堆越大,差距越明显,毕竟它消耗的时间只是与活动对象数量成正比。
- 可实现高速分配:由于GC完成后空闲空间是一个连续的内存块,在内存分配时,只要申请空间小于空闲内存块,只需要移动free指针即可。相较于标记-清理算法使用空闲链表的分配方式,复制算法明显快得多,毕竟要在空闲链表中找到合适大小的内存怎么都得遍历这个链表。
- 无碎片:没啥好说的。
- 与缓存兼容:可以回顾一下前面说的局部性原理,由于所有存活对象都紧密的排布在内存里,非常有利于CPU的高速缓存。
相较于前面的两种GC算法,其劣势主要有亮点:
- 堆空间利用率低:复制算法把堆一分为二,只有一半能被使用,内存利用率极低,这也是复制算法的最大缺陷。
- 递归调用函数:复制某个对象时要递归复制它引用的对象,相较于迭代算法,递归的效率更低,而且有栈空间溢出的风险。
Cheney 复制算法
Cheney算法是用来解决如何遍历引用关系图并将存活对象移动到TOSPACE的算法,它使用迭代算法来代替递归。
还是以一个简单的例子来看看Cheney算法的执行过程,首先还是初始状态,在前面的例子上做了一点改动,同时有两个指针指向TOSPACE的起点位置。
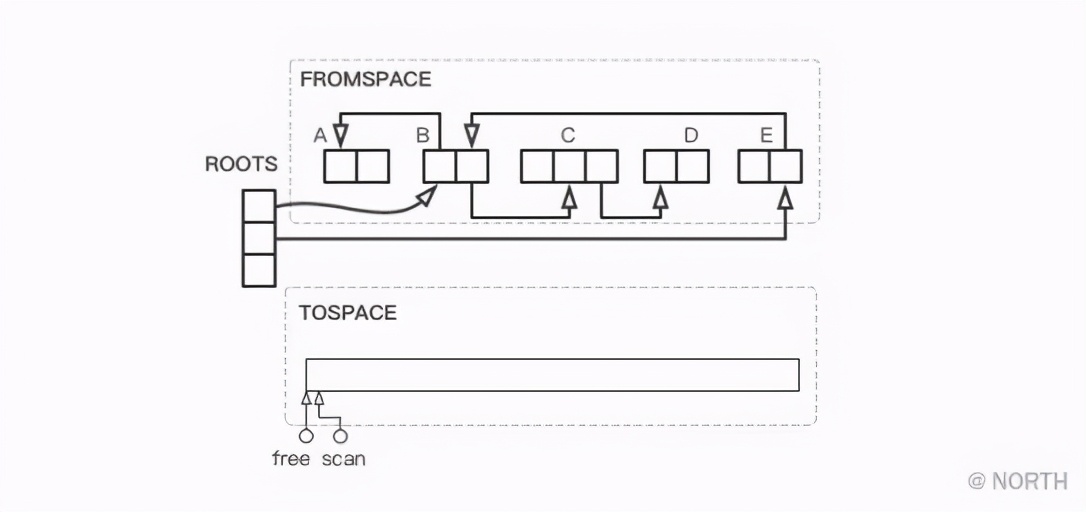
首先复制所有从根节点直接引用的对象,在这儿就是复制B和E。
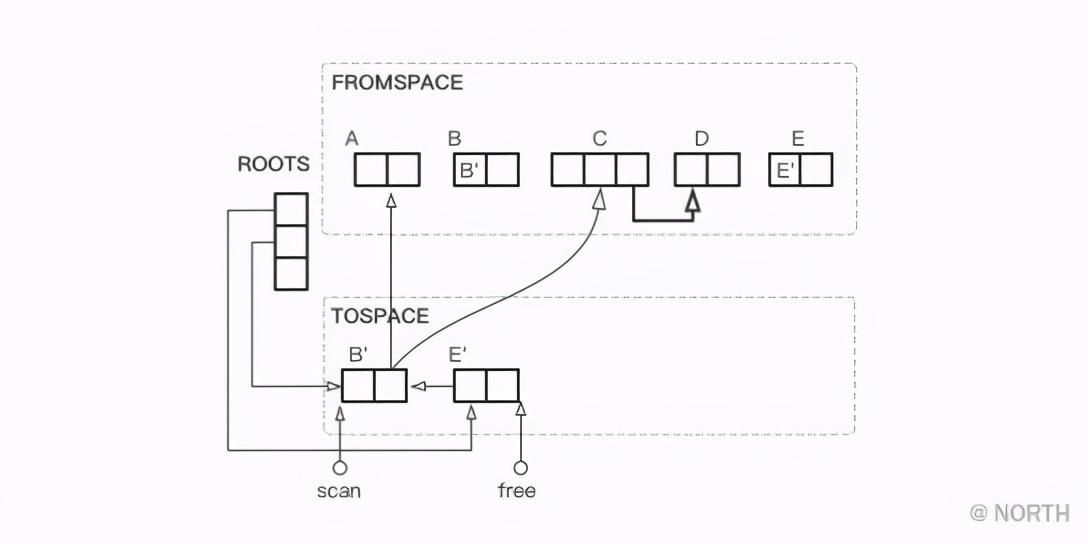
这时,与根节点直接引用的对象都已经复制完毕,scan 仍然指向TOSPACE的起点,free 从起点向前移动了B和E个长度。
接下来,scan 和 free 继续向前移动,scan 的每次移动都意味着对已完成复制对象的搜索,而 free 的向前移动则意味着新的对象复制完成。
还是以例子来说,在B和E完成复制以后,接着开始复制与B关联的所有对象,这里是A和C。
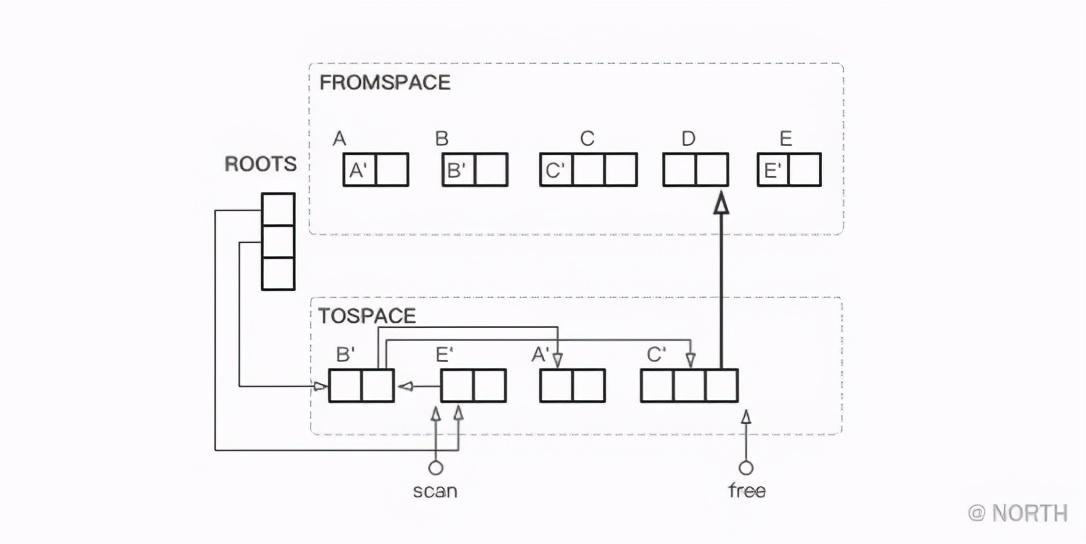
在复制A和C时,free 向前移动,等A和C复制完成以后,scan向前移动B个长度到E。接着,继续扫描E引用的对象B,发现B已经完成复制,则 scan 向前移动E个长度,free 保持不动。由于对象A没有引用任何对象,还是 scan 向前移动A个长度,free 保持不动。
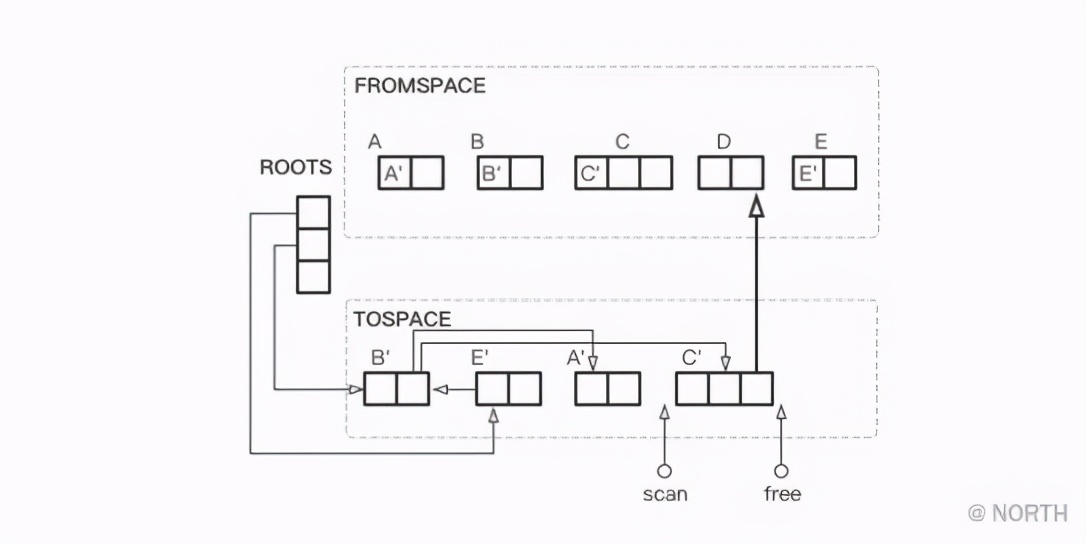
接下来,继续复制C的关联对象D,完成D的复制以后,发现 scan 和 free 相遇了,则结束复制。
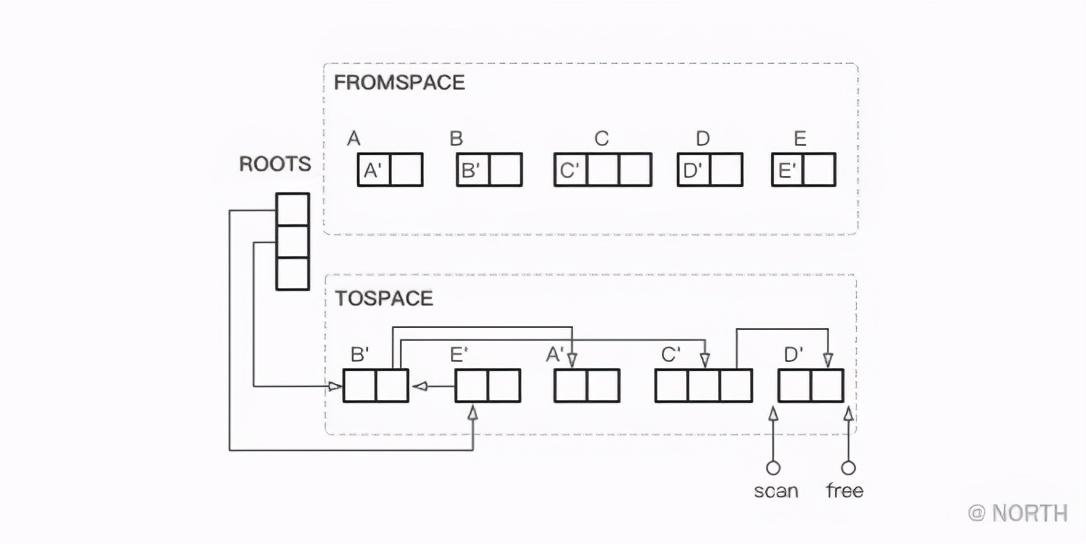
最后仍然是FROMSPACE和TOSPACE互换,GC结束。
代码实现只需要在之前的代码上稍做修改,即可:
collect() {
// free指向TOSPACE半区的起始位置
*scan = *free = *to_start;
// 复制根节点直接引用的对象
for(root in Roots) {
copy(*free, root);
}
// scan开始向前移动
// 首先获取scan位置处对象所引用的对象
// 所有引用对象复制完成后,向前移动scan
while(*scan != *free) {
for(child ingetRefObject(scan)){
copy(*free, child);
}
*scan += scan.size;
}
swap(*from_start,*to_start);
}
而 copy 函数也不再包含递归调用,仅仅是完成复制功能:
copy(*free,obj) {
if(!is_pointer_to_heap(obj.forwarding,*to_start)) {
// 将obj真正的复制到free指向的空间
copy_data(*free,obj);
// 复制完成后把对象的新地址存放在老对象的forwarding域中
obj.forwarding = *free;
// 按照obj的长度将free指针向前移动
*free += obj.size;
}
returnobj.forwarding;
}
对于 is_pointer_to_heap(obj.forwarding,*to_start) ,如果 obj.forwarding 是指向TOSPACE的指针,则返回TRUE,否则返回FALSE。这里没有使用 tag 来区分对象是否已经完成复制,而是直接判断 obj.forwarding 指针,如果 obj.forwarding 不是指针或者没有指向TOSPACE,那么就认为它没有完成复制,否则就说明已经完成复制。
通过代码可以看出,Cheney算法采用的是广度优先算法。熟悉算法的同学可能知道,广度优先搜索算法是需要一个先进先出的队列来辅助的,但这儿并没有队列。实际上 scan 和 free 之间的堆变成了一个队列,scan左边是已经搜索完的对象,右边是待搜索对象。free 向前移动,队列就会追加对象,scan 向前移动,都会有对象被取出并进行搜索,这样一来,就满足了先入先出队列的条件。
下面是一个广度优先遍历算法的典型实现,大家可以用作对比,加深理解。
voidBFS(List<Node> roots){
// 已经被访问过的元素
List<Node> visited =newArrayList<Node>();
// 用队列存放依次要遍历的元素
Queue<GraphNode> queue =newLinkedList<GraphNode>();
for(node in roots) {
visited.add(node);
process(node);
queue.offer(node);
}
while(!queue.isEmpty()) {
Node currentNode = queue.poll();
if(!visited.contains(currNode)) {
visited.add(currentNode);
process(node);
for(child ingetChildren(node)){
queue.offer(node);
}
}
}
}
对比之前的算法,Cheney算法的优点是使用迭代算法代替递归,避免了栈的消耗和可能的栈溢出风险,特别是拿堆空间用作队列来实现广度优先遍历,非常巧妙。而缺点则是,相互引用的对象并不是相邻的,就没办法充分利用缓存。注意,这里不是说,Cheney算法无法兼容缓存,只是相较于前一种算法来说,没有那么好而已。
最后
复制算法还有挺多变种的,这里没办法一一列举,更多内容可以阅读参考资料中的两本书籍。
复制算法的最大缺陷就是堆空间利用率低,因此大多数场景下,都是与其他算法搭配使用;并且我们也不是真的会把堆空间一分为二,而是根据实际情况,合理的划分。就比如,可以把堆空间分成10份,拿出2份空间分别作为From空间和To空间,用来执行复制算法,而剩下的8分则搭配使用标记-清理算法。
是不是又想到了JVM的新生代和老年代的区域划分,嗯,原因就是我们所讲的内容。